回归,探讨的是自变量与因变量的关系(因果关系)。
通过回归技术,可知道自变量与因变量存在关系,且知道自变量对因变量的影响强度如何。
常见的有一元线性、多元线性回归方程,但因为存在不满足模型基本假设问题,我们的大神们陆续推出了岭回归、Lasso回归等等。
目录:
- 一.线性回归
- 二.多项式回归
- 三.逐步回归
- 四.岭回归Ridge Regression
- 五.Lasso回归
- 六.ElasticNet回归
- 七.总结:如何选取回归方法?
- 八.sklearn中的线性回归算法
一.线性回归
自变量类型:连续OR离散型
因变量类型:连续型
keys:
- 独立变量与因变量之间必须存在线性关系
- 线性回归对异常值很敏感,可能会影响最终的回归效果
- 在多元回归中,警惕:多重共线性、自相关、异方差性
- 在自变量很多时,我们可以通过逐步回归法(前进法、后退法、逐步回归法)来选择最重要的自变量
python用法:from sklearn.linear_model import LinearRegression,再用from sklearn import metrics里的MSE、RMSE来选择评价模型:metrics.mean_squared_error()、np.sqrt(metrics.mean_squared_error())
拓:
多重共线性带来的问题:
- 当自变量存在多重共线性时,利用普通最小二乘估计得到的回归参数的估计值表现很不稳定,回归系数的方差随着多重共线性强度的增加而加速增长。
- 会造成回归方程高度显著的情况下,有些回归系数不能通过显著性检验。
- even回归系数的正负得不到合理的经济解释。
二.多项式回归
自变量的幂不再局限于1,有2次、3次等出现,此时建立多项式方程。
图形不再是一条直线,变成了一条曲线。

在应用中,要注意过拟合问题,因为更高次项可能带来拟合优度更高的模型,但是泛华能力不高,实际没用呀。下图形象表示:
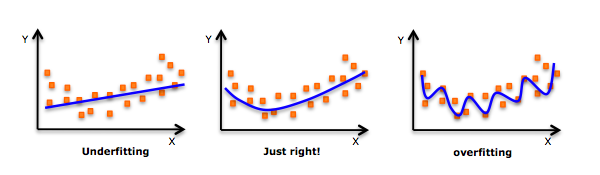
三.逐步回归
把所有的变量选入模型中,做回归的话,这叫全模型。而抽出部分自变量来建模,那模型就叫选模型,可谓少而精。此时,可根据自由度调整复决定系数(达到最大)、赤池信息量AIC(达到最小)、Cp统计量(达到最小)等来选择模型。但是,这是在自变量不太多时应用,因为假设有m个自变量时,将要计算(2的m次方)-1个回归方程,然后根据上述的选元准则来挑选出最佳模型。那么,在自变量很多时,该怎么办?
