第五部分 并行线程
在本节中,我们将介绍Framework 4.0新增的利用多核处理器的多线程API:
- 并行LINQ或PLINQ
- Parallel 类
- 任务并行性构造
- 并发集合
- 自旋锁和自旋等待
这些API统称为(松散地)称为PFX(并行框架)。并行类与任务并行性构造一起被称为任务并行库或TPL。
Framework 4.0还添加了许多针对传统多线程的较低级线程构造。我们之前介绍了这些内容:
- 低延迟信令构造(SemaphoreSlim,ManualResetEventSlim,CountdownEvent和Barrier)
- 用于合作取消的取消令牌
- 惰性初始化类
- ThreadLocal <T>
在继续之前,您需要熟悉1-4部分的基础知识,尤其是锁定和线程安全性。
并行编程部分中的所有代码清单都可以在LINQPad中作为交互式样本获得。 LINQPad是C#代码暂存器,是测试代码段的理想选择,而无需创建周围的类,项目或解决方案。要访问示例,请在左下方的LINQPad的“示例”选项卡中单击“下载更多示例”,然后在“ Nutshell:更多章节”中选择“ C#4.0”。
Why PFX?
最近,CPU时钟速度停滞不前,制造商已将重点转移到增加内核数上。作为程序员,这对我们来说是个问题,因为标准的单线程代码不会因为这些额外的内核而自动运行得更快。
对于大多数服务器应用程序而言,利用多个内核很容易,因为每个线程可以独立处理一个单独的客户端请求,但是在桌面上则比较困难-因为通常需要您使用计算密集型代码并执行以下操作:
- 将其分成小块。
- 通过多线程并行执行这些块。
- 当结果可用时,以线程安全和高效的方式整理结果。
尽管您可以使用经典的多线程结构来完成所有这些操作,但是这很尴尬-特别是分区和整理的步骤。另一个问题是,当多个线程同时处理同一数据时,通常的线程安全锁定策略会引起很多争用。
PFX库是专门为在这些情况下提供帮助而设计的。
利用多核或多个处理器进行编程称为并行编程。这是更广泛的多线程概念的子集。
PFX 概念
在线程之间划分工作有两种策略:数据并行性和任务并行性。
当必须对多个数据值执行一组任务时,我们可以通过让每个线程对值的子集执行(相同)一组任务来并行化。之所以称为数据并行性,是因为我们正在线程之间划分数据。相反,通过任务并行性,我们可以划分任务;换句话说,我们让每个线程执行不同的任务。
通常,数据并行性更容易并且可以更好地扩展到高度并行的硬件,因为它减少或消除了共享数据(从而减少了争用和线程安全问题)。此外,数据并行利用了这样一个事实,即数据值通常比离散任务多,从而增加了并行的可能性。
数据并行性还有助于结构化并行性,这意味着并行工作单元在程序中的同一位置开始和结束。相反,任务并行性往往是非结构化的,这意味着并行工作单元可能在程序中分散的位置开始和结束。结构化并行机制更简单,更不易出错,并且允许您将分区和线程协调(甚至结果归类)这一艰巨的工作移植到库中。
PFX 组件
PFX包括两层功能。较高的层由两个结构化的数据并行API组成:PLINQ和Parallel类。下层包含任务并行性类-以及一组有助于并行编程活动的其他构造。
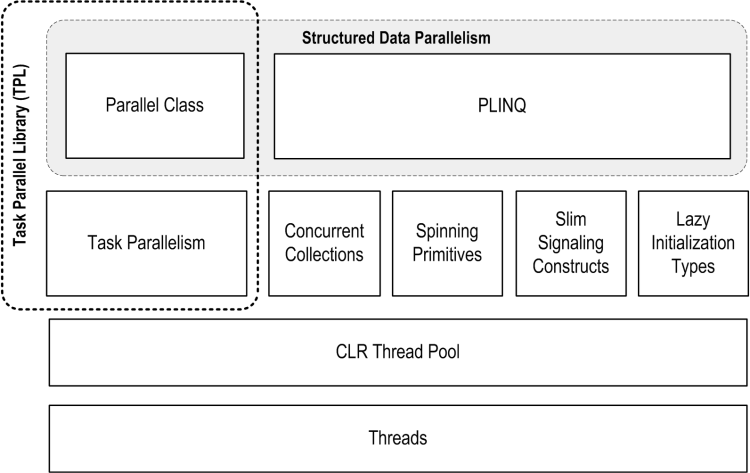
PLINQ提供了最丰富的功能:它使并行化的所有步骤自动化-包括将工作划分为任务,在线程上执行这些任务,以及将结果整理为单个输出序列。这就是声明性的-因为您只需声明要并行化您的工作(将其结构化为LINQ查询),然后让框架来处理实现细节即可。相反,其他方法则势在必行,因为您需要显式编写代码以进行分区或整理。对于Parallel类,您必须自己整理结果。使用任务并行性构造,您还必须自己划分工作:
| 分区工作 | 整理结果 | |
| PLINQ | 是 | 是 |
| Parallel 类 | 是 | 否 |
| PFX的任务并行性 | 否 | 否 |
并发集合和旋转原语可以帮助您进行较低级别的并行编程活动。这些非常重要,因为PFX不仅可以与当今的硬件一起使用,而且还可以与具有更多内核的下一代处理器一起使用。如果您要移动一堆切碎的木材并且有32名工人来完成这项工作,那么最大的挑战就是在移动木材时不让工人互相妨碍。将算法分配到32个内核中是相同的:如果使用普通锁来保护公共资源,则产生的阻塞可能意味着这些内核中只有一小部分实际上曾经同时处于繁忙状态。并发集合专门针对高度并发访问进行了调整,重点是最小化或消除阻塞。 PLINQ和Parallel类本身依靠并发集合和自旋原语来有效地管理工作。
PFX和传统多线程
传统的多线程方案是即使在单核计算机上也可以受益的多线程方案,而没有真正的并行化发生。我们之前已经介绍了这些内容:它们包括诸如维护响应式用户界面和一次下载两个网页之类的任务。
我们在并行编程部分将介绍的某些构造有时在传统的多线程中也很有用。尤其是:
- 每当您要并行执行操作然后等待它们完成(结构化并行性)时,PLINQ和Parallel类就很有用。这包括非CPU密集型任务,例如调用Web服务。
- 当您要在池线程上运行某些操作,并希望通过连续性和父/子任务管理任务的工作流时,任务并行性构造很有用。
- 当您想要线程安全的队列,堆栈或字典时,并发集合有时是合适的。
- BlockingCollection提供了一种实现生产者/消费者结构的简便方法。
何时使用PFX
PFX的主要用例是并行编程:利用多核处理器来加快计算密集型代码的速度。
利用多核的挑战是阿姆达尔定律,该定律指出并行化带来的最大性能改进取决于必须顺序执行的代码部分。例如,如果算法的执行时间只有三分之二是可并行化的,那么即使拥有无限数量的内核,您也永远不会超过三倍的性能提升。
因此,在继续之前,值得验证瓶颈在可并行代码中。同样值得考虑的是,您的代码是否需要占用大量计算资源-优化通常是最简单,最有效的方法。不过,这需要权衡取舍,因为有些优化技术会使并行代码变得更加困难。
最简单的收获来自所谓的“尴尬的并行问题”,即可以轻松地将一项工作划分为自己有效执行的任务(结构化并行非常适合此类问题)。示例包括许多图像处理任务,光线跟踪以及数学或密码学中的蛮力方法。毫不费力地并行问题的一个示例是实现quicksort算法的优化版本-一个好的结果需要一些思考,并且可能需要非结构化并行。
PLINQ
PLINQ自动并行化本地LINQ查询。 PLINQ的优点是易于使用,因为它减轻了工作分区和结果整理的负担。
要使用PLINQ,只需在输入序列上调用AsParallel(),然后照常继续LINQ查询。以下查询计算3到100,000之间的质数-充分利用目标计算机上的所有内核:
// Calculate prime numbers using a simple (unoptimized) algorithm. // // NB: All code listings in this chapter are available as interactive code snippets in LINQPad. // To activate these samples, click Download More Samples in LINQPad's Samples tab in the // bottom left, and select C# 4.0 in a Nutshell: More Chapters. IEnumerable<int> numbers = Enumerable.Range (3, 100000-3); var parallelQuery = from n in numbers.AsParallel() where Enumerable.Range (2, (int) Math.Sqrt (n)).All (i => n % i > 0) select n; int[] primes = parallelQuery.ToArray();
AsParallel是System.Linq.ParallelEnumerable中的扩展方法。它将输入包装为基于ParallelQuery <TSource>的序列,这将导致随后调用的LINQ查询运算符绑定到在ParallelEnumerable中定义的另一组扩展方法。这些提供了每个标准查询运算符的并行实现。本质上,它们通过将输入序列划分为在不同线程上执行的块,然后将结果整理回单个输出序列以供使用来工作:
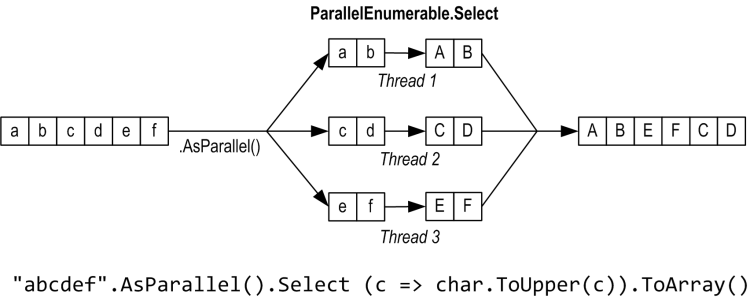
调用AsSequential()会解开ParallelQuery序列,以便后续查询运算符绑定到标准查询运算符并按顺序执行。在调用有副作用或不是线程安全的方法之前,这是必需的。
对于接受两个输入序列(Join,GroupJoin,Concat,Union,Intersect,Except和Zip)的查询运算符,必须将AsParallel()应用于两个输入序列(否则,将引发异常)。但是,您不需要在查询进行过程中继续对查询应用AsParallel,因为PLINQ的查询运算符会输出另一个ParallelQuery序列。实际上,再次调用AsParallel会导致效率低下,因为它会强制合并和重新划分查询:
mySequence.AsParallel() // Wraps sequence in ParallelQuery<int> .Where (n => n > 100) // Outputs another ParallelQuery<int> .AsParallel() // Unnecessary - and inefficient! .Select (n => n * n)
并非所有查询运算符都可以有效地并行化。对于那些无法执行的操作,PLINQ会依次实现操作符。如果PLINQ怀疑并行化的开销实际上会减慢特定查询的速度,则它也可以顺序运行。
PLINQ仅适用于本地集合:它不适用于LINQ to SQL或Entity Framework,因为在这种情况下,LINQ会转换为SQL,然后在数据库服务器上执行。但是,您可以使用PLINQ对从数据库查询获得的结果集执行其他本地查询。
如果PLINQ查询引发异常,则将其重新引发为AggregateException,其InnerExceptions属性包含实际的异常(或多个异常)。有关详细信息,请参见使用AggregateException。
Why Isn’t AsParallel the Default?
鉴于AsParallel透明地并行化LINQ查询,出现了一个问题:“ Microsoft为什么不简单地并行化标准查询运算符并将PLINQ设置为默认值?”
