本文是针对Zero-Shot(ZSSR)的缺点做出的一些改进。虽然ZSSR提出了利用内部信息,采用无监督的方式进行SR,但缺点在于其测试时间过长。本文提出的MZSR将元学习和ZSSR结合,同时利用内部和外部信息,可以在几个gradient update中就输出比较好的结果。
元学习一般分为两个部分:meta-training, meta-test,目的是训练一个模型使其能最好地适应一个任务分布$p(T)$ (i.e. 对于$p(T)$中的各种任务模型都能快速适应)。meta-training的目的是优化base-learner,使其可以适应多种不同的任务。meta-test的目的是使meta-learner可以快速调整以适应新的任务。目前比较好的方法使MAML。
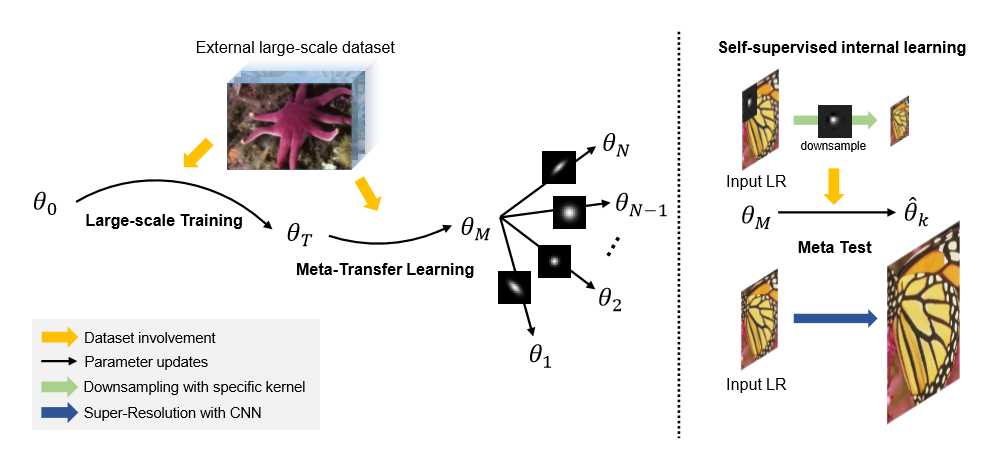
本文提出的方法分为三个步骤:large-scale training, meta-transfer learning, meta-test