可选用逐步回归法:
- 前进法:每次加入一个自变量(用到F检验)
- 后退法:先建立全模型,然后逐次剔除一个变量(同样用F检验)
- 逐步回归:自变量有进有出,保证了最后是最优回归子集
四.岭回归Ridge Regression
出现原因:多重共线性,即自变量之间存在高度相关,使得即使我们用最小二乘得到回归参数的无偏估计值,but 它们的方差很大,使得观察值远离真实值。

从上面看到,在一般的线性回归方程中,我们的损失函数仅坐了偏差的考虑。但是,一般的线性模型易过拟合,为了防止模型的过拟合,我们在基础的损失函数的基础上,加入L2正则化项,这就变成了Ridge 回归。
Ridge回归通过收缩参数lambda来解决多重共线性问题。

这时候,损失函数由两个组成,一部分是偏差,一部分是方差。通过lambda系数,计算后将被添加到最小二乘项来收缩较低的方差参数。
Ridge回归在不抛弃任何一个特征的情况下,缩小了回归系数(永远不会达到零,没有做特征选择),使得模型相对而言比较的稳定,但和Lasso回归比,这会使得模型的特征留的特别多,模型解释性差。
五.Lasso回归
与Ridge回归出现的原因类似,都是为了防止过拟合。
但是它引入的是L1范数,惩罚回归系数的绝对大小。使得一些回归系数变小,如果惩罚系数够大,它可能会使回归系数收缩为零,相当于在做特征选择了,因此特别适用于参数数目缩减与参数的选择,因而用来估计稀疏参数的线性模型。
在一批自变量高度相关的情况下,Lasso会选择保留其中一个变量,然后将其他自变量的回归系数缩减为零。
损失函数如下:
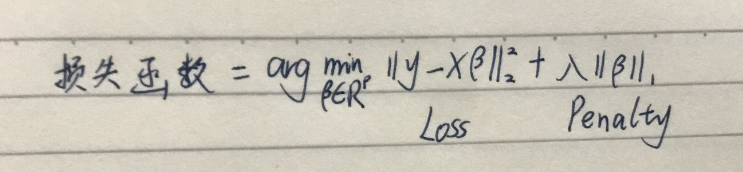
回归系数可用坐标轴下降法(coordinate descent)和最小角回归法( Least Angle Regression, LARS)求出来。
六.ElasticNet回归
它是Lasso和Ridge回归技术的混合模型,同时加入了L1和L2的正则项。当自变量之间存在相关关系时,Lasso回归可能随机地选择其中一个,而ElasticNet回归很可能选择两个。它能继承部分Ridge回归的稳定性。它对所选变量的数量没有限制,可能会遭受双倍的收缩率。

七.总结:如何选取回归方法?
- 建模前,先了解数据的自变量与因变量之间的关系、自变量之间是否存在多重共线性
- 为了比较不同模型的拟合程度,我们可以分析不同的指标,如:参数的重要性统计、R方、adjusted R方、AIC、BIC和误差项。还有一个是Cp标准。将全模型与所有的子模型拿来比较,看其中的偏差大小对比
- 交叉验证是评估用来预测的模型的最佳方式。将原始数据划分为训练集和测试集,然后一般用MSE均方误差来比较模型的建模效果
- 如果数据集中存在多个混淆变量(与因变量存在相关关系,但可能只是虚假的、影响建模效果的自变量),那么就不应该选择自动选择自变量的算法,因为建模没用呀
- 那也取决于你的建模目的。你可以需选择建立一个拟合能力不太高的模型,因为这样更易实现。当然也可以逐步优化,达到一个高精度的模型
- 正则化方法(Lasso,Ridge和ElasticNet)在高维度和存在多重共线性的数据集上表现更好
八.sklearn中的线性回归算法
求解回归系数的过程中,我们定义不同的损失函数、不同的最小化损失函数的方法、不同的验证算法的方法.Thus,产生了一系列不同的算法:
1.LinearRegression
- 损失函数:最普通的线性回归,对应只含有偏差项的损失函数。
- 最小化损失函数的方法:它有两种极小化损失函数的方法:最小二乘法、梯度下降法。sklearn中LinearRegression类用的是最小二乘法。
- 验证方法:手动划分训练集、测试集,然后逐步优化。
- 一般来说,只要我们觉得数据有线性关系,就可以先用这个基本版来建模。如果效果不佳,再继续选择后面的方法。
2.Ridge
- 损失函数:在原始版损失函数中,加入L2正则化项,这时正则化项中包含一个常数系数,要对它进行调优。Ridge回归在不抛弃任何一个特征的情况下,缩小了回归系数,使得模型相对而言比较的稳定,不至于过拟合。
