最近刚看了http协议,想写点东西加深一下理解,如果哪儿写错了,请指正。
1 介绍
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。它的发展是万维网协会(World Wide Web Consortium)和Internet工作小组IETF(Internet Engineering Task Force)合作的结果,(他们)最终发布了一系列的RFC,RFC 1945定义了HTTP/1.0版本。其中最著名的就是RFC 2616。RFC 2616定义了今天普遍使用的一个版本——HTTP 1.1。
HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议。它可以使浏览器更加高效,使网络传输减少。它不仅保证计算机正确快速地传输超文本文档,还确定传输文档中的哪一部分,以及哪部分内容首先显示(如文本先于图形)等。
1.1 http请求模型
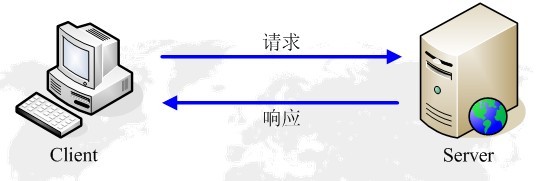
这样就限制了使用HTTP协议,无法实现在客户端没有发起请求的时候,服务器将消息推送给客户端.
1.2 工作流程
一次HTTP操作称为一个事务,其工作过程可分为四步:
1)首先客户机与服务器需要建立连接。只要单击某个超级链接,HTTP的工作开始。
2)建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
3)服务器接到请求后,给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
4)客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。对于用户来说,这些过程是由HTTP自己完成的,用户只要用鼠标点击,等待信息显示就可以了。
2 利用java代码测试各个协议头
一个完整的http协议包括请求和响应,下面我们一一介绍:
2.1 请求篇
http请求由三部分组成,分别是:请求行、消息报头、请求正文
请求行以一个方法符号开头,以空格分开,后面跟着请求的URI和协议的版本,格式如下:Method Request-URI HTTP-Version CRLF
其中 Method表示请求方法;Request-URI是一个统一资源标识符;HTTP-Version表示请求的HTTP协议版本;CRLF表示回车和换行(除了作为结尾的CRLF外,不允许出现单独的CR或LF字符)。
请求方法(所有方法全为大写)有多种,各个方法的解释如下:
GET 请求获取Request-URI所标识的资源
POST 在Request-URI所标识的资源后附加新的数据
HEAD 请求获取由Request-URI所标识的资源的响应消息报头
PUT 请求服务器存储一个资源,并用Request-URI作为其标识
DELETE 请求服务器删除Request-URI所标识的资源
TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断
CONNECT 保留将来使用
OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
应用举例:
GET方法:在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
POST方法要求被请求服务器接受附在请求后面的数据,常用于提交表单。
eg:POST /reg.jsp HTTP/ (CRLF)
Accept:image/gif,image/x-xbit,... (CRLF)
...
HOST:www.guet.edu.cn (CRLF)
Content-Length:22 (CRLF)
Connection:Keep-Alive (CRLF)
Cache-Control:no-cache (CRLF)
(CRLF) //该CRLF表示消息报头已经结束,在此之前为消息报头
user=jeffrey&pwd=1234 //此行以下为提交的数据
HEAD方法与GET方法几乎是一样的,对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。利用这个方法,不必传输整个资源内容,就可以得到Request-URI所标识的资源的信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新。
我们运用命令行命令Telnet进行测试:
1. 使用telnet连接到HTTP服务器,如要从google上请求index.html页面,首先要连接到服务器的80端口
2、请求报头后述
3、请求正文(略)
2.2 响应篇
- 状态行
200 OK //客户端请求成功
400 Bad Request //客户端请求有语法错误,不能被服务器所理解
401 Unauthorized //请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到请求,但是拒绝提供服务
404 Not Found //请求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的请求,一段时间后可能恢复正常
eg:HTTP/1.1 200 OK (CRLF)
- 头部行
2.3 测试协议头 ----响应头
通过在服务器端设置响应头,我们可以控制浏览器,在myeclipse搭建tomcat服务器我们简单地对几个进行了测试:
1,通知浏览器采用压缩数据方式发送,测试content-encoding和content-length
1 String data="aaaaaaaaaaa"; 2 System.out.print("原始数据大小:"+data.getBytes().length); 3 ByteArrayOutputStream bout=new ByteArrayOutputStream(); 4 GZIPOutputStream gout=new GZIPOutputStream(bout); 5 gout.write(data.getBytes()); 6 gout.close(); 7 8 byte gzip[]=bout.toByteArray(); 9 System.out.print("压缩后数据大小:"+gzip.length); 10 response.setHeader("Content-Encoding", "gzip"); 11 response.setHeader("Content-Length", gzip.length+""); 12 response.getOutputStream().write(gzip);
2,重定向 测试location
1 response.setStatus(302); 2 response.setHeader("Location","/web1/1.html");
3,通知浏览器以哪种方式打开数据 测试content-type
1 response.setHeader("content-type", "image/bmp"); 2 InputStream in=this.getServletContext().getResourceAsStream("/1.bmp"); 3 int len=0; 4 byte buffer[]=new byte[1024]; 5 6 OutputStream out=response.getOutputStream(); 7 while((len=in.read(buffer))>0){ 8 out.write(buffer,0,len); 9 }
4,定时刷新 跳转 测试refresh 3秒后刷新 然后跳到百度首页
1 response.setHeader("refresh", "3;url='http://uwww.baidu.com'"); 2 String data="aaaaaaaaaaaaaa"; 3 response.getOutputStream().write(data.getBytes());
5,下载方面的测试 content-disposition
1 response.setHeader("content-disposition","attachment;filename=2.bmp"); 2 InputStream in=this.getServletContext().getResourceAsStream("/2.bmp"); 3 int len=0; 4 byte buffer[]=new byte[1024]; 5 6 OutputStream out=response.getOutputStream(); 7 while((len=in.read(buffer))>0){ 8 out.write(buffer,0,len); 9 }
上面只是我的浅见,刚看完想写个博客,有错误欢迎指正!谢谢!