简介
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。DataX采用了框架 + 插件 的模式,目前已开源,代码托管在github。
DataX安装部署及小试
1.下载压缩包:
下载页面地址:https://github.com/alibaba/DataX 在页面中【Quick Start】--->【Download DataX下载地址】进行下载。下载后的包名:datax.tar.gz。解压后{datax}目录下有{bin conf job lib log log_perf plugin script tmp}几个目录。
2.安装
将下载后的压缩包直接解压后可用,前提是对应的java及python环境满足要求。
System Requirements:
Linux
JDK(1.6以上,推荐1.6)
Python(推荐Python2.6.X)一定要为python2,因为后面执行datax.py的时候,里面的python的print会执行不了,导致运行不成功,会提示你print语法要加括号,python2中加不加都行 python3中必须要加,否则报语法错
Apache Maven 3.x (Compile DataX)
测试:
json的读写两端可以去github上进行截取自己需要的代码。
https://github.com/alibaba/DataX
虽然在使用之前花费的不少的时间去研究json的写法,但是传输速度真的要比sqoop的传输速度要快很多。
1、编写json文件,去这个github上截取自己锁需要的read和write,我这里需要的是mysqlreader 和 hdfswriter,拼起来是下面的代码(需要修改自己数据库,对应的表名,ip地址,对应的字段及其类型,以及hdfs上的字段名,分隔符)在对应的md下面有各个参数介绍,根据自己需要进行修改添加。(注意,这里要现在hive中进行建表,对应字段和类型,不然会出现我下面的报错)
{ "job": { "setting": { "speed": { "channel": 3 }, "errorLimit": { "record": 0, "percentage": 0.02 } }, "content": [ { "reader": { "name": "mysqlreader", "parameter": { "username": "root", "password": "123456", "column": [ "id", "name", "age", "gender", "clazz" ], "splitPk": "clazz", "connection": [ { "table": [ "student_zeng" ], "jdbcUrl": [ "jdbc:mysql://192.168.230.20:3306/test" ] } ] } }, "writer": { "name": "hdfswriter", "parameter": { "defaultFS": "hdfs://192.168.230.20:9000", "fileType": "text", "path": "/user/hive/warehouse/test.db/dataX_hdfs", "fileName": "dataX_hdfs", "column": [ { "name": "id", "type": "INT" }, { "name": "name", "type": "VARCHAR" }, { "name": "age", "type": "INT" }, { "name": "gender", "type": "VARCHAR" }, { "name": "clazz", "type": "VARCHAR" } ], "writeMode": "append", "fieldDelimiter": "," } } } ] } }
2、去安装dataX的bin目录下执行命令:
python datax.py /usr/local/soft/a_data_shujia006/test/flumedata/mysql_hdfs.json
注意:
python datax.py 加上你的json文件的绝对路径
3、因为我漏了在hdfs上建表,所以,我报了如下的错误:
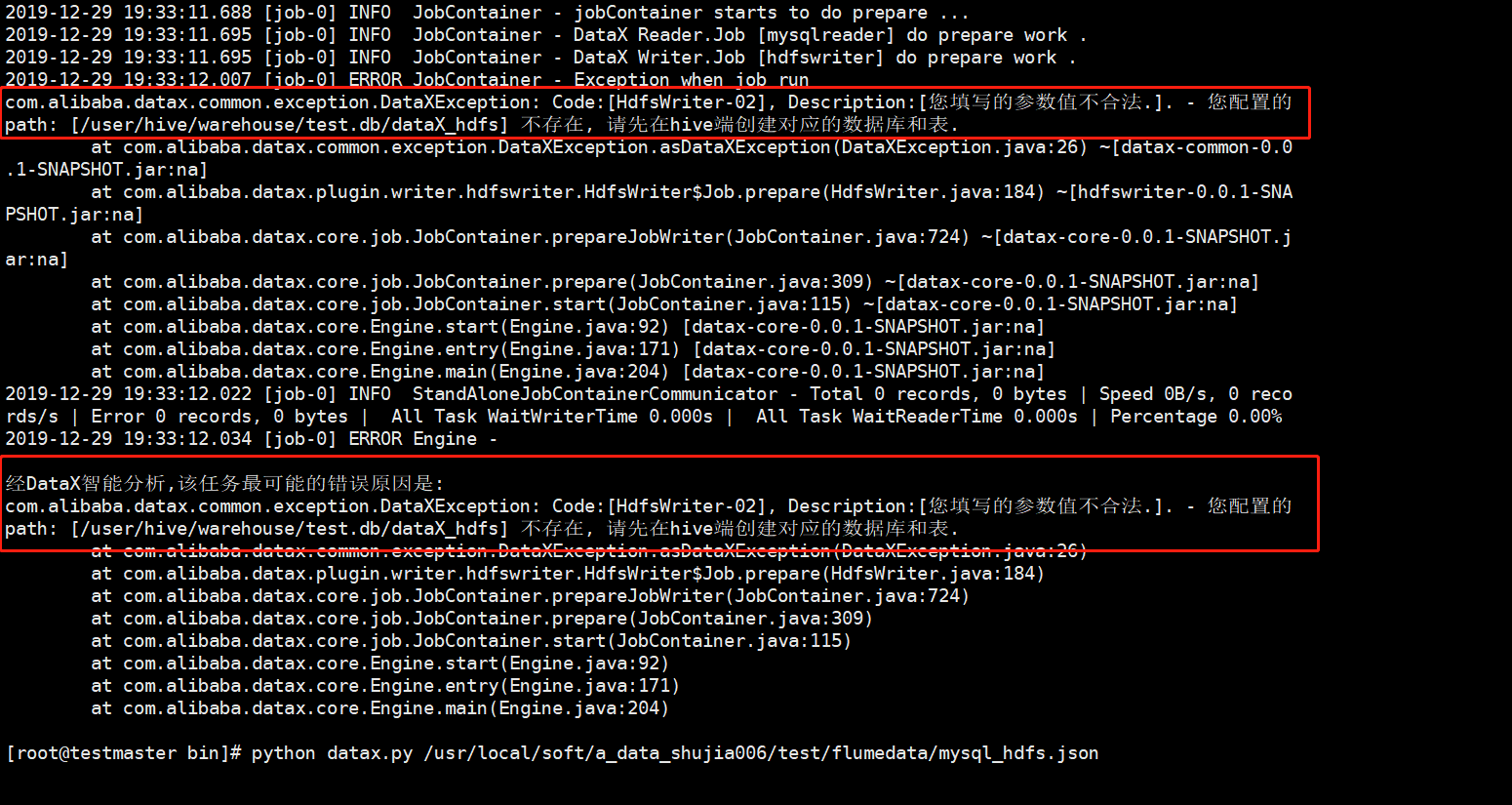
4、所以我又在hive中建表,建表语句如下:(注意对应类型)
CREATE EXTERNAL TABLE IF NOT EXISTS dataX_hdfs( id BIGINT , name STRING , age INT , gender STRING , clazz STRING ) comment '学生表' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE
5、再执行一遍,如下图:(看到这样的结果就说明执行成功)

6、查看HDFS网页
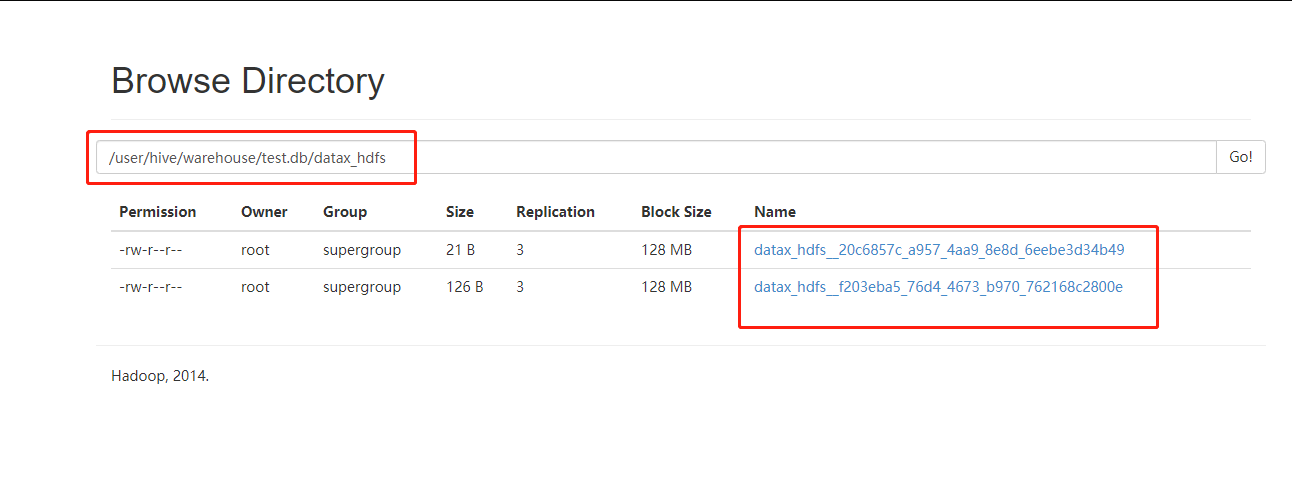
7、查看内容

8、结果发现,虽然将数据上传了,但是这个分区和结果不是我们想要的,可能是因为json的参数没有设置好。