- 最小化损失函数的方法:它有两种极小化损失函数的方法:最小二乘法、梯度下降法。sklearn中Ridge类用的是最小二乘法。
- 验证方法:手动划分训练集、测试集,然后需要手动设置正则化项里的常数系数。
- 一般来说,只要我们觉得数据有线性关系,并且LinearRegression出来的效果不佳,那你就要用Ridge回归。要自己不断设置正则化项里的常数系数,然后评估这个常数系数的好坏。
3.RidgeCV
- 损失函数:同Ridge。
- 最小化损失函数的方法:同Ridge。
- 验证方法:可以通过交叉验证来寻找最佳的正则化项里的常数系数,不用再一个一个试啦。可以一次性输入多个常数系数,让该类去计算最佳的常数系数。
- RidgeCV用起来比Ridge方便。但是如果遇到特征非常多,且是稀疏数据时,请用下面介绍的Lasso系列。
4.Lasso
- 损失函数:在基础版损失函数的基础上,增加L1正则项,需要调整正则化里的惩罚系数
- 最小化损失函数的方法:最常用:坐标轴下降法和最小角回归法,该类用坐标下降法
- 验证方法:手动划分训练集、测试集,然后设置惩罚系数,不断找最佳惩罚系数,不断优化建模效果
- 如果遇到特征非常多,且是稀疏数据时,一般会用这个类。如果你想找出其中关键影响因素,剔除没什么作用的自变量,那么请用这个类吧。不过,需要手动调参,设置惩罚系数
5.LassoCV
- 损失函数:在基础版损失函数的基础上,增加L1正则项,需要调整正则化里的惩罚系数
- 最小化损失函数的方法:最常用:坐标轴下降法和最小角回归法,该类用坐标下降法
- 验证方法:运用交叉验证来选择范围内最佳的惩罚系数
- 如果遇到特征非常多,且是稀疏数据时,一般会用这个类。如果你想找出其中关键影响因素,剔除没什么作用的自变量,那么请用这个类吧。不用多次设置惩罚系数,省时省力
6.LassoLars
- 损失函数:在基础版损失函数的基础上,增加L1正则项,需要调整正则化里的惩罚系数
- 最小化损失函数的方法:最小角回归法(Least Angle Regression)
- 验证方法:手动划分训练集、测试集,然后设置惩罚系数,不断找最佳惩罚系数,不断优化建模效果
- 用最小角回归法什么时候比坐标轴下降法好呢?
- 场景一:如果我们想探索超参数α更多的相关值的话,由于最小角回归可以看到回归路径,此时用LassoLarsCV比较好
- 场景二: 如果我们的样本数远小于样本特征数的话,用LassoLarsCV也比LassoCV好。其它一般用基本版本的Lasso
7.LassoLarsCV
- 损失函数:在基础版损失函数的基础上,增加L1正则项,需要调整正则化里的惩罚系数
- 最小化损失函数的方法:最小角回归法(Least Angle Regression)
- 验证方法:运用交叉验证来选择范围内最佳的惩罚系数
- 同6
8.LassoLarsIC
- 损失函数:在基础版损失函数的基础上,增加L1正则项,需要调整正则化里的惩罚系数
- 最小化损失函数的方法:最小角回归法(Least Angle Regression)
- 验证方法:基于AIC、BIC自动选择惩罚系数,完全不用自己选择设置
- 这个类要求比较严格,需要大样本(样本数最好远大于特征数),并且是由假设的模型产生的,所以比较少用。
9.ElasticNet
- 损失函数:在基础版损失函数的基础上,同时增加L1、l2正则项
- 最小化损失函数的方法:常用:坐标轴下降法和最小角回归法,该类用坐标轴下降法
- 验证方法:手动划分训练集、测试集,自己设置惩罚系数,不断优化
- 如果用前面的LassoCV、RidgeCV时,你发觉LassoCV回归太多,把太多特征剔除了;而RidgeCV回归系数衰减太慢,那么就用ElasticNet来用。但是更推荐下面的用交叉验证来选择惩罚系数的类
10. ElasticNetCV
- 损失函数:在基础版损失函数的基础上,同时增加L1、l2正则项
- 最小化损失函数的方法:常用:坐标轴下降法和最小角回归法,该类用坐标轴下降法
- 验证方法:用交叉验证的方法来选择最佳惩罚系数,方便
- 比9更方便
参考资料:
-《应用回归分析》 第四版