本文内容皆为作者原创,码字不易,如需转载,请注明出处:https://www.cnblogs.com/temari/p/13114519.html
一,开发工具
Python3.8.3+Pycharm 2020.1.2
二,程序功能
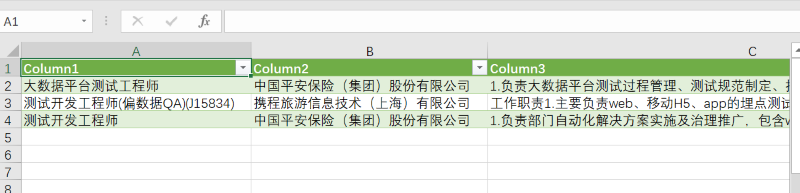
1.爬取网站的招聘信息,包括职位名称,招聘公司和岗位内容。
2.将爬取的数据保存为CSV和xls格式文件。
三,网站页面
网页源代码:
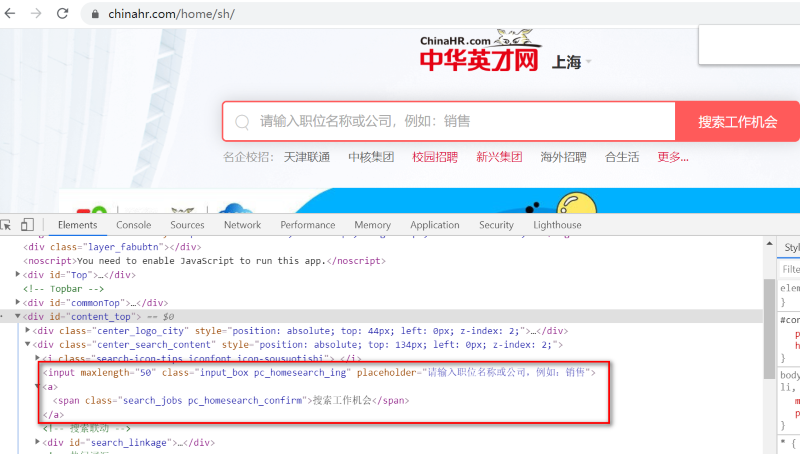
搜索框输入“”,点击【搜索工作机会】按钮,如图:
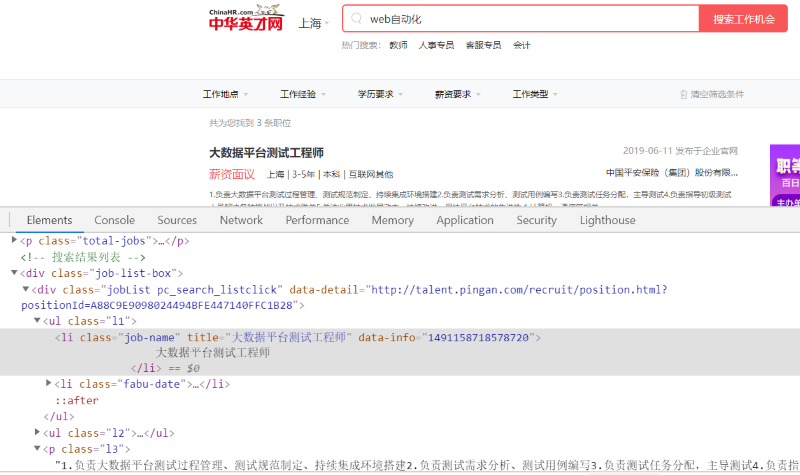
四,程序代码
1 ''' 2 程序功能:爬取网站上的招聘信息,将招聘信息保存成csv格式和xls格式。 3 作者:柠檬草不孤单 4 ''' 5 from selenium import webdriver 6 from selenium.webdriver.support.ui import WebDriverWait 7 from selenium.webdriver.support import expected_conditions as EC 8 from selenium.webdriver.common.by import By 9 from time import sleep 10 import csv 11 import xlwt 12 driver=webdriver.Chrome() 13 #隐式等待10秒 14 driver.implicitly_wait(10) 15 driver.get("https://www.chinahr.com/home/sh/") 16 driver.find_element_by_xpath("//div[@id='content_top']/div[2]/input[1]").clear() 17 