持续优化中~~~
背景:
中国电子商务的发展在全球范围内,处于遥遥领先的位置。在特定节日,如双十一,更是吸引了外国大批的消费者疯狂下单抢购。现随着各大平台的兴起,平台越来越正规化,卖家要懂得利用各方资源,来弥补自身的不足,不断提高商品的曝光率。随着国内一二线城市网购渗透率接近饱和,在未来,三四线城市将成为电商的新一轮战场。这对卖家来说,既是机遇也是挑战。各商家要想提高自己店铺的收益,达到利益最大化,应更重视对自己及行业销售数据的数据分析、了解行业竞争对手的营销方式、营销对象等等,力求更精准度的营销。才能在未来抢占一定的市场份额,活得更好。
在社交媒体中,我们可常看到女性朋友追捧各类包包。包包不再单单是通勤、逛街、出游时的必备品,在某种程度上,对部分女性来说,这已经成为一种社会地位的象征。更极端的是,部分女性为了一个几万元的包包,可以选择借贷、吃土……作为商家,应抓住人们的心理,推出市场需求大的包包。那什么样的女包更受消费者青睐呢?

——一款COACH蔻驰包包(来自淘宝官网,侵删)
现我们针对一份2018年一月的女包销售数据(狗熊会提供的数据资源),对女包销售情况进行数据分析。探讨什么类型的女包更能让消费者剁手,找出关键影响因素,给各商家提供一定的参考价值。
目录:
一.数据探索分析(EDA)
二.清洗数据&数据规约
三.建模
四.总结
五.反思
一.数据探索分析(EDA)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import warnings
warnings.filterwarnings("ignore")
import seaborn as sns
data = pd.read_csv(r"G:datalady bagslady bags.csv",encoding="gbk")
data.head(4)
| 售卖名称 | 价格 | 促销价 | 月销量 | 累计评价 | 上市时间 | 大小 | 流行款式名称 | 适用对象 | 款式 | 背包方式 | 质地 | 提拎部件类型 | 闭合方式 | 图案 | 有无夹层 | 箱包硬度 | 适用场景 | 品牌 | 风格 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ELLE女包单肩包迷你斜挎包 休闲百搭女包简约时尚女包新款包包女 | 998.0 | 399.0 | 1231.0 | 14720.0 | 2016年春季 | 小 | 其他 | 青年 | 单肩包 | 单肩斜挎 | 牛皮 | 装卸式提把 | 拉链 | 纯色 | 无 | 软 | 休闲 | ELLE | 欧美时尚 |
| 1 | 红谷包包2016新款牛皮女包手提包大容量简约杀手包大牌百搭大包AE | 1169.0 | 589.0 | 771.0 | 1132.0 | 2016年夏季 | 大 | 杀手包 | 青年 | 手提包 | NaN | 牛皮 | NaN | 拉链 | 纯色 | 无 | 硬 | 休闲 | HONGU/红谷 | 欧美时尚 |
| 2 | CHARLES&KEITH 小方包 CK2-20680447 金属流苏单肩斜跨女包 | 469.0 | NaN | 340.0 | 147.0 | 2016年冬季 | 小 | 小方包 | 青年 | 单肩包 | 单肩斜挎 | PU | NaN | 磁扣 | 纯色 | 无 | 硬 | 宴会 | CHARLES&KEITH | 欧美时尚 |
| 3 | CHARLES&KEITH小方包 CK2-20680447金属流苏单肩斜跨女包 | 469.0 | NaN | 330.0 | 97.0 | 2016年冬季 | 小 | 小方包 | 青年 | 单肩包 | 单肩斜挎 | PU | NaN | 磁扣 | 纯色 | 无 | 硬 | 宴会 | CHARLES&KEITH | 欧美时尚 |
print("数据集大小:",data.shape)
数据集大小: (6576, 20)
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6576 entries, 0 to 6575
Data columns (total 20 columns):
售卖名称 6576 non-null object
价格 6573 non-null float64
促销价 5555 non-null float64
月销量 6511 non-null float64
累计评价 6565 non-null float64
上市时间 6572 non-null object
大小 6572 non-null object
流行款式名称 6572 non-null object
适用对象 6068 non-null object
款式 6574 non-null object
背包方式 5242 non-null object
质地 6572 non-null object
提拎部件类型 5770 non-null object
闭合方式 6402 non-null object
图案 6326 non-null object
有无夹层 6135 non-null object
箱包硬度 6271 non-null object
适用场景 6438 non-null object
品牌 6574 non-null object
风格 6471 non-null object
dtypes: float64(4), object(16)
memory usage: 1.0+ MB
1.数据集有6576个样本数据,包含19个特征,以及1个目标标签:月销量。
1.1目标标签:月销量
1.2 特征
1.2.1 连续型:价格、促销价、累计评价
1.2.2 分类型:售卖名称、上市时间、大小、流行款式名称、适用对象、款式、背包方式、质地、提拎部件类型、闭合方式、图案、有无夹层、箱包硬度、适用场景、品牌、风格
1.1目标标签:月销量
data["月销量"].describe()
count 6511.00000
mean 393.84196
std 1389.86886
min 10.00000
25% 43.00000
50% 85.00000
75% 244.50000
max 45789.00000
Name: 月销量, dtype: float64
sns.distplot(data["月销量"].dropna())
<matplotlib.axes._subplots.AxesSubplot at 0x639262f588>

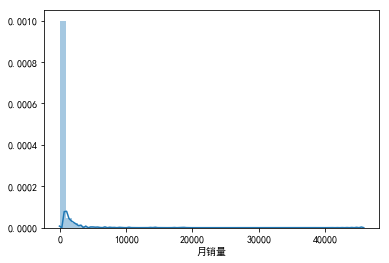
print("月销量分析:")
print("偏度Skewness: %f" % data["月销量"].dropna().skew())
print("峰度Kurtosis: %f" % data["月销量"].dropna().kurt())
print("均值:",data["月销量"].dropna().mean())
print("标准差:",data["月销量"].dropna().std())
print("方差:",data["月销量"].dropna().var())
月销量分析:
偏度Skewness: 12.880813
峰度Kurtosis: 262.101560
均值: 393.8419597604055
标准差: 1389.8688599951174
方差: 1931735.447984127
明显看到数据存在右偏情况,即数据大多集中在较小值区域。为了让建模效果更好,我们需要对月销量进行函数变换,使之更接近正态分布。
sns.distplot(np.log(data["月销量"].dropna()))
<matplotlib.axes._subplots.AxesSubplot at 0x638e3aa320>

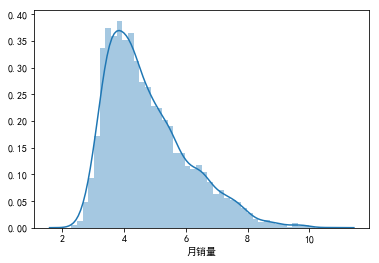
print("变换后的月销量")
print("偏度Skewness: %f" % np.log(data["月销量"].dropna()).skew())
print("峰度Kurtosis: %f" % np.log(data["月销量"].dropna()).kurt())
print("变换后的均值:",np.log(data["月销量"].dropna()).mean())
print("变换后的标准差:",np.log(data["月销量"].dropna()).std())
print("变换后的方差:",np.log(data["月销量"].dropna()).var())
变换后的月销量
偏度Skewness: 0.964234
峰度Kurtosis: 0.652875
变换后的均值: 4.756572444698999
变换后的标准差: 1.3135338810392991
变换后的方差: 1.7253712566381636
明显感受到变换后,“月销量”更加规整,更集中分布。
1.2 特征
1.2.1 连续型:价格、促销价、累计评价
data.describe().drop("月销量",axis=1) #三个连续型变量的统计量
| 价格 | 促销价 | 累计评价 | |
|---|---|---|---|
| count | 6573.000000 | 5555.000000 | 6565.000000 |
| mean | 475.231675 | 227.168358 | 1806.450571 |
| std | 551.135073 | 250.910681 | 5541.317357 |
| min | 18.000000 | 9.600000 | 0.000000 |
| 25% | 169.000000 | 69.000000 | 71.000000 |
| 50% | 299.000000 | 168.000000 | 275.000000 |
| 75% | 558.000000 | 269.000000 | 1183.000000 |
| max | 9868.000000 | 2798.000000 | 145571.000000 |
1.2.1.1 三个连续变量的数据分布图:
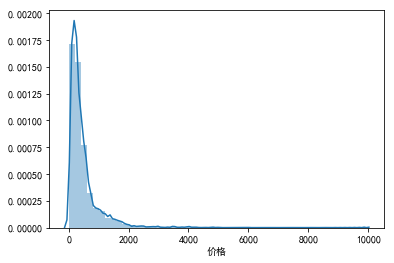
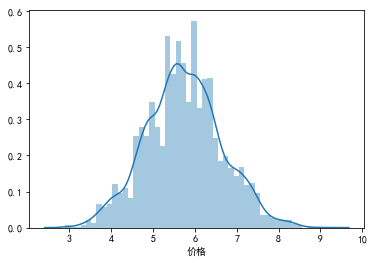
sns.distplot(data["价格"].dropna())
<matplotlib.axes._subplots.AxesSubplot at 0x6392f1dc50>

