目录
背景:

我们在使用词典app时,有没有发现即使输错几个字母,app依然能给我们推荐出想要的单词,非常智能。它是怎么找出我们想要的单词的呢?这里就需要BK树来解决这个问题了。在使用BK树之前我们要先明白一个概念,叫编辑距离,也叫Levenshtein距离。词典app是怎么判断哪些单词和我们输入的单词很相似的呢?我们需要知道两个单词有多像,换句话说就是两个单词相似度是多少。1965年,俄国科学家Vladimir Levenshtein给字符串相似度做出了一个明确的定义叫做Levenshtein距离,我们通常叫它“编辑距离”。字符串A到B的编辑距离是指,只用插入、删除和替换三种操作,最少需要多少步可以把A变成B。例如,从aware到award需要一步(一次替换),从has到have则需要两步(替换s为v和再加上e)。Levenshtein给出了编辑距离的一般求法,就是大家都非常熟悉的经典动态规划问题。这里给出Levenshtein距离的性质。设d(x,y)表示字符串x到y的Levenshtein距离,那么显然:
- d(x,y) = 0 当且仅当 x=y (Levenshtein距离为0 <==> 字符串相等)
- d(x,y) = d(y,x) (从x变到y的最少步数就是从y变到x的最少步数)
- d(x,y) + d(y,z) >= d(x,z) (从x变到z所需的步数不会超过x先变成y再变成z的步数) 最后这一个性质叫做三角形不等式。就好像一个三角形一样,两边之和必然大于第三边。
在自然语言处理中,这个概念非常重要,比如在词典app中:如果用户马虎输错了单词,则可以列出字典里与它的Levenshtein距离小于某个数n的单词,让用户选择正确的那一个。n通常取到2或者3,或者更好地,取该单词长度的1/4等等。这里主要讲编辑距离如何求?至于怎么实现列出词典中相似的单词,详见拼写检查编程题详解-BK树算法。
求编辑距离算法:
这里需要有动态规划的思想,如果之前没有听过动态规划算法,请参考最少钱币数(凑硬币)详解-2-动态规划算法(初窥)。动态规划算法通常基于一个递推公式及一个或多个初始状态。 当前子问题的解将由上一次子问题的解推出。所以我们首要目标是找到某个状态和一个地推公式。假设我们可以使用d[ x,y ]个步骤(可以使用一个二维数组保存这个值),表示将串x[1...i]转换为 串y [ 1…j ]所需最少步骤数。
在最简单的情况下,即在i=0时,也就是说串x为空,那么对应的d[0,j] 就是x增加j个字符,即需要j步,使得x转化为y;在j等于0时,也就是说串y为空,那么对应的d[i,0] 就是x减少 i个字符,即需要i步,使得x转化为y。这是需要的最少步骤数了。
然后我们再进一步,如果我们想要将x[1...i]经过最少次数的增、删、改 操作转换为y[1...j],可以考虑三种情况:
1)假设我们可以在最少a步内将x[1...i]转换为y[1...j-1],这时我们只需要将x[1...i]加上y[j]就可以完成将x[1...i]转化为y[1...j],这样x转换为y就需要a+1步。
2)假设我们可以在最少b步内将x[1...i-1]转换位y[1...j],这时我们只需要将x[i]删除就可以完成将x[1...i]转换为y[1...j],这样x转换为y就需要b+1步。
3)假设我们可以在最少k步内将x[1...i-1]转换为y[1...j-1],这时我们就需要判断x[i]和y[j]是否相等,如果相等,那么我们只需要k步就可以完成将x[1...i]转换为y[1...j];如果x[i]和y[j]不相等,那么我们需要将x[i]替换为y[j],这样需要k+1步就可以将x[1...i]转换为y[1...j]。
这三种情况是在前一个状态可以以最少次数的增加,删除或者替换操作,使得现在串x和串y只需要再做一次操作或者不做就可以完成x[1..i]到y[1..j]的转换。最后,我们为了保证目前这个状态(x[1..i]转换为y[1..j])下所需的步骤最少,我们需要从上面三种情况中选择步骤最少的一种作为将x[1...i]转换为y[1...j]所需的最少步骤数。即min(a+1,b+1,k+eq),其中x[i]和y[j]相等,则eq=0,否则eq=1。
具体算法步骤如下(可以结合者下边的图来理解):
1、构造 行数为m+1 列数为 n+1 的数组,用来保存完成某个字串转换所需最少步数,将串x[1..m] 转换到 串y[1…n] 所需要最少步数为levenST[m][n]的值;
2、初始化levenST第0行为0到n,第0列为0到m。
levenST[0][j]表示第0行第j-1列的值,这个值表示将串x[1…0]转换为y[1..j]所需最少步数,很显然将一个空串转换为一个长度为j的串,只需要j次的add操作,所以levenST[0][j]的值应该是j,其他的值类似。这是最简单的情形。
3、然后我们考虑一般的情况,如果我们想要将x[1...i]经过最少次数的增、删、改 操作转换为y[1...j],就需要将串x和串y的每一个字符两两进行比较,如果相等,则eq=0,如果不等,则eq=1。例如,我们可以从x的第一个字母x[0]开始依次和y中的字母(y[0],y[1],y[2],......y[n])进行比较,然后得出相应位置(levenST[1][j])上的最少转换步骤数。需要考虑三种情况(也就是三个初始的状态):
- 1)这时levenST[i][j-1]的值a的含义就是最少a步将x[1...i]转换为y[1...j-1],这时我们只需要将x[1...i]加上y[j]就可以完成将x[1...i]转化为y[1...j],这样x转换为y就需要a+1步。
- 2)levenST[i-1][j]的值b的含义就是在最少b步内将x[1...i-1]转换为y[1...j],这时我们只需要将x[i]删除就可以完成将x[1...i]转换为y[1...j],这样x转换为y就需要b+1步。
- 3)而levenST[i-1][j-1]的值k的含义就是在最少k步内将x[1...i-1]转换为y[1...j-1],这时我们就需要判断x[i]和y[j]是否相等,如果相等,那么我们只需要k步就可以完成将x[1...i]转换为y[1...j];如果x[i]和y[j]不相等,那么我们需要将x[i]替换为y[j],这样需要k+1步就可以将x[1...i]转换为y[1...j]。
最后,我们为了保证目前这个状态(x[1..i]转换为y[1..j])下所需的步骤最少,我们需要从上面三种状态中选择步骤最少的一种作为将x[1...i]转换为y[1...j]所需的最少步骤数。即min( levenST[ i-1 ][ j ] + 1, levenST[ i ][ j-1 ] + 1, levenST [i-1 ][ j-1 ] + eq ),其中x[i]和y[j]相等,则eq=0,否则eq=1。
于是我们就可以得出递推公式:
levenST[ i ][ j ] = minOfTreeNum( levenST[ i-1 ][ j ] + 1, levenST[ i ][ j-1 ] + 1, levenST [i-1 ][ j-1 ] + eq );
(递推公式需要三个初始状态,即 levenST[i-1][j], levenST[i][j-1]和 levenST[i-1][j-1] ,所以我们需要对数组 levenST[][] 事先进行初始化,先求出最简单的状态下的levenshtein距离)
最后,我们将两个字符串中所有字母都遍历对比完成之后,将x转换为y所需最少步骤数就是levenST[m][n]。其中m为字符串x的长度,n为字符串y的长度。
图解过程:
计算has和have的编辑距离:
1、构造初始化二维数组levenST[4][5]
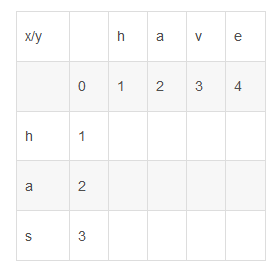
2、从字符串has第一个字母开始,依次和y中的字母(y[1...j])进行比较,然后得出相应位置(levenST[1,j])上的最少转换步骤数。

