学习目的:
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特点字符、及这些特点字符组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正式步骤
Step1:常用匹配模式
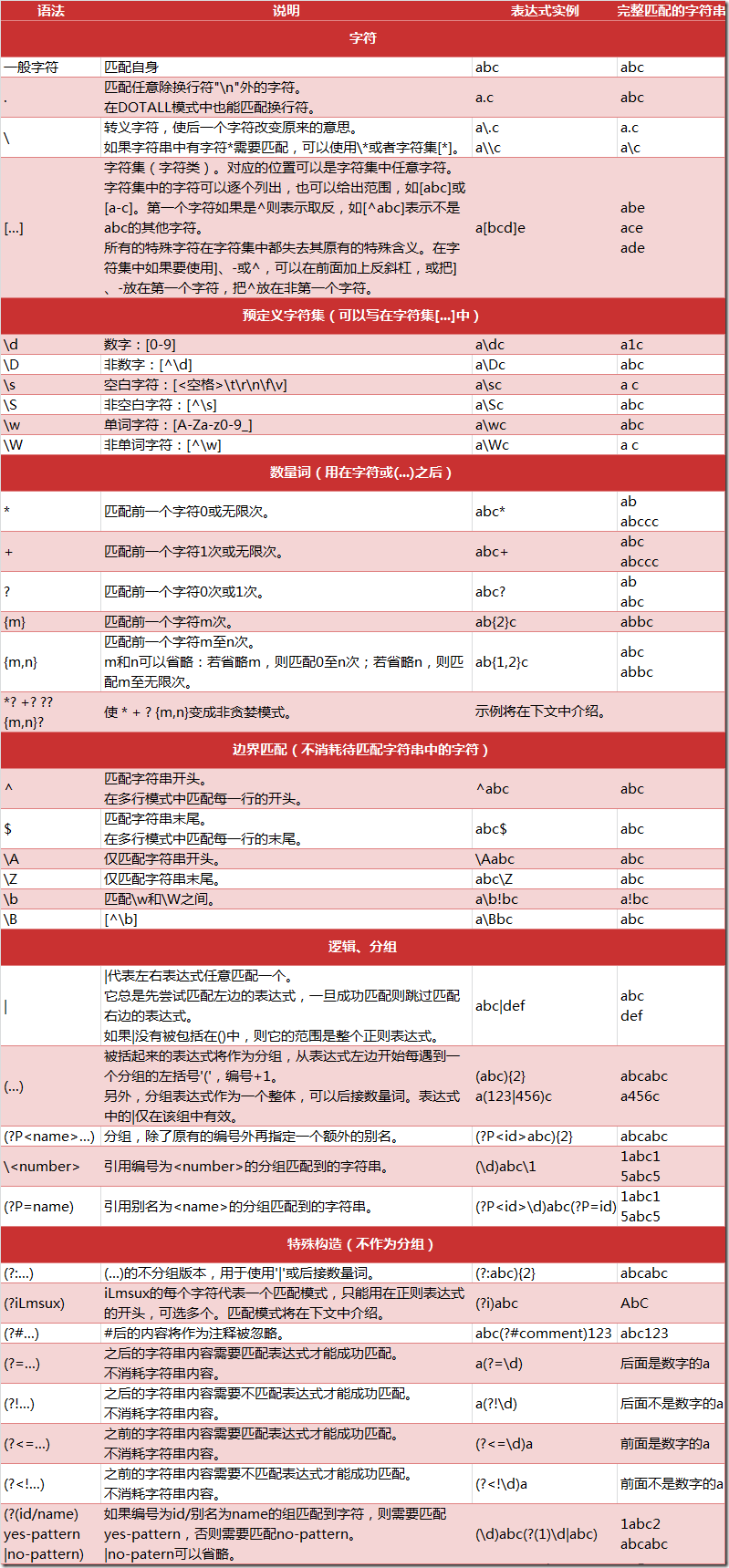
Step2:最常规的匹配
import re testString = 'I have 4Learned the python years' print(len(testString)) result = re.match('^Isw{4}sdw{7}.*years$',testString) print(result) print(result.group()) #现实匹配结果 print(result.span() #现实匹配区间
运行结果:
32 <_sre.SRE_Match object; span=(0, 32), match='I have 4Learned the python years'> I have 4Learned the python years (0, 32)
范匹配:
.*可以把除了匹配的开头和结尾都匹配
import re testString = 'I have 4Learned the python years' print(len(testString)) result = re.match('^I.*years$',testString) print(result) print(result.group()) print(result.span())
匹配目标:
设置起始端点后,用()来把需要匹配的目标括号起来
import re testString = 'I have Learned the python years' print(len(testString)) result = re.match('^Isw{4}s(w+)s.*years$',testString) print(result) print(result.group(1)) print(result.span())
贪婪匹配:
import re testString = 'I have 7777 Learned the python years' print(len(testString)) result = re.match('^I.*(d+).*years$',testString) print(result) print(result.group(1)) print(result.span())
运行结果:
36 <_sre.SRE_Match object; span=(0, 36), match='I have 7777 Learned the python years'> 7 (0, 36)
非贪婪匹配
import re testString = 'I have 7777 Learned the python years' print(len(testString)) result = re.match('^I.*?(d+).*years$',testString) print(result) print(result.group(1)) print(result.span())
运行结果:
36 <_sre.SRE_Match object; span=(0, 36), match='I have 7777 Learned the python years'> 7777 (0, 36)
Step3:匹配模式
包含换行符:
import re testString = '''I have 7777 Learned the python years''' print(len(testString)) result = re.match('^I.*(d+).*years$',testString,re.S) print(result) print(result.group(1)) print(result.span())
转义:
import re content = "i have $5.00" result = re.match('i have $5.00',content) print(result.group())
Step4: re.search
功能:扫描整个字符串,返回第一个成功的匹配
import re testString = '''I have 7777 Learned the python years''' print(len(testString)) result = re.search('I.*(d+).*years$',testString,re.S) print(result) print(result.group(1)) print(result.span())
总结:为了匹配方便,能用search就不用match,因为search方法不用限制匹配字符串的头部必须一致
Step5: re.compile
# -*- coding:utf-8 -*- """ re.compile 将一个正则表达式串编译成正则对象,以便于复用该匹配模式--简言之就是代码复用 按我的理解就是下面例子中的pattern就是过滤条件 """ import re content = "I love python" pattern = re.compile('I.*python',re.S) result = re.match(pattern,content) result1 = pattern.match(content) print(result.group()) print(result1.group())
运行结果:
I love python
I love python
学习总结:
正则表达式的应用需要多实践,在过滤爬取的数据时,应用较多