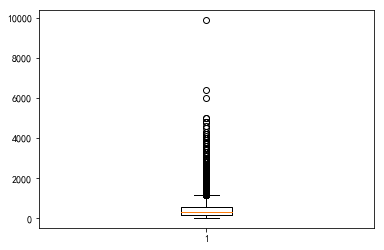
plt.boxplot(data["价格"].dropna())
{'boxes': [<matplotlib.lines.Line2D at 0x6393136e80>],
'caps': [<matplotlib.lines.Line2D at 0x6393149898>,
<matplotlib.lines.Line2D at 0x6393149a58>],
'fliers': [<matplotlib.lines.Line2D at 0x6393151ac8>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x63931512b0>],
'whiskers': [<matplotlib.lines.Line2D at 0x6393142828>,
<matplotlib.lines.Line2D at 0x6393142fd0>]}

sns.distplot(data["促销价"].dropna())
<matplotlib.axes._subplots.AxesSubplot at 0x63930ee278>

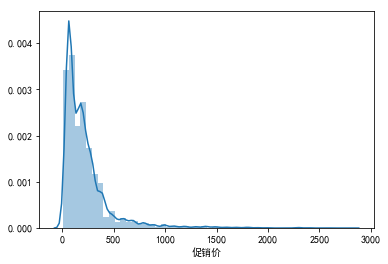
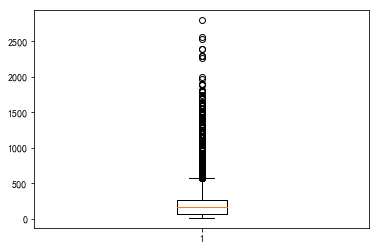
plt.boxplot(data["促销价"].dropna())
{'boxes': [<matplotlib.lines.Line2D at 0x639335fe80>],
'caps': [<matplotlib.lines.Line2D at 0x6393373898>,
<matplotlib.lines.Line2D at 0x6393373a58>],
'fliers': [<matplotlib.lines.Line2D at 0x6393379ac8>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x63933792b0>],
'whiskers': [<matplotlib.lines.Line2D at 0x639336b828>,
<matplotlib.lines.Line2D at 0x639336bfd0>]}

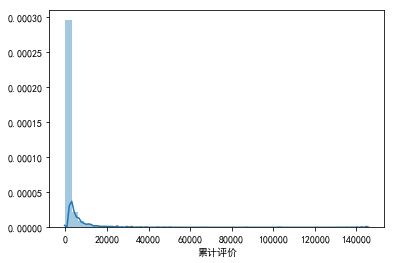
sns.distplot(data["累计评价"].dropna())
<matplotlib.axes._subplots.AxesSubplot at 0x639331e278>

plt.boxplot(data["累计评价"].dropna())
{'boxes': [<matplotlib.lines.Line2D at 0x639358d7f0>],
'caps': [<matplotlib.lines.Line2D at 0x6393597b70>,
<matplotlib.lines.Line2D at 0x63935a0a20>],
'fliers': [<matplotlib.lines.Line2D at 0x63935a8a90>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x63935a0be0>],
'whiskers': [<matplotlib.lines.Line2D at 0x639358d9b0>,
<matplotlib.lines.Line2D at 0x63935979b0>]}


发现普遍的有变量的最小值和最大值相差较大,数据存在右偏情况,表明数据集中在较小区域,但存在较大值造成拖尾。这些偏大的数值并不利于我们建模。
(1)“价格”的有效计数为6573个,平均值为475,中位数为299,标准差为551。最小值为18,最大值为9868,差距较大。
(2)“促销价”有效计数为5555个,缺失了1000多个数据(16%)。平均值为227,中位数为168,平均值大于中位数。最小值为10,最大值为2798,标准差为251。
(3)“累计评价”有效计数为6565条,平均值为1806条,中位数为275条。最小值为0,最大值为145571,标准差达到5541,可见数据的波动范围较大。
1.2.1.2 函数变换后三个连续变量的数据分布图:
sns.distplot(np.log(data["价格"].dropna()))
<matplotlib.axes._subplots.AxesSubplot at 0x63935151d0>

plt.boxplot(np.log(data["价格"].dropna()))
{'boxes': [<matplotlib.lines.Line2D at 0x63937be9e8>],
'caps': [<matplotlib.lines.Line2D at 0x63937c9d68>,
<matplotlib.lines.Line2D at 0x63937d2c18>],
'fliers': [<matplotlib.lines.Line2D at 0x63937d9c88>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x63937d2dd8>],
'whiskers': [<matplotlib.lines.Line2D at 0x63937beba8>,
<matplotlib.lines.Line2D at 0x63937c9ba8>]}


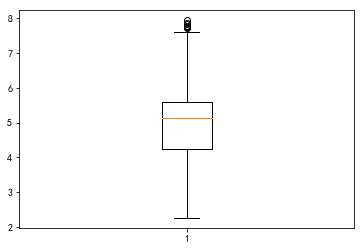
sns.distplot(np.log(data["促销价"].dropna()))
<matplotlib.axes._subplots.AxesSubplot at 0x6393761710>

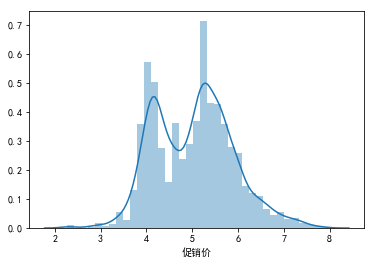
plt.boxplot(np.log(data["促销价"].dropna()))
{'boxes': [<matplotlib.lines.Line2D at 0x63939b6d68>],
'caps': [<matplotlib.lines.Line2D at 0x63939c6780>,
<matplotlib.lines.Line2D at 0x63939c6f98>],
'fliers': [<matplotlib.lines.Line2D at 0x63939cdf60>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x63939cd198>],
'whiskers': [<matplotlib.lines.Line2D at 0x63939b6f28>,
<matplotlib.lines.Line2D at 0x63939bff28>]}

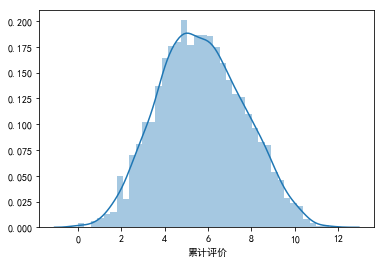
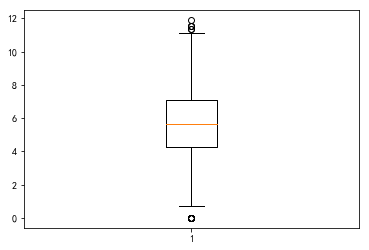
a = np.log(data["累计评价"].dropna())
a.describe()
count 6565.000000
mean -inf
std NaN
min -inf
25% 4.262680
50% 5.616771
75% 7.075809
max 11.888419
Name: 累计评价, dtype: float64
已知累计评价中有0值得出现,对数变换后变为负无穷,我们将该值去掉后作图看数据的分布:
b = a[a>=0]
sns.distplot(b)
<matplotlib.axes._subplots.AxesSubplot at 0x639376bda0>

plt.boxplot(b)
{'boxes': [<matplotlib.lines.Line2D at 0x6393bc2780>],
'caps': [<matplotlib.lines.Line2D at 0x6393bcdb00>,
<matplotlib.lines.Line2D at 0x6393bd39b0>],
'fliers': [<matplotlib.lines.Line2D at 0x6393bdba20>],
'means': [],
'medians': [<matplotlib.lines.Line2D at 0x6393bd3b70>],
'whiskers': [<matplotlib.lines.Line2D at 0x6393bc2940>,
<matplotlib.lines.Line2D at 0x6393bcd940>]}

