如何透明地支持数据库分库分表?
下面主要讨论,一个分布式数据库领域的需求。设计一个中间层,让应用逻辑不必关心数据库的物理分布。这样,无论把数据库拆成多少个分库,编程时都会像面对一个物理库似的没什么区别。
分布式数据库解决了什么问题,又带来了哪些挑战
随着技术的进步,我们编写的应用所采集、处理的数据越来越多,处理的访问请求也越来越多。而单一数据库服务器的处理能力是有限的,当数据量和访问量超过一定级别以后,就要开始做分库分表的操作。比如,把一个数据库的大表拆成几张表,把一个库拆成几个库,把读和写的操作分离开等等。我们把这类技术统称为分布式数据库技术。
分库分表(Sharding)有时也翻译成“数据库分片”。分片可以依据各种不同的策略,比如与社区有关的应用系统,这个系统的很多业务逻辑都是围绕小区展开的。对于这样的系统,按照地理分布的维度来分片就很合适,因为每次对数据库的操作基本上只会涉及其中一个分库。
假设我们有一个订单表,那么就可以依据一定的规则对订单或客户进行编号,编号中就包含地理编码。比如SDYT代表山东烟台,BJHD代表北京海淀,不同区域的数据放在不同的分库中:
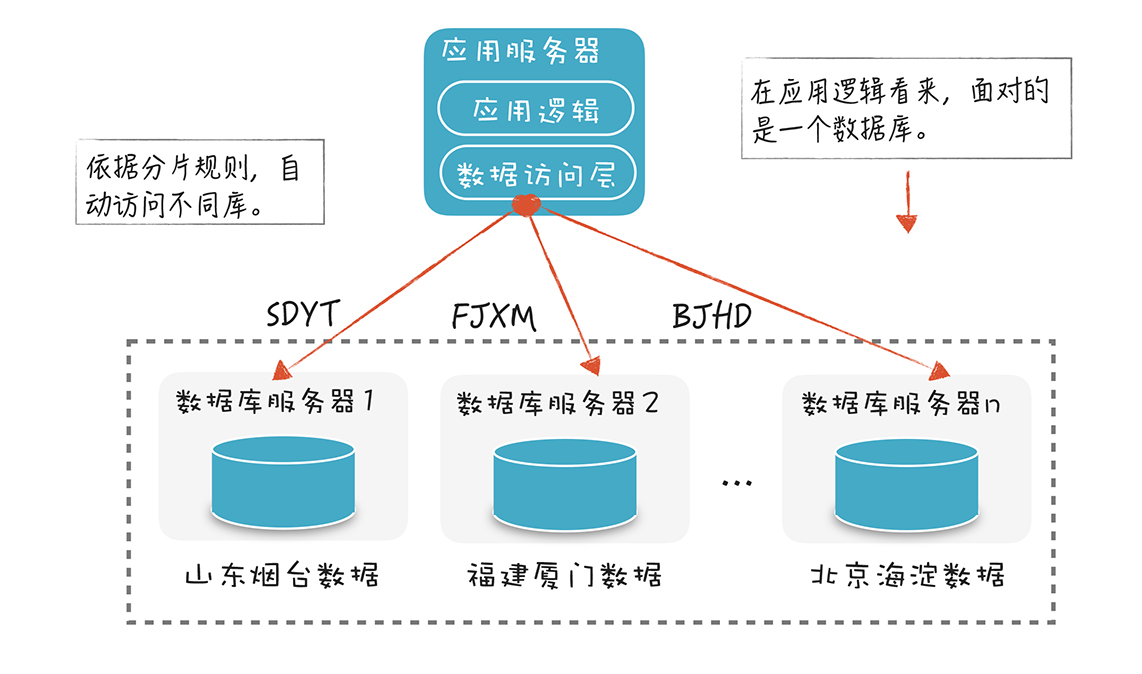
通过数据库分片,我们可以提高数据库服务的性能和可伸缩性。当数据量和访问量增加时,增加数据库节点的数量就行了。不过,虽然数据库的分片带来了性能和伸缩性的好处,但它也带来了一些挑战。
最明显的一个挑战,是数据库分片逻辑侵入到业务逻辑中。
过去,应用逻辑只访问一个数据库,现在需要根据分片的规则,判断要去访问哪个数据库,再去跟这个数据库服务器连接。如果增加数据库分片,或者对分片策略进行调整,访问数据库的所有应用模块都要修改。这会让软件的维护变得更复杂,显然也不太符合软件工程中模块低耦合、把变化隔离的理念。
所以如果有一种技术,能让我们访问很多数据库分片时,像访问一个数据库那样就好了。数据库的物理分布,对应用是透明的。
可是,“理想很吸引人,现实很骨感”。要实现这个技术,需要解决很多问题:
跨库查询的难题
如果SQL操作都针对一个库还好,但如果某个业务需求恰好要跨多个库,
比如上面的例子中,如果要查询多个小区的住户信息,那么就要在多个库中都执行查询,然后把查询结果合并,一般还要排序。
如果我们前端显示的时候需要分页,每页显示一百行,那就更麻烦了。我们不可能从10个分库中各查出10行,合并成100行,这100行不一定排在前面,最差的情况,可能这100行恰好都在其中一个分库里。所以,你可能要从每个分库查出100行来,合并、排序后,再取出前100行。
如果涉及数据库表跨库做连接,想象一下,那就更麻烦了。
跨库做写入的难题
如果对数据库写入时遇到了跨库的情况,那么就必须实现分布式事务。所以,虽然分布式数据库的愿景很吸引人,但我们必须解决一系列技术问题。
解析SQL语句,判断访问哪个数据库
