随着MySQL MGR的版本的升级以及技术成熟,在把MHA拉下神坛之后, MGR越来越成为MySQL高可用的首选方案。
MGR的搭建并不算很复杂,但是有一系列手工操作步骤,为了简便MGR的搭建和故障诊断,这里完成了一个自动化的脚本,来实现MGR的自动化搭建,自动化故障诊断以及修复。
MGR自动化搭建
为了简便起见,这里以单机多实例的模式进行测试,
先装好三个MySQL实例,端口号分别是7001,7002,7003,其中7001作为写节点,其余两个节点作为读节,8000节点是笔者的另外一个测试节点,请忽略。
在指明主从节点的情况下,如下为mgr_tool.py一键搭建MGR集群的测试demo

MGR故障模拟1
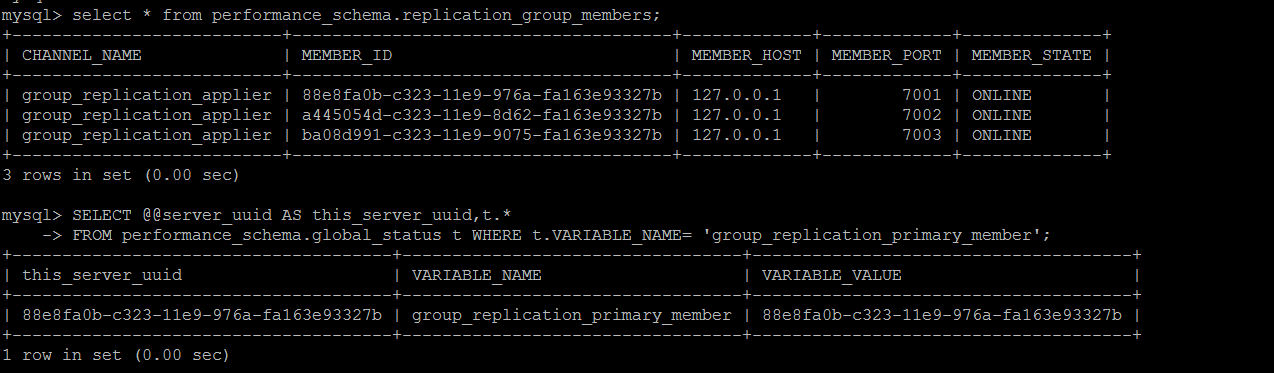
MGR节点故障自动监测和自愈实现,如下是搭建完成后的MGR集群,目前集群处于完全正常的状态中。
主观造成主从节点间binlog的丢失
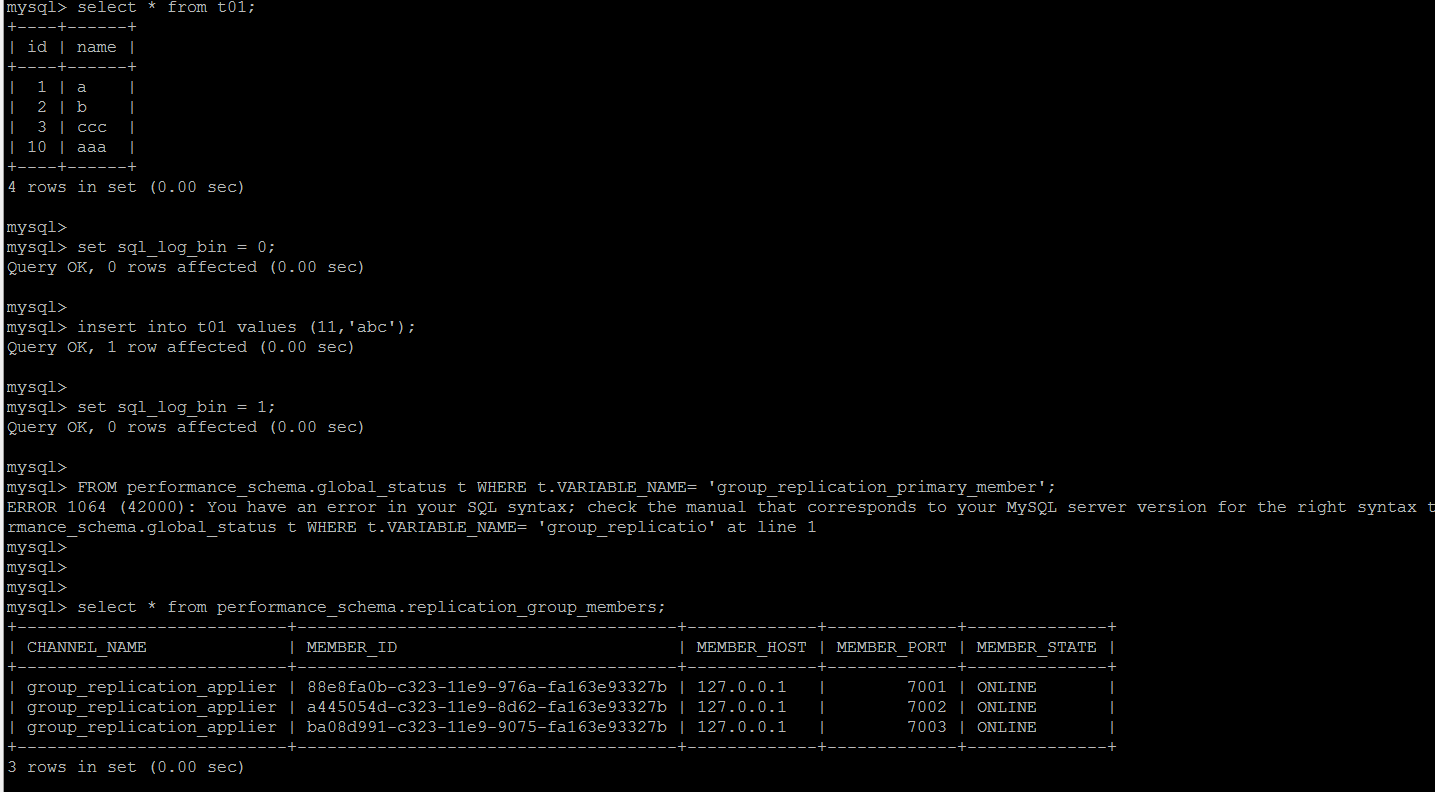
在主节点上对于对于从节点丢失的数据操作,GTID无法找到对应的数据,组复制立马熄火
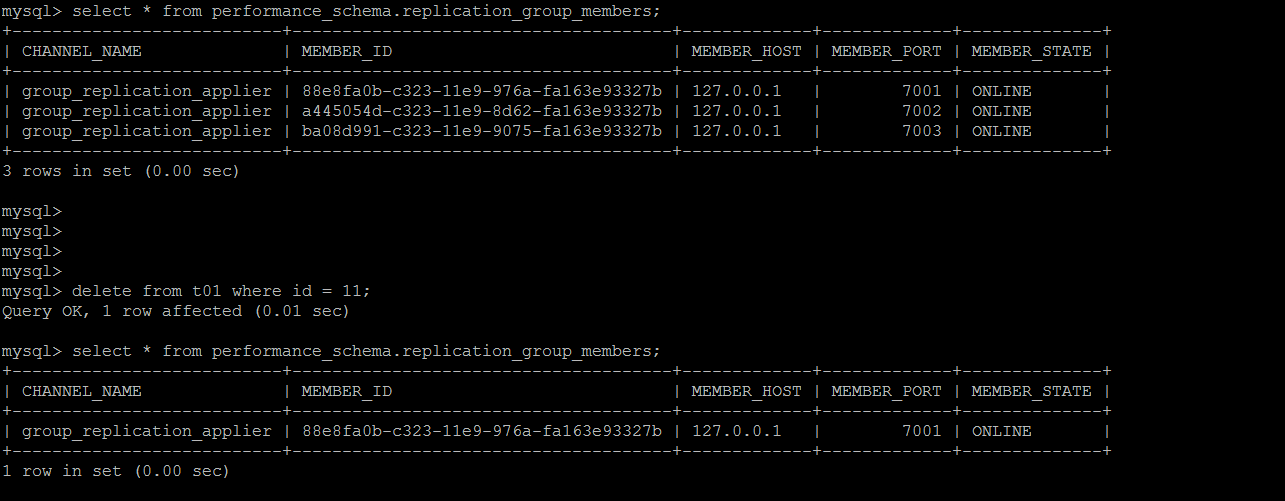
非写入节点出现错误
看下errorlog
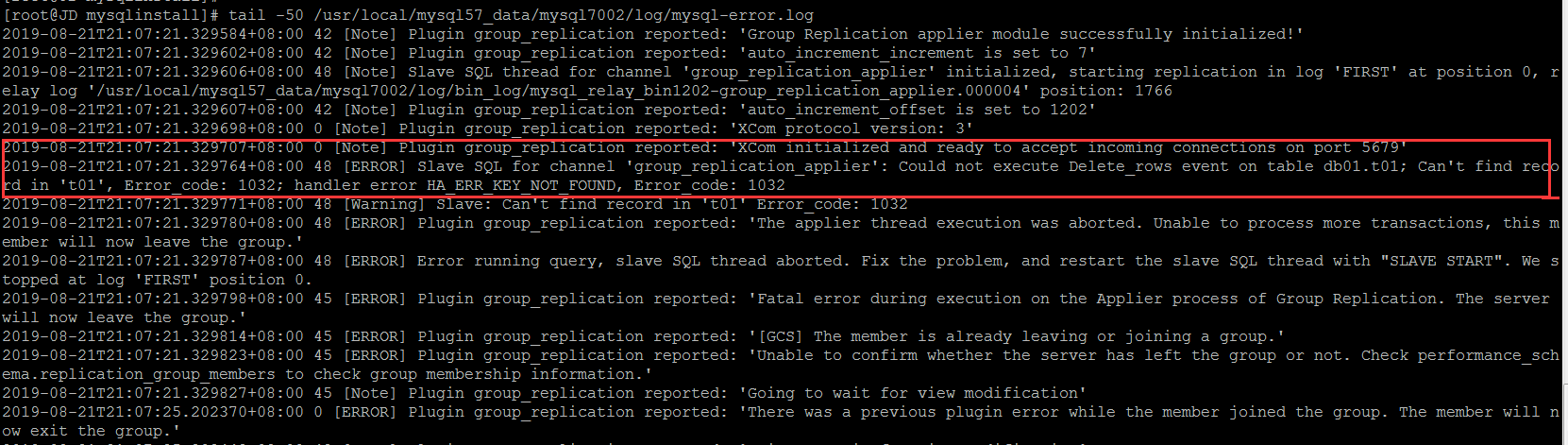
如果是手动解决的话,还是GTID跳过错误事物的套路,master上的GTID信息

尝试跳过最新的一个事物ID,然后重新连接到组,可以正常连接到组,另外一个节点仍旧处于error状态
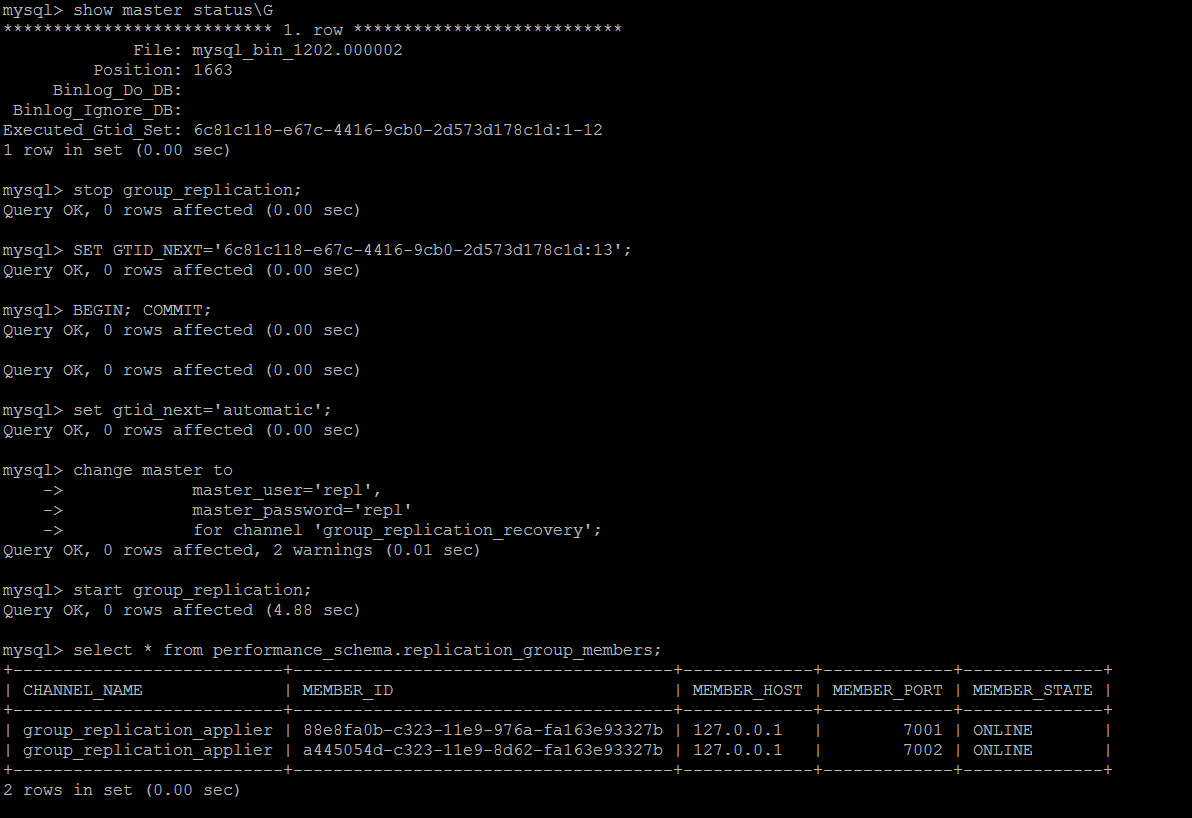
另外一个节点类似,依次解决。
MGR故障模拟2
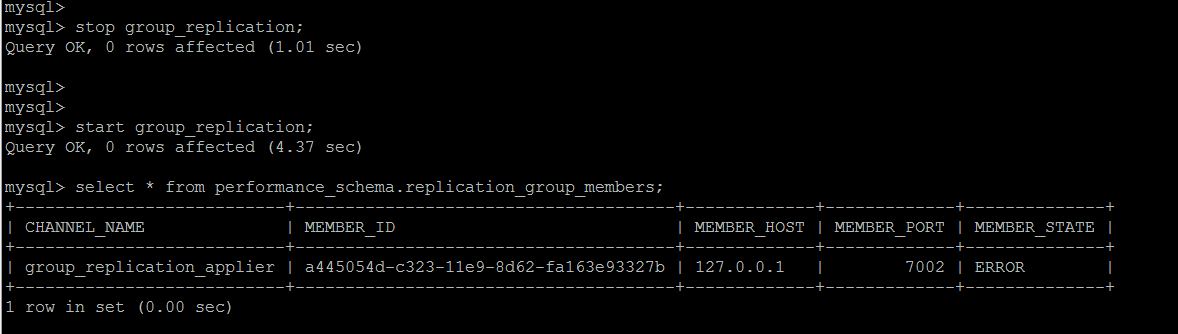
从节点脱离Group
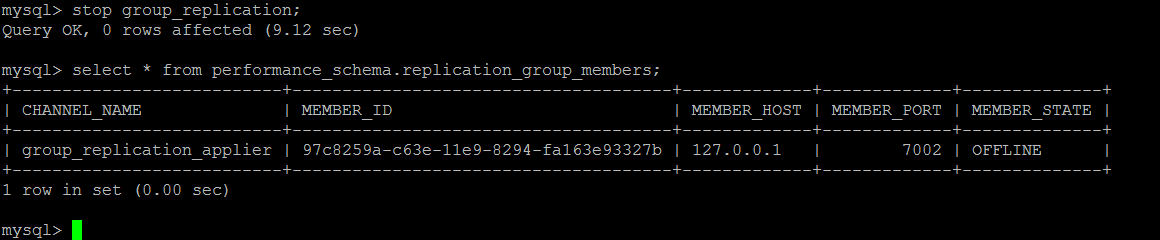
这种情况倒是比较简单,重新开始组复制即可,start group_replication
MGR故障自动检测和修复
对于如上的两种情况,
1,如果是从节点丢失主节点的事物,尝试在从节点上跳过GTID,重新开始复制即可
2,如果是从节点非丢失主节点事物,尝试在从节点重新开始组复制即可
实现代码如下
def auto_fix_mgr_error(conn_master_dict,conn_slave_dict): group_replication_status = get_group_replication_status(conn_slave_dict) if(group_replication_status[0]["MEMBER_STATE"]=="ERROR" or group_replication_status[0]["MEMBER_STATE"] == "OFFLINE"): print(conn_slave_dict["host"]+str(conn_slave_dict["port"])+'------>'+group_replication_status[0]["MEMBER_STATE"]) print("auto fixing......") while 1 > 0: master_gtid_list = get_gtid(conn_master_dict) slave_gtid_list = get_gtid(conn_slave_dict) master_executed_gtid_value = int((master_gtid_list[-1]["Executed_Gtid_Set"]).split("-")[-1]) slave_executed_gtid_value = int(slave_gtid_list[-1]["Executed_Gtid_Set"].split("-")[-1]) slave_executed_gtid_prefix = slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[0] slave_executed_skiped_gtid = slave_executed_gtid_value + 1 if (master_executed_gtid_value > slave_executed_gtid_value): print("skip gtid and restart group replication,skiped gtid is " + slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[-1].split("-")[0] + ":"+str(slave_executed_skiped_gtid)) slave_executed_skiped_gtid = slave_executed_gtid_prefix+":"+str(slave_executed_skiped_gtid) skip_gtid_on_slave(conn_slave_dict,slave_executed_skiped_gtid) time.sleep(10) start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break else: start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break elif (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("mgr cluster is normal,nothing to do") check_replication_group_members(conn_slave_dict)
对于故障类型1,GTID事物不一致的自动化修复

对于故障类型2从节点offline的自动化修复
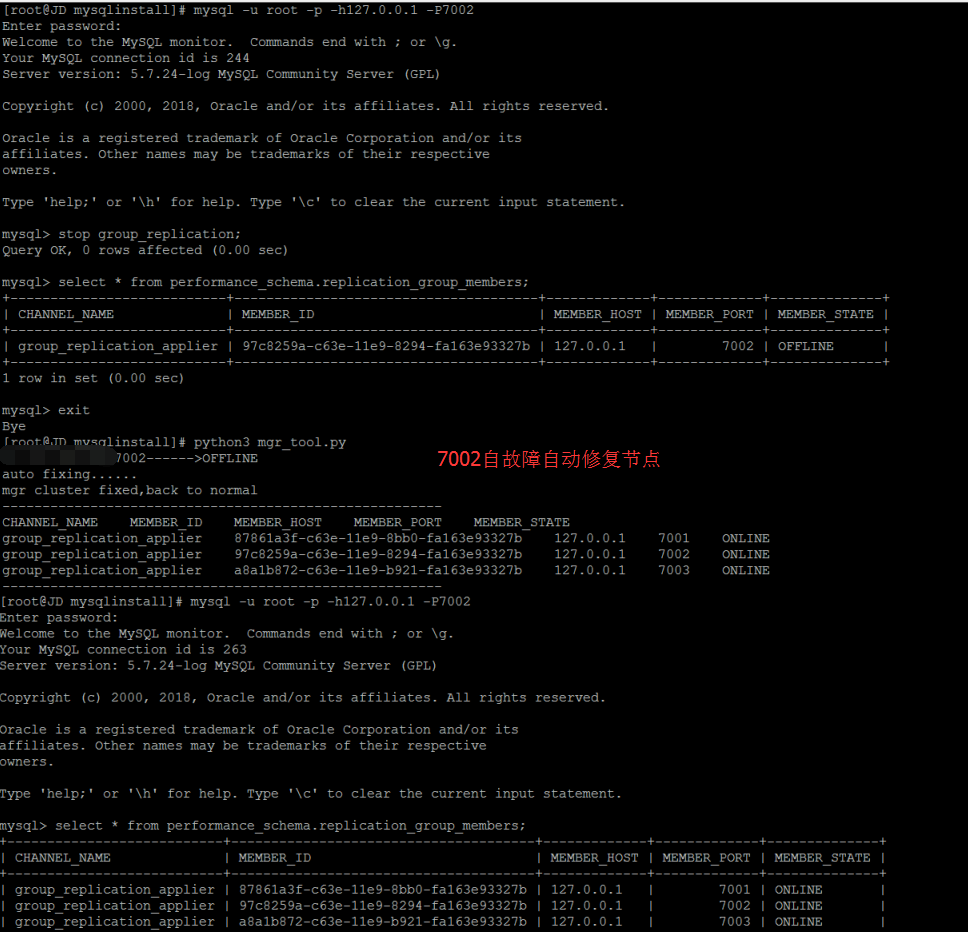
完整的实现代码
该过程要求MySQL实例必须满足MGR的基本条件,如果环境本身无法满足MGR,一切都无从谈起,因此要非常清楚MGR环境的最基本要求
完成的实现代码如下,花了一个下午写的,目前来说存在以下不足
1,创建复制用户的时候,没有指定具体的slave机器,目前直接指定的%:create user repl@'%' identified by repl
2,对于slave的修复,目前无法整体修复,只能一台一台修复,其实就是少了一个循环slave机器判断的过程
3,目前搭建之前都会reset master(不管主从,主要是清理可能的残留GTID),因此只适合新环境的搭建
4,目前只支持offline和gtid事物冲突的错误类型修复,无法支持其他MGR错误类型的修复
5,开发环境是单机多实例模式测试,没有在多机单实例模式下充分测试
以上都会逐步改善&加强。
