1、配置文件
package config
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
case object conf {
private val master = "local[*]"
val confs: SparkConf = new SparkConf().setMaster(master).setAppName("jobs")
// val confs: SparkConf = new SparkConf().setMaster("http://laptop-2up1s8pr:4040/").setAppName("jobs")
val sc = new SparkContext(confs)
sc.setLogLevel("ERROR")
val spark_session: SparkSession = SparkSession.builder()
.appName("jobs").config(confs).getOrCreate()
// 设置支持笛卡尔积 对于spark2.0来说
spark_session.conf.set("spark.sql.crossJoin.enabled",true)
}
2、读取RDD及转换dataframe,spark2.0 dataframe保存CSV文件方法
package sparkDataMange
import config.conf.{sc,spark_session}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SaveMode}
import config.conf.spark_session.implicits._
object irisDataMange {
def main(args: Array[String]): Unit = {
val path:String = "data/iris.data"
val irisData: RDD[String] = sc.textFile(path)
// case class irsModel(ft1:String,ft2:String,ft3:String,ft4:String,label:String)
val rdd1: RDD[Array[String]] = irisData.map(lines => {lines.split(",")})
val df: RDD[(Double, Double, Double, Double, Double)] = rdd1.map(line => {
(line(0).toDouble, line(1).toDouble, line(2).toDouble, line(3).toDouble,
if (line(4) == "Iris-setosa") {
1D
}
else if (line(4) == "Iris-versicolor") {
2D
}
else {
3D
})
})
val df1: DataFrame = df.toDF("ft1","ft2","ft3","ft4","label")
println(df1.count())
//创建临时表
df1.createOrReplaceTempView("iris")
spark_session.sql("select * from iris").show(150)
//保存csv
df1.coalesce(1).write.format("csv").save("data/irsdf")
sc.stop()
}
}
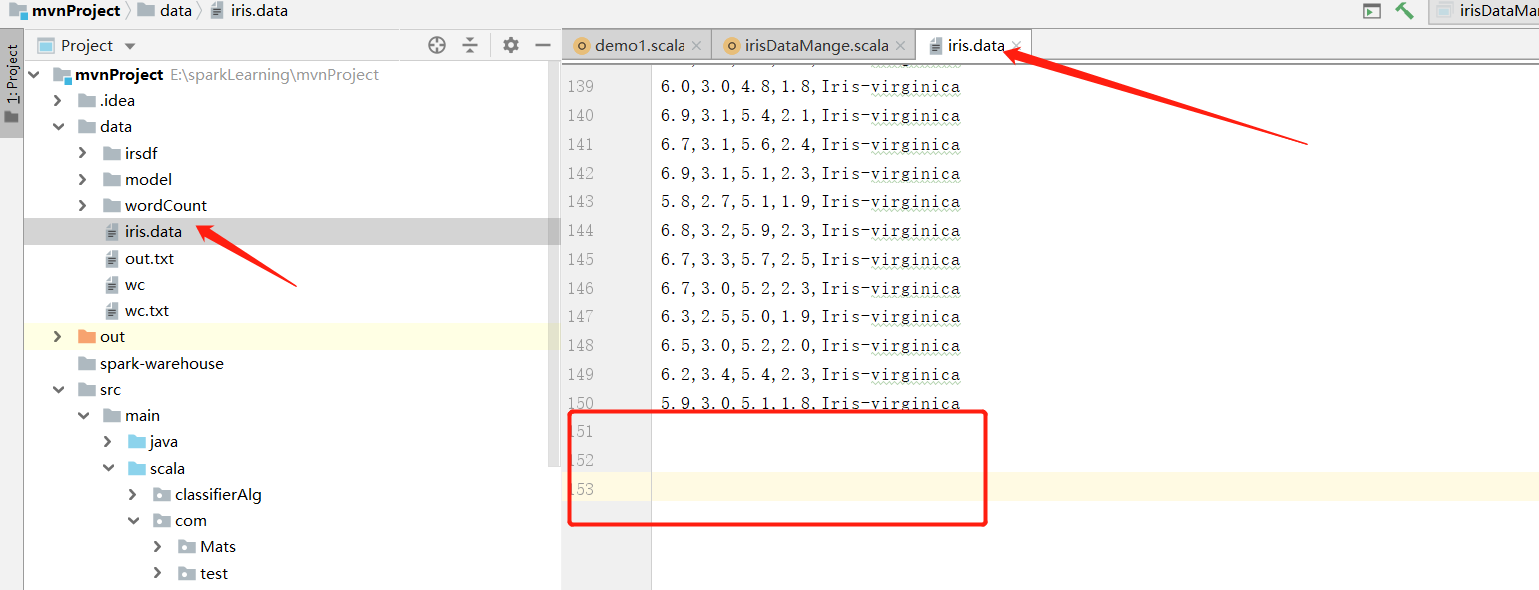
3、报错注意:
ERROR Executor:91 - Exception in task 1.0 in stage 0.0 (TID 1) java.lang.NumberFormatException: empty String
把多余的回车去掉,只保留标准的CSV数据格式,否则在处理转dataframe的时候出问题。