large-scale training阶段,首先使用DIV2K作为数据集用bicubic的方法生成对应的$(I_{HR} I_{LR}^{bic})$对,来训练一个网络$L^D( heta)=E_{Dsim(I_{HR}, I_{LR}^{bic})}$$[||I_{HR}-f_{ heta}(I_{LR}^{bic})||_1]}$
meta-transfer learning阶段使用一个外部的数据集$D_{mate}:(I_{HR}, I_{LR}^k)$其中包含了多种不同的核产生的LR图像。并且进一步划分为$D_{tr}:task-level training, D_{te}:task-level test$
meta-test则直接使用ZSSR,进行internal learning。
完整的算法流程如下:


实验:
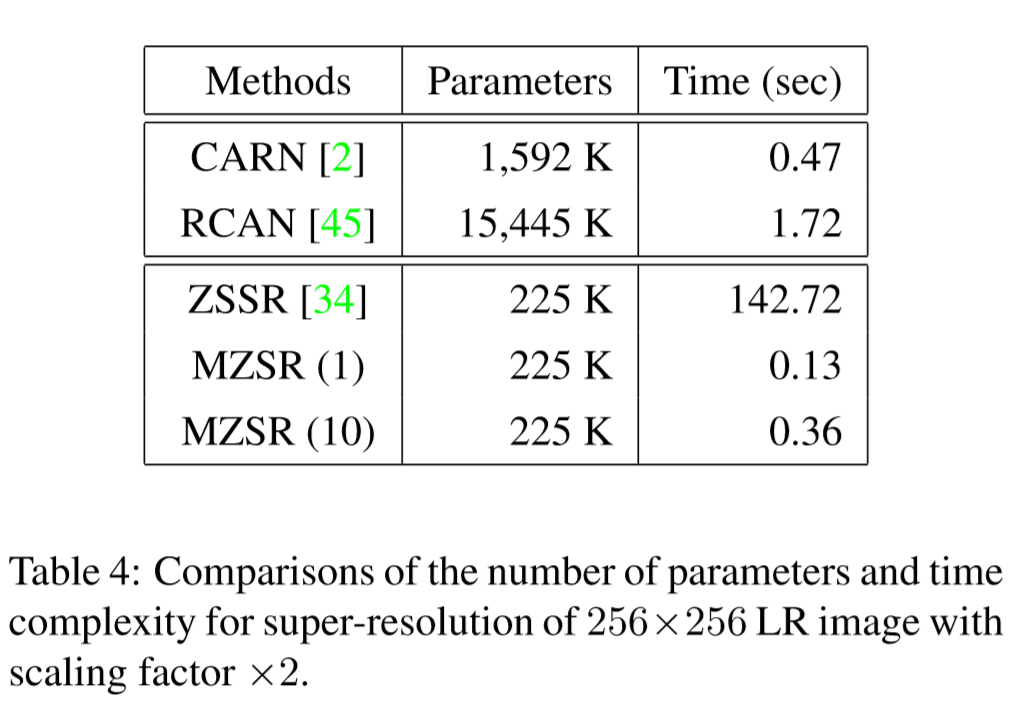
