一、缓存穿透
在讨论缓存穿透之前,我们先来看下从缓存中读取数据时的流程,如图:

缓存穿透是什么?
如果每次都去查一个“缓存和数据库中都必不存在的数据(如id=-1的数据)”,因为缓存中不存在,那么每次请求都会打到DB上,从而导致缓存失去意义,在高并发的情况下就可能导致数据库崩溃,这就是缓存穿透。
缓存穿透的解决方案
1、规范key过滤
规范key的命名,并且统一缓存查询的入口,在入口处对key的命名格式进行检测,过滤掉不规范key的访问,这样可以过滤掉大部分的恶意攻击。如约定项目中Redis缓存key的前缀都是以"公司名_项目名_REDIS_"开头,不符合这个约定的key在一开始就过滤掉。
2、缓存空值
简单粗暴,如果查询DB返回的数据为空,我们仍然把这个空值放到Redis缓存中,只是将它的过期时间设置的很短,另外为了避免不必要的内存消耗,可以定期清理空值的key。
3、加锁
根据key从缓存中获取到的value为空时,先锁上,再去查DB将数据加载到缓存,若其它线程获取锁失败,则等待一段时间后重试,从而避免了大量请求直接打到DB。单机可以使用synchronized或ReentrantLock加锁,分布式环境需要加分布式锁,如Redis分布式锁。
4、布隆过滤器
我们想这样一个问题,如果想判断某个元素是不是在一个集合里,一般做法是将集合中所有的元素保存起来,然后通过比较确定,比如HashMap。但是随着集合中元素的增加,数据量超大时,我们需要的存储空间也越来越大,甚至超过服务器内存,这时我们就不能再用HashMap等数据结构了。
这时布隆过滤器就出场了,它的空间效率非常好,它是一个二进制向量,每一位存放的是0或1,初始时默认为0,长下面这样:

当一个元素加入集合时,通过 K 个 Hash 函数将这个元素映射成 k 个值 :K1、K2、K3...,把向量中下标为K1、K2、K3...的位置置为1 。
比如,元素X进来,将X作为参数,通过3个hash函数的计算,分别得到3个值:Hash1(X)=5;Hash2(X)=2;Hash3(X)=9;那么我们就将布隆过滤器中下标为5、2、9的位置分别置为1,如下,

可以看出,布隆过滤器根本没有存放完整的数据,只是运用一系列随机映射函数计算出位置,然后填充二进制向量,所以它的空间效率非常好。
※ 有一个元素Y,怎么判断Y在布隆过滤器中是否存在呢?
同样将Y作为参数,通过3个hash函数的计算,分别得到3个值,比如是:4/6/8,我们只要看下标为4/6/8的位置是不是都是1,
> 如果都是1,则元素Y可能存在于集合中,为什么说可能呢——hash碰撞,不同的两个元素,经过同样的hash函数,计算出来的值,从概率上来讲是有可能重复的。所以这也是布隆过滤器最大的缺点,存在误判率。
> 如果不全是1,则元素Y肯定不存在。
即:当它说某个 key 不存在时,key一定不存在;当它说某个 key 存在时,key 可能存在。
※ 布隆过滤器是怎样解决缓存穿透的?
预先将所有缓存数据的key存放到布隆过滤器中,当一个查询请求过来的时候,先判断这个key在布隆过滤器中是否存在?
> 如果不存在,直接返回提示,都不用去查缓存更不用说DB了;
> 如果存在,则去查缓存,但我们知道布隆过滤器判断存在有一定的误判率,这里我是这样理解的,如果这个误判率针对你们的业务场景是可被接受的则可以忽略,另外我们在用Guava实现布隆过滤器的时候可以指定误判率不超过多少,你可以指定一个可被你接受的值。再或者,因为布隆过滤器可以过滤掉绝大多数的恶意key,针对少部分的漏网之鱼,我们可以在缓存层面使用功能上面说过的缓存空值或加锁的方案。
二、缓存击穿
缓存击穿和缓存穿透不一样!
说缓存击穿之前,我们先来了解一个概念——热点key,某个访问非常频繁,访问量非常大的一个缓存key,我们叫做热点key。
缓存击穿是指某个热点key在失效的瞬间(一般是缓存时间到期),持续的大并发请求穿破缓存,直接打到数据库,就像在一个屏障上凿开了一个洞,造成数据库压力瞬间增大,这就是缓存击穿。
缓存击穿的解决方案
1、设置热点key永不过期
2、加锁,根据热点key从缓存中获取到的value为空时,先锁上,再去查DB将数据加载到缓存,若其它线程获取锁失败,则等待一段时间后重试,从而避免了大量请求直接打到DB。单机可以使用synchronized或ReentrantLock,分布式需要加分布式锁,如Redis分布式锁。【为了不阻塞对其他key的请求,此处可以用热点key来加锁】
三、缓存雪崩
缓存雪崩是指缓存由于某些原因整体或者大量失效,导致大量请求打到后端数据库,从而导致数据库崩溃,整个系统崩溃,发生灾难。
导致缓存整体或大量失效的场景一般有:
1、缓存服务宕机,如Redis集群彻底崩溃;
2、在某个集中的时间段内,系统预加载的缓存集中失效了;
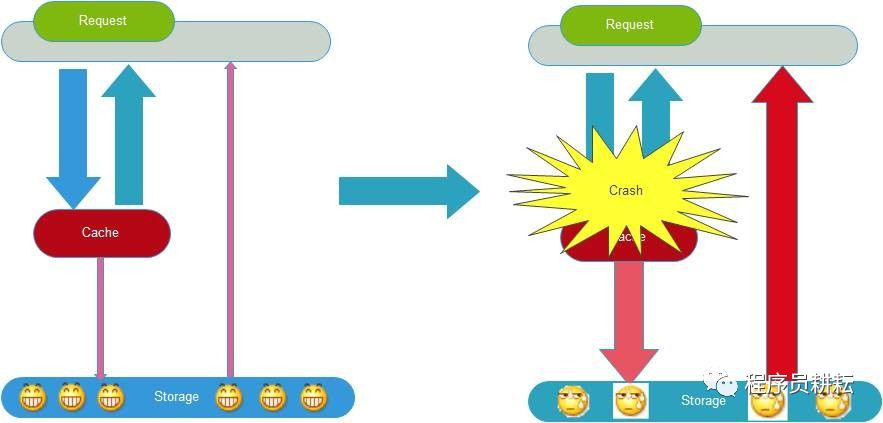
预防和解决缓存雪崩
1、保证缓存层服务高可用性,如使用Redis Sentinel 和 Redis Cluster,双机房部署,保证Redis服务高可用。
2、通过设置不同的过期时间,来错开缓存过期,从而避免缓存集中失效。