# -*- coding: utf-8 -*- import pymysql import logging import time import decimal def execute_query(conn_dict,sql): conn = pymysql.connect(host=conn_dict['host'], port=conn_dict['port'], user=conn_dict['user'], passwd=conn_dict['password'], db=conn_dict['db']) cursor = conn.cursor(pymysql.cursors.DictCursor) cursor.execute(sql) list = cursor.fetchall() cursor.close() conn.close() return list def execute_noquery(conn_dict,sql): conn = pymysql.connect(host=conn_dict['host'], port=conn_dict['port'], user=conn_dict['user'], passwd=conn_dict['password'], db=conn_dict['db']) cursor = conn.cursor() cursor.execute(sql) conn.commit() cursor.close() conn.close() return list def get_gtid(conn_dict): sql = "show master status;" list = execute_query(conn_dict,sql) return list def skip_gtid_on_slave(conn_dict,gtid): sql_1 = 'stop group_replication;' sql_2 = '''set gtid_next='{0}';'''.format(gtid) sql_3 = 'begin;' sql_4 = 'commit;' sql_5 = '''set gtid_next='automatic';''' try: execute_noquery(conn_dict, sql_1) execute_noquery(conn_dict, sql_2) execute_noquery(conn_dict, sql_3) execute_noquery(conn_dict, sql_4) execute_noquery(conn_dict, sql_5) except: raise def get_group_replication_status(conn_dict): sql = '''select MEMBER_STATE from performance_schema.replication_group_members where (MEMBER_HOST = '{0}' or ifnull(MEMBER_HOST,'') = '') AND (MEMBER_PORT={1} or ifnull(MEMBER_PORT,'') ='') ; '''.format(conn_dict["host"], conn_dict["port"]) result = execute_query(conn_dict,sql) if result: return result