对数变换后:
“价格”:数据的分布较原先更接近正态分布
“促销价”:对数变换后,数据偏度减小,但注意到其缺失值较多
“累计评价”:数据相对集中于某一区域,异常值明显减少。
1.2.2 分类型变量:
售卖名称、上市时间、大小、流行款式名称、适用对象、款式、背包方式、质地、提拎部件类型、闭合方式、图案、有无夹层、箱包硬度、适用场景、品牌、风格
data.describe(include=['O'])
| 售卖名称 | 上市时间 | 大小 | 流行款式名称 | 适用对象 | 款式 | 背包方式 | 质地 | 提拎部件类型 | 闭合方式 | 图案 | 有无夹层 | 箱包硬度 | 适用场景 | 品牌 | 风格 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 6576 | 6572 | 6572 | 6572 | 6068 | 6574 | 5242 | 6572 | 5770 | 6402 | 6326 | 6135 | 6271 | 6438 | 6574 | 6471 |
| unique | 5889 | 19 | 4 | 34 | 5 | 7 | 12 | 18 | 5 | 11 | 57 | 2 | 2 | 6 | 712 | 13 |
| top | 包包2016新款韩版女士单肩包时尚手提包女包小包斜挎包百搭冬季潮 | 2016年秋季 | 中 | 小方包 | 青年 | 单肩包 | 单肩斜挎手提 | PU | 软把 | 拉链 | 纯色 | 有 | 软 | 休闲 | Mexican/稻草人 | 欧美时尚 |
| freq | 9 | 1960 | 2742 | 1729 | 5767 | 3702 | 2071 | 2933 | 3442 | 3886 | 4873 | 3293 | 4634 | 6063 | 142 | 3278 |
- 售卖名称:共有5889种名称,分类过多,不利于建模。
- 上市时间:共有19种分类,其中“2016年秋季”占比最大。
- 大小:共有4中分类,“中”型女包占比最大。
- 流行款式名称:共有34种分类,“小方包”占比最大。
- 适用对象:共有5种分类,“青年”类产品最多
- 款式:共有7种分类,“单肩包”占比最多。
- 背包方式:共有12种分类,“单肩斜挎手提”占比最多。
- 质地:共有18种质地分类,“PU”类占比最大。
- 提拎部件类型:共有5种分类,“软把”占比最大。
- 闭合方式:共有11种分类,“拉链”类占比最大。
- 图案:共有57种分类,“纯色”占比最大。
- 有无夹层:2分类,有夹层较多。
- 箱包硬度:2分类,软包较多。
- 适用场景:共有6个分类,“休闲”类产品较多。
- 品牌:共有712个品牌,“Mexican/稻草人”占比最大。
- 风格:13种分类,“欧美时尚”类占比最大。
2.缺失值情况:
2.1针对单个变量:
除了售卖名称,其余变量都有不同程度的缺失。部分变量缺失数量为个位数,但有的变量缺失一千多个值,差异较大。见下表:
missing_number = data.isnull().sum().sort_values(ascending=False)
percent = (data.isnull().sum()/data.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([missing_number, percent*100], axis=1, keys=["missing_number", "Percentage"])
missing_data
| missing_number | Percentage | |
|---|---|---|
| 背包方式 | 1334 | 20.285888 |
| 促销价 | 1021 | 15.526156 |
| 提拎部件类型 | 806 | 12.256691 |
| 适用对象 | 508 | 7.725061 |
| 有无夹层 | 441 | 6.706204 |
| 箱包硬度 | 305 | 4.638078 |
| 图案 | 250 | 3.801703 |
| 闭合方式 | 174 | 2.645985 |
| 适用场景 | 138 | 2.098540 |
| 风格 | 105 | 1.596715 |
| 月销量 | 65 | 0.988443 |
| 累计评价 | 11 | 0.167275 |
| 流行款式名称 | 4 | 0.060827 |
| 大小 | 4 | 0.060827 |
| 上市时间 | 4 | 0.060827 |
| 质地 | 4 | 0.060827 |
| 价格 | 3 | 0.045620 |
| 款式 | 2 | 0.030414 |
| 品牌 | 2 | 0.030414 |
| 售卖名称 | 0 | 0.000000 |
缺失值情况:
- 小于1%:月销量、累计评价、流行款式名称、大小、上市时间、质地、价格、款式、品牌
- 1%-5%:箱包硬度、图案、闭合方式、适用场景、风格
- 5%-10%:适用对象、有无夹层
- 10%-15%:提拎部件类型
- 大于15%:背包方式、促销价
可以看到特征:“背包方式”和“促销价”的缺失值较多,超过15%,应当考虑删除。
- 考虑“促销价”:
data[["价格","促销价"]].corr()
| 价格 | 促销价 | |
|---|---|---|
| 价格 | 1.000000 | 0.871734 |
| 促销价 | 0.871734 | 1.000000 |
已知变量中,还有一个“价格”变量,通过计算线性相关系数,我们发现“价格”与“促销价”之间存在较强的正线性相关关系(0.87),而且“价格”的缺失个数仅为3个(促销价缺失1021个),所以我们剔除“促销价”,保留“价格”因素。
- 针对变量“背包方式”:
a = data["背包方式"]
b = np.log(data["月销量"])
aa = pd.concat([a,b],axis=1)
plt.figure(figsize=(5,5))
sns.boxplot(x="背包方式",y="月销量",data=aa)
plt.title("背包方式对月销量(对数变换后)的影响")
<matplotlib.text.Text at 0x6394c1fe48>

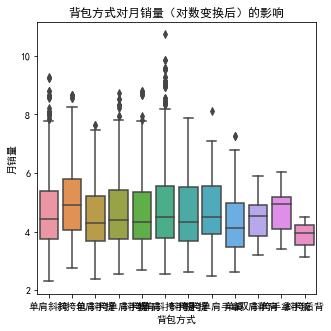
从箱线图来看,多种背包方式,对女包的月销售影响还是有的,但是考虑到其20%的缺失率,我们将对这一变量剔除。
2.2 针对每个样本的缺失值情况:
for i in range(0,21):
print(i,(data.isnull().T.apply(sum)>=i).sum())
0 6576
1 3328
2 963
3 343
4 179
5 116
6 90
7 73
8 50
9 18
10 4
11 4
12 4
13 4
14 2
15 2
16 1
17 0
18 0
19 0
20 0
- 样本数据总共有20个变量,缺失最严重的情况:某个样本共缺失16个变量值。
- 3328个样本(超过50%)都存在缺失值。
- 15%的样本缺失两个或以上的属性值。
- 缺失4个或以上属性值的样本有179个,占总样本的2.7%。
从初步观察数据来看,我们需删除变量:促销价、背包方式、售卖名称
data.drop(["促销价","背包方式","售卖名称"],axis=1,inplace=True)
data.shape
(6576, 17)
3.探究自变量对因变量的影响
3.1 价格、累计评价对月销量的影响
data1 = data.dropna()
data1 = pd.concat([np.log(data1[["价格","月销量","累计评价"]]),data1.iloc[:,3:]],axis=1)
data1.corr()
| 价格 | 月销量 | 累计评价 | |
|---|---|---|---|
| 价格 | 1.000000 | -0.148725 | -0.045426 |
| 月销量 | -0.148725 | 1.000000 | 0.605353 |
| 累计评价 | -0.045426 | 0.605353 | 1.000000 |
plt.scatter(data.价格,data.月销量)
plt.title("价格对月销量的影响")
plt.xlabel("价格")
plt.ylabel("月销量")
<matplotlib.text.Text at 0x6394d98e48>

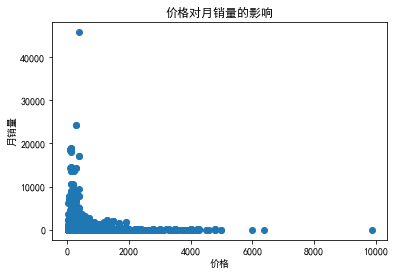
价格在做函数变换前,明显看到价格大于2000的女包,其销量普遍很差。
而1000-2000这一部分,其月销量比大于2000元的部分稍微好一点。
大概在0-500这一部分的女包,其销量普遍较好。最高的超过4000的月销量。
plt.scatter(data.累计评价,data.月销量)
plt.title("累计评价对月销量的影响")
plt.xlabel("累计评价")
plt.ylabel("月销量")
<matplotlib.text.Text at 0x6395267a58>


可以感受到,累计评价数对月销量存在一定的线性关系。可以看到有个样本的累计评价超过14万,但月销量平平,可能是淘宝刷单的数据。
评价的数量只是影响的其中一个维度,在实际购买中,评论的质量更具有指导作用。
sns.heatmap(data1.corr(),annot=True,square=True,vmax=1,vmin=-1,linewidths=0.1,cmap="RdBu")
plt.title("连续型变量之间的线性关系")
<matplotlib.text.Text at 0x6395343208>

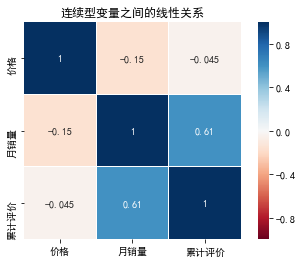
看到:
- “价格”与“月销量”的线性相关系数为-0.15,即价格越高,月销量越低,但是这种线性对应关系很弱。但也不能表明这两者之间没有其他关系,毕竟在现实中,价格对产品的销量还是存在很大影响的。保留该变量。
- “累计评价”与“月销量”的线性相关系数为0.61,即累计评价越高,月销量越高,我们保留该变量。
3.2 上市时间对月销量的影响
plt.figure(figsize=(17,5))
sns.boxplot(data1["上市时间"],data1["月销量"],data=data1)
plt.title("上市时间对月销量的影响")
<matplotlib.text.Text at 0x639545e860>

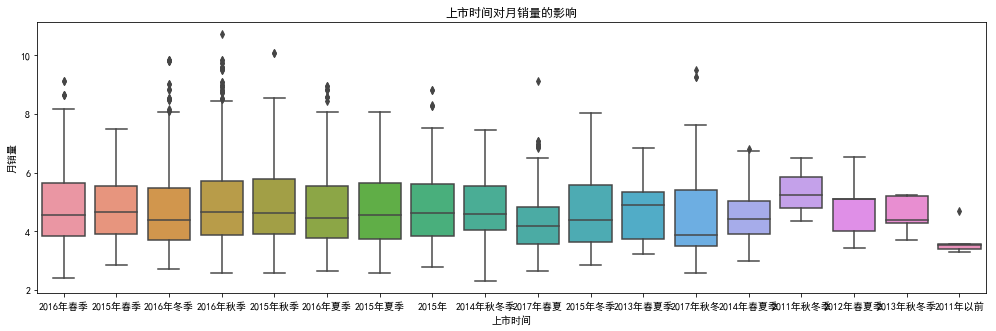
看到2015、2016年的女包产品的月销量较相近,月销量数据普遍右偏。而其他年份的产品月销量有一定的波动。其中2011年以前的产品月销量主要集中于一个小的范围内,且月销量普遍比较低。2017年秋冬的产品月销量的中位数也较低,而且她的箱体较大,即数据分布范围大,有很多大于中位数的值,存在较大的值。保留该变量。
3.2 大小对月销量的影响
data["大小"].value_counts()
中 2742
小 2548
大 927
迷你 355
Name: 大小, dtype: int64
plt.figure(figsize=(4,4))
sns.boxplot(data1["大小"],data1["月销量"],data=data1)
plt.title("大小对月销量的影响")
<matplotlib.text.Text at 0x6395a566a0>