driver.find_element_by_xpath("//div[@id='content_top']/div[2]/input[1]").send_keys("web自动化") 18 driver.find_element_by_xpath("//div[@id='content_top']/div[2]/a/span").click() 19 #窗口最大化 20 driver.maximize_window() 21 sleep(2) 22 #定义空列表 23 jobTitlesList=[] 24 jobCompaniesList=[] 25 jobContentsList=[] 26 while True: 27 try: 28 #抓取所有职位title 29 jobTitles=driver.find_elements_by_xpath("//div[@class='job-list-box']/div/ul/li[@class='job-name']") 30 #将职位title文本存放到list 31 for jobTitle in jobTitles: 32 jobTitlesList.append(jobTitle.text) 33 #抓取所有职位公司名称 34 jobCompanies=driver.find_elements_by_xpath("//div[@class='job-list-box']/div/ul/li[@class='job-company']") 35 #将职位公司名称文本存放到list 36 for jobCompany in jobCompanies: 37 jobCompaniesList.append(jobCompany.text) 38 #抓取所有职位工作内容 39 jobContents=driver.find_elements_by_xpath("//div[@class='job-list-box']/div/p[@class='l3']") 40 #将职位工作内容文本存放到list 41 for jobContent in jobContents: 42 jobContentsList.append(jobContent.text) 