else: return None def check_replication_group_members(conn_dict): print('-------------------------------------------------------') result = execute_query(conn_dict, " select * from performance_schema.replication_group_members; ") if result: column = result[0].keys() current_row = '' for key in column: current_row += str(key) + " " print(current_row) for row in result: current_row = '' for key in row.values(): current_row += str(key) + " " print(current_row) print('-------------------------------------------------------') def auto_fix_mgr_error(conn_master_dict,conn_slave_dict): group_replication_status = get_group_replication_status(conn_slave_dict) if(group_replication_status[0]["MEMBER_STATE"]=="ERROR" or group_replication_status[0]["MEMBER_STATE"] == "OFFLINE"): print(conn_slave_dict["host"]+str(conn_slave_dict["port"])+'------>'+group_replication_status[0]["MEMBER_STATE"]) print("auto fixing......") while 1 > 0: master_gtid_list = get_gtid(conn_master_dict) slave_gtid_list = get_gtid(conn_slave_dict) master_executed_gtid_value = int((master_gtid_list[-1]["Executed_Gtid_Set"]).split("-")[-1]) slave_executed_gtid_value = int(slave_gtid_list[-1]["Executed_Gtid_Set"].split("-")[-1]) slave_executed_gtid_prefix = slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[0] slave_executed_skiped_gtid = slave_executed_gtid_value + 1 if (master_executed_gtid_value > slave_executed_gtid_value): print("skip gtid and restart group replication,skiped gtid is " + slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[-1].split("-")[0] + ":"+str(slave_executed_skiped_gtid)) slave_executed_skiped_gtid = slave_executed_gtid_prefix+":"+str(slave_executed_skiped_gtid) skip_gtid_on_slave(conn_slave_dict,slave_executed_skiped_gtid) time.sleep(10) start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break else: start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break elif (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("mgr cluster is normal,nothing to do") check_replication_group_members(conn_slave_dict) ''' reset master ''' def reset_master(conn_dict): try: execute_noquery(conn_dict, "reset master;") except: raise def install_group_replication_plugin(conn_dict): get_plugin_sql = "SELECT name,dl FROM mysql.plugin WHERE name = 'group_replication';" install_plugin_sql = '''install plugin group_replication soname 'group_replication.so'; ''' try: result = execute_query(conn_dict, get_plugin_sql) if not result: execute_noquery(conn_dict, install_plugin_sql) except: raise def create_mgr_repl_user(conn_master_dict,user,password): try: reset_master(conn_master_dict) sql_exists_user = '''select user from mysql.user where user = '{0}'; '''.format(user) user_list = execute_query(conn_master_dict,sql_exists_user) if not user_list: create_user_sql = '''create user {0}@'%' identified by '{1}'; '''.format(user,password) grant_privilege_sql = '''grant replication slave on *.