一、基础入门
1.1什么是爬虫
爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序。
从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
1.2爬虫基本流程
用户获取网络数据的方式:
方式1:浏览器提交请求--->下载网页代码--->解析成页面
方式2:模拟浏览器发送请求(获取网页代码)->提取有用的数据->存放于数据库或文件中
爬虫要做的就是方式2。
入门python爬虫,10分钟就够了,这可能是我见过最简单的基础教学

![]()
1发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
Request模块缺陷:不能执行JS 和CSS 代码
2获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3解析内容
解析html数据:正则表达式(RE模块)、xpath(主要使用)、beautiful soup、css
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4保存数据
数据库(MySQL,Mongdb、Redis)或 文件的形式。
1.3http协议 请求与响应
http协议

![]()
Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
1.3.1
request
(1) 请求方式
常见的请求方式:GET / POST
(2)请求的URL
url全球统一资源定位符,用来定义互联网上一个唯一的资源 例如:一张图片、一个文件、一段视频都可以用url唯一确定
(3)请求头
User-agent:请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户host;
cookies:cookie用来保存登录信息
注意:一般做爬虫都会加上请求头。
请求头需要注意的参数:
Referrer:访问源至哪里来(一些大型网站,会通过Referrer 做防盗链策略;所有爬虫也要注意模拟)
User-Agent:访问的浏览器(要加上否则会被当成爬虫程序)
cookie:请求头注意携带
(4)请求体
请求体 如果是get方式,请求体没有内容 (get请求的请求体放在 url后面参数中,直接能看到) 如果是post方式,请求体是format data
ps:1、登录窗口,文件上传等,信息都会被附加到请求体内 2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
1.3.2
response
(1)响应状态码
200:代表成功
301:代表跳转
404:文件不存在
403:无权限访问
502:服务器错误
(2)response header
响应头需要注意的参数:Set-Cookie:BDSVRTM=0; path=/:可能有多个,是来告诉浏览器,把cookie保存下来
(3)preview就是网页源代码
json数据
如网页html,图片
二进制数据等
02
二、基础模块
2.1requests
requests是python实现的简单易用的HTTP库,是由urllib的升级而来。
开源地址:
https://github.com/kennethrei...
中文API:
http://docs.python-requests.o...
2.2re 正则表达式
在 Python 中使用内置的 re 模块来使用正则表达式。
缺点:处理数据不稳定、工作量大
2.3XPath
Xpath(XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
在python中主要使用 lxml 库来进行xpath获取(在框架中不使用lxml,框架内直接使用xpath即可)
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
2.4BeautifulSoup
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
使用BeautifulSoup需要导入bs4库
缺点:相对正则和xpath处理速度慢
优点:使用简单
2.5Json
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
在python中主要使用 json 模块来处理 json数据。Json解析网站:
https://www.sojson.com/simple...
2.6threading
使用threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法
03
三、方法实例
3.1get方法实例
demo_get.py
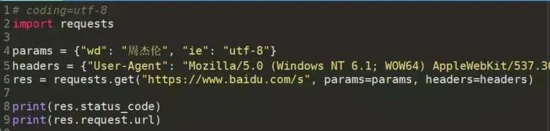
![]()
3.2post方法实例
demo_post.py
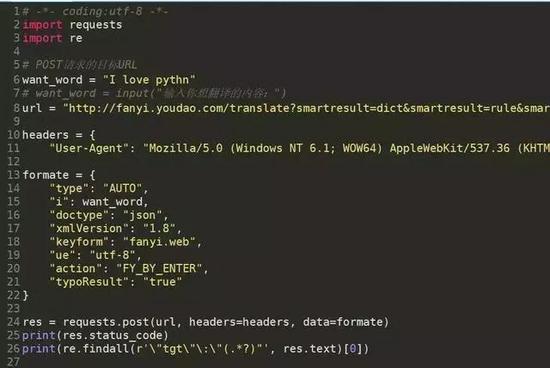
![]()
3.3添加代理
demo_proxies.py
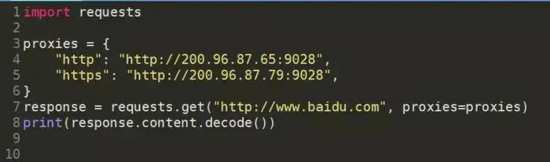
![]()
3.4获取ajax类数据实例
demo_ajax.py
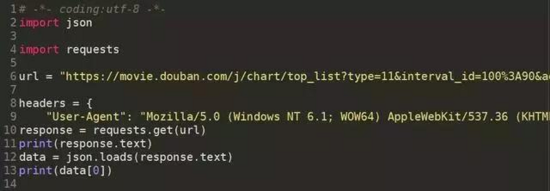
![]()
3.5使用多线程实例
demo_thread.py
04
四、爬虫框架
4.1Srcapy框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
Scrapy 使用了 Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
4.2Scrapy架构图

![]()
4.3Scrapy主要组件
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
4.4Scrapy的运作流程
引擎:Hi!Spider, 你要处理哪一个网站?
Spider:老大要我处理xxxx.com。
引擎:你把第一个需要处理的URL给我吧。
Spider:给你,第一个URL是xxxxxxx.com。
引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
调度器:好的,正在处理你等一下。
引擎:Hi!调度器,把你处理好的request请求给我。
调度器:给你,这是我处理好的request
引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
管道``调度器:好的,现在就做!
4.5制作Scrapy爬虫4步曲
1新建爬虫项目scrapy startproject mySpider2明确目标 (编写items.py)打开mySpider目录下的items.py3制作爬虫 (spiders/xxspider.py)scrapy genspider gushi365 "gushi365.com"4存储内容 (pipelines.py)设计管道存储爬取内容
05
五、常用工具
5.1fidder
fidder是一款抓包工具,主要用于手机抓包。
5.2XPath Helper
xpath helper插件是一款免费的chrome爬虫网页解析工具。可以帮助用户解决在获取xpath路径时无法正常定位等问题。
谷歌浏览器插件xpath helper 的安装和使用:
https://jingyan.baidu.com/art...
06
六、分布式爬虫
6.1scrapy-redis
Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(pip install scrapy-redis)
6.2分布式策略
Master端(核心服务器) :搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储。
此文转载文,著作权归作者所有,如有侵权联系小编删除!
原文地址:https://www.tuicool.com/articles/7v6fEf6
需要源代码或者想了解更多的(点击这里下载)