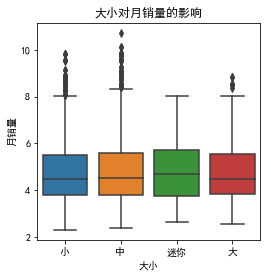
看到迷你女包的月销量中位数大于其他大小的女包,而大型女包最小。普遍有较大的月销量值,小、中的包包更是存在一定的大的异常值,这些包包的月销量较突出。实际购买,女包的大小一般会影响消费者的购买意愿,我们保留该变量。
3.3 流行款式名称对月销量的影响
data["流行款式名称"].value_counts()
小方包 1729
其他 1091
托特包 468
贝壳包 424
杀手包 320
翅膀包 282
波士顿包 239
水桶包 230
信封包 174
饺子包 153
菱格链条包 142
机车包 131
马鞍包 131
凯莉包 126
戴妃包 113
邮差包 109
小圆包 106
子母包 105
铂金包 78
新月包 75
流苏包 73
笑脸包 53
医生包 43
编织包 43
小猫包 26
褶皱包 22
玳瑁包 21
果冻包 20
潘多拉包 16
罗马包 14
法棍包 5
缪斯包 5
竹节包 3
豆豆包 2
Name: 流行款式名称, dtype: int64
plt.figure(figsize=(17,4))
sns.boxplot(data1["流行款式名称"],data1["月销量"],data=data1)
plt.title("流行款式名称对月销量的影响")
<matplotlib.text.Text at 0x63957c8550>

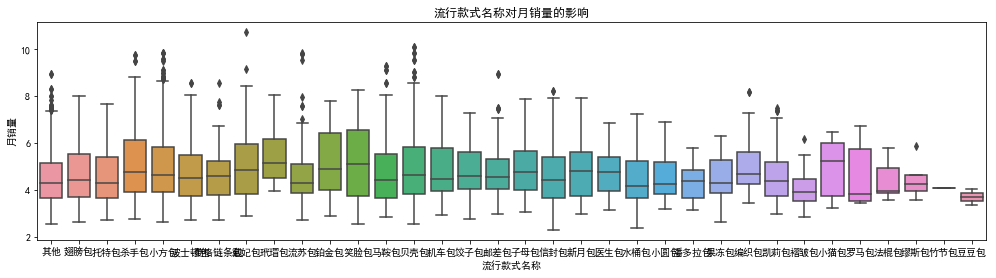
不同的流行款式对女包的月销量的影响是存在的,我们保留该变量。
3.4 适用对象对月销量的影响
data["适用对象"].value_counts()
青年 5767
中年 280
少年 19
儿童 1
老年 1
Name: 适用对象, dtype: int64
plt.figure(figsize=(4,4))
sns.boxplot(data1["适用对象"],data1["月销量"],data=data1)
plt.title("适用对象对月销量的影响")
<matplotlib.text.Text at 0x6395dd7d68>

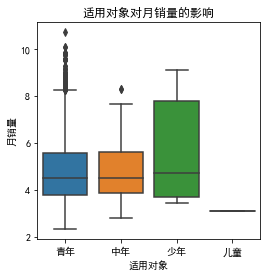
样本数据中,5767(88%)的女包为青年类产品。看到青年类产品有销量很好的产品,我们保留该变量,看针对不同年龄段的人群,女包的销量是否存在明显差异。
3.5 款式对月销量的影响
data["款式"].value_counts()
单肩包 3702
斜挎包 1540
手提包 1131
手拿包 164
胸包 26
化妆包 9
腰包 2
Name: 款式, dtype: int64
plt.figure(figsize=(7,4))
sns.boxplot(data1["款式"],data1["月销量"],data=data1)
plt.title("款式对月销量的影响")
<matplotlib.text.Text at 0x6395ed0358>

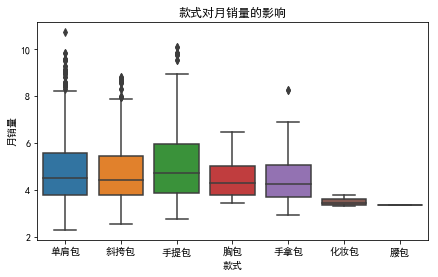
样本数据中,女包主要为单肩、斜挎、手提包。箱线图中,看到这三者的箱体、中位线位置相差不是很明显,但联系实际,在购买中,不同款式的用途不一样,我们保留该变量。
3.6 质地对月销量的影响
data["质地"].value_counts()
PU 2933
牛皮 2224
其他 503
PVC 283
帆布 183
锦纶 180
牛津纺 88
羊皮 84
涤纶 38
兔毛 20
猪皮 9
呢子 8
鳄鱼皮 7
丝绒 6
无纺布 2
麻 2
牛仔布 1
PC 1
Name: 质地, dtype: int64
plt.figure(figsize=(8,4))
sns.boxplot(data1["质地"],data1["月销量"],data=data1)
plt.title("质地对月销量的影响")
<matplotlib.text.Text at 0x6396235d68>

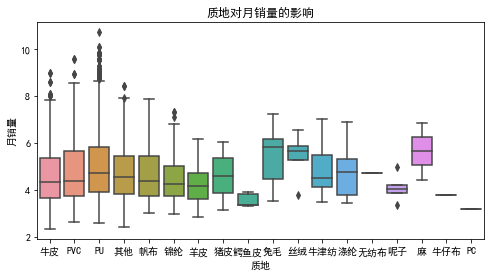
样本数据中,主要为PU和牛皮类的女包。而从箱线图来看,不同质地的女包影响女包的销量,不同的质地,月销量的中位数分布不同,箱体位置也不一样。保留该变量。
3.7 提拎部件类型对月销量的影响
data["提拎部件类型"].value_counts()
软把 3442
硬把 953
装卸式提把 697
锁链式提把 413
伸缩式提把 265
Name: 提拎部件类型, dtype: int64
plt.figure(figsize=(5,4))
sns.boxplot(data1["提拎部件类型"],data1["月销量"],data=data1)
plt.title("提拎部件类型对月销量的影响")
<matplotlib.text.Text at 0x639651d8d0>

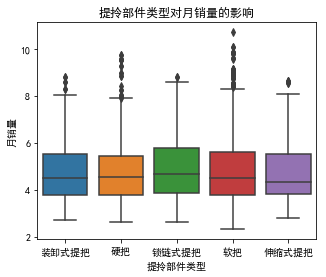
软把、硬把占大比例。而且,它们的销量表现较好,我们保留该变量。
3.8 闭合方式对月销量的影响
data["闭合方式"].value_counts()
拉链 3886
包盖式 829
锁扣 593
磁扣 556
拉链搭扣 308
抽带 84
其他 62
敞口 42
抽带锁扣 26
挂钩 11
魔术贴 5
Name: 闭合方式, dtype: int64
plt.figure(figsize=(7,4))
sns.boxplot(data1["闭合方式"],data1["月销量"],data=data1)
plt.title("闭合方式对月销量的影响")
<matplotlib.text.Text at 0x6396635a90>

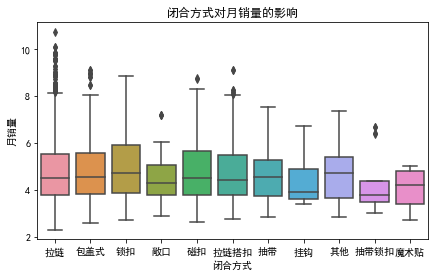
data[data["闭合方式"]=="拉链"].shape[0]/data.shape[0]
0.6151922475773679
data[data["闭合方式"]=="包盖式"].shape[0]/data.shape[0]
0.1259768677711785
样本数据中,拉链(62%)、包盖式(13%)产品占大多数。从箱线图看,拉链女包的异常值较多,它的有些销量较好,我们保留该变量。
3.9 图案对月销量的影响
data["图案"].value_counts()
纯色 4873
几何图案 319
动物图案 293
植物花卉 212
卡通动漫 193
格子 133
人物 82
文字 82
条纹 49
风景 13
拼色 7
水果 5
民族风绣片 4
图腾 4
刺绣花朵 4
字母 3
立体花纹 3
刺绣 2
铂金包 2
鳞片 2
鳄鱼纹 2
英文字母 2
菱格 2
荔枝纹 2
自然纹理 1
Running girl 1
心形图案 1
徽章 1
立体蝴蝶结 1
花猫 1
喵星人 1
蛇纹 1
圆球 花朵 1
笑脸 1
大嘴唇 1
猫咪图案、鲸鱼图案、猫咪耳朵 1
冰激凌 1
油蜡 1
文字、人物、动物、风景等图案 1
彩虹色 1
花朵贴皮 1
撞色 1
红唇 1
热气球 1
贝壳包 1
刺绣蜻蜓 1
超人图案 1
鳄鱼纹 蛇纹 1
爱心小鸟 1
海锚 1
压花 1
艺术学院 1
鸵鸟纹 1
大象纹 1
石头纹 1
镭射料皮层 1
口红、五星 1
Name: 图案, dtype: int64
plt.figure(figsize=(8,4))
sns.boxplot(data1["图案"],data1["月销量"],data=data1)
plt.title("图案对月销量的影响")
<matplotlib.text.Text at 0x639682beb8>