* to {0}@'%';'''.format(user) execute_noquery(conn_master_dict,create_user_sql) execute_noquery(conn_master_dict, grant_privilege_sql) execute_noquery(conn_master_dict, "flush privileges;") except: raise def set_super_read_only_off(conn_dict): super_read_only_off = '''set global super_read_only = 0;''' execute_noquery(conn_dict, super_read_only_off) def open_group_replication_bootstrap_group(conn_dict): sql = '''select variable_name,variable_value from performance_schema.global_variables where variable_name = 'group_replication_bootstrap_group';''' result = execute_query(conn_dict, sql) open_bootstrap_group_sql = '''set @@global.group_replication_bootstrap_group=on;''' if result and result[0]['variable_value']=="OFF": execute_noquery(conn_dict, open_bootstrap_group_sql) def close_group_replication_bootstrap_group(conn_dict): sql = '''select variable_name,variable_value from performance_schema.global_variables where variable_name = 'group_replication_bootstrap_group';''' result = execute_query(conn_dict, sql) close_bootstrap_group_sql = '''set @@global.group_replication_bootstrap_group=off;''' if result and result[0]['variable_value'] == "ON": execute_noquery(conn_dict, close_bootstrap_group_sql) def start_group_replication(conn_dict): start_group_replication = '''start group_replication;''' group_replication_status = get_group_replication_status(conn_dict) if not (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): execute_noquery(conn_dict, start_group_replication) def connect_to_group(conn_dict,repl_user,repl_password): connect_to_group_sql = '''change