画了一张简化版的示意图:假设有两张表,分别是订单表和客户表,它们的主键是order_id和cust_id:
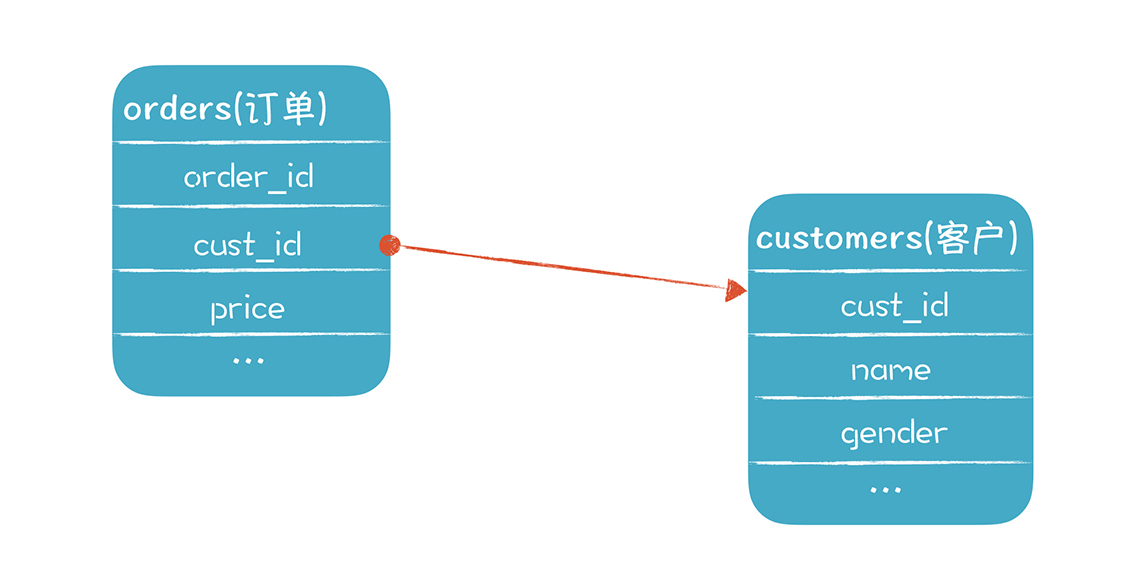
我们采用的分片策略,是依据这两个主键的前4位的编码来确定数据库分片的逻辑,
比如:前四位是SDYT,那就使用山东烟台的分片,如果是BJHD,就使用北京海淀的分片,等等。
在我们的应用中,会对订单表进行一些增删改查的操作,比如会执行下面的SQL语句:
//查询
select * from orders where order_id = 'SDYT20190805XXXX'
select * from orders where cust_id = 'SDYT987645'
//插入
insert into orders (order_id,...其他字段) values( "BJHD20190805XXXX",...)
//修改
update orders set price=298.00 where order_id='FJXM20190805XXXX'
//删除
delete from orders where order_id='SZLG20190805XXXX'
我们要能够解析这样的SQL语句,根据主键字段的值,决定去访问哪个分库或者分表。这就需要用到编译器前端技术,包括词法分析、语法分析和语义分析。
听到这儿,你可能会质疑:“解析SQL语句?是在开玩笑吗?”你可能觉得这个任务太棘手,犹豫着是否要忍受业务逻辑和技术逻辑混杂的缺陷,把判断分片的逻辑写到应用代码里,或者想解决这个问题,又或者想自己写一个开源项目,帮到更多的人。
无论你的内心活动如何,应用编译技术,能让你有更强的信心解决这个问题。那么如何去做呢?
要想完成解析SQL的任务,在词法分析和语法分析这两个阶段,建议你采用工具快速落地,比如Antlr。你要找一个现成的SQL语句的语法规则文件。
GitHub中,那个收集了很多示例Antlr规则文件的项目里,有两个可以参考的规则:
还有MySQL workbench所使用的一个产品级的规则文件。MySQL workbench是一个图形化工具,用于管理和访问MySQL。这个规则文件还是很靠谱的,不过它里面嵌了很多属性计算规则,而且是C++语言写的,处理起来麻烦,就先弃之不用,暂且采用SQLite的规则文件来做示范。
先来看一下这个文件里的一些规则,例如select语句相关的语法:
factored_select_stmt
: ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )?
select_core ( compound_operator select_core )*
( K_ORDER K_BY ordering_term ( ',' ordering_term )* )?
( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )?
;
common_table_expression
: table_name ( '(' column_name ( ',' column_name )* ')' )? K_AS '(' select_stmt ')'
;
select_core
: K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )*
( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )?
( K_WHERE expr )?
( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )?
| K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )*
;
result_column
: '*'
| table_name '.' '*'
| expr ( K_AS? column_alias )?
;
我们可以一边看这个语法规则,一边想几个select语句做一做验证。你可以思考一下,这个规则是怎么把select语句拆成不同的部分的。
SQL里面也有表达式,我们研究一下它的表达式的规则:
expr
: literal_value
| BIND_PARAMETER
| ( ( database_name '.' )? table_name '.' )? column_name
| unary_operator expr
| expr '||' expr
| expr ( '*' | '/' | '%' ) expr
| expr ( '+' | '-' ) expr
| expr ( '<<' | '>>' | '&' | '|' ) expr
| expr ( '<' | '<=' | '>' | '>=' ) expr
| expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr
| expr K_AND expr
| expr K_OR expr
| function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')'
| '(' expr ')'
| K_CAST '(' expr K_AS type_name ')'
| expr K_COLLATE collation_name
| expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )?
| expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL )
| expr K_IS K_NOT? expr
| expr K_NOT? K_BETWEEN expr K_AND expr
| expr K_NOT? K_IN ( '(' ( select_stmt
| expr ( ',' expr )*
)?
')'
| ( database_name '.' )? table_name )
| ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')'
| K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END
| raise_function
;
你可能会觉得SQL的表达式的规则跟其他语言的表达式规则很像。比如都支持加减乘除、关系比较、逻辑运算等等。而且从这个规则文件里,你一下子就能看出各种运算的优先级,比如你会注意到,字符串连接操作“||”比乘法和除法的优先级更高。所以,研究一门语言时积累的经验,在研究下一门语言时仍然有用。
有了规则文件之后,接下来,我们用Antlr生成词法分析器和语法分析器:
antlr -visitor -package dsql.parser SQLite.g4
在这个命令里,我用-package参数指定了生成的Java代码的包是dsql.parser。dsql是分布式SQL的意思。接着,我们可以写一点儿程序测试一下所生成的词法分析器和语法分析器:
String sql = "select order_id from orders where cust_id = 'SDYT987645'";
//词法分析
SQLiteLexer lexer = new SQLiteLexer(CharStreams.fromString(sql));
CommonTokenStream tokens = new CommonTokenStream(lexer);
//语法分析
SQLiteParser parser = new SQLiteParser(tokens);
ParseTree tree = parser.sql_stmt();
//输出lisp格式的AST
System.out.println(tree.toStringTree(parser));
这段程序的输出是LISP格式的AST,调整了一下缩进,让它显得更像一棵树:
(sql_stmt
(factored_select_stmt
(select_core select
(result_column
(expr
(column_name
(any_name order_id))))
from (table_or_subquery
(table_name
(any_name orders)))
where (expr
(expr
(column_name
(any_name cust_id)))
=
(expr
(literal_value
('SDYT987645'))))))
从AST中,我们可以清晰地看出这个select语句是如何被解析成结构化数据的,再继续写点儿代码,就能获得想要的信息了。
接下来的任务是:对于访问订单表的select语句,要在where子句里找出cust_id="客户编号"或order_id="订单编号"这样的条件,从而能够根据客户编号或订单编号确定采用哪个分库。
怎么实现呢?很简单,我们用visitor模式遍历一下AST就可以了:
public String getDBName(String sql) {
//词法解析
SQLiteLexer lexer = new SQLiteLexer(CharStreams.fromString(sql));
CommonTokenStream tokens = new CommonTokenStream(lexer);
//语法解析
SQLiteParser parser = new SQLiteParser(tokens);
ParseTree tree = parser.sql_stmt();
//以lisp格式打印AST
System.out.println(tree.toStringTree(parser));
//获得select语句的要素,包括表名和where条件
SQLVisitor visitor = new SQLVisitor();
SelectStmt select = (SelectStmt) visitor.visit(tree);
String dbName = null;
if (select.tableName.equals("orders")) {
if (select.whereExprs != null) {
for (WhereExpr expr : select.whereExprs) {
//根据cust_id或order_id来确定库的名称
if (expr.columnName.equals("cust_id") || expr.columnName.equals("order_id")) {
//取编号的前4位,即区域编码
String region = expr.value.substring(1, 5);
//根据区域编码,获取库名称
dbName = region2DB.get(region);
break;
}
}
}
}
return dbName;
}
获取表名和where子句条件的代码在SQLVisitor.java中。因为已经有了AST,抽取这些信息是不难的。你可以点提供的链接,查看示例代码。
我们的示例离实用还有多大差距?