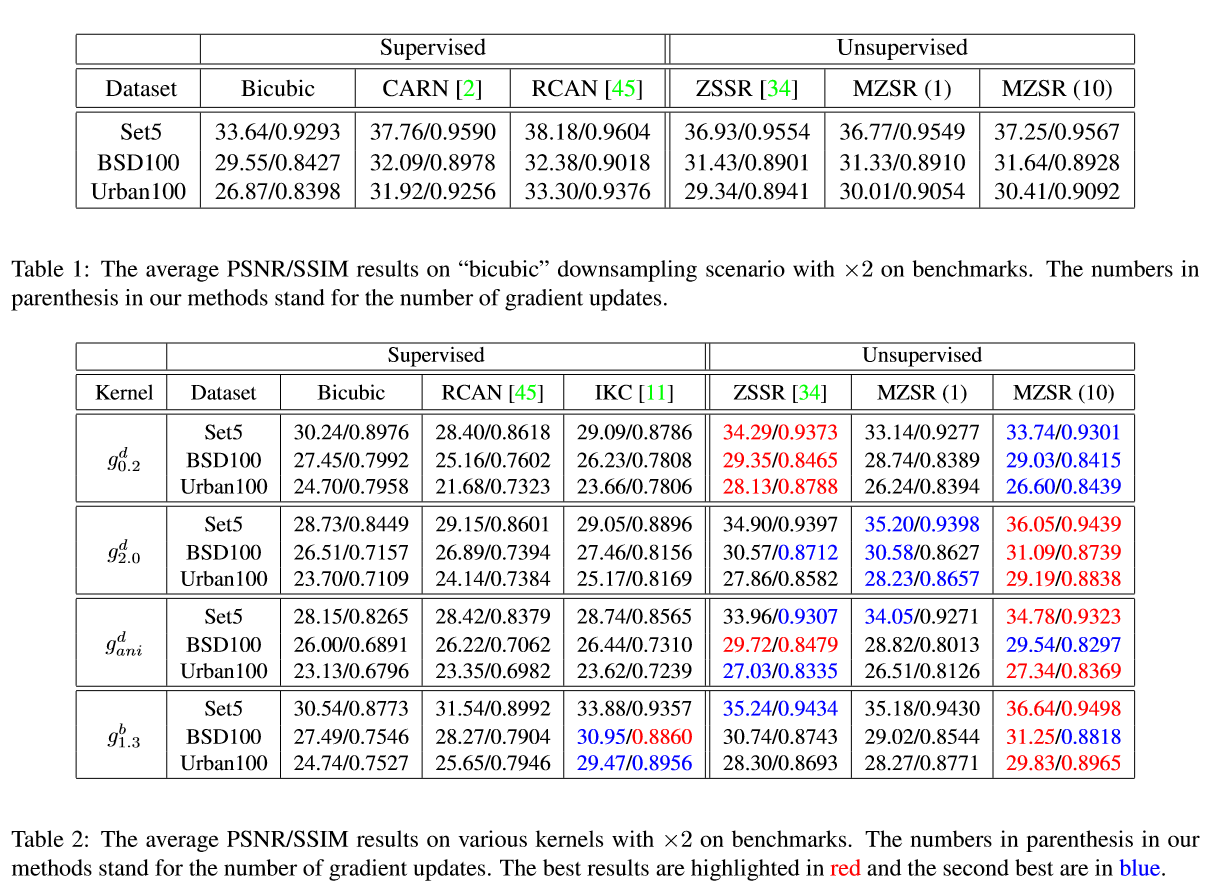
- 分别测试了在标准bicubic情况下和其他4种blur kernel情况下(severe aliasing, isotropic Gaussian, unisotropic Gaussian, isotropic Gaussian followed by bicubic subsampling)。在后面四种情况下目前的SOTA RCAN、IKC等表现都下降很多。
- 比较了几个模型表现随迭代数的变化。可以弹道MZSR最初的表现使很差的,但是可以在一次迭代后迅速适应。并且gradient update iterations越多表现的提升越多。
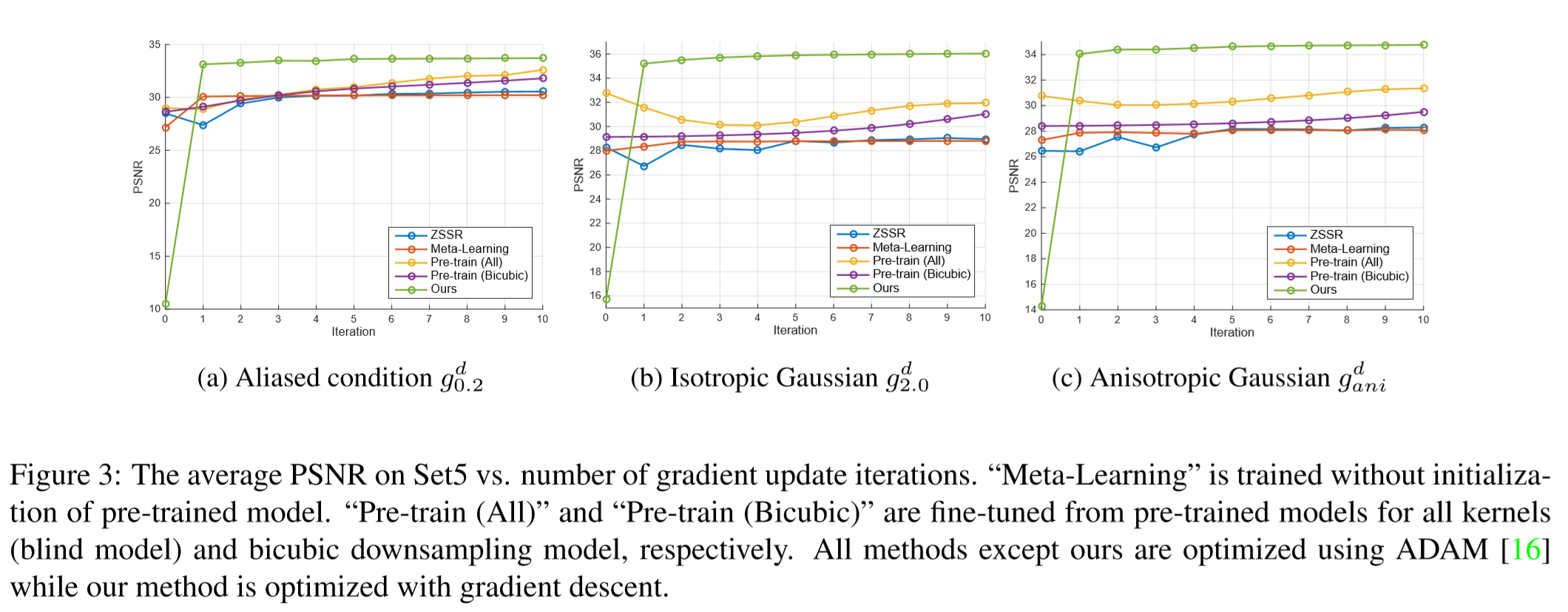
- 比较了CARN,RCAN,ZSSR,MZSR(1),MZSR(10)的参数量和预测时间。MZSR的参数量只有RCAN的约七十分之一,与ZSSR接近。而测试时所需时间又远小于ZSSR,与CARN接近。