master to master_user='{0}', master_password='{1}' for channel 'group_replication_recovery'; '''.format(repl_user,repl_password) try: execute_noquery(conn_dict, connect_to_group_sql) except: raise def start_mgr_on_master(conn_master_dict,repl_user,repl_password): try: set_super_read_only_off(conn_master_dict) reset_master(conn_master_dict) create_mgr_repl_user(conn_master_dict,repl_user,repl_password) connect_to_group(conn_master_dict,repl_user,repl_password) open_group_replication_bootstrap_group(conn_master_dict) start_group_replication(conn_master_dict) close_group_replication_bootstrap_group(conn_master_dict) group_replication_status = get_group_replication_status(conn_master_dict) if (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("master added in mgr and run successfully") return True except: raise print("############start master mgr error################") exit(1) def start_mgr_on_slave(conn_slave_dict,repl_user,repl_password): try: set_super_read_only_off(conn_slave_dict) reset_master(conn_slave_dict) connect_to_group(conn_slave_dict,repl_user,repl_password) start_group_replication(conn_slave_dict) # wait for 10 time.sleep(10) # then check mgr status group_replication_status = get_group_replication_status(conn_slave_dict) if (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("slave added in mgr and run successfully") if (group_replication_status[0]['MEMBER_STATE'] == 'RECOVERING'): print("slave is recovering") except: print("############start slave mgr