选择加入的原因有很多。首先,为了使PLINQ有用,必须将其合理数量的计算密集型工作移植到工作线程中。大多数LINQ to Objects查询执行得非常快,不仅不需要并行化,而且分区,整理和协调额外线程的开销实际上可能会使事情变慢。
另外:
在元素排序方面,PLINQ查询的输出(默认情况下)可能与LINQ查询不同。
PLINQ将异常包装在AggregateException中(以处理引发多个异常的可能性)。
如果查询调用线程不安全的方法,PLINQ将给出不可靠的结果。
最后,PLINQ提供了许多挂钩来进行调整和调整。细微的负担使标准LINQ to Objects API负担加重。
并行执行弹道
像普通的LINQ查询一样,PLINQ查询也会被延迟评估。这意味着仅当您开始使用结果时才会触发执行-通常通过foreach循环(尽管也可以通过转换运算符(例如ToArray)或返回单个元素或值的运算符)触发执行。
但是,在枚举结果时,执行过程与普通顺序查询的执行过程有所不同。顺序查询完全由使用者以“拉”方式提供动力:输入序列中的每个元素都是在使用者需要时准确获取的。并行查询通常使用独立线程来在消费者需要时(比方说新闻阅读器的电话提示器或CD播放器中的防跳缓冲区)在需要时从输入序列中稍稍提取元素。然后,它通过查询链并行处理元素,将结果保存在较小的缓冲区中,以便按需为消费者准备就绪。如果使用者提前暂停或退出枚举,查询处理器也会暂停或停止,以免浪费CPU时间或内存。
您可以通过在AsParallel之后调用WithMergeOptions来调整PLINQ的缓冲行为。通常,AutoBuffered的默认值可以提供最佳的整体效果。 NotBuffered禁用缓冲区,如果您希望尽快看到结果,则很有用; FullyBuffered在将整个结果集呈现给使用者之前会对其进行高速缓存(OrderBy和Reverse运算符自然会以这种方式工作,元素,聚合和转换运算符也是如此)。
PLINQ和订购
并行查询操作符的副作用是,整理结果后,结果不一定与提交结果的顺序相同,如上图所示。换句话说,LINQ对序列的常规顺序保留保证不再成立。
如果需要保留订单,可以通过在AsParallel()之后调用AsOrdered()来强制执行以下操作:
myCollection.AsParallel()。AsOrdered()...
调用AsOrdered会导致大量元素的性能下降,因为PLINQ必须跟踪每个元素的原始位置。
您可以稍后通过调用AsUnordered在查询中取消AsOrdered的效果:这引入了“随机混叠点”,该点使查询从该点开始可以更高效地执行。因此,如果您只想保留前两个查询运算符的输入序列顺序,则可以执行以下操作:
inputSequence.AsParallel().AsOrdered() .QueryOperator1() .QueryOperator2() .AsUnordered() // From here on, ordering doesn’t matter .QueryOperator3() ...
AsOrdered不是默认值,因为对于大多数查询而言,原始输入顺序并不重要。换句话说,如果默认为AsOrdered,则必须对大多数并行查询应用AsUnordered才能获得最佳性能,这会很麻烦。
PLINQ局限性
目前,PLINQ可以并行化方面存在一些实际限制。这些限制可能在后续的Service Pack和Framework版本中放松。
以下查询运算符可防止查询并行化,除非源元素处于其原始索引位置:
- Take,TakeWhile,Skip和SkipWhile
- Select,SelectMany和ElementAt的索引版本
大多数查询运算符都会更改元素的索引位置(包括那些删除元素的索引位置,例如Where)。这意味着,如果要使用前面的运算符,通常需要在查询开始时使用它们。
以下查询运算符是可并行化的,但是使用昂贵的分区策略,该策略有时可能比顺序处理要慢:
Join,GroupBy,GroupJoin,Distinct,Union,Intersect, andExcept
Aggregate运算符在其标准版本中的种子重载是不可并行化的-PLINQ提供了特殊的重载来处理此问题。
所有其他运算符都是可并行化的,尽管使用这些运算符并不能保证您的查询将被并行化。如果PLINQ怀疑并行化的开销会减慢该特定查询的速度,则可以按顺序运行您的查询。您可以通过在AsParallel()之后调用以下代码来覆盖此行为并强制并行化:
.WithExecutionMode(ParallelExecutionMode.ForceParallelism)
示例:并行拼写检查器
假设我们想编写一个拼写检查器,以利用所有可用的内核快速运行非常大的文档。通过将我们的算法表述为LINQ查询,我们可以非常轻松地对其进行并行化。
第一步是将英语单词词典下载到HashSet中以进行有效查找:
if (!File.Exists ("WordLookup.txt")) // Contains about 150,000 words new WebClient().DownloadFile ( "http://www.albahari.com/ispell/allwords.txt", "WordLookup.txt"); var wordLookup = new HashSet<string> ( File.ReadAllLines ("WordLookup.txt"), StringComparer.InvariantCultureIgnoreCase);
然后,我们将使用单词查找功能创建一个测试“文档”,其中包含一百万个随机单词的数组。构建数组之后,我们将引入一些拼写错误:
var random = new Random(); string[] wordList = wordLookup.ToArray(); string[] wordsToTest = Enumerable.Range (0, 1000000) .Select (i => wordList [random.Next (0, wordList.Length)]) .ToArray(); wordsToTest [12345] = "woozsh"; // Introduce a couple wordsToTest [23456] = "wubsie"; // of spelling mistakes.
现在,我们可以通过针对wordLookup测试wordsToTest来执行并行拼写检查。 PLINQ使这非常容易:
var query = wordsToTest
.AsParallel()
.Select ((word, index) => new IndexedWord { Word=word, Index=index })
.Where (iword => !wordLookup.Contains (iword.Word))
.OrderBy (iword => iword.Index);
query.Dump(); // Display output in LINQPad
这是在LINQPad中显示的输出:
|
OrderedParallelQuery<IndexedWord> (2 items) |
|
|
Word |
Index |
|
woozsh |
12345 |
|
wubsie |
23456 |
IndexedWord是我们定义的自定义结构,如下所示:
structIndexedWord { publicstring Word; publicint Index; }
谓词中的wordLookup.Contains方法为查询提供了一些“肉”,使其值得并行化。
我们可以使用匿名类型而不是IndexedWord结构来稍微简化查询。但是,这会降低性能,因为匿名类型(是类,因此是引用类型)会导致基于堆的分配和后续垃圾收集的开销。
对于顺序查询而言,这种差异可能不足以解决问题,但对于并行查询,偏向基于堆栈的分配可能会非常有利。这是因为基于堆栈的分配是高度可并行化的(因为每个线程都有自己的堆栈),而所有线程必须竞争同一堆-由单个内存管理器和垃圾收集器管理。
使用 ThreadLocal<T>
让我们通过并行创建随机测试词列表本身来扩展我们的示例。我们将此结构构造为LINQ查询,因此应该很容易。这是顺序版本:
string[] wordsToTest = Enumerable.Range (0, 1000000) .Select (i => wordList [random.Next (0, wordList.Length)]) .ToArray();
不幸的是,对random.Next的调用不是线程安全的,因此它不像在查询中插入AsParallel()那样简单。潜在的解决方案是编写一个锁定random的函数。但是,这将限制并发性。更好的选择是使用ThreadLocal <Random>为每个线程创建一个单独的Random对象。然后我们可以并行化查询,如下所示:
var localRandom = new ThreadLocal<Random> ( () => new Random (Guid.NewGuid().GetHashCode()) ); string[] wordsToTest = Enumerable.Range (0, 1000000).AsParallel() .Select (i => wordList [localRandom.Value.Next (0, wordList.Length)]) .ToArray();
在用于实例化Random对象的工厂函数中,我们传入Guid的哈希码,以确保如果在短时间内创建了两个Random对象,它们将产生不同的随机数序列。
何时使用PLINQ
试图在现有应用程序中搜索LINQ查询并尝试并行化它们很诱人。这通常是无济于事的,因为对于LINQ显然是最佳解决方案的大多数问题,它们往往很快就会执行,因此无法从并行化中受益。更好的方法是找到占用大量CPU的瓶颈,然后考虑“可以将其表示为LINQ查询吗?” (这种重组的令人欢迎的副作用是,LINQ通常使代码更小,更易读。)
PLINQ非常适合解决令人尴尬的并行问题。它也可以很好地用于结构化阻止任务,例如一次调用多个Web服务(请参阅调用阻止或I / O密集功能)。
PLINQ对于成像而言可能不是一个好的选择,因为将数百万个像素整理到一个输出序列中会造成瓶颈。相反,最好将像素直接写入数组或非托管内存块,并使用Parallel类或任务并行性来管理多线程。 (但是,可以使用ForAll打败结果归类。如果图像处理算法自然地适合LINQ,则这样做很有意义。)
功能纯度
由于PLINQ在并行线程上运行查询,因此必须注意不要执行线程不安全的操作。特别是,写入变量会产生副作用,因此线程不安
// The following query multiplies each element by its position. // Given an input of Enumerable.Range(0,999), it should output squares. int i = 0; var query = from n in Enumerable.Range(0,999).AsParallel() select n * i++;
我们可以通过使用锁或互锁来使i线程安全递增,但问题仍然存在,即我不一定与输入元素的位置相对应。并且向查询中添加AsOrdered不能解决后一个问题,因为AsOrdered仅确保按与顺序处理顺序一致的顺序输出元素-实际上不会按顺序处理它们。
而是,应重写此查询以使用Select的索引版本:
varquery = Enumerable.Range(0,999).AsParallel().Select ((n, i) => n * i);
为了获得最佳性能,从查询运算符调用的任何方法都应该是线程安全的,因为它不会写入字段或属性(无副作用或功能纯净)。如果它们通过锁定是线程安全的,则查询的并行性潜力将受到限制-锁定的持续时间除以该函数所花费的总时间。
调用阻塞或I / O密集型函数
有时,查询之所以能够长期运行,并不是因为它占用大量CPU资源,而是因为它会等待某些内容,例如网页下载或某些硬件响应。如果您通过在AsParallel之后调用WithDegreeOfParallelism进行提示,PLINQ可以有效地并行化此类查询。例如,假设我们要同时对六个网站执行ping操作。无需使用笨拙的异步委托或手动拆分六个线程,我们可以通过PLINQ查询轻松完成此任务:
from site in new[] { "www.albahari.com", "www.linqpad.net", "www.oreilly.com", "www.takeonit.com", "stackoverflow.com", "www.rebeccarey.com" } .AsParallel().WithDegreeOfParallelism(6) let p = new Ping().Send (site) select new { site, Result = p.Status, Time = p.RoundtripTime }
WithDegreeOfParallelism强制PLINQ同时运行指定数量的任务。在调用诸如Ping.Send之类的阻止功能时,这是必需的,因为PLINQ否则假设查询是CPU密集型的,并相应地分配任务。例如,在两核计算机上,PLINQ可能默认为一次仅运行两个任务,这在这种情况下显然是不可取的。
PLINQ通常为每个任务提供一个线程,并由线程池分配。您可以通过调用ThreadPool.SetMinThreads来加速线程的初始启动。
再举一个例子,假设我们正在编写一个监视系统,并且想要将来自四个安全摄像机的图像重复组合成一个合成图像,以显示在CCTV上。我们将代表以下类别的相机:
class Camera { public readonly int CameraID; public Camera (int cameraID) { CameraID = cameraID; } // Get image from camera: return a simple string rather than an image public string GetNextFrame() { Thread.Sleep (123); // Simulate time taken to get snapshot return "Frame from camera " + CameraID; } }
要获得合成图像,我们必须在四个相机对象的每一个上调用GetNextFrame。假设操作是受I / O限制的,那么即使在单核计算机上,我们也可以将并行化的帧速率提高四倍。 PLINQ通过最少的编程工作即可实现:
Camera[] cameras = Enumerable.Range (0, 4) // Create 4 camera objects. .Select (i => new Camera (i)) .ToArray(); while (true) { string[] data = cameras .AsParallel().AsOrdered().WithDegreeOfParallelism (4) .Select (c => c.GetNextFrame()).ToArray(); Console.WriteLine (string.Join (", ", data)); // Display data... }
GetNextFrame是一种阻塞方法,因此我们使用WithDegreeOfParallelism获得所需的并发性。在我们的示例中,阻塞发生在我们调用Sleep时;在现实生活中,它会阻塞,因为从摄像机获取图像是I / O而不是CPU密集型的。
调用AsOrdered可确保图像以一致的顺序显示。因为序列中只有四个元素,所以对性能的影响可以忽略不计。
改变并行度
您只能在PLINQ查询中调用WithDegreeOfParallelism。如果需要再次调用它,则必须通过在查询中再次调用AsParallel()来强制合并和重新分区查询:
"The Quick Brown Fox" .AsParallel().WithDegreeOfParallelism (2) .Where (c => !char.IsWhiteSpace (c)) .AsParallel().WithDegreeOfParallelism (3) // Forces Merge + Partition .Select (c => char.ToUpper (c))
Cancellation消除
