转载请注明出处,本文链接:https://www.cnblogs.com/wxylyw/p/9807369.html
less 5 GET - Double Injection - Single Quotes - String (双注入GET单引号字符型注入)
先采用常规方法注入 
发现页面显示You are in ...
查看源代码

发现根本没有输出$row
所以这里要通过mysql_error() 打印出我们想要的数据
先学习一些报错注入的基础知识
mysql几个函数
1.rand()函数返回一个0-1的随机数
2.count(*)返回数据行数 包括NULL
count(1)执行效果等同于* 但是性能上有所不同
count(column)返回制定列的行数 不包括NULL
count(distinct column)返回指定列不重复数据的行数
3.group by 分组
4.floor函数返回小于等于该值的最大整数.
常用报错sql语句固定套路为
select count(*),concat_ws(':',([子查询],floor(rand()*2))) as a form [table_name] group by a;
为了得出这个报错语句,逐步操作对比如下:
先使用一下前面提过的函数
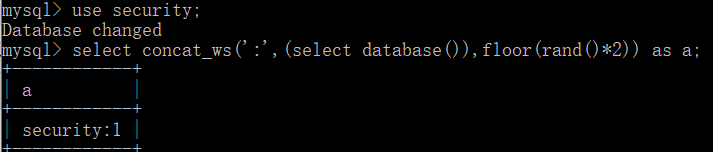
接着,我们把count函数也加上,这时候需要注意,要从一张表中查询结果,具体从什么表没关系,但是一定要确保有这个表,所以比较好的选择方案就是information_schema中的表,比如tables:

以上两条语句多次实验会发现0和1的概率各是百分之五十,具体原因这里不赘述了。
最后加上group by语句整体执行

发生报错
深层次的原因参考了https://www.cnblogs.com/BloodZero/p/4660971.html这篇博客
简单总结为,通过floor报错的方法来爆数据的本质是group by语句的报错。group by语句报错的原因是floor(random(0)*2)的不确定性,即可能为0也可能为1。group by key的原理是循环读取数据的每一行,先将结果保存于临时表中。读取每一行的key时,如果key存在于临时表中,则更新临时表中的数据;如果该key不存在于临时表中,则在临时表中插入key所在行的数据。group by floor(random(0)*2)出错的原因是这时key是个随机数0或1,检测临时表中key是否存在时,如果要插入临时表的key值为0,而此时临时表只有key为1的行不存在key为0的行,那么数据库要将该条记录插入临时表。由于是随机数,检测之后插入时,又要计算一下随机值,此时floor(random(0)*2)结果可能为1,就会导致插入时key冲突而报错。
还有一种可以产生报错的sql语句
select count(*),floor(rand(0)*2) as a from information_schema.tables group by a;
基本原理与前一种相同,这里提一下是我遇到这个语句时发现自己之前错误的理解了rand()函数的功能
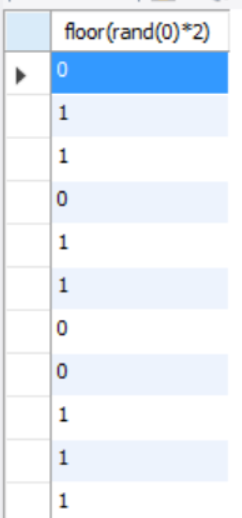
select floor(rand(0)*2) from table_name;
返回如下图
因为rand指定了参数0,所以每次的返回序列都相同。
这里我学习的时候有一个疑惑,我当时以为每次rand(0)的值都应该是相同的,在咨询了学长之后发现,其实不同行的返回值是不同的,只不过这个参数传入之后返回的各行组成的序列是相同的。
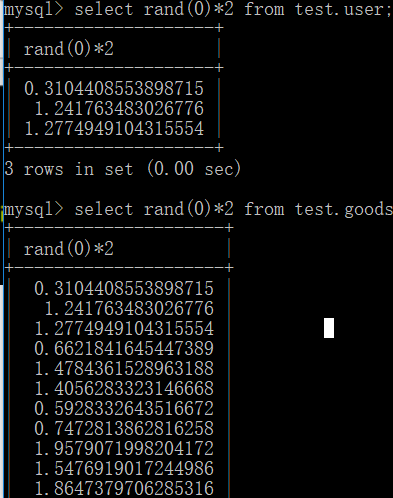
第二种语句建立虚拟表报错过程:
取第一条记录,执行floor(rand(0)*2),发现结果为0(第一次计算),查询虚拟表,发现0的键值不存在,则在虚拟表插入新的数据时floor(rand(0)*2)会被再计算一次,结果为1(第二次计算)。
取第二条记录,执行floor(rand(0)*2),发现结果为1(第三次计算),查询虚拟表,发现1的键值存在,所以floor(rand(0)*2)不会被计算第二次,直接count(*)加1,第二条记录查询完毕。
取第三条记录,再次计算floor(rand(0)*2),发现结果为0(第4次计算),查询虚拟表,发现0的键值不存在,则在虚拟表插入新的数据时floor(rand(0)*2)会被再计算一次,结果为1(第5次计算),然而1这个主键已经存在于虚拟表中,而新计算的值也为1。主键键值必须唯一,所以插入的时候就直接报错了。
如果没有count(*),那么就不可能报错了,因为这个时候没有使用虚表。还是让表中只有一项,执行select floor(rand(0)*2) as a from information_schema.tables group by a;看看。

报错注入的基础就是以上这些,接下来进入正题。
使用刚刚学过的报错语句注入

这里提示一下 0x3a 是十六进制表示的冒号 :
报错信息为 Operand should contain 1 column(s),操作数只能有一列。
尝试使用
(select 1 from(select count(*),concat(0x3a,0x3a,(select database()),0x3a,0x3a,floor(rand()*2)) as a from information_schema.columns group by a))再次注入

新的报错信息为 Every derived table must have its own alias,每个衍生出来的表必须有它自己的别名
构建新的注入语句为
(select 1 from(select count(*),concat(0x3a,0x3a,(select database()),0x3a,0x3a,floor(rand()*2)) as a from information_schema.columns group by a)as b) (as可以省略)

key名重复引起报错爆出数据库名
继续爆当前用户和版本信息,以及表名列名用户名密码...


爆表名

payload:
?id=1' and (select 1 from (select count(*),concat(0x3a,0x3a,(select table_name from information_schema.tables where table_schema=database() limit 0,1),0x3a,0x3a,floor(rand(0)*2))as a from information_schema.columns group by a)b)--+
原理就是在concat函数中加入之前使用过的sql注入语句,这里直接上图了。



爆列名

其它列名不一张一张截图了
直接爆密码

这一课的本意就是让我们使用这种双注入的方法。对于基于错误的SQL注入来说,还有其它办法。
1.使用extractvalue
extractvalue(xml_frag,xpath_expr)
extractvalue()接受两个字符串参数,一个xml标记xml_frag的片段和一个xpath表达式xpath_expr(也称为定位符)。这个函数返回第一个文本节点的文本。在mysql 5.6.6及更早版本中,xpath表达式最多可以包含127个字符。这个限制在mysql 5.6.7中解除。我们可以在xpath中填写获得我们想要的信息的语句。
2.使用updatexml
updatexml(xml_target,xpath_expr,new_xml)
此函数用新的xml片段new_xml替换xml标记xml_target的给定片段的单个部分,然后返回更改的xml。被替换的xml_target的部分与用户提供的xpath表达式xpath_expr匹配。在 mysql 5.6.6及更早版本中,xpath表达式最多可以包含127个字符。这个限制在mysql 5.6.7中解除。如果没有找到匹配xpath_expr的表达式,或者找到多个匹配项,函数将返回原始的xml_target片段。 所有三个参数应该是字符串。我们可以在xpath中填写获得我们想要的信息的语句。
3.使用name_const
name_const(name,value)
用于生成结果时,name_const()会使列具有给定的名称。参数应该是常量。它和select value as name是等价的。我们可以构造两个列使得它们名字一样并在列名中填写获得我们想要的信息的语句。
这三种方法我只是简单了解了一下还并没有实践,感兴趣的可以亲自试一下。
less6的方法和less5的基本一致,今天不想再写了,就先整理这些吧。