调节Executor堆外内存
概述: Spark底层shuffle的传输方式是使用netty传输,netty在进行网络传输的过程会申请堆外 内存(netty是零拷贝),所以使用了堆外内存。
什么时候需要调节Executor的堆外内存大小?
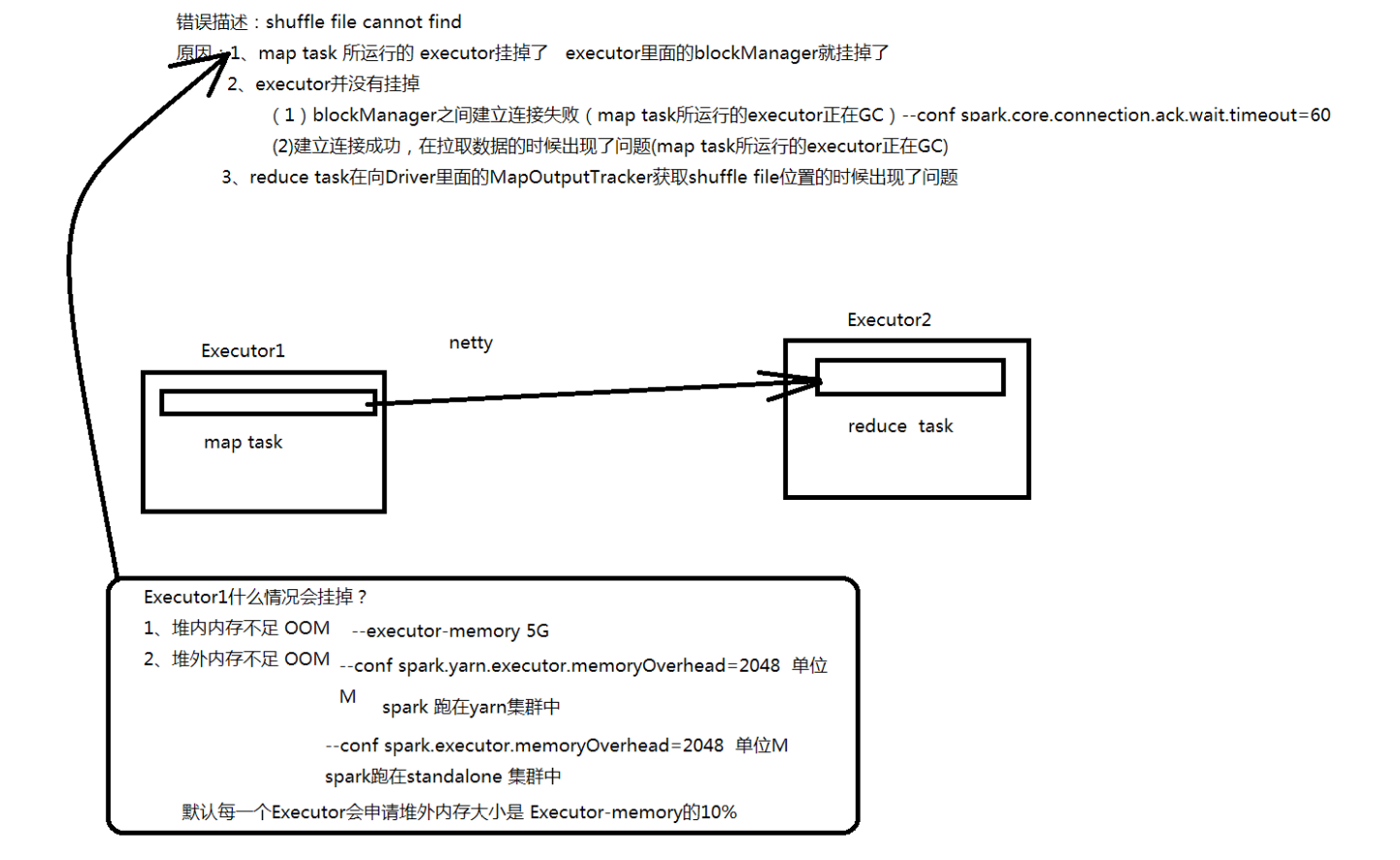
shuffle file cannot find (DAGScheduler,resubmitting task)
executor lost
task lost
out of memory
问题原因: Executor由于内存不足或者堆外内存不足了,挂掉了,对应的Executor上面的block manager也挂掉了,找不到对应的shuffle map output文件,Reducer端不能够拉取数 据 Executor并没有挂掉,而是在拉取数据的过程出现了问题 上述情况下,就可以去考虑调节一下executor的堆外内存。也许就可以避免报错; 解决办法: yarn下: --conf spark.yarn.executor.memoryOverhead=2048 单位M standlone下:--conf spark.executor.memoryOverhead=2048单位M
默认情况下,这个堆外内存上限默认是每一个executor的内存大小的10%;真正处理大数据的时候, 这里都会出现问题,导致spark作业反复崩溃,无法运行;此时就会去调节这个参数,到至少1G (1024M),甚至说2G、4G
调节等待时长 executor在进行shuffle write,优先从自己本地关联的BlockManager中获取某份数据如果本地 block manager没有的话,那么会通过TransferService,去远程连接其他节点上executor的block manager去获取,尝试建立远程的网络连接,并且去拉取数据 频繁的让JVM堆内存满溢,进行垃圾回收。正好碰到那个exeuctor的JVM在垃圾回收。处于垃圾回 收过程中,所有的工作线程全部停止;相当于只要一旦进行垃圾回收,spark / executor停止工作, 无法提供响应,spark默认的网络连接的超时时长,是60s;如果卡住60s都无法建立连接的话,那 么这个task就失败了。 解决?--conf spark.core.connection.ack.wait.timeout=300