使用sklearn进行数据挖掘系列文章:
- 1.使用sklearn进行数据挖掘-房价预测(1)
- 2.使用sklearn进行数据挖掘-房价预测(2)—划分测试集
- 3.使用sklearn进行数据挖掘-房价预测(3)—绘制数据的分布
- 4.使用sklearn进行数据挖掘-房价预测(4)—数据预处理
- 5.使用sklearn进行数据挖掘-房价预测(5)—训练模型
- 6.使用sklearn进行数据挖掘-房价预测(6)—模型调优
上一节我们对数据集进行了了解,知道了数据集大小、特征个数及类型和数据分布等信息。做数据挖掘任务过程中需要对数据划分为训练集和测试集合,你可能会问不就数据集的划分么,有必要单独进行讲解么?莫急,听我慢慢道来,希望对你有帮助。
划分数据集###
在划分测试集的时候我们要完全随机的划分,因为当我们看过数据集时候,我们会带着主观偏见进行模型的选取,这将会造成数据窥探偏见(data snooping bias),在划分数据集的时候非常简单,我们只需要随机抽取其中的一部分,例如20%,将之放在一边即可。
import numpy as np
def split_train_test(data,test_ratio):
indices = np.random.permutation(len(data)) #随机全排列
test_size = int(len(data) * test_ratio)
test_indices = indices[:test_size]
train_indices = indices[test_size:]
return data.iloc[train_indices],data.iloc[test_indices]
运行方法
train_set,test_set = split_train_test(housing,0.2)
print("train set len",len(train_set))
print("test set len",len(test_set))
('train set len', 16512)
('test set len', 4128)
note:这里面返回的结果是DataFrame类型,如果取其中的某一条样本不能像数组那样train_set[0],需要使用train_set.iloc[0],这样返回的是一个Series类型的对象,如果取其值使用train_set.iloc[0].values返回的是np.array类型
这样我们就将训练集和测试机划分完毕,那么这一节也就结束了。。等下,细心的人可能会发现,每次运行返回的数据集结果内容不一样啊,这也就意味着跑算法的时候,每次跑的数据可能不一样。一个解决方法是在第一次运行的时候,将训练集保存起来,供后续使用,另外一个方法是在执行之前使用np.random.seed(42),这个整数任意。
可以尝试下
a = [1,2,3,4,5,6]
np.random.seed(32) #使用和不使用
print np.random.permutation(a)
seed( ) 用于指定随机数生成时所用算法开始的整数值。
- 1.如果使用相同的seed( )值,则每次生成的随即数都相同;
- 2.如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。
- 3.设置的seed()值仅一次有效
当数据集被更新的时候,这两种方法就会失效。一种常用的方法是使用样本的ID作为是否选为测试集的依据,我们可以选取样本的hash值作为ID,选取hash的最后一位小于51(256 / 5)。这就保证了测试集始终如一(不会包含之前的训练集样本),即使更新了数据集。下面是实现方法:
def test_set_check(idd,test_ratio,hash):
return hash(str(idd)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data,test_ratio,id_column,hash=hashlib.md5):
ids = data[id_column]
is_in_test = ids.apply(lambda id_:test_set_check(id_,test_ratio,hash))
return data.loc[~is_in_test],data.loc[is_in_test]
上面方法使用的是md5哈希方法,对上面使用的函数进行解释一下
digest()以二进制的形式返回摘要值;还有hexdigest()这个是返回摘要的十六进制字符串;eg
a = hash('1')
a.digest()
Out[103]: 'xc4xcaB8xa0xb9#x82
xccPx9aoux84x9b'
a.hexdigest()
Out[104]: 'c4ca4238a0b923820dcc509a6f75849b'
apply(func,axis=0),根据axis,应用当前的func函数iloc和loc,iloc[行号],loc[行标签],两者都可使用boolean类型的数组
使用行号作为ID的时候,需要保证当添加新数据的时候是添加到了数据集的尾部,并且保证数据集中的某些样本被删除;
sklearn也提供了划分数据集的方法
from sklearn.model_selection import train_test_split
train_set,test_set = train_test_split(housing,test_size=0.2,random_state=42)
目前我们讲的划分测试集和训练集的方法是纯随机,当我们的数据集比较大的时候,这是一个很好的方法,但如果数据集不够大就将出现采样偏差问题,就例如对1000人进行问卷调查,你到师范学校发现男女比例3:7女生那么多。。。为了反应总体,你应该男性选择男生300人女性700人。这就叫做分层采样(stratifed sampling),至于选取哪个特征作为分类指标和分多少层这就需要根据实际的工作场景来判断,在这里选取median_income作为分层指标。先看一下这一特征的数据分布情况

从上图可以看出,media_income这一属性为连续的数值类型,那么首先我们需要对其离散化,即划分为几个类别;
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
# Label those above 5 as 5
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
housing["income_cat"].hist()
上面这段代码通过除以1.5来限制类别的个数,并将大于5的值归为5这一类别,得到的结果如下图所示:
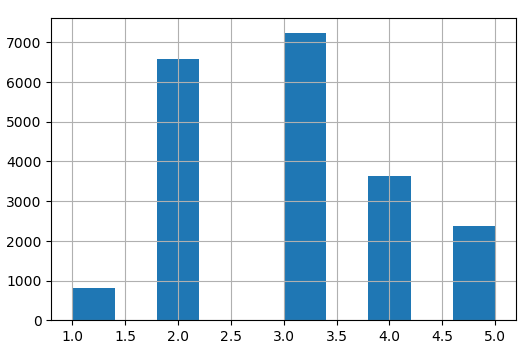
从图中可以看出,media_income这一属性大多落在2和3类别之间。
note:
housing.where(cond, other=nan, inplace=True):判断condition,如果为True值不变,如果为false则取other的值,是否对值修改np.ceil:向上取整>>a = np.array([-1.7, -1.5, -0.2, 0.2, 1.5, 1.7, 2.0]) >>np.ceil(a) array([-1., -1., -0., 1., 2., 2., 2.])
目前我们已经对样本分好了类别,并加上了income_cat类标签。接下来我们就需要按照类别划分数据集了。
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42)
for train_index,test_index in split.split(housing,housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
这里面n_splits是迭代的次数。
到这里数据集划分为训练集和测试集已经完毕,刚刚添加的新的辅助分类特征income_cat也可以退伍了,把他从原始数据集中删除。
for set_ in (strat_train_set, strat_test_set):
set_.drop("income_cat", axis=1, inplace=True)