目前,我们已经初步解决了数据库访问透明化的问题。当然,这只是一个示例,如果要做得严密、实用,我们还要补充一些工作。
语义分析工作需要确保SQL语句的合法性
语法分析并不能保证程序代码完全合法,我们必须进行很多语义的检查才行。
我给订单表起的名字,是orders。如果你把表名称改为order,那么必须用引号引起来,写成’order’,不带引号的order会被认为是一个关键字。因为在SQL中我们可以使用order by这样的子句,这时候,order这个表名就会被混淆,进而被解析错误。这个语法解析程序会在表名的地方出现一个order节点,这在语义上是不合法的,需要被检查出来并报错。
如果要检查语义的正确性,我们还必须了解数据库的元数据。否则,就没有办法判断在SQL语句中是否使用了正确的字段,以及正确的数据类型。除此之外,我们还需要扩展到能够识别跨库操作,比如下面这样一个where条件:
order_id = 'FJXM20190805XXXX' or order_id = 'SZLG20190805XXXX'
分析这个查询条件,可以知道数据是存在两个不同的数据库中的。但是我们要让解析程序分析出这个结果,甚至让它针对更加复杂的条件,也能分析出来。这就需要更加深入的语义分析功能了。
解析器的速度也是一个需要考虑的因素
因为执行每个SQL都需要做一次解析,而这个时间就加在了每一次数据库访问上。所以,SQL解析的时间越少越好。因此,有的项目就会尽量提升解析效率。阿里有一个开源项目Druid,是一个数据库连接池。这个项目强调性能,因此他们纯手写了一个SQL解析器,尽可能地提升性能。
总之,要实现一个完善的工具,让工具达到产品级的质量,有不少工作要做。如果要支持更强的分布式数据库功能,还要做更多的工作。
SQL防注入
SQL注入攻击是一种常见的攻击手段。你向服务器请求一个url的时候,可以把恶意的SQL嵌入到参数里面,这样形成的SQL就是不安全的。
以前面的SQL语句为例,这个select语句本来只是查询一个订单,订单编号“SDYT20190805XXXX”作为参数传递给服务端的一个接口,服务端收到参数以后,用单引号把这个参数引起来,并加上其他部分,就组装成下面的SQL并执行:
//原来的SQL
select * from orders where order_id = 'SDYT20190805XXXX'
如果我们遇到了一个恶意攻击者,他可能把参数写成“SDYT20190805XXXX’;drop table customers; --”。服务器接到这个参数以后,仍然把它拿单引号引起来,并组装成SQL,组装完毕以后就是下面的语句:
//被注入恶意SQL后
select * from orders where order_id = 'SDYT20190805XXXX'; drop table customers; --'
如果你看不清楚,我分行写一下,这样你就知道它是怎么把你宝贵的客户信息全都删掉的:
//被注入恶意SQL后
select * from orders where order_id = 'SDYT20190805XXXX';
drop table customers; // 把顾客表给删了
--' //把你加的单引号变成了注释,这样SQL不会出错
所以SQL注入有很大的危害。而我们一般用检查客户端传过来的参数的方法,看看有没有SQL语句中的关键字,来防止SQL注入。不过这是比较浅的防御,有时还会漏过一些非法参数,所以要在SQL执行之前,做最后一遍检查。而这个时候,就要运用编译器前端技术来做SQL的解析了。借此,我们能检查出来异常:明明这个功能是做查询的,为什么形成的SQL会有删除表的操作?
通过这个例子,我们又分析了一种场景:开发一个安全可靠的系统,用编译技术做SQL分析是必须做的一件事情。
总结
利用学到的编译器前端技术,解析了SQL语句,并针对分布式数据库透明查询的功能做了一次概念证明。
SQL是程序员经常打交道的语言。有时,我们会遇到需要解析SQL语言的需求,除了分布式数据库场景的需求以外,Hibernate对HQL的解析,也跟解析SQL差不多。而且,最近有一种技术,能够通过RESTful这样的接口做通用的查询,其实也是一种类SQL的子语言。
当然了,今天我们只是基于工具做解析。
一方面,有时候我们就是需要做个原型系统或者最小的能用的系统,有时间有资源了,再追求完美也不为过,比如追求编译速度的提升。
另一方面,你能看到MySQL workbench也是用Antlr来作帮手的,在很多情况下,Antlr这样的工具生成的解析器足够用,甚至比你手写的还要好,所以,我们大可以节省时间,用工具做解析。
可能你会觉得,实际应用的难度似乎要低于学习原理的难度。如果你有这个感觉,那就对了,这说明你已经掌握了原理篇的内容,所以日常的一些应用根本不是问题,你可以找出更多的应用场景来练练手。
如何设计一个报表工具?