如果两个字母相等,则在从此位置的左+1,上+1,左上+0三个数中获取最小的值存入;若不等,则在从此位置的左,上,左上三个位置中获取最小的值再加上1。如下图,首先对比字符串x中第一个字母h和字符串y中第一个字母h,发现两个字母相等,所以对比左、上、左上三个位置得出最小值0存入levenST[1][1],接着依次对比‘h'->'a',‘h'->'v',‘h'->'e'。得出h子串和h,ha,hav,have四个子串的编辑距离。
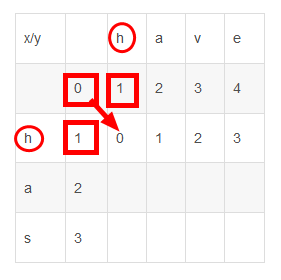
3、接着将字母a依次和have中字母对比,得出ha子串和h,ha,hav,have四个子串的编辑距离。

4、接着将字母s依次和have中字母h,a,v,e对比,得出has子串和h,ha,hav,have四个子串的编辑距离。

最后一个即为单词has和have的编辑距离,
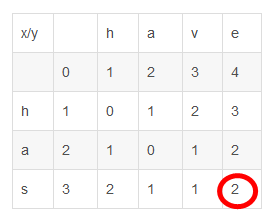
求出编辑距离,就可以得到两个字符串has和have的相似度 Similarity = (Max(x,y) - Levenshtein)/Max(x,y),其中 x,y 为源串和目标串的长度。
| x/y | h | a | v | e | |
| 0 | 1 | 2 | 3 | 4 | |
| h | 1 | 0 | 1 | 2 | 3 |
| a | 2 | 1 | 0 | 1 | 2 |
| s | 3 | 2 | 1 | 1 | 2 |
C++代码如下:
#include <iostream>
#include <string>
using namespace std;
int minOfTreeNum(int a, int b, int c) //返回a,b,c三个数中最小值
{
int minNum = a;
if(minNum > b )
{
minNum = b;
}
if(minNum > c )
{
minNum = c;
}
return minNum;
}
int levenSTDistance(string x, string y) //计算字符串x和字符串y的levenshtein距离
{
int lenx = x.length();
int leny = y.length();
int levenST[lenx+1][leny+1]; //申请一个二维数组存放编辑距离
int eq = 0; //存放两个字母是否相等
int i,j;
//初始化二维数组,也就是将最简单情形的levenshtein距离写入
for(i=0; i <= lenx; i++)
{
levenST[i][0] = i;
}
for(j=0; j <= leny; j++)
{
levenST[0][j] = j;
}
//将串x和串y中的字母两两进行比较,得出相应字串的编辑距离
for(i=1; i <= lenx; i++ )
{
for(j=1; j <= leny; j++)
{
if(x[i-1] == y[j-1])
{
eq = 0;
}else{
eq = 1;
}
levenST[i][j] = minOfTreeNum(levenST[i-1][j] + 1, levenST[i][j-1] + 1, levenST[i-1][j-1] + eq);
}
}
return levenST[lenx][leny];
}
int main()
{
string a,b;
int levenDistance;
cin >> a;
cin >> b;
levenDistance = levenSTDistance(a,b);
cout << "Levenshtein Distance:" << levenDistance << endl;
return 0;
}
总结:
动态规划算法通常基于一个递推公式及一个或多个初始状态。 当前子问题的解将由上一次子问题的解推出。关键是找到这个递推公式。需要多加练习。
参考资料: (这是java版代码) 编辑距离算法详解:Levenshtein Distance算法