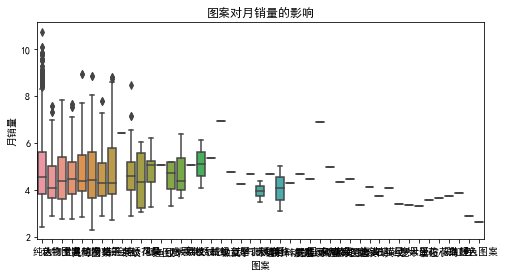
从样本数据中,排名前三的图案为:纯色(74%)、几何(5%)、动物(4%)。不同图案,对女包的月销量存在影响。在实际选购中,图案的影响是很重要的。保留该变量。
3.10 有无夹层对月销量的影响
data["有无夹层"].value_counts()
有 3293
无 2842
Name: 有无夹层, dtype: int64
plt.figure(figsize=(3,4))
sns.boxplot(data1["有无夹层"],data1["月销量"],data=data1)
plt.title("有无夹层对月销量的影响")
<matplotlib.text.Text at 0x6396e7bc88>

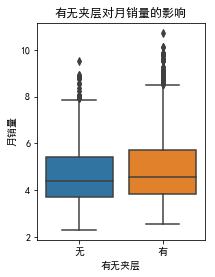
有夹层的女包超过50%。从箱线图,看出有夹层的女包销量比无夹层的好一点,我们保留该变量。
3.11 箱包硬度对月销量的影响
data["箱包硬度"].value_counts()
软 4634
硬 1637
Name: 箱包硬度, dtype: int64
plt.figure(figsize=(4,4))
sns.boxplot(data1["箱包硬度"],data1["月销量"],data=data1)
plt.title("箱包硬度对月销量的影响")
<matplotlib.text.Text at 0x6396f77f98>


看到软硬女包的箱体、中位线位置相近,我们剔除该变量。
3.12 适用场景对月销量的影响
data["适用场景"].value_counts()
休闲 6063
宴会 236
商务 101
其他 22
旅行 13
运动 3
Name: 适用场景, dtype: int64
plt.figure(figsize=(5,4))
sns.boxplot(data1["适用场景"],data1["月销量"],data=data1)
plt.title("适用场景对月销量的影响")
<matplotlib.text.Text at 0x63970381d0>


在6576个样本数据中,6063个为休闲类的包包(占92%)。再从箱线图来看,排名前三的:休闲、宴会、商务类包包,它们的箱体位置、中位数很接近,表明其50%的月销量数据比较接近。我们选择剔除此变量。
3.12 品牌对月销量的影响
data["品牌"].value_counts()
Mexican/稻草人 142
北包包 125
JONBAG/简·佰格 124
JUST STAR/欧时纳 103
toutou 92
沐鱼 87
A-ZA/阿札 84
Zooler/朱尔 79
代代花枳 79
MICHERR/米榭尔 77
Viney 76
HONGU/红谷 75
TUCANO/啄木鸟 67
御匠坊 63
薇纯 62
资黛 62
伊诗黛 61
MISS MUSI/暮思小姐 61
FOXER/金狐狸 61
CHARLES&KEITH 60
ELLE 55
凡思曼 54
ZARA 53
MAKEV 53
EMINI HOUSE/伊米妮 50
mood/妙迪 50
Danny Bear/丹尼熊 49
GOOT&DIYA/古缇蒂亚 48
La Festin/拉菲斯汀 48
D.BLACK/黑眼袋袋 47
...
Chareiharper/香奈哈泼 1
GIOVANNI VALENTINO/卓凡尼·华伦天奴 1
其季 1
Mbaoyuan/麦包园 1
火狐 1
圣茵娜 1
Disney/迪士尼 1
TONRIN/彤琳 1
枫莲丽 1
Vihus/威浩 1
露比妮 1
枫雅千代 1
俏皮郎 1
欧缇路 1
copione/科皮妮 1
XUNZIHANDWORK/薰子手工 1
LDK/路迪克 1
云朵工厂 1
L.B.CRAZY/爱包狂 1
欧贝姿 1
奈雯 1
flower season&rainy season/花季雨季 1
Tottyblu 1
杰凡喜 1
宾尼兔 1
杰利凯利 1
E·FREIER/伊菲儿 1
Puluo-vik/普洛维淇 1
DU DU 1
CASGOOTE/查斯·古特 1
Name: 品牌, Length: 712, dtype: int64
plt.figure(figsize=(100,4))
sns.boxplot(data1["品牌"],data1["月销量"],data=data1)
plt.title("品牌对月销量的影响")
<matplotlib.text.Text at 0x63981ae7f0>


总共有712个品牌,从箱线图看到品牌影响女包的月销量,我们保留该变量。
3.12 风格对月销量的影响
data["风格"].value_counts()
欧美时尚 3278
日韩 1724
时尚潮流 689
复古 217
甜美淑女 216
卡通 99
小清新 73
民族风 66
商务/OL 62
学院 24
运动 15
其他 7
摇滚 1
Name: 风格, dtype: int64
plt.figure(figsize=(8,4))
sns.boxplot(data1["风格"],data1["月销量"],data=data1)
plt.title("风格对月销量的影响")
<matplotlib.text.Text at 0x639db87d30>