很多软件都需要面向开发者甚至最终用户提供自定义功能。
在每个应用系统中,我们对数据的处理大致会分成两类:
-
一类是在线交易,叫做OLTP,比如在网上下订单;
-
一类是在线分析,叫做OLAP,它是对应用中积累的数据进行进一步分析利用。
而报表工具就是最简单,但也是最常用的数据分析和利用的工具。
报表工具所需要的编译技术
如果要做一个报表软件,我们要想清楚软件面对的用户是谁。
有一类报表工具面向的用户是程序员,那么这种软件可以暴露更多技术细节。比如,如果报表要从数据库获取数据,你可以写一个SQL语句作为数据源。
还有一类软件是给业务级的用户使用的,很多BI软件包都是这种类型。带有IT背景的顾问给用户做一些基础配置,然后用户就可以用这个软件包了。Excel可以看做是这种报表工具,IT人员建立Excel与数据库之间的连接,剩下的就是业务人员自己去操作了。
这些业务人员可以采用一个图形化的界面设计报表,对数据进行加工处理。我们来看看几个场景。
计算字段
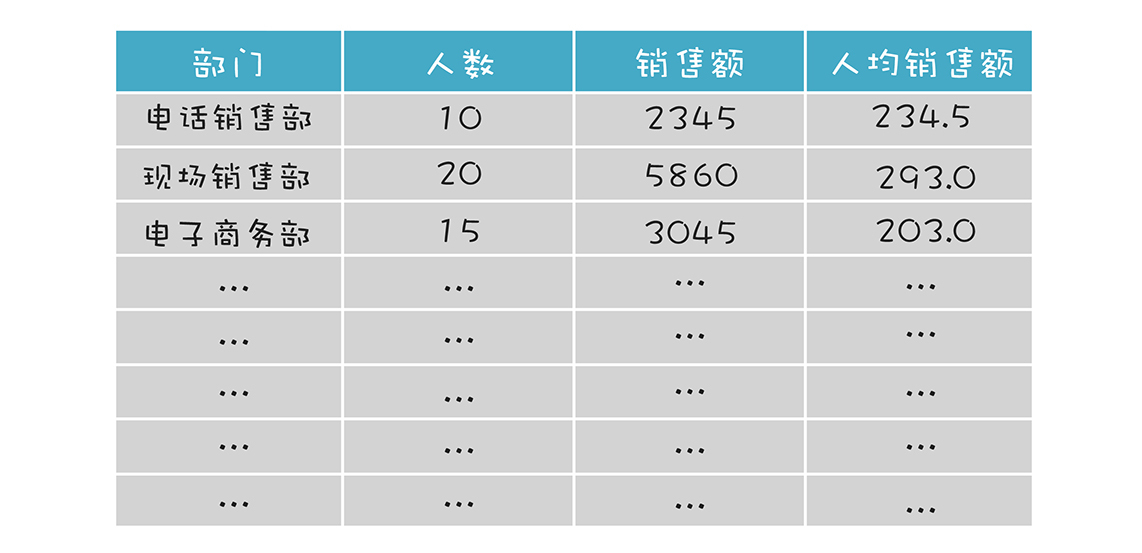
计算字段的意思是,原始数据里没有这个数据,我们需要基于原始数据,通过一个自定义的公式来把它计算出来,比如在某个CRM系统中保存着销售数据。我们有每个部门的总销售额,也有每个部门的人数,要想在报表中展示每个部门的人均销售额,这个时候就可以用到计算公式功能,计算公式如下:
人均销售额=部门销售额/部门人数
得到的结果如下图所示:
进一步,我们可以在计算字段中支持函数。比如我们可以把各个部门按照人均销售额排名次。这可以用一个函数来计算:
=rank(人均销售额)
rank就是排名次的意思,其他统计函数还包括:
- min(),求最小值。
- max(),求最大值。
- avg(),求平均值。
- sum(),求和。
还有一些更有意思的函数,比如:
- runningsum(),累计汇总值。
- runningavg(),累计平均值。
这些有意思的函数是什么意思呢?