取消要在foreach循环中使用其结果的PLINQ查询很容易:只需中断foreach即可,因为隐式处理了枚举数,该查询将被自动取消。
对于以转换,元素或聚合运算符结尾的查询,可以通过取消标记从另一个线程中取消它。若要插入令牌,请在调用AsParallel之后传入With CancellationTokenSource对象的Token属性,然后调用WithCancellation。然后,另一个线程可以在令牌源上调用Cancel,这会在查询的使用者上引发OperationCanceledException:
IEnumerable<int> million = Enumerable.Range (3, 1000000); var cancelSource = new CancellationTokenSource(); var primeNumberQuery = from n in million.AsParallel().WithCancellation (cancelSource.Token) where Enumerable.Range (2, (int) Math.Sqrt (n)).All (i => n % i > 0) select n; new Thread (() => { Thread.Sleep (100); // Cancel query after cancelSource.Cancel(); // 100 milliseconds. } ).Start(); try { // Start query running: int[] primes = primeNumberQuery.ToArray(); // We'll never get here because the other thread will cancel us. } catch (OperationCanceledException) { Console.WriteLine ("Query canceled"); }
PLINQ不会抢先中止线程,因为这样做有危险。取而代之的是,取消操作会等待每个工作线程以其当前元素结束,然后再结束查询。这意味着查询调用的任何外部方法都将运行完成。
PLINQ优化
输出端优化
PLINQ的优点之一是可以方便地将并行工作的结果整理到单个输出序列中。不过,有时,您最终使用该序列所做的所有工作都会在每个元素上运行一次功能:
foreach (int n in parallelQuery) DoSomething (n);
如果是这种情况,并且您不关心元素的处理顺序,则可以使用PLINQ的ForAll方法提高效率。
ForAll方法在ParallelQuery的每个输出元素上运行委托。它直接链接到PLINQ的内部,而无需进行整理和枚举结果的步骤。举个简单的例子:
"abcdef".AsParallel().Select (c => char.ToUpper(c)).ForAll (Console.Write);
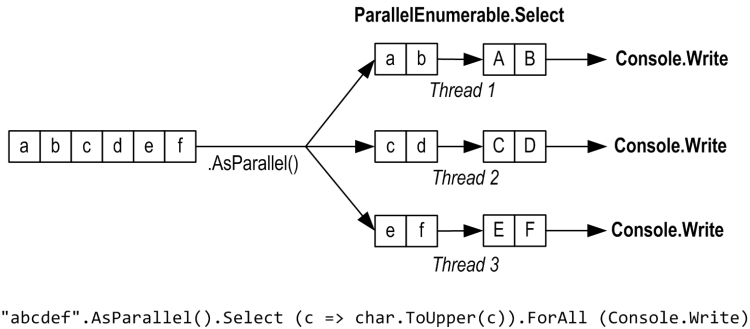
整理和枚举结果并不是一项昂贵的操作,因此,当有大量快速执行的输入元素时,ForAll优化可带来最大的收益。
输入端优化
PLINQ具有三种用于将输入元素分配给线程的分区策略:
|
策略 |
元素分配 |
相对性能 |
|
块分区 |
Dynamic |
普通 |
|
范围分区 |
Static |
较好 |
|
哈希分区 |
Static |
差 |
对于需要比较元素(GroupBy,Join,GroupJoin,Intersect,Except,Union和Distinct)的查询运算符,您别无选择:PLINQ始终使用哈希分区。哈希分区的效率相对较低,因为它必须预先计算每个元素的哈希码(以便具有相同哈希码的元素可以在同一线程上进行处理)。如果发现此速度太慢,则唯一的选择是调用AsSequential以禁用并行化。
对于所有其他查询运算符,您可以选择使用范围分区还是块分区。默认情况下:
- 如果输入序列是可索引的(如果它是数组或实现IList <T>),则PLINQ选择范围分区。
- 否则,PLINQ选择块分区。
简而言之,范围较长的序列可以更快地进行分区,对于每个序列,每个元素都需要花费相似的CPU时间来处理。否则,块分区通常会更快。
强制范围划分:
- 如果查询以Enumerable.Range开头,则将后者替换为ParallelEnumerable.Range。
- 否则,只需在输入序列上调用ToList或ToArray(显然,这本身会导致性能损失,您应该考虑在内)。
ParallelEnumerable.Range不仅仅是调用Enumerable.Range(...)。AsParallel()的快捷方式。它通过激活范围分区来更改查询的性能。
要强制进行块分区,请将输入序列包装在对Partitioner.Create(在System.Collection.Concurrent中)的调用中,如下所示:
int[] numbers = { 3, 4, 5, 6, 7, 8, 9 }; var parallelQuery = Partitioner.Create (numbers, true).AsParallel() .Where (...)
Partitioner.Create的第二个参数指示您要对查询进行负载平衡,这是您希望对块进行分区的另一种方式。
块分区的工作原理是让每个工作线程定期从输入序列中抓取元素的小“块”以进行处理。 PLINQ首先分配非常小的块(一次分配一个或两个元素),然后随着查询的进行增加块的大小:这可确保小序列有效地并行化,大序列不会引起过多的往返。如果一个工人碰巧(容易处理)获得“简单”元素,那么最终将得到更多的块。该系统使每个线程保持同等繁忙(内核处于“平衡”状态);唯一的缺点是从共享输入序列中获取元素需要同步(通常是互斥锁),这可能会导致一些开销和争用。

范围分区绕过常规的输入端枚举,并为每个工作程序预分配了相等数量的元素,从而避免了对输入序列的争用。但是,如果某些线程碰巧获得了轻松的元素并尽早完成,那么它们将处于空闲状态,而其余线程则继续工作。我们较早的素数计算器在范围划分上可能会表现不佳。范围分区最适合的示例是计算前一千万个整数的平方根之和:
ParallelEnumerable.Range (1, 10000000).Sum (i => Math.Sqrt (i))
ParallelEnumerable.Range返回ParallelQuery <T>,因此您无需随后调用AsParallel。
范围分区并不一定要在连续的块中分配元素范围,而是可以选择“分段”策略。例如,如果有两个工作程序,则一个工作程序可能处理奇数元素,而另一个工作程序则处理偶数元素。 TakeWhile运算符几乎可以肯定会触发条带化策略,以避免在序列的后面不必要地处理元素
并行自定义聚合 (Parallelizing Custom Aggregations)
PLINQ无需额外干预即可有效地并行化Sum,Average,Min和Max运算符。但是,聚合运算符对PLINQ提出了特殊的挑战。
如果您不熟悉此运算符,则可以将Aggregate视为Sum,Average,Min和Max的通用版本-换句话说,该运算符可让您插入自定义的累积算法来实现异常聚合。以下内容演示了聚合如何完成Sum的工作
int[] numbers = { 2, 3, 4 }; int sum = numbers.Aggregate (0, (total, n) => total + n); // 9
他对聚合的第一个争论是种子,从种子开始积累。第二个参数是一个表达式,用于在给定新元素的情况下更新累计值。您可以选择提供第三个参数,以根据累加值投影最终结果值。
使用foreach循环和更熟悉的语法可以轻松解决针对Aggregate设计的大多数问题。聚合的优点恰恰是大型或复杂的聚合可以使用PLINQ声明性地并行化。
非种子聚合
您可以在调用Aggregate时忽略种子值,在这种情况下,第一个元素成为隐式种子,而聚合从第二个元素开始。这是前面的示例,没有种子:
int[] numbers = { 1, 2, 3 }; int sum = numbers.Aggregate ((total, n) => total + n); // 6
这样得出的结果与以前相同,但是实际上我们在做不同的计算。之前,我们计算的是0 + 1 + 2 + 3;现在我们计算1 + 2 + 3。我们可以通过乘而不是加来更好地说明差异:
int[] numbers = { 1, 2, 3 }; int x = numbers.Aggregate (0, (prod, n) => prod * n); // 0*1*2*3 = 0 int y = numbers.Aggregate ( (prod, n) => prod * n); // 1*2*3 = 6
稍后我们将看到,无种子聚合具有可并行化的优点,而无需使用特殊的重载。但是,存在一个带有非种子聚合的陷阱:非种子聚合方法旨在用于可交换和关联的委托。如果以其他方式使用,结果要么是不直观的(对于普通查询),要么是不确定的(在将查询与PLINQ并行化的情况下)。例如,考虑以下功能:
(total, n) => total + n * n
这既不是可交换的也不是关联的。 (例如1 + 2 * 2!= 2 + 1 * 1)。让我们看看使用它求和数字2、3和4的平方时会发生什么:
int[] numbers = { 2,3,4 };
int sum = numbers.Aggregate ((total, n) => total + n * n); // 27
代替计算:
2*2 + 3*3 + 4*4 // 29
它计算:
2 + 3*3 + 4*4 // 27
我们可以通过多种方式解决此问题。首先,我们可以将0作为第一个元素:
int[] numbers = { 0,2,3,4 };
这不仅不雅致,而且如果进行并行化,它仍然会给出不正确的结果-因为PLINQ通过选择多个元素作为种子来利用该函数假定的关联性。为了说明,如果我们将聚合函数表示如下:
f(total, n) => total + n * n
然后LINQ to Objects会计算得出:
f(f(f(0,2),3),4)
而PLINQ可以这样做:
f(f(0,2),f(3,4))
结果如下:
第一个分区:a = 0 + 2 * 2(= 4)
第二分区:b = 3 + 4 * 4(= 19)
最终结果:a + b * b(= 365)
甚至偶数:b + a * a(= 35)
有两个好的解决方案。首先是将其转换为种子聚合-种子为零。唯一的麻烦是,使用PLINQ,我们需要使用特殊的重载,才能使查询不按顺序执行(我们将很快看到)。
第二种解决方案是重构查询,以使聚合函数可交换和关联:
int sum = numbers.Select (n => n * n).Aggregate ((total, n) => total + n);
当然,在这种简单的情况下,您可以(并且应该)使用Sum运算符而不是Aggregate:
int sum = numbers.Sum (n => n * n);
实际上,仅求和与平均值就可以走得很远。例如,您可以使用“平均值”来计算均方根:
Math.Sqrt (numbers.Average (n => n * n))
甚至标准差:
double mean = numbers.Average(); double sdev = Math.Sqrt (numbers.Average (n => { double dif = n - mean; return dif * dif; }));
两者都是安全,高效且完全可并行化的。
并行聚集
我们刚刚看到,对于非种子聚合,提供的委托必须是关联的和可交换的。如果违反此规则,PLINQ将给出错误的结果,因为它会从输入序列中提取多个种子,以便同时聚合该序列的多个分区。
对于PLINQ,显式种子聚合似乎是一个安全的选择,但不幸的是,由于依赖于单个种子,因此这些种子通常按顺序执行。为了减轻这种情况,PLINQ提供了另一个Aggregate重载,可让您指定多个种子-或更确切地说,是种子工厂函数。对于每个线程,它执行此功能以生成单独的种子,该种子成为线程本地的累加器,在其中将元素本地聚合到其中。
您还必须提供一个函数来指示如何组合本地和主要累加器。最后,此Aggregate重载(某种程度上是免费的)期望委托对结果执行任何最终转换(您可以通过在结果上自己运行一些函数来轻松实现此最终转换)。因此,这是四个代表,按照传递的顺序排列:
seedFactory
返回一个新的本地累加器
updateAccumulatorFunc
将元素聚合到本地累加器中
CombineAccumulatorFunc
将本地累加器与主累加器组合
resultSelector
将任何最终变换应用于最终结果
在简单的情况下,您可以指定种子值而不是种子工厂。当种子是您希望突变的引用类型时,此策略将失败,因为每个线程将共享同一实例。
为了给出一个非常简单的示例,以下内容将数字数组中的值相加:
numbers.AsParallel().Aggregate ( () => 0, // seedFactory (localTotal, n) => localTotal + n, // updateAccumulatorFunc (mainTot, localTot) => mainTot + localTot, // combineAccumulatorFunc finalResult => finalResult) // resultSelector
该示例的设计之处在于,我们可以使用更简单的方法(例如,非种子聚合或更好的Sum运算符)有效地获得相同的答案。为了给出一个更实际的示例,假设我们要计算给定字符串中英文字母中每个字母的频率。一个简单的顺序解决方案可能看起来像这样:
string text = "Let’s suppose this is a really long string"; var letterFrequencies = new int[26]; foreach (char c in text) { int index = char.ToUpper (c) - 'A'; if (index >= 0 && index <= 26) letterFrequencies [index]++; };
基因测序是输入文本可能很长的一个示例。这样,“字母”将由字母a,c,g和t组成。
为实现此目的,我们可以用对Parallel.ForEach的调用来代替foreach语句(如下节所述),但这将使我们能够处理共享数组上的并发问题。锁定访问该阵列几乎可以消除并行化的潜力。
骨料提供了一个整洁的解决方案。在这种情况下,累加器是一个数组,就像我们前面的示例中的letterFrequencies数组一样。这是使用Aggregate的顺序版本:
int[] result = text.Aggregate ( new int[26], // Create the "accumulator" (letterFrequencies, c) => // Aggregate a letter into the accumulator { int index = char.ToUpper (c) - 'A'; if (index >= 0 && index <= 26) letterFrequencies [index]++; return letterFrequencies; });
现在是并行版本,使用PLINQ的特殊重载
int[] result = text.AsParallel().Aggregate ( () => new int[26], // Create a new local accumulator (localFrequencies, c) => // Aggregate into the local accumulator { int index = char.ToUpper (c) - 'A'; if (index >= 0 && index <= 26) localFrequencies [index]++; return localFrequencies; }, // Aggregate local->main accumulator (mainFreq, localFreq) => mainFreq.Zip (localFreq, (f1, f2) => f1 + f2).ToArray(), finalResult => finalResult // Perform any final transformation ); // on the end result.
注意,本地累积函数使localFrequencies数组发生突变。执行此优化的能力非常重要,这是合法的,因为localFrequency对每个线程都是本地的。
Parallel 类
PFX通过Parallel类中的三种静态方法提供了结构化并行的基本形式:
Parallel.Invoke
并行执行代表数组
Parallel.For
执行C#for循环的并行等效项
Parallel.ForEach
执行C#foreach循环的并行等效项
这三种方法都将阻塞,直到所有工作完成。与PLINQ一样,在未处理的异常之后,剩余的工作程序将在当前迭代之后停止,并将异常(或多个异常)返回给调用方(包装在AggregateException中)。
Parallel.Invoke并行调用
Parallel.Invoke并行执行一个Action委托数组,然后等待它们完成。该方法的最简单版本定义如下:
public static void Invoke (params Action[] actions);
我们可以使用Parallel.Invoke一次下载两个网页:
Parallel.Invoke ( () => new WebClient().DownloadFile ("http://www.linqpad.net", "lp.html"), () => new WebClient().DownloadFile ("http://www.jaoo.dk", "jaoo.html"));
从表面上看,这似乎是创建和等待两个Task对象(或异步委托)的便捷快捷方式。但是有一个重要的区别:Parallel.Invoke如果您传入一百万个代表,则仍然可以有效地工作。这是因为它将大量元素划分为批次,然后将其分配给少数基础任务-而不是为每个委托创建单独的任务。
与Parallel的所有方法一样,在整理结果时,您自己一个人。这意味着您需要牢记线程安全性。例如,以下是线程不安全的:
var data = new List<string>(); Parallel.Invoke ( () => data.Add (new WebClient().DownloadString ("http://www.foo.com")), () => data.Add (new WebClient().DownloadString ("http://www.far.com")));
锁定添加到列表中可以解决此问题,尽管如果您有大量快速执行的委托,锁定会造成瓶颈。更好的解决方案是使用线程安全集合,例如ConcurrentBag在这种情况下将是理想的选择。
Parallel.Invoke也被重载以接受ParallelOptions对象:
public static void Invoke (ParallelOptions options, params Action[] actions);
使用ParallelOptions,您可以插入取消令牌,限制最大并发性并指定自定义任务计划程序。当您执行的任务(大约)多于核心任务时,取消令牌就很重要:取消后,所有未启动的委托都将被放弃。但是,任何已经执行的代表将继续完成。有关如何使用取消标记的示例,请参见取消。
Parallel.For 和 Parallel.ForEach
Parallel.For和Parallel.ForEach等效于C#for和foreach循环,但是每个迭代都是并行执行而不是顺序执行。这是他们(最简单的)签名:
public static ParallelLoopResult For ( int fromInclusive, int toExclusive, Action<int> body) public static ParallelLoopResult ForEach<TSource> ( IEnumerable<TSource> source, Action<TSource> body)
以下顺序的for循环:
for(int i = 0; i <100; i ++) Foo (i);
像这样并行化:
Parallel.For(0,100,i => Foo(i));
或更简单地说:
Parallel.For(0,100,Foo);
以及以下顺序的foreach:
foreach (char c in "Hello, world") Foo (c);
像这样并行化:
Parallel.ForEach ("Hello, world", Foo);
举一个实际的例子,如果我们导入System.Security.Cryptography命名空间,我们可以并行生成六个公共/私有密钥对字符串,如下所示:
var keyPairs = new string[6]; Parallel.For (0, keyPairs.Length, i => keyPairs[i] = RSA.Create().ToXmlString (true));
与Parallel.Invoke一样,我们可以提供Parallel.For和Parallel.ForEach大量的工作项,它们可以有效地划分为几个任务。
后面的查询也可以用PLINQ完成:
string[] keyPairs = ParallelEnumerable.Range (0, 6) .Select (i => RSA.Create().ToXmlString (true)) .ToArray();
外循环与内循环
通常,Parallel.For和Parallel.ForEach在外部循环而不是内部循环上效果最佳。这是因为使用前者,您需要提供更大的工作量来并行化,从而减少了管理开销。通常不需要并行进行内部和外部循环。在以下示例中,我们通常需要100个以上的内核才能从内部并行化中受益:
Parallel.For (0, 100, i => { Parallel.For (0, 50, j => Foo (i, j)); // Sequential would be better });
// for the inner loop.
Parallel.ForEach索引
有时了解循环迭代索引很有用。通过顺序的foreach,
int i = 0; foreach (char c in "Hello, world") Console.WriteLine (c.ToString() + i++);
但是,在并行上下文中,递增共享变量并不是线程安全的。您必须改为使用以下版本的ForEach:
public static ParallelLoopResult ForEach<TSource> ( IEnumerable<TSource> source, Action<TSource,ParallelLoopState,long> body)
我们将忽略ParallelLoopState(将在下一部分中介绍)。目前,我们对Action的long类型的第三个类型参数感兴趣,该参数指示循环索引:
Parallel.ForEach ("Hello, world", (c, state, i) => { Console.WriteLine (c.ToString() + i); });
为使之实用,我们将重新审视使用PLINQ编写的拼写检查器。以下代码加载字典以及一百万个单词的数组以进行测试:
if (!File.Exists ("WordLookup.txt")) // Contains about 150,000 words new WebClient().DownloadFile ( "http://www.albahari.com/ispell/allwords.txt", "WordLookup.txt"); var wordLookup = new HashSet<string> ( File.ReadAllLines ("WordLookup.txt"), StringComparer.InvariantCultureIgnoreCase); var random = new Random(); string[] wordList = wordLookup.ToArray(); string[] wordsToTest = Enumerable.Range (0, 1000000) .Select (i => wordList [random.Next (0, wordList.Length)]) .ToArray(); wordsToTest [12345] = "woozsh"; // Introduce a couple wordsToTest [23456] = "wubsie"; // of spelling mistakes.
我们可以使用Parallel.ForEach的索引版本对wordsToTest数组执行拼写检查,如下所示:
var misspellings = new ConcurrentBag<Tuple<int,string>>(); Parallel.ForEach (wordsToTest, (word, state, i) => { if (!wordLookup.Contains (word)) misspellings.Add (Tuple.Create ((int) i, word)); });
注意,我们必须将结果整理到线程安全的集合中:与使用PLINQ相比,这样做是不利的。与PLINQ相比,优点是我们避免了应用索引的Select查询运算符的成本—它比索引的ForEach效率低。
ParallelLoopState:尽早摆脱循环
由于并行For或ForEach中的循环主体是委托,因此无法使用break语句提早退出循环。而是必须在ParallelLoopState对象上调用Break或Stop:
public class ParallelLoopState { public void Break(); public void Stop(); public bool IsExceptional { get; } public bool IsStopped { get; } public long? LowestBreakIteration { get; } public bool ShouldExitCurrentIteration { get; } }
获得ParallelLoopState很容易:For和ForEach的所有版本都被重载以接受Action <TSource,ParallelLoopState>类型的循环体。因此,要并行化它:
foreach (char c in "Hello, world") if (c == ',') break; else Console.Write (c); do this: Parallel.ForEach ("Hello, world", (c, loopState) => { if (c == ',') loopState.Break(); else Console.Write (c); }); Hlloe
从输出中可以看到,循环体可能以随机顺序完成。除了这种差异之外,调用Break至少会产生与顺序执行循环相同的元素:此示例将始终至少按某种顺序输出字母H,e,l,l和o。相反,调用Stop而不是Break会强制所有线程在当前迭代之后立即完成。在我们的示例中,如果另一个线程落后,调用Stop可以给我们字母H,e,l,l和o的子集。当您找到所需的内容时-出现错误或无法查看结果时,调用Stop非常有用。
Parallel.For和Parallel.ForEach方法返回一个ParallelLoopResult对象,该对象公开名为IsCompleted和LowestBreakIteration的属性。这些告诉您循环是否完成,如果没有结束,则循环在哪个周期中断。
如果LowestBreakIteration返回null,则意味着您在循环上调用了Stop(而不是Break)。
如果循环主体很长,则可能需要其他线程在方法主体中途中断,以防早期中断或停止。您可以通过在代码中的不同位置轮询ShouldExitCurrentIteration属性来实现。停止后或休息后不久,此属性变为true。
取消请求后或循环中引发异常时,ShouldExitCurrentIteration也将变为true。
IsExceptional使您知道另一个线程上是否发生了异常。任何未处理的异常都会导致循环在每个线程的当前迭代之后停止:为避免这种情况,您必须在代码中显式处理异常。
使用本地值进行优化
Parallel.For和Parallel.ForEach各自提供一组重载,这些重载具有称为TLocal的泛型类型参数。这些重载旨在帮助您优化迭代密集型循环的数据整理。最简单的是:
public static ParallelLoopResult For <TLocal> ( int fromInclusive, int toExclusive, Func <TLocal> localInit, Func <int, ParallelLoopState, TLocal, TLocal> body, Action <TLocal> localFinally);
在实践中很少需要这些方法,因为它们的目标方案大部分由PLINQ覆盖(这很幸运,因为这些重载有些令人生畏!)。
本质上,问题是这样的:假设我们要对数字1到10,000,000的平方根求和。计算1000万平方根很容易并行化,但是求和它们的值很麻烦,因为我们必须锁定更新总数:
object locker = new object(); double total = 0; Parallel.For (1, 10000000, i => { lock (locker) total += Math.Sqrt (i); });
并行获得的收益远远超过了获得1000万个锁的成本,再加上由此产生的阻塞。
不过现实是,我们实际上并不需要1000万把锁。想象一下,一群志愿者捡起大量的垃圾。如果所有工人共用一个垃圾桶,那么旅行和争用将使该过程效率极低。显而易见的解决方案是让每个工人都拥有一个私人或“本地”垃圾桶,偶尔将其倒入主垃圾箱。
For和ForEach的TLocal版本完全以这种方式工作。志愿者是内部工作人员线程,本地值表示本地垃圾桶。为了让Parallel能够完成这项工作,您必须向它提供两个额外的代表,以指示:
- 如何初始化新的本地值
- 如何将本地聚合与主值结合
此外,代替正文委托返回void,它应该返回本地值的新聚合。这是我们重构的示例:
o
bject locker = new object(); double grandTotal = 0; Parallel.For (1, 10000000, () => 0.0, // Initialize the local value. (i, state, localTotal) => // Body delegate. Notice that it localTotal + Math.Sqrt (i), // returns the new local total. localTotal => // Add the local value { lock (locker) grandTotal += localTotal; } // to the master value. );
我们仍然必须锁定,但只能围绕将本地价值汇总到总计中。这使该过程大大提高了效率。
如前所述,PLINQ通常非常适合这些情况。我们的示例可以像这样简单地与PLINQ并行化:
ParallelEnumerable.Range(1, 10000000) .Sum (i => Math.Sqrt (i))
(请注意,我们使用ParallelEnumerable来强制范围分区:在这种情况下,由于所有数字都需要花费相同的时间来处理,因此可以提高性能。)
在更复杂的情况下,您可以使用LINQ的Aggregate运算符代替Sum。如果您提供了一个本地种子工厂,那么情况就类似于使用Parallel.For提供本地值功能。
任务并行
任务并行性是与PFX并行化的最低级别方法。在System.Threading.Tasks命名空间中定义了用于此级别的类,这些类包括以下内容:
|
类 |
目的 |
|
用于管理单位的工作 |
|
|
用于管理具有返回值的工作单元 |
|
|
creating tasks |
|
|
用于创建具有相同返回类型的任务和延续 |
|
| 用于管理任务计划 | |
|
用于手动控制任务的工作流程 |
本质上,任务是用于管理可并行工作单元的轻量级对象。通过使用CLR的线程池,任务避免了启动专用线程的开销:这与ThreadPool.QueueUserWorkItem使用的线程池相同,在CLR 4.0中进行了调整,以更高效地与Tasks配合使用(并且通常更高效)。
每当您要并行执行某些任务时,都可以使用任务。但是,它们针对利用多核进行了调整:实际上,Parallel类和PLINQ在内部建立在任务并行性构造上。
- 任务不仅仅提供一种简单高效的方法进入线程池。它们还提供了一些用于管理工作单元的强大功能,其中包括:
- 调整任务的时间表
- 当一项任务从另一项任务开始时,建立父子关系
- 实行合作取消
- 等待一组任务-没有信号构造
- 附加“继续”任务
- 根据多个先前任务安排继续
- 向父类,延续者和任务使用者传播异常
任务还实现了本地工作队列,该优化使您可以有效地创建许多快速执行的子任务,而不会产生单个工作队列否则会引起的争用开销。
任务并行库使您可以用最少的开销创建数百个(甚至数千个)任务。但是,如果您要创建数百万个任务,则需要将这些任务划分为较大的工作单元,以保持效率。 Parallel类和PLINQ自动执行此操作。
Visual Studio 2010提供了一个用于监视任务的新窗口(调试|窗口|并行任务)。这等效于“线程”窗口,但用于任务。 “并行堆栈”窗口还具有用于任务的特殊模式。
创建和启动任务
如我们在线程池讨论的第1部分中所述,您可以通过调用Task.Factory.StartNew并传入Action委托来创建和启动Task:
Task.Factory.StartNew (() => Console.WriteLine ("Hello from a task!"));
通用版本Task <TResult>(Task的子类)使您可以在完成时从任务取回数据:
Task<string> task = Task.Factory.StartNew<string> (() => // Begin task { using (var wc = new System.Net.WebClient()) return wc.DownloadString ("http://www.linqpad.net"); }); RunSomeOtherMethod(); // We can do other work in parallel... string result = task.Result; // Wait for task to finish and fetch result
Task.Factory.StartNew一步创建并启动任务。您可以通过首先实例化Task对象,然后调用Start来分离这些操作。
var task = new Task (() => Console.Write ("Hello")); ... task.Start();
以这种方式创建的任务也可以通过调用RunSynchronously而不是Start来同步运行(在同一线程上)。
您可以通过其状态属性跟踪任务的执行状态。
指定状态对象
实例化任务或调用Task.Factory.StartNew时,可以指定状态对象,该对象将传递给目标方法。如果您想直接调用方法而不是使用lambda表达式,这将很有用:
static void Main()
{
var task = Task.Factory.StartNew (Greet, "Hello");
task.Wait(); // Wait for task to complete.
}
static void Greet (object state) { Console.Write (state); } // Hello
鉴于我们在C#中具有lambda表达式,我们可以更好地使用state对象,即为任务分配一个有意义的名称。然后,我们可以使用AsyncState属性查询其名称:
static void Main() { var task = Task.Factory.StartNew (state => Greet ("Hello"), "Greeting"); Console.WriteLine (task.AsyncState); // Greeting task.Wait(); }
static void Greet (string message) { Console.Write (message); }
Visual Studio在“并行任务”窗口中显示每个任务的AsyncState,因此在此处使用有意义的名称可以大大简化调试。
TaskCreationOptions
您可以通过在调用StartNew(或实例化Task)时指定TaskCreationOptions枚举来调整任务的执行。 TaskCreationOptions是带有以下(组合)值的标志枚举:
LongRunning
PreferFairness
AttachedToParent
LongRunning建议调度程序为任务分配一个线程。这对于长时间运行的任务很有用,因为它们可能会“占用”队列,并迫使短期运行的任务在计划之前等待不合理的时间。 LongRunning也适合阻止任务。
出现任务排队问题是因为任务调度程序通常试图一次使线程上足够多的活动任务保持每个CPU内核繁忙。不为CPU分配过多的活动线程可以避免性能下降,如果操作系统被迫执行大量昂贵的时间分割和上下文切换操作,则性能可能会降低。
PreferFairness告诉调度程序尝试确保任务按照启动顺序进行调度。它通常可以这样做,因为它在内部使用本地工作窃取队列优化了任务调度。对于非常小的(细粒度的)任务,此优化具有实际意义。
AttachedToParent用于创建子任务
子任务
当一个任务开始另一个任务时,可以选择指定TaskCreationOptions.AttachedToParent来建立父子关系:
Task parent = Task.Factory.StartNew (() => { Console.WriteLine ("I am a parent"); Task.Factory.StartNew (() => // Detached task { Console.WriteLine ("I am detached"); }); Task.Factory.StartNew (() => // Child task { Console.WriteLine ("I am a child"); }, TaskCreationOptions.AttachedToParent); });
子任务的特殊之处在于,当您等待父任务完成时,它也会等待所有子任务。当子任务继续执行时,这特别有用,我们很快就会看到。
等待任务
您可以通过两种方式显式等待任务完成:
调用其Wait方法(可选地带有超时)
访问其Result属性(对于Task <TResult>)
您还可以一次等待多个任务-通过静态方法Task.WaitAll(等待所有指定的任务完成)和Task.WaitAny(等待一个任务完成)。
WaitAll类似于依次轮流完成每个任务,但是效率更高,因为它(最多)仅需要一个上下文切换。另外,如果一个或多个任务抛出未处理的异常,则WaitAll仍会等待每个任务-然后重新抛出一个AggregateException,该异常会累积每个故障任务的异常。等同于这样做:
// Assume t1, t2 and t3 are tasks: var exceptions = new List<Exception>(); try { t1.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); } try { t2.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); } try { t3.Wait(); } catch (AggregateException ex) { exceptions.Add (ex); } if (exceptions.Count > 0) throw new AggregateException (exceptions);
调用WaitAny等效于等待每个任务完成时发出的ManualResetEventSlim。
除了超时,还可以将取消令牌传递给Wait方法:这使您可以取消等待,而不是任务本身。
异常处理任务
当您等待任务完成时(通过调用其Wait方法或访问其Result属性),所有未处理的异常都可以方便地重新抛出给调用者,并包装在AggregateException对象中。这通常避免了需要在任务块内编写代码来处理意外的异常;相反,我们可以这样做:
int x = 0; Task<int> calc = Task.Factory.StartNew (() => 7 / x); try { Console.WriteLine (calc.Result); } catch (AggregateException aex) { Console.Write (aex.InnerException.Message); // Attempted to divide by 0 }
您仍然需要对分离的自主任务(未等待的未父任务)进行异常处理,以防止在任务超出范围并被垃圾回收时导致未处理的异常占用应用程序(请注意以下内容)。对于超时等待的任务也是如此,因为超时间隔之后抛出的任何异常都将被“未处理”。
静态TaskScheduler.UnobservedTaskException事件提供了处理未处理任务异常的最后手段。通过处理此事件,您可以拦截否则将终止应用程序的任务异常,并提供自己的逻辑来处理它们。
对于有父母的任务,在父母上等待会隐式地在孩子上等待,然后任何孩子例外都会冒出来TaskCreationOptionsatp = TaskCreationOptions.AttachedToParent;
varparent = Task.Factory.StartNew (() =>
{
Task.Factory.StartNew (() => // Child
{
Task.Factory.StartNew (() => { thrownull; }, atp); // Grandchild
}, atp);
});
// The following call throws a NullReferenceException (wrapped
// in nested AggregateExceptions):
parent.Wait();
有趣的是,如果您在任务的Exception属性抛出异常后对其进行检查,则读取该属性的行为将阻止该异常随后关闭您的应用程序。这样做的理由是PFX的设计师不希望您忽略异常-只要您以某种方式承认异常,他们就不会通过终止程序来惩罚您。
任务中未处理的异常不会导致应用程序立即终止:相反,它被延迟到垃圾收集器赶上任务并调用其终结器为止。由于无法确定您不打算调用Wait或检查其Result或Exception属性,直到任务被垃圾回收之前,终止才被延迟。这种延迟有时可能使您误解错误的原始来源(尽管如果您启用了先发机会例外,Visual Studio的调试器可以提供帮助)。
我们很快就会看到,处理异常的另一种策略是延续。
取消任务
您可以选择在启动任务时传递取消令牌。这使您可以通过前面描述的协作取消模式来取消任务:
varcancelSource = new CancellationTokenSource();
CancellationTokentoken = cancelSource.Token;
Tasktask = Task.Factory.StartNew (() =>
{
// Do some stuff...
token.ThrowIfCancellationRequested(); // Check for cancellation request
// Do some stuff...
}, token);
...
cancelSource.Cancel();;
要检测已取消的任务,请捕获AggregateException并检查内部异常,如下所示:
try
{
task.Wait();
}
catch (AggregateExceptionex)
{
if (ex.InnerException is OperationCanceledException)
Console.Write ("Task canceled!");
}
如果您想显式抛出OperationCanceledException(而不是调用token.ThrowIfCancellationRequested),则必须将取消令牌传递到OperationCanceledException的构造函数中。如果操作失败,该任务将不会以TaskStatus.Canceled状态结束,也不会触发OnlyOnCanceled继续。
如果任务在开始之前被取消,则将无法安排任务-而是将OperationCanceledException立即抛出任务。
由于取消令牌可以被其他API识别,因此您可以将它们传递到其他构造中,并且取消将无缝传播:
varcancelSource = new CancellationTokenSource();
CancellationTokentoken = cancelSource.Token;
Tasktask = Task.Factory.StartNew (() =>
{
// Pass our cancellation token into a PLINQ query:
varquery = someSequence.AsParallel().WithCancellation (token)...
... enumeratequery ...
});
在此示例中,在cancelSource上调用Cancel将取消PLINQ查询,这将在任务主体上引发OperationCanceledException,然后将取消任务。
可以传递给诸如Wait和CancelAndWait之类的方法的取消令牌允许您取消等待操作,而不是任务本身。
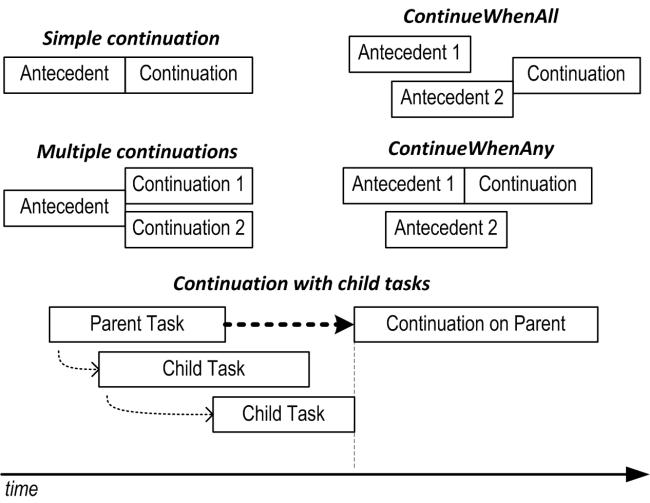
延续
有时,在另一个任务完成(或失败)后立即开始任务很有用。 Task类上的ContinueWith方法正是这样做的:
Task task1 = Task.Factory.StartNew (() => Console.Write ("antecedant..")); Task task2 = task1.ContinueWith (ant => Console.Write ("..continuation"));
任务1(前提)完成,失败或取消后,任务2(继续)将自动启动。 (如果task1在第二行代码运行之前完成,则task2将安排立即执行。)传递给延续的lambda表达式的ant参数是对前一个任务的引用。
我们的示例演示了最简单的延续,其功能类似于以下内容:
Task task = Task.Factory.StartNew (() => { Console.Write ("antecedent.."); Console.Write ("..continuation"); });
但是,基于连续的方法更加灵活,因为您可以先等待任务1,然后再等待任务2。如果task1返回数据,这将特别有用。
另一个(更微妙的)区别是,默认情况下,前提任务和延续任务可以在不同的线程上执行。您可以通过在调用ContinueWith时指定TaskContinuationOptions.ExecuteSynchronously来强制它们在同一线程上执行:这可以通过减少间接性来提高细粒度连续性的性能。
继续和任务<TResult>
与普通任务一样,延续可以是Task <TResult>类型并返回数据。在以下示例中,我们使用一系列链接的任务来计算Math.Sqrt(8 * 2),然后写出结果:
Task.Factory.StartNew<int> (() => 8) .ContinueWith (ant => ant.Result * 2) .ContinueWith (ant => Math.Sqrt (ant.Result)) .ContinueWith (ant => Console.WriteLine (ant.Result)); // 4
为了简单起见,我们的示例有些人为的。在现实生活中,这些lambda表达式将调用计算密集型函数。
延续与例外
延续可以通过前项任务的Exception属性来确定前项是否引发了异常。下面将NullReferenceException的详细信息写入控制台:
Task task1 = Task.Factory.StartNew (() => { throw null; });
Task task2 = task1.ContinueWith (ant => Console.Write (ant.Exception));
如果某个前件引发并且延续无法查询该前件的Exception属性(并且该前件没有等待),则该异常将被视为未处理,并且该应用程序将死亡(除非由TaskScheduler.UnobservedTaskException处理)。
一个安全的模式是抛出先前的异常。只要继续等待,异常就会传播并重新抛出给服务员:
Task continuation = Task.Factory.StartNew (() => { throw null; })
.ContinueWith (ant =>
{
if (ant.Exception != null) throw ant.Exception; // Continue processing...
});
continuation.Wait(); // //现在将异常返回给调用方。
处理异常的另一种方法是为异常结果和非异常结果指定不同的延续。这是通过TaskContinuationOptions完成的:
Task task1 = Task.Factory.StartNew (() => { throw null; });
Task error = task1.ContinueWith (ant => Console.Write (ant.Exception),
TaskContinuationOptions.OnlyOnFaulted);
Task ok = task1.ContinueWith (ant => Console.Write ("Success!"),TaskContinuationOptions.NotOnFaulted);
这种模式在与子任务结合使用时特别有用,我们很快就会看到。
以下扩展方法“吞噬”了任务的未处理异常:
public static void IgnoreExceptions(此Task任务) { task.ContinueWith(t => {var ignore = t.Exception;}, TaskContinuationOptions.OnlyOnFaulted); }
(可以通过添加代码来记录异常来对此进行改进。)使用方法如下:
Task.Factory.StartNew(()=> {throw null;})。IgnoreExceptions();
延续和子任务
延续的强大功能是它们仅在所有子任务完成后才开始。到那时,孩子们抛出的任何异常都会被封存到后续文件中。
在下面的示例中,我们启动了三个子任务,每个任务都抛出一个NullReferenceException。然后,我们通过对父项的延续一口气捕获了所有这些项:
TaskCreationOptions atp = TaskCreationOptions.AttachedToParent; Task.Factory.StartNew(()=> { Task.Factory.StartNew(()=> {throw null;},atp); Task.Factory.StartNew(()=> {throw null;},atp); Task.Factory.StartNew(()=> {throw null;},atp); }) .ContinueWith(p => Console.WriteLine(p.Exception), TaskContinuationOptions.OnlyOnFaulted);
有条件的延续
默认情况下,连续性是无条件调度的-无论前提是完成,引发异常还是被取消。您可以通过TaskContinuationOptions枚举中包含的一组(可组合)标志来更改此行为。控制条件继续的三个核心标志是:
NotOnRanToCompletion = 0x10000, NotOnFaulted = 0x20000, NotOnCanceled = 0x40000,
这些标志是减法,即您应用的次数越多,继续执行的可能性就越小。为了方便起见,还提供以下预组合值:
OnlyOnRanToCompletion = NotOnFaulted |未取消, OnlyOnFaulted = NotOnRanToCompletion |未取消, OnlyOnCanceled = NotOnRanToCompletion |没有故障
(将所有Not *标志[NotOnRanToCompletion,NotOnFaulted,NotOnCanceled]组合在一起是无意义的,因为这将导致连续取消总是被取消。)
“ RanToCompletion”是指成功的先例,没有取消或未处理的异常。
- “错误”是指在先例上引发了未处理的异常。
- “取消”是指以下两件事之一:
前一个通过其取消令牌被取消。换句话说,在前项上引发了OperationCanceledException-其CancellationToken属性与启动时传递给前项的属性相匹配。
该先行词不满足条件延续谓词,因此被隐式取消。
必须牢记,当不借助这些标志执行连续时,不会遗忘或放弃连续,而是将其取消。这意味着该延续本身上的任何延续都将继续运行-除非您使用NotOnCanceled为其断言。例如,考虑一下:
Task t1 = Task.Factory.StartNew (...); Task fault = t1.ContinueWith (ant => Console.WriteLine ("fault"), TaskContinuationOptions.OnlyOnFaulted); Task t3 = fault.ContinueWith (ant => Console.WriteLine ("t3"));
就目前而言,即使t1不会引发异常,t3也将始终按计划进行。这是因为如果t1成功,则将取消故障任务,并且在t3上没有继续限制,则t3将无条件执行。

如果希望t3仅在故障实际发生时才执行,则必须执行以下操作:
Task t3 = fault.ContinueWith(ant => Console.WriteLine(“ t3”),
TaskContinuationOptions.NotOnCanceled);
(或者,我们可以指定OnlyOnRanToCompletion;不同之处在于,如果在错误内引发异常,则t3将不执行。)
具有多个前提的连续性
延续的另一个有用功能是,您可以安排它们基于多个前提的完成而执行。 ContinueWhenAll计划所有先决条件完成后的执行;当一个前提完成时,ContinueWhenAny计划执行。这两种方法都在TaskFactory类中定义:
var task1 = Task.Factory.StartNew(()=> Console.Write(“ X”)); var task2 = Task.Factory.StartNew(()=> Console.Write(“ Y”)); varcontinuation = Task.Factory.ContinueWhenAll( new [] {task1,task2},task => Console.WriteLine(“ Done”));
在写入“ XY”或“ YX”之后写入“完成”。 lambda表达式中的task参数使您可以访问已完成任务的数组,这在前提条件返回数据时很有用。以下示例将两个先前任务返回的数字加在一起:
// task1和task2在现实生活中会调用复杂的函数:
Task <int> task1 = Task.Factory.StartNew(()=> 123);
Task <int> task2 = Task.Factory.StartNew(()=> 456);
Task <int> task3 = Task <int> .Factory.ContinueWhenAll(
new [] {task1,task2},task => task.Sum(t => t.Result));
Console.WriteLine(task3.Result); // 579
在此示例中,我们在对Task.Factory的调用中包含了<int>类型参数,以阐明我们正在获取通用任务工厂。但是,类型参数不是必需的,因为它将由编译器推断出来。
单个前提的多个延续
在同一任务上多次调用ContinueWith会在一个前项上创建多个延续。前一个条件完成时,所有继续将一起开始(除非您指定TaskContinuationOptions.ExecuteSynchronously,在这种情况下,这些继续将按顺序执行)。
以下内容等待一秒钟,然后写入“ XY”或“ YX”:
var t = Task.Factory.StartNew(()=> Thread.Sleep(1000)); t.ContinueWith(ant => Console.Write(“ X”)); t.ContinueWith(ant => Console.Write(“ Y”));
任务计划程序和用户界面
任务计划程序将任务分配给线程。所有任务都与任务计划程序相关联,该任务计划程序由抽象TaskScheduler类表示。该框架提供了两个具体的实现:与CLR线程池协同工作的默认调度程序,以及同步上下文调度程序。后者的设计(主要是)帮助您使用WPF和Windows Forms的线程模型,该模型要求UI元素和控件只能从创建它们的线程中进行访问。例如,假设我们想在后台从Web服务中获取一些数据,然后使用其结果更新名为lblResult的WPF标签。我们可以将其分为两个任务:
调用方法以从Web服务获取数据(先验任务)。
用结果更新lblResult(继续任务)。
如果对于继续任务,我们指定在构造窗口时获得的同步上下文调度程序,则可以安全地更新lblResult:
public partial class MyWindow : Window { TaskScheduler _uiScheduler; // Declare this as a field so we can use // it throughout our class. public MyWindow() { InitializeComponent(); // Get the UI scheduler for the thread that created the form: _uiScheduler = TaskScheduler.FromCurrentSynchronizationContext(); Task.Factory.StartNew<string> (SomeComplexWebService) .ContinueWith (ant => lblResult.Content = ant.Result, _uiScheduler); } string SomeComplexWebService() { ... } }
也可以编写我们自己的任务计划程序(通过将TaskScheduler子类化),尽管只有在非常特殊的情况下才需要这样做。对于自定义计划,您通常会使用TaskCompletionSource,我们将在稍后进行介绍。
TaskFactory
调用Task.Factory时,您是在Task上调用静态属性,该属性会返回默认的TaskFactory对象。任务工厂的目的是创建任务,特别是三种任务:
- “普通”任务(通过StartNew)
- 具有多个前提的继续(通过ContinueWhenAll和ContinueWhenAny)
- 封装遵循异步编程模型的方法的任务(通过FromAsync)
有趣的是,TaskFactory是实现后两个目标的唯一方法。就StartNew而言,TaskFactory纯粹是一种便利,并且在技术上是多余的,因为您只需实例化Task对象并对其调用Start。
创建自己的任务工厂
TaskFactory不是抽象工厂:您实际上可以实例化该类,当您要使用TaskCreationOptions,TaskContinuationOptions或TaskScheduler的相同(非标准)值重复创建任务时,此方法很有用。例如,如果我们想重复创建长期运行的父任务,则可以如下创建自定义工厂:
var factory = new TaskFactory( TaskCreationOptions.LongRunning | TaskCreationOptions.AttachedToParent, TaskContinuationOptions.None);
然后,只需在工厂上调用StartNew即可创建任务:
Task task1 = factory.StartNew (Method1); Task task2 = factory.StartNew (Method2); ...
自定义继续选项在调用ContinueWhenAll和ContinueWhenAny时应用。
TaskCompletionSource
Task类实现了两个不同的功能:
它安排委托在池线程上运行。
它提供了一组丰富的功能来管理工作项(继续,子任务,异常封送等)。
有趣的是,这两件事并没有同时出现:您可以利用任务的功能来管理工作项,而无需安排在线程池上运行的任何东西。启用这种使用方式的类称为TaskCompletionSource。
要使用TaskCompletionSource,您只需实例化该类。它公开了一个Task属性,该属性返回一个可以等待并附加延续的任务,就像其他任何任务一样。但是,该任务完全由TaskCompletionSource对象通过以下方法控制:
publicclassTaskCompletionSource<TResult>
{
publicvoid SetResult (TResultresult);
publicvoid SetException (Exceptionexception);
publicvoid SetCanceled();
publicbool TrySetResult (TResultresult);
publicbool TrySetException (Exceptionexception);
publicbool TrySetCanceled();
...
}
如果多次调用,则SetResult,SetException或SetCanceled会引发异常。 Try *方法将返回false。
TResult与任务的结果类型相对应,因此TaskCompletionSource <int>为您提供一个Task <int>。如果您希望没有结果的任务,请创建一个TaskCompletionSource对象,并在调用SetResult时传递null。然后,您可以将Task <object>强制转换为Task。
下面的示例等待五秒钟后打印123:
var source = new TaskCompletionSource<int>(); new Thread (() => { Thread.Sleep (5000); source.SetResult (123); }) .Start(); Task<int> task = source.Task; // Our "slave" task. Console.WriteLine (task.Result); // 123
稍后,我们将展示如何使用BlockingCollection编写生产者/消费者队列。然后,我们演示TaskCompletionSource如何通过允许等待和取消排队的工作项来改善解决方案。
使用AggregateException
如我们所见,PLINQ,Parallel类和Tasks自动将异常封送给使用者。要了解为什么这是必需的,请考虑以下LINQ查询,该查询在第一次迭代时引发DivideByZeroException:
try { var query = from i in Enumerable.Range (0, 1000000) select 100 / i; ... } catch (DivideByZeroException) { ... }
如果我们要求PLINQ并行化此查询,并且它忽略了异常的处理,则DivideByZeroException可能会抛出到单独的线程中,从而绕过我们的catch块并导致应用程序死亡。
因此,异常会被自动捕获并重新抛出给调用者。但不幸的是,它并不像捕获DivideByZeroException那样简单。由于这些库利用许多线程,因此实际上有可能同时引发两个或更多异常。为了确保报告所有异常,因此将异常包装在AggregateException容器中,该容器公开了一个InnerExceptions属性,该属性包含每个捕获的异常
try { var query = from i in ParallelEnumerable.Range (0, 1000000) select 100 / i; // Enumerate query ... } catch (AggregateException aex) { foreach (Exception ex in aex.InnerExceptions) Console.WriteLine (ex.Message); }
PLINQ和Parallel类都在遇到第一个异常时结束查询或循环执行-通过不处理任何其他元素或循环体。但是,在当前循环完成之前,可能会引发更多异常。 AggregateException中的第一个异常在InnerException属性中可见。
Flatten和Handle
AggregateException类提供了几种简化异常处理的方法:Flatten和Handle。
Flatten
AggregateExceptions通常会包含其他AggregateExceptions。例如,如果子任务引发异常,则可能发生这种情况。您可以通过调用Flatten消除任何级别的嵌套以简化处理。此方法返回一个新的AggregateException,带有内部异常的简单平面列表:
catch (AggregateExceptionaex)
{
foreach (Exception ex in aex.Flatten().InnerExceptions)
myLogWriter.LogException (ex);
}
Handle
有时,仅捕获特定的异常类型并重新抛出其他类型很有用。 AggregateException上的Handle方法提供了执行此操作的快捷方式。它接受一个异常谓词,该谓词遍历每个内部异常:
publicvoid Handle (Func<Exception, bool>predicate)
如果谓词返回true,则认为该异常已“处理”。委托运行完所有异常后,将发生以下情况:
如果所有异常都得到“处理”(委托返回的是true),则不会重新抛出该异常。
如果委托为其返回了任何异常(“未处理”),则将构建一个新的AggregateException,其中包含这些异常,并将其重新抛出。
例如,以下结果最终抛出了另一个AggregateException,它包含一个NullReferenceException:
var parent = Task.Factory.StartNew (() => { // We’ll throw 3 exceptions at once using 3 child tasks: int[] numbers = { 0 }; var childFactory = new TaskFactory (TaskCreationOptions.AttachedToParent, TaskContinuationOptions.None); childFactory.StartNew (() => 5 / numbers[0]); // Division by zero childFactory.StartNew (() => numbers [1]); // Index out of range childFactory.StartNew (() => { throw null; }); // Null reference }); try { parent.Wait(); } catch (AggregateException aex) { aex.Flatten().Handle (ex => // Note that we still need to call Flatten { if (ex is DivideByZeroException) { Console.WriteLine ("Divide by zero"); return true; // This exception is "handled" } if (ex is IndexOutOfRangeException) { Console.WriteLine ("Index out of range"); return true; // This exception is "handled" } return false; // All other exceptions will get rethrown }); }
并发集合
Framework 4.0在System.Collections.Concurrent命名空间中提供了一组新集合。所有这些都是完全线程安全的:
|
Concurrent collection |
Nonconcurrent equivalent |
|
|
|
|
|
|
|
(none) |
|
|
(none) |
|
|
|
|
当您需要线程安全的集合时,并发集合有时在常规多线程中很有用。但是,有一些警告:
- 调整并发集合以进行并行编程。在几乎并发的情况下,常规集合的性能要优于它们。
- 线程安全的集合不能保证使用它的代码将是线程安全的。
- 如果在另一个线程修改它的同时枚举并发集合,则不会引发异常。相反,您会混合使用新旧内容。
- 没有并发版本的List <T>。
- 并发堆栈,队列和包类在内部通过链表实现。这使它们的内存效率比非并发Stack和Queue类低,但对于并发访问则更好,因为链接列表有助于无锁或低锁实现。 (这是因为将节点插入到链表中仅需要更新几个引用,而将元素插入到类似List <T>的结构中则可能需要移动成千上万个现有元素。)
换句话说,这些集合不仅为使用带锁的普通集合提供了快捷方式。为了演示,如果我们在一个线程上执行以下代码:
vard = new ConcurrentDictionary<int,int>();
for (int i = 0; i < 1000000; i++) d[i] = 123;
它的运行速度比这慢三倍:
vard = new Dictionary<int,int>();
for (int i = 0; i < 1000000; i++) lock (d) d[i] = 123;
(但是,从ConcurrentDictionary读取数据是快速的,因为读取是无锁的。)
并发集合与常规集合的不同之处还在于,它们公开了执行原子测试和操作操作的特殊方法,例如TryPop。这些方法大多数都是通过IProducerConsumerCollection <T>接口统一的。
IProducerConsumerCollection <T>
生产者/消费者集合是两个主要用例之一:
- 添加元素(“生产中”)
- 在删除元素的同时检索元素(“消耗”)
经典示例是堆栈和队列。生产者/消费者集合在并行编程中非常重要,因为它们有助于高效的无锁实现。
IProducerConsumerCollection <T>接口表示线程安全的生产者/消费者集合。以下类实现此接口:
IProducerConsumerCollection <T>扩展了ICollection,并添加了以下方法:
void CopyTo (T[] array, int index); T[] ToArray(); bool TryAdd (T item); bool TryTake (out T item);;
TryAdd和TryTake方法测试是否可以执行添加/删除操作,如果可以,则执行添加/删除操作。测试和执行是原子执行的,无需像对待常规集合那样进行锁定:
int result;
lock (myStack)if (myStack.Count > 0) result = myStack.Pop();
如果集合为空,则TryTake返回false。在提供的三个实现中,TryAdd总是成功并返回true。但是,如果您编写了自己的禁止重复的并发集合,则如果该元素已经存在,则可以使TryAdd返回false(例如,如果您编写了一个并发集合)。
TryTake删除的特定元素由子类定义:
- 对于堆栈,TryTake删除最近添加的元素。
- 对于队列,TryTake删除最近最少添加的元素。
- 有了袋子,TryTake会删除它可以最有效地删除的任何元素。
这三个具体的类主要是显式实现TryTake和TryAdd方法,并通过更具体命名的公共方法(如TryDequeue和TryPop)公开相同的功能。
ConcurrentBag <T>存储对象的无序集合(允许重复)。 ConcurrentBag <T>适用于以下情况:当您不在乎调用Take或TryTake时会得到哪个元素。
ConcurrentBag <T>在并发队列或堆栈上的好处是,当一个包被多个线程一次调用时,bag的Add方法几乎没有争用。相反,在队列或堆栈上并行调用Add会引起一些争用(尽管比锁定非并发集合要少得多)。在每个并发包上调用Take也是非常有效的-只要每个线程所占用的元素不超过Added。
在并发包中,每个线程都有自己的私有链接列表。元素被添加到属于调用Add的线程的私有列表中,从而消除了争用。枚举包时,枚举器遍历每个线程的私有列表,依次产生其每个元素。
致电Take时,手提袋会首先查看当前线程的私人列表。如果至少有一个要素,则可以轻松完成任务(在大多数情况下)而无需争用。但是,如果列表为空,则必须“窃取”另一个线程的私有列表中的元素,并可能引起争用。
因此,确切地说,调用Take将为您提供该线程上最近添加的元素。如果该线程上没有元素,它将为您提供最近在另一个线程上添加的元素,该元素是随机选择的。
当您的收藏夹上的并行操作主要包含添加元素时,或者当线程中的收支平衡时,并发袋是理想的选择。我们在使用Parallel.ForEach实现并行拼写检查器时看到了前一个示例。
varmisspellings = new ConcurrentBag<Tuple<int,string>>();
Parallel.ForEach (wordsToTest, (word, state, i) =>
{
if (!wordLookup.Contains (word))
misspellings.Add (Tuple.Create ((int) i, word));
});
对于生产者/消费者队列,并发包将是一个糟糕的选择,因为元素是由不同的线程添加和删除的。
BlockingCollection <T>
如果您在前面讨论过的任何生产者/消费者集合上调用TryTake,则:
ConcurrentStack<T>
ConcurrentQueue<T>
ConcurrentBag<T>
并且集合为空,该方法返回false。有时,在这种情况下等到元素可用时会更有用。
PFX的设计人员没有将此功能重载TryTake方法(在允许取消令牌和超时后会导致成员崩溃),PFX的设计师将此功能封装到了一个名为BlockingCollection <T>的包装器类中。阻塞集合包装实现IProducerConsumerCollection <T>的任何集合,并允许您从已封装的集合中获取元素-如果没有可用的元素,则阻塞。
阻止集合还允许您限制集合的总大小,如果超出该大小,则阻止生产者。以这种方式限制的集合称为有界块集合。
要使用BlockingCollection <T>:
- 实例化该类,可以选择指定要包装的IProducerConsumerCollection <T>以及集合的最大大小(绑定)。
- 调用Add或TryAdd将元素添加到基础集合。
- 调用Take或TryTake从底层集合中删除(消耗)元素。
如果在不传递集合的情况下调用构造函数,则该类将自动实例化ConcurrentQueue <T>。通过使用生产方法和使用方法,您可以指定取消标记和超时。如果集合大小有界,则Add和TryAdd可能会阻塞;集合为空时,使用Take和TryTake块。
消费元素的另一种方法是调用GetConsumingEnumerable。这将返回一个(潜在的)无限序列,该序列会在元素可用时产生它们。您可以通过调用CompleteAdding强制序列结束:此方法还可以防止其他元素入队。
之前,我们使用Wait和Pulse编写了一个生产者/消费者队列。这是重构为使用BlockingCollection <T>的同一类(除了例外处理):
public class PCQueue : IDisposable { BlockingCollection<Action> _taskQ = new BlockingCollection<Action>(); public PCQueue (int workerCount) { // Create and start a separate Task for each consumer: for (int i = 0; i < workerCount; i++) Task.Factory.StartNew (Consume); } public void Dispose() { _taskQ.CompleteAdding(); } public void EnqueueTask (Action action) { _taskQ.Add (action); } void Consume() { // This sequence that we’re enumerating will block when no elements // are available and will end when CompleteAdding is called. foreach (Action action in _taskQ.GetConsumingEnumerable()) action(); // Perform task. }
}
因为我们没有将任何东西传递给BlockingCollection的构造函数,所以它会自动实例化并发队列。如果我们传递了ConcurrentStack,我们最终将获得生产者/消费者堆栈。
BlockingCollection还提供了称为AddToAny和TakeFromAny的静态方法,这些方法可让您在指定多个阻止集合的同时添加或获取元素。然后由能够处理请求的第一个集合来执行该操作。
利用TaskCompletionSource
我们刚刚写的生产者/消费者是不灵活的,因为我们无法跟踪工作项目入队。如果可以,那就太好了:
- 知道工作项何时完成。
- 取消未启动的工作项目。
- 优雅地处理工作项引发的任何异常。
理想的解决方案是让EnqueueTask方法返回一些对象,从而为我们提供刚刚描述的功能。好消息是,已经有一个类可以执行此操作-Task类。我们需要做的就是通过TaskCompletionSource劫持任务的控制权:
public class PCQueue : IDisposable { class WorkItem { public readonly TaskCompletionSource<object> TaskSource; public readonly Action Action; public readonly CancellationToken? CancelToken; public WorkItem ( TaskCompletionSource<object> taskSource, Action action, CancellationToken? cancelToken) { TaskSource = taskSource; Action = action; CancelToken = cancelToken; } } BlockingCollection<WorkItem> _taskQ = new BlockingCollection<WorkItem>(); public PCQueue (int workerCount) { // Create and start a separate Task for each consumer: for (int i = 0; i < workerCount; i++) Task.Factory.StartNew (Consume); } public void Dispose() { _taskQ.CompleteAdding(); } public Task EnqueueTask (Action action) { return EnqueueTask (action, null); } public Task EnqueueTask (Action action, CancellationToken? cancelToken) { var tcs = new TaskCompletionSource<object>(); _taskQ.Add (new WorkItem (tcs, action, cancelToken)); return tcs.Task; } void Consume() { foreach (WorkItem workItem in _taskQ.GetConsumingEnumerable()) if (workItem.CancelToken.HasValue && workItem.CancelToken.Value.IsCancellationRequested) { workItem.TaskSource.SetCanceled(); } else try { workItem.Action(); workItem.TaskSource.SetResult (null); // Indicate completion } catch (OperationCanceledException ex) { if (ex.CancellationToken == workItem.CancelToken) workItem.TaskSource.SetCanceled(); else workItem.TaskSource.SetException (ex); } catch (Exception ex) { workItem.TaskSource.SetException (ex); } } }
在EnqueueTask中,我们排队一个工作项目,该工作项目封装了目标委托和任务完成源-这使我们以后可以控制返回给使用者的任务。
在“消费”中,我们首先检查工作项目出队后是否已取消任务。如果没有,我们将运行委托,然后在任务完成源上调用SetResult以指示其完成。
这是我们如何使用此类的方法
var pcQ = new PCQueue (1); Task task = pcQ.EnqueueTask (() => Console.WriteLine ("Easy!")); ...
现在,我们可以等待任务,对其执行延续,让异常传播到父任务的延续等等。换句话说,在实现我们自己的调度程序的同时,我们拥有了丰富的任务模型。
自旋锁和自旋等待
在并行编程中,短暂的旋转通常比阻塞更好,因为它避免了上下文切换和内核转换的开销。 SpinLock和SpinWait旨在在这种情况下提供帮助。它们的主要用途是编写自定义同步结构。
SpinLock和SpinWait是结构而不是类!该设计决策是一种极端的优化技术,可以避免间接和垃圾回收的成本。这意味着您必须注意不要无意间复制实例,例如,将它们传递给没有ref修饰符的另一种方法,或者将它们声明为只读字段。这对于SpinLock而言尤其重要。
自旋锁
SpinLock结构使您可以锁定而无需花费上下文切换的成本,但代价是保持线程旋转(无用的繁忙)。当锁定非常短暂时(例如,从头开始编写线程安全的链表),这种方法在竞争激烈的情况下有效。
如果您将自旋锁的争用时间过长(我们最多只能说毫秒),它将产生其时间片,从而像普通锁一样导致上下文切换。重新计划后,它将以“自旋收益”的连续循环再次收益。与完全旋转相比,这消耗的CPU资源要少得多,但比阻塞消耗的资源更多。
- 在单核计算机上,如果有竞争,自旋锁将立即开始“自旋屈服”。
- 使用SpinLock类似于使用普通锁,不同之处在于:
- 自旋锁是结构(如前所述)。
- 自旋锁不是可重入的,这意味着您不能在同一线程上连续两次在同一自旋锁上调用Enter。如果违反此规则,它将引发异常(如果启用了所有者跟踪)或死锁(如果禁用了所有者跟踪)。您可以指定在构造自旋锁时是否启用所有者跟踪。所有者跟踪会导致性能下降。
SpinLock使您可以通过属性IsHeld以及是否启用所有者跟踪的IsHeldByCurrentThread查询是否已锁定。
没有等效于C#的lock语句来提供SpinLock语法糖。
另一个区别是,在调用Enter时,必须遵循提供lockTaken参数的可靠模式(几乎总是在try / finally块中完成)。
这是一个例子:
var spinLock = new SpinLock (true); // Enable owner tracking bool lockTaken = false; try { spinLock.Enter (ref lockTaken); // Do stuff... } finally { if (lockTaken) spinLock.Exit(); }
与普通锁一样,在Enter方法(且仅当Enter方法引发异常)且未使用锁的情况下,调用Enter后lockTaken将为false。这在非常罕见的情况下会发生(例如在线程上调用Abort或引发OutOfMemoryException),并使您可靠地知道是否随后调用Exit。
SpinLock还提供了一个接受超时的TryEnter方法。
鉴于SpinLock具有笨拙的价值型语义和缺乏语言支持,几乎就像他们希望您每次使用它时一样遭受痛苦!解除普通锁之前,请仔细考虑。
编写自己的可重用同步结构时,SpinLock最有意义。即使那样,自旋锁也没有听起来那么有用。它仍然限制了并发性。而且浪费CPU时间做无用的事情。通常,一个更好的选择是在SpinWait的帮助下,花一些时间进行一些投机活动。
旋转等待
SpinWait帮助您编写旋转而不是阻止旋转的无锁代码。它通过实施保护措施来工作,以避免因旋转而可能出现的资源匮乏和优先级倒置的危险。
SpinWait的无锁编程与多线程一样具有硬性,旨在用于没有任何高级构造可以使用的情况。先决条件是了解非阻塞同步。
为什么我们需要SpinWait
假设我们编写了一个纯粹基于简单标志的基于自旋的信号系统:
bool _proceed; void Test() { // Spin until another thread sets _proceed to true: while (!_proceed) Thread.MemoryBarrier(); ... }
如果在_proceed已经为真时运行测试,或者如果_proceed在几个周期内变为真,那么这将非常高效。但是现在假设_proceed保持为假状态持续了几秒钟,并且四个线程同时调用了Test。然后旋转将完全消耗四核CPU!这将导致其他线程运行缓慢(资源匮乏),包括可能最终将_proceed设置为true(优先级倒置)的线程。这种情况在单核计算机上更为严重,在这种情况下,旋转几乎总是会导致优先级倒置。 (尽管如今单核计算机很少见,但单核虚拟机却不是。)
SpinWait通过两种方式解决这些问题。首先,它将CPU密集型旋转限制为一定的迭代次数,然后在每次旋转时生成时间片(通过调用Thread.Yield和Thread.Sleep),从而降低了资源消耗。其次,它检测它是否在单核计算机上运行,如果是,则在每个周期都产生结果。
如何使用SpinWait
有两种使用SpinWait的方法。第一种是调用其静态方法SpinUntil。此方法接受一个谓词(以及可选的超时):
bool _proceed; void Test() { SpinWait.SpinUntil (() => { Thread.MemoryBarrier(); return _proceed; }); ... } The other (more flexible) way to use SpinWait is to instantiate the struct and then to call SpinOnce in a loop: bool _proceed; void Test() { var spinWait = new SpinWait(); while (!_proceed) { Thread.MemoryBarrier(); spinWait.SpinOnce(); } ... }
前者是后者的捷径。
SpinWait如何工作
在其当前实现中,SpinWait在屈服之前执行CPU密集型旋转10次迭代。但是,它不会在每个周期之后立即返回给调用者:而是调用Thread.SpinWait在指定的时间段内通过CLR(最终是操作系统)旋转。此时间段最初为几十纳秒,但每次迭代都会翻倍,直到10次迭代结束。这样可确保在CPU密集型旋转阶段花费的总时间中具有一定的可预测性,CLR和操作系统可以根据条件进行调整。通常,它在几十微秒的区域内-很小,但比上下文切换的成本还要高。
在单核计算机上,SpinWait会在每次迭代时产生收益。您可以通过属性NextSpinWillYield测试SpinWait是否在下一次旋转时产生。
如果SpinWait处于“旋转生成”模式的时间足够长(可能为20个周期),它将周期性地睡眠数毫秒,以进一步节省资源并帮助其他线程进行进程。
使用SpinWait和Interlocked.CompareExchange进行无锁更新。
SpinWait与Interlocked.CompareExchange一起可以原子地更新从原始值(读取-修改-写入)计算出的字段。例如,假设我们想将字段x乘以10。仅执行以下操作就不是线程安全的:
x = x * 10;
出于同样的原因,就像在非阻塞同步中看到的那样,增加字段不是线程安全的。
没有锁的正确方法如下:
- 将x的“快照”放入局部变量。
- 计算新值(在这种情况下,将快照乘以10)。
- 如果快照仍是最新的,则将计算出的值写回(必须通过调用Interlocked.CompareExchange自动完成此步骤)。
- 如果快照过时,请旋转并返回到步骤1。
例如:
int x; void MultiplyXBy (int factor) { var spinWait = new SpinWait(); while (true) { int snapshot1 = x; Thread.MemoryBarrier(); int calc = snapshot1 * factor; int snapshot2 = Interlocked.CompareExchange (ref x, calc, snapshot1); if (snapshot1 == snapshot2) return; // No one preempted us. spinWait.SpinOnce(); } }
通过取消对Thread.MemoryBarrier的调用,我们可以(略)提高性能。我们可以避免这种情况,因为CompareExchange无论如何都会生成内存屏障-因此,如果快照1在其第一次迭代中恰好读取过时的值,则可能发生的最糟糕的情况是额外的旋转。
如果该字段的当前值与第三个参数匹配,则Interlocked.CompareExchange将使用指定的值更新该字段。然后,它返回该字段的旧值,因此您可以通过将其与原始快照进行比较来测试该字段是否成功。如果值不同,则意味着另一个线程优先于您,在这种情况下,您旋转并重试。
CompareExchange被重载,也可以使用对象类型。我们可以通过编写适用于所有引用类型的无锁更新方法来利用此重载:
static void LockFreeUpdate<T> (ref T field, Func <T, T> updateFunction) where T : class { var spinWait = new SpinWait(); while (true) { T snapshot1 = field; T calc = updateFunction (snapshot1); T snapshot2 = Interlocked.CompareExchange (ref field, calc, snapshot1); if (snapshot1 == snapshot2) return; spinWait.SpinOnce(); } }
我们可以使用以下方法来编写不带锁的线程安全事件(实际上,这是C#4.0编译器现在默认情况下对事件执行的操作)
EventHandler _someDelegate; public event EventHandler SomeEvent { add { LockFreeUpdate (ref _someDelegate, d => d + value); } remove { LockFreeUpdate (ref _someDelegate, d => d - value); } }
自旋等待与自旋锁
我们可以通过将对共享字段的访问权包装在SpinLock周围来解决这些问题。但是,自旋锁定的问题在于,一次旋转仅允许一个线程继续进行-尽管自旋锁(通常)消除了上下文切换开销。使用SpinWait,我们可以进行推测性操作,并且不承担任何争用。如果确实被抢占,我们只需重试即可。花CPU时间做一些可能有用的事情比浪费自旋锁中的CPU时间要好!
最后,考虑以下类:
class Test { ProgressStatus _status = new ProgressStatus (0, "Starting"); class ProgressStatus // Immutable class { public readonly int PercentComplete; public readonly string StatusMessage; public ProgressStatus (int percentComplete, string statusMessage) { PercentComplete = percentComplete; StatusMessage = statusMessage; } } }
我们可以使用LockFreeUpdate方法来“增加” _status中的PercentComplete字段,如下所示:
LockFreeUpdate (ref _status, s => new ProgressStatus (s.PercentComplete + 1, s.StatusMessage));
请注意,我们正在基于现有值创建一个新的ProgressStatus对象。多亏了LockFreeUpdate方法,读取不存在的PercentComplete值,将其递增并写回的操作不会被不安全地抢占:可靠地检测到任何抢占,触发了旋转并重试