error################") exit(1) def auto_mgr(conn_master,conn_slave_1,conn_slave_2,repl_user,repl_password): install_group_replication_plugin(conn_master) master_replication_status = get_group_replication_status(conn_master) if not (master_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): start_mgr_on_master(conn_master,repl_user,repl_password) slave1_replication_status = get_group_replication_status(conn_slave_1) if not (slave1_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): install_group_replication_plugin(conn_slave_1) start_mgr_on_slave(conn_slave_1, repl_user, repl_user) slave2_replication_status = get_group_replication_status(conn_slave_2) if not (slave2_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): install_group_replication_plugin(conn_slave_2) start_mgr_on_slave(conn_slave_2, repl_user, repl_user) check_replication_group_members(conn_master) if __name__ == '__main__': conn_master = {'host': '127.0.0.1', 'port': 7001, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'} conn_slave_1 = {'host': '127.0.0.1', 'port': 7002, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'} conn_slave_2 = {'host': '127.0.0.1', 'port': 7003, 'user': 'root', 'password': 'root', 'db': 'mysql', 'charset': 'utf8mb4'} repl_user = "repl" repl_password = "repl" #auto_mgr(conn_master,conn_slave_1,conn_slave_2,repl_user,repl_password) auto_fix_mgr_error(conn_master,conn_slave_1) check_replication_group_members(conn_master)
/*
the waiting game:尽管人生如此艰难,不要放弃;不要妥协;不要失去希望
*/