因为很多明细性的报表,都是逐行显示的,累计汇总值和累计平均值,就是累计到当前行的计算结果。当然了,我们还可以支持更多的函数,比如当前日期、当前页数等等。更有意思的是,上述字段也好、函数也好,都可以用来组合成计算字段的公式,比如:
=部门销售额/sum(部门销售额) //本部门的销售额在全部销售额的占比
=max(部门销售额)-部门销售额 //本部门的销售额与最高部门的差距
=max(部门销售额/部门人数)-部门销售额/部门人数 //本部门人均销售额与最高的那个部门的差
=sum(部门销售额)/sum(人数)-部门销售额/部门人数 //本部门的人均销售额与全公司人均销售额的差
如何设计报表
假设我们的报表是一行一行地展现数据,也就是最简单的那种。那我们将报表的定义做成一个XML文件,可能是下面这样的,它定义了表格中每一列的标题和所采用字段或公式:
<playreport title="Report 1">
<section>
<column>
<title>部门</title>
<field>dept</field>
</column>
<column>
<title>人数</title>
<field>num_person</field>
</column>
<column>
<title>销售额</title>
<field>sales_amount</field>
</column>
<column>
<title>人均销售额</title>
<field>sales_amount/num_person</field>
</column>
</section>
<datasource>
<connection>数据库连接信息...</connection>
<sql>select dept, num_person, sales_amount from sales</sql>
</datasource>
</playreport>
这个报表定义文件还是蛮简单的,它主要表达的是数据逻辑,忽略了表现层的信息。
如果我们想要优先表达表现层的信息,例如字体大小、界面布局等,可以采用HTML模板的方式来定义报表,其实就是在一个HTML中嵌入了公式,比如:
<html>
<body>
<div class="report" datasource="这里放入数据源信息">
<div class="table_header">
<div class="column_header">部门</div>
<div class="column_header">人数</div>
<div class="column_header">销售额</div>
<div class="column_header">人均销售额</div>
</div>
<div class="table_body">
<div class="field">{=dept}</div>
<div class="field">{=num_person}</div>
<div class="field">{=sales_amount}</div>
<div class="field">{=sales_amount/num_person}</div>
</div>
</div>
</body>
</html>
这样的HTML模板看上去是不是很熟悉?
其实在很多语言里,比如PHP,都提供模板引擎功能,实现界面设计和应用代码的分离。这样一个模板,可以直接解释执行,或者先翻译成PHP或Java代码,然后再执行。只要运用我们学到的编译技术,这些都可以实现。
我想你应该会发现,这样的一个模板文件,其实就是一个特定领域语言,也就是我们常说的DSL。DSL可以屏蔽掉实现细节,让我们专注于领域问题,像上面这样的DSL,哪怕没有技术背景的工作人员,也可以迅速地编写出来。
而这个简单的报表,在报表设计界面上可能是下图这样的形式:

编写所需要的语法规则
我们设计了PlayReport.g4规则文件,这里面的很多规则,是把PlayScript.g4里的规则拿过来改一改用的:
bracedExpression
: '{' '=' expression '}'
;
expression
: primary
| functionCall
| expression bop=('*'|'/'|'%') expression
| expression bop=('+'|'-') expression
| expression bop=('<=' | '>=' | '>' | '<') expression
| expression bop=('==' | '!=') expression
| expression bop='&&' expression
| expression bop='||' expression
;
primary
: '(' expression ')'
| literal
| IDENTIFIER
;
expressionList
: expression (',' expression)*
;
functionCall
: IDENTIFIER '(' expressionList? ')'
;
literal
: integerLiteral
| floatLiteral
| CHAR_LITERAL
| STRING_LITERAL
| BOOL_LITERAL
| NULL_LITERAL
;
integerLiteral
: DECIMAL_LITERAL
| HEX_LITERAL
| OCT_LITERAL
| BINARY_LITERAL
;
floatLiteral
: FLOAT_LITERAL
| HEX_FLOAT_LITERAL
;
这里面,其实就是用了表达式的语法,包括支持加减乘除等各种运算,用来书写公式。我们还特意支持functionCall功能,也就是能够调用函数。因为我们内部实现了很多内置函数,比如求最大值、平均值等,可以在公式里调用这些函数。
实现一个简单的报表引擎
报表引擎的工作,是要根据报表的定义和数据源中的数据,生成最后报表的呈现格式。具体来说,可以分为以下几步:
- 解析报表的定义。我们首先要把报表定义形成Java对象。这里只是简单地生成了一个测试用的报表模板。
- 从数据源获取数据。我们设计了一个TabularData类,用来保存类似数据库表那样的数据。
- 实现一个FieldEvaluator类,能够在运行时对字段和公式进行计算。这个类是playscript中ASTEvaluator类的简化版。我们甚至连语义分析都简化了。数据类型信息作为S属性,在求值的同时自底向上地进行类型推导。当然,如果做的完善一点儿,我们还需要多做一点儿语义分析,比如公式里的字段是不是数据源中能够提供的?而这时需要用到报表数据的元数据。
- 渲染报表。我们要把上面几个功能组合在一起,对每一行、每一列求值,获得最后的报表输出。
主控程序我放在了下面,用一个示例报表模板和报表数据来生成报表:
public static void main(String args[]) {
System.out.println("Play Report!");
PlayReport report = new PlayReport();
//打印报表1
String reportString = report.renderReport(ReportTemplate.sampleReport1(), TabularData.sampleData());
System.out.println(reportString);
}
renderReport方法用来渲染报表,它会调用解析器和报表数据的计算器:
public String renderReport(ReportTemplate template, TabularData data){
StringBuffer sb = new StringBuffer();
//输出表格头
for (String columnHeader: template.columnHeaders){
sb.append(columnHeader).append(' ');
}
sb.append("
");
//编译报表的每个字段
List<BracedExpressionContext> fieldASTs = new LinkedList<BracedExpressionContext>();
for (String fieldExpr : template.fields){
//这里会调用解析器
BracedExpressionContext tree = parse(fieldExpr);
fieldASTs.add(tree);
}
//计算报表字段
FieldEvaluator evaluator = new FieldEvaluator(data);
List<String> fieldNames = new LinkedList<String>();
for (BracedExpressionContext fieldAST: fieldASTs){
String fieldName = fieldAST.expression().getText();
fieldNames.add(fieldName);
if (!data.hasField(fieldName)){
Object field = evaluator.visit(fieldAST);
data.setField(fieldName, field);
}
}
//显示每一行数据
for (int row = 0; row< data.getNumRows(); row++){
for (String fieldName: fieldNames){
Object value = data.getFieldValue(fieldName, row);
sb.append(value).append(" ");
}
sb.append("
");
}
return sb.toString();
}
程序的运行结果如下,它首先打印输出了每个公式的解析结果,然后输出报表:
Play Report!