43 nextPageXpath = "//div[@class='page-list']/a/i[@class='nextBtn iconfont']" 44 #判断是否到最后一页 45 element = WebDriverWait(driver, 15).until(EC.element_to_be_clickable((By.XPATH, nextPageXpath))) 46 driver.find_element_by_xpath(nextPageXpath).click() 47 except: 48 print("已经加载到最后一页") 49 #到最后一页,跳出 50 break 51 jobInformations=[] 52 for i in range(len(jobTitlesList)): 53 for j in range(len(jobCompaniesList)): 54 if i == j: 55 for k in range(len(jobContentsList)): 56 if j==k: 57 #将三个列表的值合并成新的列表 58 Infor=[jobTitlesList[i],jobCompaniesList[j],jobContentsList[k]] 59 jobInformations.append(Infor) 60 print(jobInformations) 61 #将爬取内容另存csv文件 62 with open(r"jobInformation.csv", 'w+',encoding='utf-8',newline='') as file: 63 writer = csv.writer(file) 64 writer.writerows(jobInformations) 65 print("创建csv文件成功!") 66 #将爬取内容另存为xls文件 67 workbook = xlwt.Workbook() 68 worksheet=workbook.add_sheet("jobInfo") 69 for i in range(len(jobInformations)): 70 for j in range(len(jobInformations[0])): 71 worksheet.write(i,j,jobInformations[i][j]) 72 workbook.save("jobInfor.xls") 73 print("创建xls文件成功!") 74 sleep(5) 75 driver.quit()
五,程序演示
程序调试成功,如图:
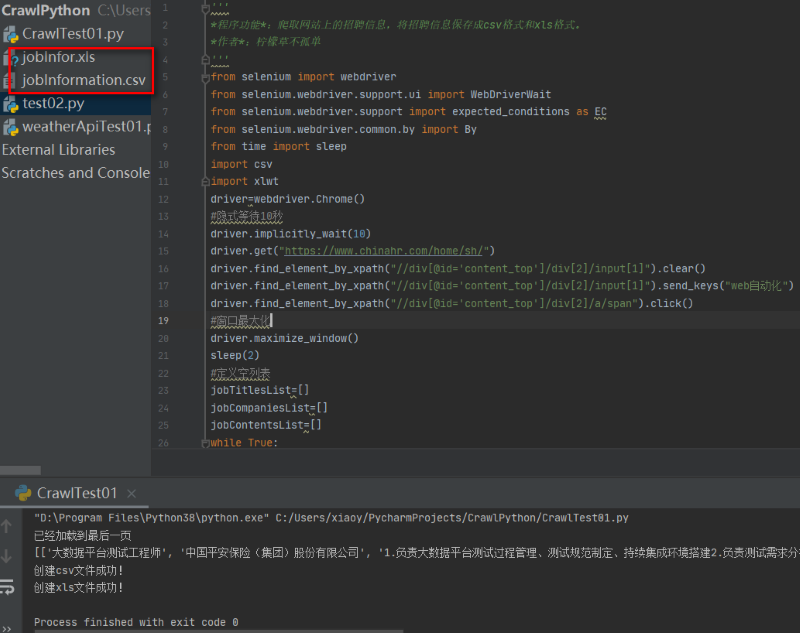
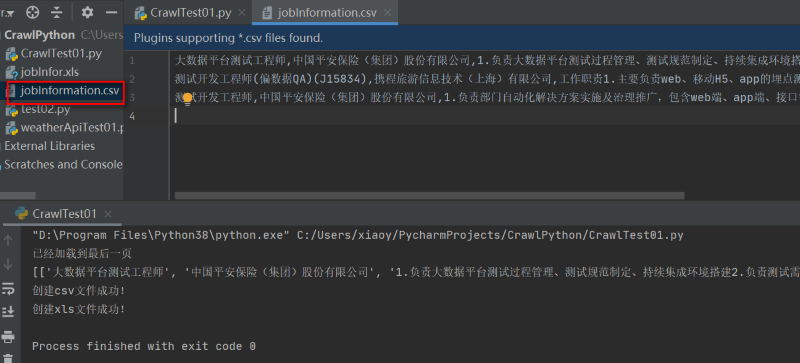
程序调试成功后,项目CrawlPython目录下生成两个文件,一个csv文件,如图:
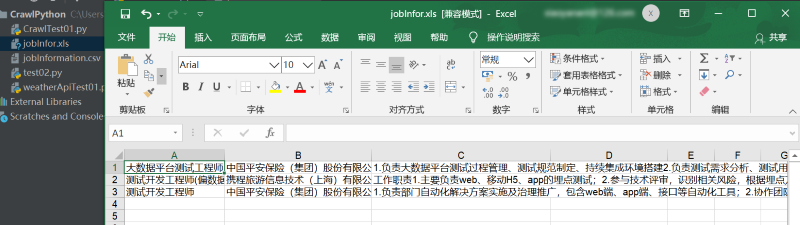
另外一个xls文件,点击可直接打开,内容正确,如图:
六,遇到问题
问题1:本地目录的csv文件用excel打开显示乱码,如图:
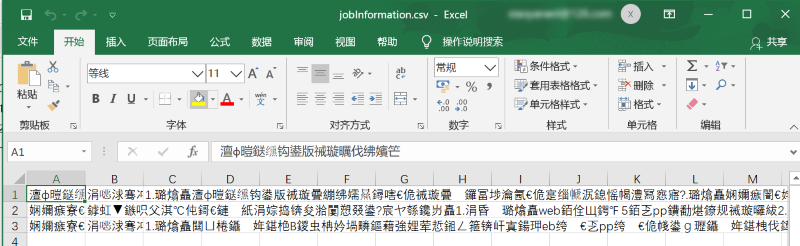
问题分析:经百度浏览了一些帖子定位分析是文件编码设置的问题。由于我的excel默认打开是gb2312编码,文件写入时用的是UTF-8格式,导致打开文件时解析乱码。
解决步骤:
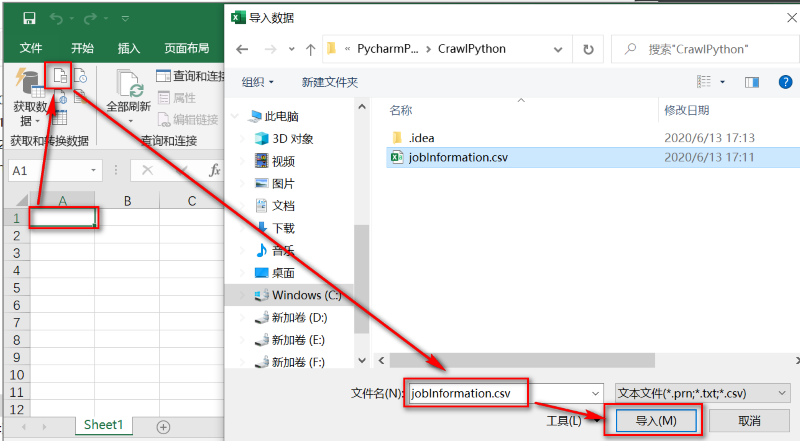
1.打开一个空的excel文件,选中左上角作为文件导入位置,鼠标定位在第一行第一列,点击【数据】-【从文本/CSV】,弹出导入数据窗口,选择乱码的文件,点击【导入】,如图:
2.在弹出的加载窗口,可以看到当前文件打开的默认使用的编码为GB2312,分隔符默认为“逗号”,调整文件原始格式为“UTF-8”,如图:
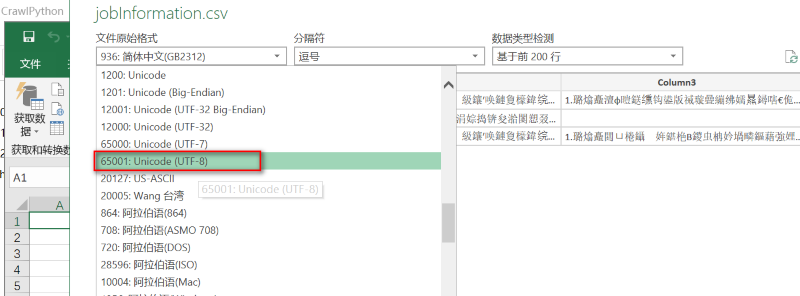
3.调整编码后,可以看到当前页面导入文件的显示效果,点击【加载】按钮,如图:
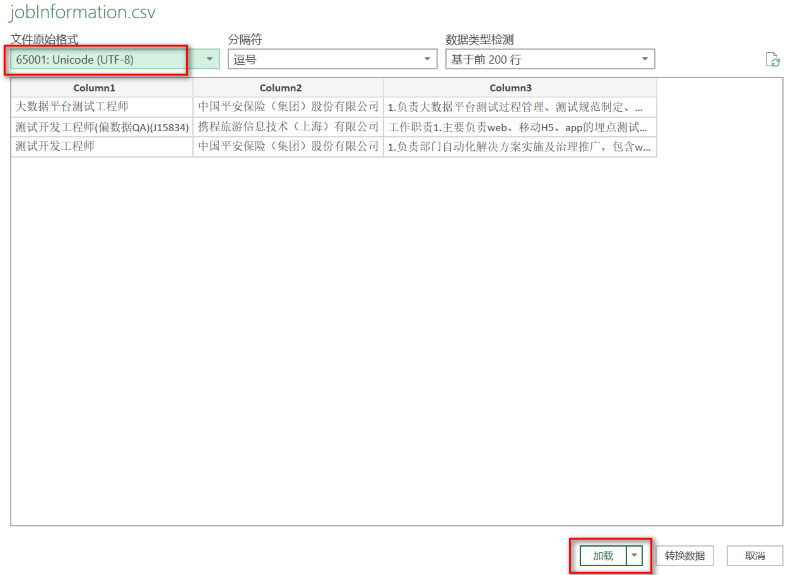
4.CSV文件显示正常,问题解决,如图: