使用kettle设计ETL设计完成后,我们就需要按照我们业务的需要对我们设计好的ETL程序,ktr或者kjb进行调度,以实现定时定点的数据抽取,或者说句转换工作,我们如何实现调度呢?
场景:在/works/wxj/test目录下放着两个ktr模型,我们需要每天晚上24点定时抽取数据
如图所示:

方法一:最简单的方法就是设计一个kjb,拖两个ktr控件,把两个ktr模型串起来,然后定时的调度这个kjb文件即可实现每天定时的抽取数据。
方法二:如果随着业务的增多,ktr文件原来越多,那么上面的情况操作起来就很麻烦,我们在目录下新增加一个ktr模型我们就要去修改总的kjb,把新增加的ktr串进去,这样才能保证新增加的ktr被执行到,那么下面我们来尝试另一种方法,只要把新设计好的ktr文件放入指定目录,调度程序就会遍历执行该目录下面的所有程序。
2.1:整体描述:
大概需要的控件有:
(1)Get repository names根据指定目录得到所有ktr或者kjb的列表

(2)复制记录到结果

(3)从结果获取记录

(4)设置环境变量

(5)表输入与表述出job中的ktr与kjb
2.2:设计过程
step1:新建tran_getall.ktr(读取指定目录下的对象,将数据写入到内存)

控件1设计如下
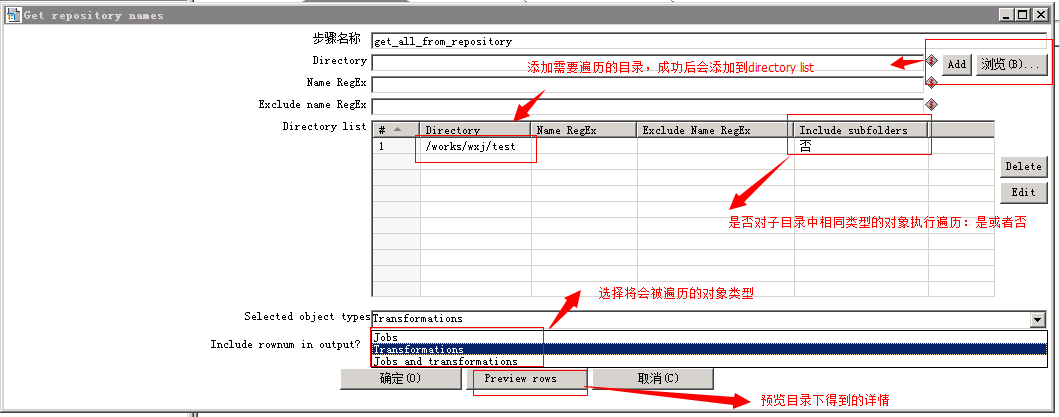
控件2设计如下

step2:新建tran_set_variable.ktr(从内存读取结果集,并设置环境变量)
 、
、
控件3设计如下

控件4设计如下

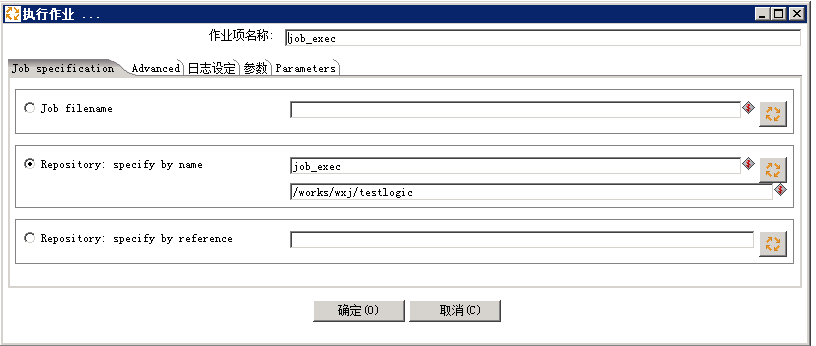
step3:新建job_exec.kjb(传参并执行所有指定目录对象)

1处的详细设计为

2处的详细设计为

step4:创建job_runall.kjb(调度所有对象,根据逻辑设计执行顺序)

从上面可以大概的看出,tran_getall是从资源库得到目录下面的所有内容,job_exec这个是传参赋值并且执行所有对象,这样的顺序是正确的。
1处的详细设计为

2处的详细设计为
2处需要注意的是

一定要勾上对每个输入行执行一次,这样才会循环覆盖一次变量值不然会报参数重复错误
job_exec的作用也就在这个地方,否则就可以讲job_exec省去,把所有的逻辑放在job_runall里面来实现了,OK 设计完毕运行job_runall.

执行成功,看结果

看遍历排序

OK,效果实现,这样无论目录/works/wxj/test下有多少个ktr或者kjb都会被遍历执行了,不必一个一个的去串起来
PS:需要注意的是如果遇到特殊的业务逻辑比如涉及到ktr执行先后顺序的,必须先跑ktr1才可以跑ktr2的需要单独拿出来处理。因为遍历目录的时候的顺序不是我们手工可以改变的,至少现在我还没有发现可以控制顺序来执行的方法。