样本中,欧美时尚(接近50%)、日韩(26%)、时尚潮流(10%)的产品占了主导。不同风格也是影响销量的一个重要因素,我们保留该变量。
二.清洗数据&数据规约
2.1 剔除上述不必要的变量
data.columns
Index(['价格', '月销量', '累计评价', '上市时间', '大小', '流行款式名称', '适用对象', '款式', '质地',
'提拎部件类型', '闭合方式', '图案', '有无夹层', '箱包硬度', '适用场景', '品牌', '风格'],
dtype='object')
data.drop(["箱包硬度","适用场景"],axis=1,inplace=True)
data.columns
Index(['价格', '月销量', '累计评价', '上市时间', '大小', '流行款式名称', '适用对象', '款式', '质地',
'提拎部件类型', '闭合方式', '图案', '有无夹层', '品牌', '风格'],
dtype='object')
2.2 剔除一定的样本
2.2.1 剔除”月销量“缺失的样本
data["月销量"].isnull().sum()
65
月销量有缺失的样本为65个,我们剔除这些样本。
data = data[data["月销量"].notnull()]
data.shape
(6511, 15)
2.2.2 剔除样本缺失值较多的样本
for i in range(16):
print(i,(data.isnull().T.sum()>=i).sum())
0 6511
1 1437
2 417
3 192
4 113
5 73
6 47
7 3
8 3
9 3
10 3
11 1
12 1
13 0
14 0
15 0
剔除样本缺失值等于4个或大于4个的样本。
data = data[(data.notnull().T.sum())>=12]
data.shape
(6398, 15)
2.3 补填缺失值
data.isnull().sum()
价格 0
月销量 0
累计评价 8
上市时间 0
大小 0
流行款式名称 0
适用对象 427
款式 0
质地 0
提拎部件类型 695
闭合方式 81
图案 152
有无夹层 324
品牌 0
风格 20
dtype: int64
- 分类变量:用占比最多的一类作为填补值
- 连续型变量:用中位数插补
data["累计评价"] = data["累计评价"].fillna(275)
data.mode()
| 价格 | 月销量 | 累计评价 | 上市时间 | 大小 | 流行款式名称 | 适用对象 | 款式 | 质地 | 提拎部件类型 | 闭合方式 | 图案 | 有无夹层 | 品牌 | 风格 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 299.0 | 32.0 | 11.0 | 2016年秋季 | 中 | 小方包 | 青年 | 单肩包 | PU | 软把 | 拉链 | 纯色 | 有 | Mexican/稻草人 | 欧美时尚 |
data.fillna({"适用对象":"青年","提拎部件类型":"软把","闭合方式":"拉链","图案":"纯色","有无夹层":"有","风格":"欧美时尚"},inplace=True)
| 价格 | 月销量 | 累计评价 | 上市时间 | 大小 | 流行款式名称 | 适用对象 | 款式 | 质地 | 提拎部件类型 | 闭合方式 | 图案 | 有无夹层 | 品牌 | 风格 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 998.0 | 1231.0 | 14720.0 | 2016年春季 | 小 | 其他 | 青年 | 单肩包 | 牛皮 | 装卸式提把 | 拉链 | 纯色 | 无 | ELLE | 欧美时尚 |
| 1 | 1169.0 | 771.0 | 1132.0 | 2016年夏季 | 大 | 杀手包 | 青年 | 手提包 | 牛皮 | 软把 | 拉链 | 纯色 | 无 | HONGU/红谷 | 欧美时尚 |
| 2 | 469.0 | 340.0 | 147.0 | 2016年冬季 | 小 | 小方包 | 青年 | 单肩包 | PU | 软把 | 磁扣 | 纯色 | 无 | CHARLES&KEITH | 欧美时尚 |
| 3 | 469.0 | 330.0 | 97.0 | 2016年冬季 | 小 | 小方包 | 青年 | 单肩包 | PU | 软把 | 磁扣 | 纯色 | 无 | CHARLES&KEITH | 欧美时尚 |
| 4 | 799.0 | 1276.0 | 7642.0 | 2015年春季 | 中 | 翅膀包 | 青年 | 斜挎包 | 牛皮 | 硬把 | 包盖式 | 纯色 | 无 | JESSIE&JANE | 欧美时尚 |
| 5 | 599.0 | 130.0 | 132.0 | 2016年冬季 | 迷你 | 其他 | 青年 | 单肩包 | 牛皮 | 锁链式提把 | 锁扣 | 人物 | 无 | EMINI HOUSE/伊米妮 | 欧美时尚 |
| 6 | 1798.0 | 127.0 | 325.0 | 2016年秋季 | 大 | 托特包 | 青年 | 单肩包 | 牛皮 | 装卸式提把 | 拉链 | 纯色 | 无 | VANESSA HOGAN | 欧美时尚 |
| 7 | 849.0 | 180.0 | 437.0 | 2015年秋季 | 中 | 杀手包 | 青年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | DILAKS | 欧美时尚 |
| 8 | 1699.0 | 129.0 | 469.0 | 2016年秋季 | 中 | 小方包 | 青年 | 斜挎包 | 牛皮 | 软把 | 拉链 | 动物图案 | 无 | bampo/半坡饰族 | 甜美淑女 |
| 9 | 1398.0 | 141.0 | 1931.0 | 2016年春季 | 小 | 波士顿包 | 青年 | 手提包 | PVC | 软把 | 拉链 | 文字 | 无 | Fion/菲安妮 | 欧美时尚 |
| 10 | 1790.0 | 104.0 | 869.0 | 2016年春季 | 小 | 菱格链条包 | 青年 | 单肩包 | 牛皮 | 锁链式提把 | 锁扣 | 纯色 | 无 | Dissona | 欧美时尚 |
| 11 | 1298.0 | 133.0 | 335.0 | 2016年秋季 | 小 | 翅膀包 | 青年 | 斜挎包 | PVC | 软把 | 包盖式 | 几何图案 | 无 | WHY | 甜美淑女 |
| 12 | 1498.0 | 53.0 | 45.0 | 2016年冬季 | 迷你 | 小方包 | 青年 | 斜挎包 | 牛皮 | 软把 | 锁扣 | 纯色 | 无 | KHDESIGN/明治 | 欧美时尚 |
| 13 | 225.0 | 2243.0 | 1662.0 | 2016年冬季 | 中 | 杀手包 | 青年 | 手提包 | PU | 硬把 | 拉链 | 纯色 | 无 | A-ZA/阿札 | 时尚潮流 |
| 14 | 249.0 | 326.0 | 280.0 | 2016年冬季 | 小 | 翅膀包 | 青年 | 斜挎包 | 其他 | 装卸式提把 | 包盖式 | 纯色 | 无 | JONBAG/简·佰格 | 时尚潮流 |
| 15 | 1380.0 | 1746.0 | 6491.0 | 2016年春季 | 中 | 其他 | 青年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | Zooler/朱尔 | 欧美时尚 |
| 16 | 95.0 | 18531.0 | 6451.0 | 2016年冬季 | 中 | 小方包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | 伊诗黛 | 日韩 |
| 17 | 428.0 | 1353.0 | 6183.0 | 2016年夏季 | 中 | 其他 | 青年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | Viney | 欧美时尚 |
| 18 | 794.0 | 1842.0 | 1324.0 | 2016年夏季 | 大 | 杀手包 | 青年 | 手提包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | oimei | 欧美时尚 |
| 19 | 598.0 | 3035.0 | 6401.0 | 2015年秋季 | 中 | 杀手包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | Mexican/稻草人 | 欧美时尚 |
| 20 | 288.0 | 1300.0 | 444.0 | 2016年冬季 | 中 | 托特包 | 青年 | 单肩包 | 牛皮 | 软把 | 敞口 | 纯色 | 有 | vvmi/维维米 | 欧美时尚 |
| 21 | 558.0 | 2113.0 | 9179.0 | 2015年夏季 | 大 | 戴妃包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | Mexican/稻草人 | 欧美时尚 |
| 22 | 239.0 | 5694.0 | 7960.0 | 2016年春季 | 小 | 小方包 | 青年 | 斜挎包 | PU | 伸缩式提把 | 锁扣 | 纯色 | 有 | 凡思曼 | 甜美淑女 |
| 23 | 299.0 | 3084.0 | 31369.0 | 2016年冬季 | 中 | 玳瑁包 | 青年 | 单肩包 | PU | 软把 | 拉链 | 纯色 | 有 | doodoo | 欧美时尚 |
| 24 | 1495.0 | 2006.0 | 7338.0 | 2016年冬季 | 中 | 杀手包 | 青年 | 手提包 | 牛皮 | 伸缩式提把 | 拉链 | 纯色 | 有 | GOOT&DIYA/古缇蒂亚 | 欧美时尚 |
| 25 | 159.0 | 337.0 | 110.0 | 2016年冬季 | 中 | 小方包 | 青年 | 单肩包 | PU | 软把 | 磁扣 | 立体花纹 | 有 | toutou | 时尚潮流 |
| 26 | 129.0 | 18100.0 | 3720.0 | 2016年冬季 | 小 | 流苏包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | 茜秀 | 欧美时尚 |
| 27 | 298.0 | 2145.0 | 1595.0 | 2016年冬季 | 中 | 小方包 | 青年 | 斜挎包 | PU | 硬把 | 拉链 | 卡通动漫 | 无 | JUST STAR/欧时纳 | 日韩 |
| 28 | 399.0 | 71.0 | 25.0 | 2016年秋季 | 大 | 其他 | 青年 | 手提包 | 牛皮 | 软把 | 拉链 | 植物花卉 | 有 | Pmsix | 复古 |
| 29 | 1030.0 | 809.0 | 9043.0 | 2015年秋季 | 中 | 杀手包 | 中年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | 老人头 | 欧美时尚 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6546 | 1790.0 | 104.0 | 870.0 | 2016年春季 | 小 | 菱格链条包 | 青年 | 单肩包 | 牛皮 | 锁链式提把 | 锁扣 | 纯色 | 无 | Dissona | 欧美时尚 |
| 6547 | 1498.0 | 54.0 | 45.0 | 2016年冬季 | 迷你 | 小方包 | 青年 | 斜挎包 | 牛皮 | 软把 | 锁扣 | 纯色 | 无 | KHDESIGN/明治 | 欧美时尚 |
| 6548 | 225.0 | 2258.0 | 1677.0 | 2016年冬季 | 中 | 杀手包 | 青年 | 手提包 | PU | 硬把 | 拉链 | 纯色 | 无 | A-ZA/阿札 | 时尚潮流 |
| 6549 | 249.0 | 331.0 | 281.0 | 2016年冬季 | 小 | 翅膀包 | 青年 | 斜挎包 | 其他 | 装卸式提把 | 包盖式 | 纯色 | 无 | JONBAG/简·佰格 | 时尚潮流 |
| 6550 | 1380.0 | 1735.0 | 6497.0 | 2016年春季 | 中 | 其他 | 青年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | Zooler/朱尔 | 欧美时尚 |
| 6551 | 428.0 | 1360.0 | 6191.0 | 2016年夏季 | 中 | 其他 | 青年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | Viney | 欧美时尚 |
| 6552 | 95.0 | 18654.0 | 6562.0 | 2016年冬季 | 中 | 小方包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | 伊诗黛 | 日韩 |
| 6553 | 239.0 | 5723.0 | 7991.0 | 2016年春季 | 小 | 小方包 | 青年 | 斜挎包 | PU | 伸缩式提把 | 锁扣 | 纯色 | 有 | 凡思曼 | 甜美淑女 |
| 6554 | 794.0 | 1866.0 | 1337.0 | 2016年夏季 | 大 | 杀手包 | 青年 | 手提包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | oimei | 欧美时尚 |
| 6555 | 159.0 | 340.0 | 112.0 | 2016年冬季 | 中 | 小方包 | 青年 | 单肩包 | PU | 软把 | 磁扣 | 立体花纹 | 有 | toutou | 时尚潮流 |
| 6556 | 598.0 | 3080.0 | 6420.0 | 2015年秋季 | 中 | 杀手包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | Mexican/稻草人 | 欧美时尚 |
| 6557 | 558.0 | 2121.0 | 9198.0 | 2015年夏季 | 大 | 戴妃包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | Mexican/稻草人 | 欧美时尚 |
| 6558 | 299.0 | 3098.0 | 31391.0 | 2016年冬季 | 中 | 玳瑁包 | 青年 | 单肩包 | PU | 软把 | 拉链 | 纯色 | 有 | doodoo | 欧美时尚 |
| 6559 | 1495.0 | 2022.0 | 7340.0 | 2016年冬季 | 中 | 杀手包 | 青年 | 手提包 | 牛皮 | 伸缩式提把 | 拉链 | 纯色 | 有 | GOOT&DIYA/古缇蒂亚 | 欧美时尚 |
| 6560 | 298.0 | 2166.0 | 1606.0 | 2016年冬季 | 中 | 小方包 | 青年 | 斜挎包 | PU | 硬把 | 拉链 | 卡通动漫 | 无 | JUST STAR/欧时纳 | 日韩 |
| 6561 | 288.0 | 1322.0 | 451.0 | 2016年冬季 | 中 | 托特包 | 青年 | 单肩包 | 牛皮 | 软把 | 敞口 | 纯色 | 有 | vvmi/维维米 | 欧美时尚 |
| 6562 | 399.0 | 72.0 | 25.0 | 2016年秋季 | 大 | 其他 | 青年 | 手提包 | 牛皮 | 软把 | 拉链 | 植物花卉 | 有 | Pmsix | 复古 |
| 6563 | 129.0 | 18443.0 | 3849.0 | 2016年冬季 | 小 | 流苏包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | 茜秀 | 欧美时尚 |
| 6564 | 1030.0 | 822.0 | 9017.0 | 2015年秋季 | 中 | 杀手包 | 中年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | 老人头 | 欧美时尚 |
| 6565 | 89.8 | 1229.0 | 887.0 | 2016年冬季 | 小 | 小方包 | 青年 | 手提包 | PU | 软把 | 包盖式 | 卡通动漫 | 无 | 七公主 | 日韩 |
| 6566 | 289.0 | 85.0 | 47.0 | 2016年冬季 | 中 | 其他 | 青年 | 斜挎包 | 牛皮 | 硬把 | 拉链 | 纯色 | 有 | MISS MUSI/暮思小姐 | 日韩 |
| 6567 | 278.0 | 2472.0 | 25259.0 | 2016年夏季 | 小 | 铂金包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 无 | D.BLACK/黑眼袋袋 | 欧美时尚 |
| 6568 | 256.0 | 293.0 | 79.0 | 2016年秋季 | 中 | 小方包 | 青年 | 单肩包 | 牛皮 | 硬把 | 锁扣 | 几何图案 | 有 | Vikosen/威科什 | 日韩 |
| 6569 | 588.0 | 1047.0 | 3282.0 | 2016年秋季 | 中 | 托特包 | 青年 | 单肩包 | 牛皮 | 硬把 | 拉链 | 几何图案 | 有 | FOXER/金狐狸 | 欧美时尚 |
| 6570 | 388.0 | 202.0 | 53.0 | 2016年冬季 | 大 | 其他 | 青年 | 单肩包 | 牛皮 | 软把 | 拉链 | 纯色 | 有 | 莫妮芬 | 欧美时尚 |
| 6571 | 288.0 | 3086.0 | 4103.0 | 2016年秋季 | 大 | 其他 | 青年 | 单肩包 | PU | 软把 | 拉链 | 纯色 | 有 | 伊莲 | 欧美时尚 |
| 6572 | 199.0 | 239.0 | 47.0 | 2017年春夏 | 迷你 | 小方包 | 青年 | 单肩包 | PU | 软把 | 磁扣 | 纯色 | 有 | Westlink/西遇 | 欧美时尚 |
| 6573 | 135.0 | 533.0 | 126.0 | 2017年春夏 | 中 | 小方包 | 青年 | 斜挎包 | PU | 软把 | 锁扣 | 纯色 | 有 | 黛薇拉 | 欧美时尚 |
| 6574 | 189.0 | 10515.0 | 20648.0 | 2016年夏季 | 小 | 小方包 | 青年 | 单肩包 | PU | 软把 | 包盖式 | 纯色 | 无 | Somay | 时尚潮流 |
| 6575 | 229.0 | 1672.0 | 2443.0 | 2016年夏季 | 中 | 小方包 | 青年 | 手提包 | PU | 软把 | 拉链 | 纯色 | 有 | 纳丝语 | 时尚潮流 |
6398 rows × 15 columns
2.4 对连续型变量做对数变换
transformed_num = np.log(data[data.describe().columns])
transformed_num.describe()
| 价格 | 月销量 | 累计评价 | |
|---|---|---|---|
| count | 6398.000000 | 6398.000000 | 6398.000000 |
| mean | 5.716856 | 4.771208 | -inf |
| std | 0.894600 | 1.315311 | NaN |
| min | 2.890372 | 2.302585 | -inf |
| 25% | 5.123964 | 3.761200 | 4.317488 |
| 50% | 5.700444 | 4.465908 | 5.661221 |
| 75% | 6.308098 | 5.517453 | 7.116800 |
| max | 9.197052 | 10.731799 | 11.888419 |
累计评价存在负无穷值,需要去除对应的样本。
2.5 整理自变量、因变量
all_data = pd.concat([transformed_num,data.iloc[:,3:]],axis=1)
all_data.shape
(6398, 15)
all_data_noinf = all_data[all_data["累计评价"]>=0] #剔除累计评价中带有负无穷值的样本
all_data_noinf.shape
(6388, 15)
xx = all_data_noinf.drop(["月销量"],axis=1)
yy = all_data_noinf["月销量"]
print("自变量:",xx.shape)
print("因变量:",yy.shape)
自变量: (6388, 14)
因变量: (6388,)
xx = pd.get_dummies(xx)
print("Final自变量:",xx.shape)
print("Final因变量:",yy.shape)
Final自变量: (6388, 878)
Final因变量: (6388,)
三.建模
选择用Gradient Boosting Decision Tree(GBDT) 和随机森林
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.model_selection import KFold, cross_val_score, train_test_split
from sklearn.metrics import mean_squared_error,mean_absolute_error
from sklearn import cross_validation, metrics
from sklearn.grid_search import GridSearchCV
F:Anacondalibsite-packagessklearncross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
F:Anacondalibsite-packagessklearngrid_search.py:42: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. This module will be removed in 0.20.
DeprecationWarning)
x_train, x_test, y_train, y_test = train_test_split(xx, yy, test_size=0.3, random_state=2019)
3.1 随机森林
MSE = []
estimators = range(50,500,10)
for num in estimators:
RFregressor = RandomForestRegressor(n_estimators=num, oob_score=True, max_depth=6, max_features='sqrt',
min_samples_split=50, min_samples_leaf=15,random_state=100)
RFregressor.fit(x_train,y_train)
y_pred = RFregressor.predict(x_test)
MSE.append(mean_squared_error(y_test,y_pred))
plt.plot(estimators,MSE)
plt.xlabel("弱学习器决策树的数量")
plt.ylabel("MSE")
<matplotlib.text.Text at 0x639fb16d68>

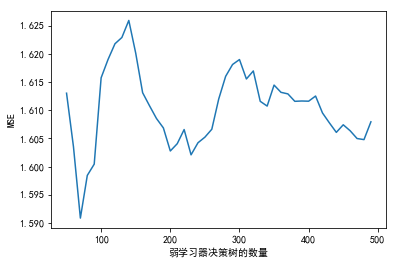
在50-100间,存在较小的均方误差,下面继续调整:
MSE = []
estimators = range(50,100,5)
for num in estimators:
RFregressor = RandomForestRegressor(n_estimators=num, oob_score=True, max_depth=6, max_features='sqrt',
min_samples_split=50, min_samples_leaf=15,random_state=100)
RFregressor.fit(x_train,y_train)
y_pred = RFregressor.predict(x_test)
MSE.append(mean_squared_error(y_test,y_pred))
plt.plot(estimators,MSE)
plt.xlabel("弱学习器决策树的数量")
plt.ylabel("MSE")
<matplotlib.text.Text at 0x639eeb29b0>

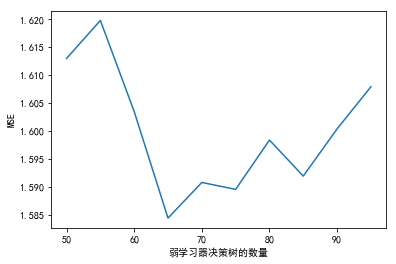
把弱学习器个数定到60-70之间:
MSE = []
estimators = range(50,71)
for num in estimators:
RFregressor = RandomForestRegressor(n_estimators=num, oob_score=True, max_depth=6, max_features='sqrt',
min_samples_split=50, min_samples_leaf=15,random_state=100)
RFregressor.fit(x_train,y_train)
y_pred = RFregressor.predict(x_test)
MSE.append(mean_squared_error(y_test,y_pred))
plt.plot(estimators,MSE)
plt.xlabel("弱学习器决策树的数量")
plt.ylabel("MSE")
<matplotlib.text.Text at 0x639fbf3940>


将弱学习器的个数定为63,做随机森林:
RFregressor_final = RandomForestRegressor(n_estimators=63, oob_score=True, max_depth=6, max_features='sqrt',
min_samples_split=50, min_samples_leaf=15,random_state=100)
RFregressor_final.fit(x_train,y_train)
y_pred = RFregressor.predict(x_test)
print("均方误差为:",mean_squared_error(y_test,y_pred))
均方误差为: 1.59085648039
接下来看各自特征的重要性:
feature_importance_RF = RFregressor_final.feature_importances_
feature_importance_RF_trans = feature_importance_RF / (feature_importance_RF.max())
Index_sorted = np.argsort(feature_importance_RF_trans) #将特征按重要性从小到大排序,得到特征对应的索引的排序(从小到大)
bar_position = np.arange(Index_sorted.shape[0]) + 0.5
plt.figure(figsize=(7,6))
bar_position = np.arange(20) + 0.5
plt.barh(bar_position, feature_importance_RF_trans[Index_sorted][-20:], align="center")
plt.yticks(bar_position, xx.columns[Index_sorted][-20:])
plt.xlabel("属性重要性")
plt.title("前20个重要特征")
<matplotlib.text.Text at 0x639fc9d8d0>


