前言:
很多网站的注册,登录都会有验证码,有安全作用的一方面,也避免了一些持续访问攻击对服务产生性能问题。
自动化测试中对验证码处理的办法一般有三种:
- 让开发写一个固定的验证码
- 自动化测试的时候让开发去掉验证码
- 自己想办法识别验证码
接下来使用python 中的pytesseract 模块和 PIL 模块解决一些不太复杂的验证码。
PIL(Python Imaging Library)是Python常用的图像处理库。
pytesseract 识别验证码。
思路步骤:
- 获取验证码页面
- 确定验证码坐标和大小
- 通过坐标和尺寸截取验证码图片,PIL 模块处理图片
- 通过pytesseract 识别验证码
安装PIL 和 pytesseract
pip install pytesseract -i https://pypi.douban.com/simple
pip install pillow -i https://pypi.douban.com/simple
Pillow 是 pil 的一个分支。
以下开始截取验证码图片。
找到验证码图片 id
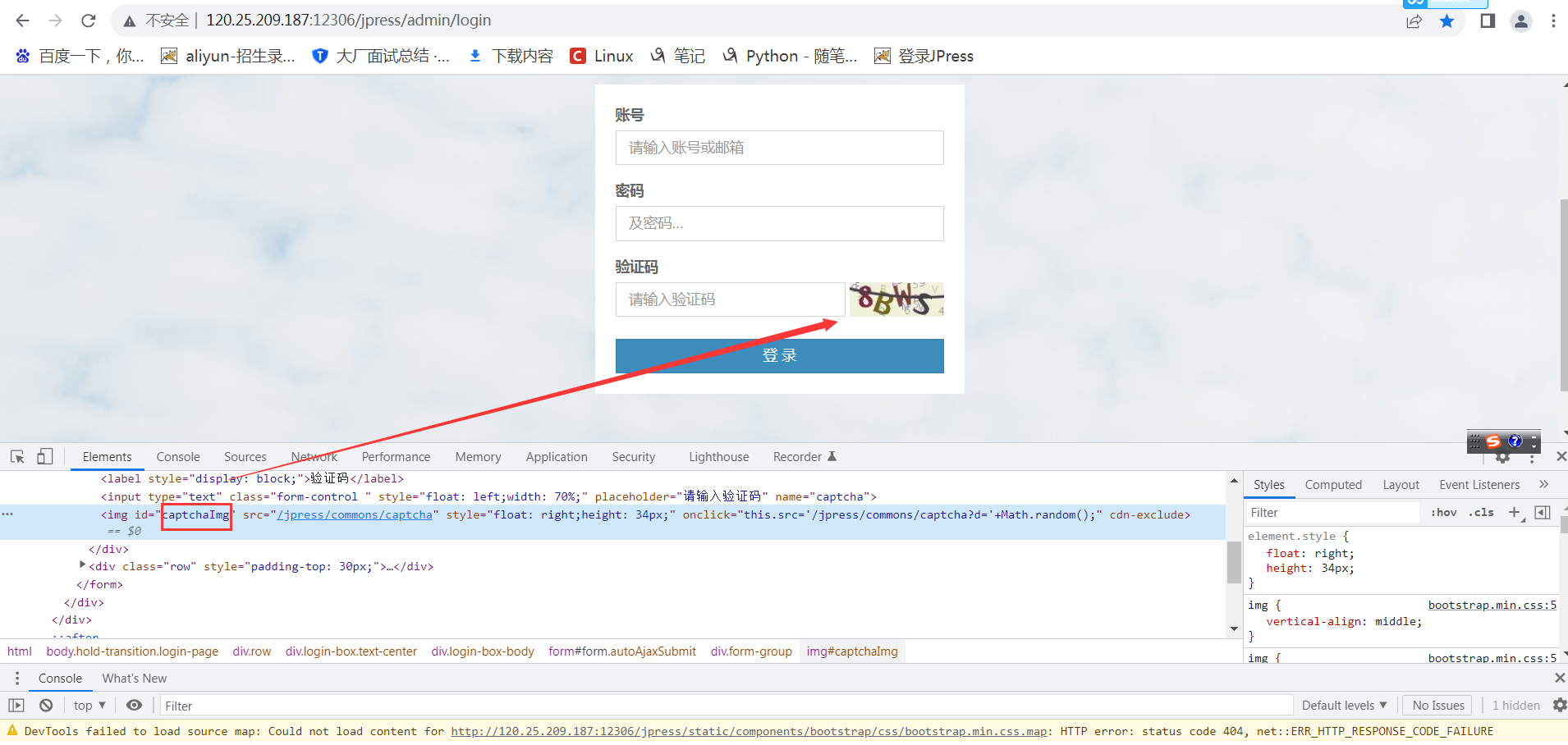
截取验证码
import time
from selenium import webdriver
from time import sleep
from PIL import Image
driver = webdriver.Chrome()
driver.get("http://120.25.209.187:12306/jpress/user/register")
sleep(2)
driver.maximize_window() # 页面最大化
t = time.time() # 时间戳
picture_name1 = str(t)+'.png' # 图片名称
driver.save_screenshot(picture_name1) # 截取登录页面图片
# 获取图片验证码坐标和尺寸
ce = driver.find_element_by_id("captchaimg")
print(ce.location)
left = ce.location['x']
top = ce.location['y']
right = ce.size['width']+left
height = ce.size['height']+top
sleep(2)
# 截取验证码图片
im = Image.open(picture_name1)
img = im.crop((left, top, right, height))
t = time.time()
picture_name2 = str(t)+'.png' # 验证码图片命名为 picture_name2
img.save(picture_name2)
driver.close()
识别登录页面验证码
from selenium import webdriver
import time
from PIL import Image
def matting():
# 打开谷歌浏览器
browser = webdriver.Chrome()
# 打开网站首页
# browser.get("https://v3pro.houjiemeishi.com/PC/pages/login/login.html")
browser.get("http://120.25.209.187:12306/jpress/admin/login")
# 网页最大化
browser.maximize_window()
# 登录页图片
picture_name1 = 'login1'+'.png'
# 保存第一张截图
browser.save_screenshot(picture_name1)
# 定位元素
ce = browser.find_element_by_id("captchaImg")
# ce = browser.find_element_by_xpath('//input[@class="ipt2"]')
# 打印元素位置、元素尺寸
print(ce.location, ce.size)
# 要抠验证码的图,先获取元素参数
# 坐标有时候要自己调节,参考这篇文章第八点,多试试二三十次,就可以截出来了。
# https://www.cnblogs.com/mypath/articles/6646858.html
left = ce.location.get('x') + 210
top = ce.location.get('y') + 100
r_size = ce.size.get('width') + 15
h_size = ce.size.get('height') + 10
right = r_size + left
height = h_size + top
# 读取刚才截的第一张图
im = Image.open(picture_name1)
# 抠图
img = im.crop((left, top, right, height))
# 验证码块的图片
picture_name2 = 'code1'+'.png'
# 保存图片
img.save(picture_name2)
time.sleep(2)
browser.close()
if __name__ == '__main__':
matting()