(bracedExpression { = (expression (primary dept)) })
(bracedExpression { = (expression (primary num_person)) })
(bracedExpression { = (expression (primary sales_amount)) })
(bracedExpression { = (expression (expression (primary sales_amount)) / (expression (primary num_person))) })
部门 人数 销售额 人均销售额
电话销售部 10 2345.0 234.5
现场销售部 20 5860.0 293.0
电子商务部 15 3045.0 203.0
渠道销售部 20 5500.0 275.0
微商销售部 12 3624.0 302.0
你可以看到,报表工具准确地得出了计算字段的数据。
报表数据计算的细节
如果你看一看FieldEvaluator.java这个类,就会发现我实际上实现了一个简单的向量数据的计算器。在计算机科学里,向量是数据的有序列表,可以看做一个数组。相对应的,标量只是一个单独的数据。运用向量计算,我们在计算人均销售额的时候,会把“销售额”和“人数”作为两个向量,每个向量都有5个数据。把这两个向量相除,会得到第三个向量,就是“人均销售额”。这样就不需要为每行数据运行一次计算器,会提高性能,也会简化程序。
其实,这个向量计算器还能够把向量和标量做混合运算。因为我们的报表里有时候确实会用到标量,比如对销售额求最大值{=max(sales_amount)},就是一个标量。而如果计算销售额与最大销售额的差距{=max(sales_amount)-sales_amount},就是标量和向量的混合运算,返回结果是一个向量。
TabularData.java这个类是用来做报表数据的存储的。我简单地用了一个Map,把字段的名称对应到一个向量或标量上,其中字段的名称可以是公式:
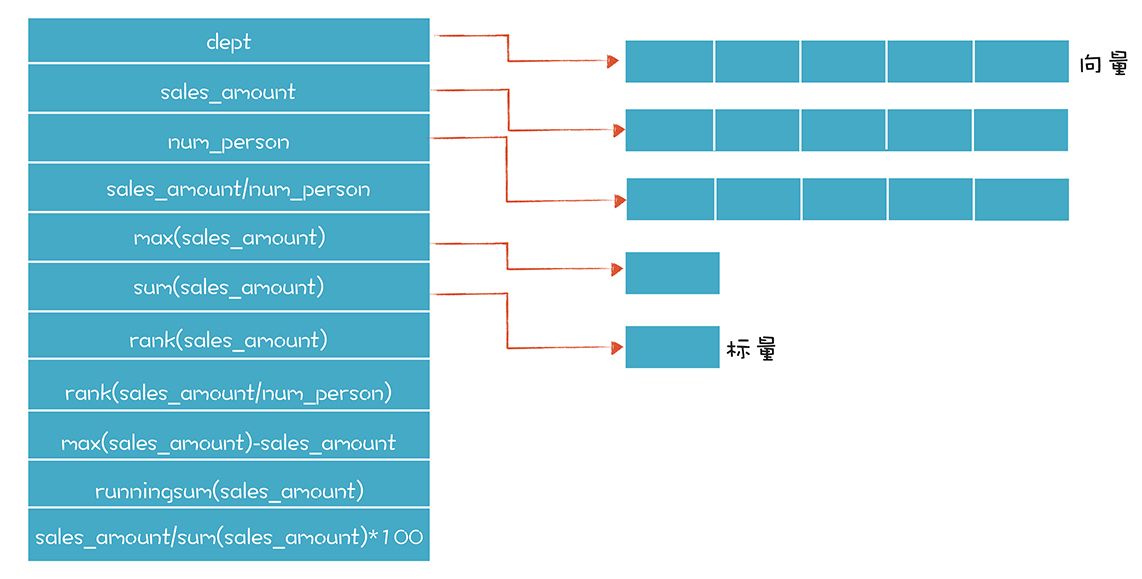
在报表数据计算过程中,我们还做了一个优化。公式计算的中间结果会被存起来,如果下一个公式刚好用到这个数据,可以复用。
比如,在计算rank(sales_amount/num_person)这个公式的时候,它会查一下括号中的sales_amount/num_person这个子公式的值是不是以前已经计算过,如果计算过,就复用,否则,就计算一下,并且把这个中间结果也存起来。
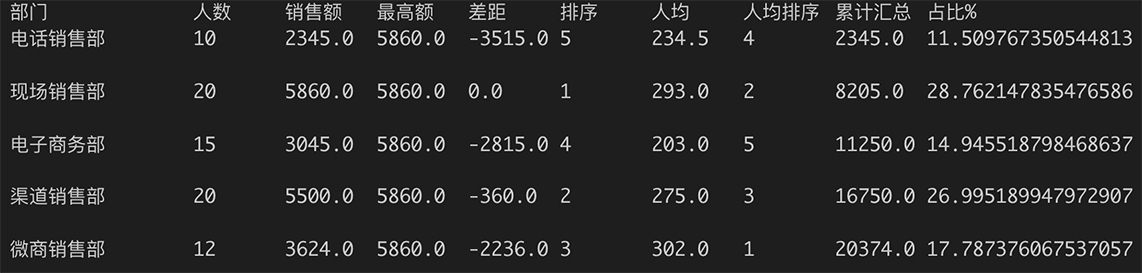
我们把这个报表再复杂化一点,形成下面一个报表模板。这个报表模版用到了好几个函数,包括排序、汇总值、累计汇总值和最大值,并通过公式定义出一些相对复杂的计算字段,包括最高销售额、销售额的差距、销售额排序、人均销售额排序、销售额累计汇总、部门销售额在总销售额中的占比,等等。
public static ReportTemplate sampleReport2(){
ReportTemplate template = new ReportTemplate();
template.columnHeaders.add("部门");
template.columnHeaders.add("人数");