3.2 GBDT(Gradient Boosting Decision Tree)
MSE_GBDT = []
est = range(60,2000,50)
for num in est:
GBDT = GradientBoostingRegressor(n_estimators=num, learning_rate=0.05, max_depth=6, max_features="sqrt",
min_samples_split=50, min_samples_leaf=15, loss="huber", random_state=100)
GBDT.fit(x_train,y_train)
y_pred = GBDT.predict(x_test)
MSE_GBDT.append(mean_squared_error(y_test,y_pred))
plt.plot(est, MSE_GBDT)
plt.xlabel("弱学习器决策树的数量")
plt.ylabel("MSE")
<matplotlib.text.Text at 0x63a00039b0>

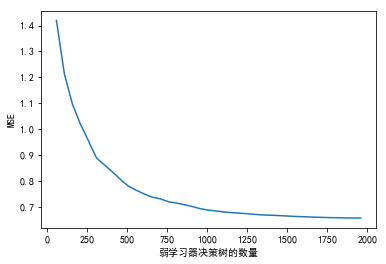
MSE_GBDT = []
est = range(1500,3001,50)
for num in est:
GBDT = GradientBoostingRegressor(n_estimators=num, learning_rate=0.05, max_depth=6, max_features="sqrt",
min_samples_split=50, min_samples_leaf=15, loss="huber", random_state=100)
GBDT.fit(x_train,y_train)
y_pred = GBDT.predict(x_test)
MSE_GBDT.append(mean_squared_error(y_test,y_pred))
plt.plot(est, MSE_GBDT)
plt.xlabel("弱学习器决策树的数量")
plt.ylabel("MSE")
<matplotlib.text.Text at 0x63a011ca90>

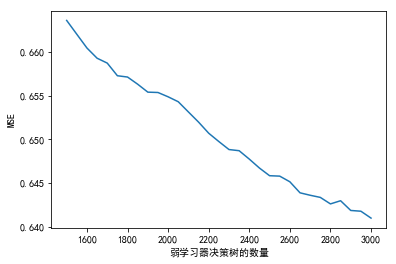
MSE_GBDT = []
est = range(2800,4001,50)
for num in est:
GBDT = GradientBoostingRegressor(n_estimators=num, learning_rate=0.05, max_depth=6, max_features="sqrt",
min_samples_split=50, min_samples_leaf=15, loss="huber", random_state=100)
GBDT.fit(x_train,y_train)
y_pred = GBDT.predict(x_test)
MSE_GBDT.append(mean_squared_error(y_test,y_pred))
plt.plot(est, MSE_GBDT)
plt.xlabel("弱学习器决策树的数量")
plt.ylabel("MSE")
<matplotlib.text.Text at 0x63a021eac8>

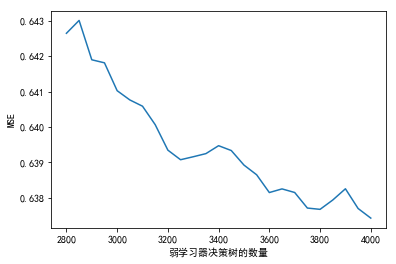
考虑到运行时间,我们取弱学习器数量为3800:
GBDT_final = GradientBoostingRegressor(n_estimators=3800, learning_rate=0.05, max_depth=6, max_features="sqrt",
min_samples_split=50, min_samples_leaf=15, loss="huber", random_state=100)
GBDT_final.fit(x_train,y_train)
y_pred = GBDT_final.predict(x_test)
print("均方误差为:",mean_squared_error(y_test,y_pred))
均方误差为: 0.637675471294
feature_importance_GB = GBDT_final.feature_importances_
feature_importance_GB_trans = feature_importance_GB / (feature_importance_GB.max())
Index_sorted_GB = np.argsort(feature_importance_GB_trans) #将特征按重要性从小到大排序,得到特征对应的索引的排序(从小到大)
plt.figure(figsize=(7,6))
bar_position_GB = np.arange(20) + 0.5
plt.barh(bar_position_GB, feature_importance_GB_trans[Index_sorted_GB][-20:], align="center")
plt.yticks(bar_position_GB, xx.columns[Index_sorted_GB][-20:])
plt.xlabel("属性重要性")
plt.title("前20个重要特征")
<matplotlib.text.Text at 0x63a04a3390>

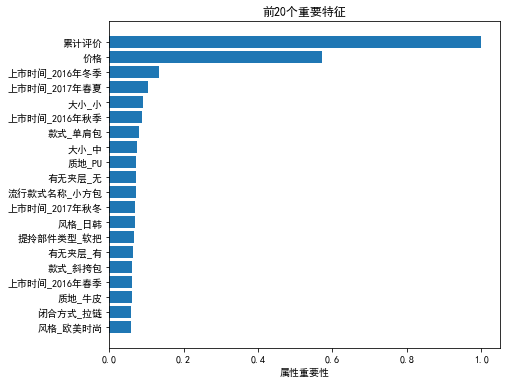
四.总结:
1.从上面两个图中,我们看到前20个影响月销量的因素。其中,在878个特征中,累计评价与价格对月销量的影响最大。
- 针对累计评价,商家在店铺运营中,要注重让买家参与商品的评论,并且提高评论的内容质量。给潜在的买家营造一种该款女包销量好、火爆的的景象,起到吸引消费者的作用。再者,通过评论内容(文字、图片、视频),可以让潜在消费者提前感受到女包的使用体验,让买家有代入感,更具真实感,某种程度上,更能促进消费者的购买欲望。
- 针对价格,根据品牌的调性,商家主要推出500元以下的产品。根据二八定理,商家可推出少量价格较高、质量较好的产品,主要还是研究主要的消费群体的审美、消费习惯、消费能力,根据其需求,推出新产品。
2.其次,在质地方面,PU和牛皮都入选前20特征。而且,相对来说,PU质地的女包更占优势。商家可优先考虑这两种材质的女包作销售,其次,还可选择羊皮类的产品作产品。
3.流行款式方面,小方包相对其他款更具优势。
4.上市时间方面,2016、2017的产品相对较早的产品,月销量更高。实际商铺运营中,陈年的产品要注意及时处理,在过季时及时作一定的优惠、促销活动,吸引消费者及时消耗掉这批产品。网络时代,消费者的审美变化很快,如果商家不及时淘汰过季产品,赶不上消费者的口味变化,则在最终影响营收,造成损失。
5.款式方面,单肩包与手提包对应的月销量也相对较高。在女性群体中,这两类产品应用场景也比较多,实用性比较强,所以卖家可以多推出此类产品。
6.品牌方面,凡思曼、黑眼袋袋、沐鱼产品的月销量相对较好。
7.风格方面,日韩、欧美系列的产品月销量也相对较高。
8.大小方面,小包、中包的月销量更好,在推出新款中,商家可多推出这两类产品。
9.女包的闭合方式方面,拉链类产品更具优势。
10.图案方面,纯色产品更能让消费者剁手。在推出新图案吸引消费者的同时,不妨考虑经典、耐看的纯色产品,保证一定量的店铺月销量。
11.我们从样本中,看到女包多种多样,其款式、风格、图案等因素的分类多得尤为让人眼花缭乱。这反映了当今时代,女性消费者对个性化的追求,希望通过女包来表达她的一个对生活的态度。不排除部分女性希望通过身上的配饰来吸引别人的眼光,得到别人的赞许。商家可适时地推出一两款款式新颖的女包,给消费者一种新颖的感觉。在平时要注重抖音、小红书、微博的热点,关注一些KOL,及时蹭热点,推出款式类似、相近的女包。
12.在店铺的营运中,要巧妙利用直播、社群来留住我们的用户。打造一个有温度的社区,在社群中,及时发布新品发布信息、活动信息、优惠信息、销售排行版、缺货补货信息,分享店铺下期新品趋势、卖家旅游动态、选品动态、一些潮流资讯、服装搭配技巧,让消费者觉得这是一个活的、有用的、真实的、能找到存在感的社区,提高用户的留存。平时多与买家互动,对于售前售后的疑问及时做出解答,树立形象。提高用户的黏着性,才有后期的转化动作。
13.打造一个有品牌、有自己格调的店铺,专注于一定的群体,最好针对20-35岁的女性群体。这部分人有一定的经济能力,且对美的追求是有很强劲的需求的。商家可以到小红书、微博等平台,做一个官方的宣传或者是以普通卖家的身份对女包产品进行点评,给广大女性群体种草,或者借助自己店铺中的顾客,给予一定的奖励(免费送某款包包、半价等)来到这些平台分享女包。注重售后的反馈,收集卖家的意见(以问卷调查,给予一定的选项),来不断优化店铺的运营方式,实现更高的创收。
五.反思
- 对numpy、pandas的操作更为熟练,作图方面,同时作多图需补起来。
- 对数据出现偏态的处理能力有待提高。
- 最后调参过程中,用GridsearchCV调参耗时过长,没有调出来,后面再尝试用此法调参,看效果如何。