template.columnHeaders.add("销售额");
template.columnHeaders.add("最高额");
template.columnHeaders.add("差距");
template.columnHeaders.add("排序");
template.columnHeaders.add("人均");
template.columnHeaders.add("人均排序");
template.columnHeaders.add("累计汇总");
template.columnHeaders.add("占比%");
template.fields.add("{=dept}");
template.fields.add("{=num_person}");
template.fields.add("{=sales_amount}");
template.fields.add("{=max(sales_amount)}");
template.fields.add("{=max(sales_amount)-sales_amount}");
template.fields.add("{=rank(sales_amount)}");
template.fields.add("{=sales_amount/num_person}");
template.fields.add("{=rank(sales_amount/num_person)}");
template.fields.add("{=runningsum(sales_amount)}");
template.fields.add("{=sales_amount/sum(sales_amount)*100}");
return template;
}
最后输出的报表截屏如下,怎么样,现在看起来功能还是挺强的吧!
当然了,这个程序只是拿很短的时间写的一个Demo,如果要变成一个成熟的产品,还要在很多地方做工作。比如:
- 可以把字段名称用中文显示,这样更便于非技术人员使用;
- 除了支持行列报表,还要支持交叉表,用于统计分析;
- 支持多维数据计算。
- ……
在报表工具中,编译技术除了用来做字段的计算,还可以用于其他功能,比如条件格式。我们可以在人均销售额低于某个数值时,给这行显示成红色,其中的判断条件,也是一个公式。
甚至你还可以为报表工具添加自定义公式功能。我们给用户提供脚本功能,用户可以自己做一个函数,实现某个领域的一个专业功能。我十分建议你在这个示例程序的基础上进一步加工,看看能做否做出一些让自己惊喜的功能。
总结
本我们做了一个示例性的报表工具。你能在这个过程中看到,像报表工具这样的软件,如果有编译技术的支持,真的可以做得很灵活、很强大。
与此同时,我们能看到编译技术可以跟某个应用领域结合在一起,内置在产品中,同时形成领域的DSL,比如报表的模板文件。这样,我们就相当于赋予了普通用户在某个领域内的编程能力,比如用户只需要编写一个报表模板,就可以生成报表了。
词法分析和语法分析都很简单,我们就是简单地用了表达式和函数调用的功能。而语义分析除了需要检查类型以外,还要检查所用到的字段和函数是否合法,这是另一种意义上的引用消解。而且这个例子中的运算的含义是向量运算,同样是加减乘除,每个操作都会处理一组数据,这也是一种语义上的区别。