信息编码
首先,我们来考虑一下简单数据类型,如int,long,char,String等,是如何通过套接字发送和接收的。从前面章节我们已经知道,传输信息时可以通过套接字将字节信息写入一个OutputStream实例中(该实例已经与一个Socket相关联),或将其封装进一个DatagramPacket实例中(该实例将由DatagramSocket发送)。然而,这些操作所能处理的唯一数据类型是字节和字节数组。作为一种强类型语言,Java需要把其他数据类型(int,String等)显式转换成字节数组。所幸的是Java的内置工具能够帮助我们完成这些转换。在第2前面的TCPEchoClient.java示例程序中,我们看到过String类的getBytes()方法,该方法就是将一个Sring实例中的字符转换成字节的标准方式。在考虑数据类型转换的细节之前,我们先来看看大部分基本数据类型的表示方法。
基本整型
如我们所见,TCP和UDP套接字使我们能发送和接收字节序列(数组),即范围在0-255之间的整数。使用这个功能,我们可以对值更大的基本整型数据进行编码,不过发送者和接收者必须先在一些方面达成共识。一是要传输的每个整数的字节大小(size)。例如,Java程序中,int数据类型由32位表示,因此,我们可以使用4个字节来传输任意的int型变量或常量;short数据类型由16位表示,传输short类型的数据只需要两个字节;同理,传输64位的long类型数据则需要8个字节。
下面我们考虑如何对一个包含了4个整数的序列进行编码:一个byte型,一个short型,一个int型,以及一个long型,按照这个顺序从发送者传输到接收者。我们总共需要15个字节:第一个字节存放byte型数据,接下来两个字节存放short型数据,再后面4个字节存放int型数据,最后8个字节存放long型数据。
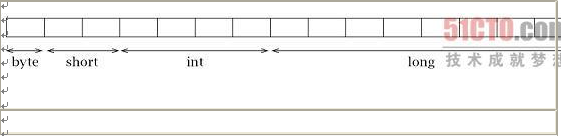
我们已经做好深入研究的准备了吗?未必。对于需要超过一个字节来表示的数据类型,我们必须知道这些字节的发送顺序。显然有两种选择:从整数的右边开始,由低位到高位地发送,即little-endian顺序;或从左边开始,由高位到低位发送,即big-endian顺序。(注意,幸运的是字节中位的顺序在实现时是以标准的方式处理的)考虑长整型数123456787654321L,其64位(以十六进制形式)表示为0x0000704885F926B1。如果我们以big-endian顺序来传输这个整数,其字节的十进制数值序列就如下所示:
order of transmission:传输顺序
如果我们以little-endian顺序传输,则字节的十进制数组序列为:
order of transmission:传输顺序
关键的一点是,对于任何多字节的整数,发送者和接收者必须在使用big-endian顺序还是使用little-endian顺序上达成共识[ ]。如果发送者使用了little-endian顺序来发送上述整数,而接收者以big-endian顺序对其进行接收,那么接收者将取到错误的值,它会将这个8字节序列的整数解析成12765164544669515776L。
发送者和接收者需要达成共识的最后一个细节是:所传输的数值是有符号的(signed)还是无符号的(unsigned)。Java中的四种基本整型都是有符号的,它们的值以二进制补码(two's-complement)的方式存储,这是有符号数值的常用表示方式。在处理有k位的有符号数时,用二进制补码的形式表示负整数-n(1 ≤ n ≤ 2k?1),则补码的二进制值就为2k?n。而对于非负整数p(0 ≤ p ≤ 2k?1 - 1),只是简单地用k位二进制数来表示p的值。因此,对于给定的k位,我们可以通过二进制补码来表示?2k?1到2k?1?1范围的值。注意,最高位(msb)标识了该数是正数(msb = 0)还是负数(msb = 1)。另外,如果使用无符号(unsigned)编码,k位可以直接表示0到2k - 1之间的数值。例如,32位数值0xffffffff(所有位全为1),将其解析为有符号数时,二进制补码整数表示-1;将其解析为无符号数时,它表示4294967295。由于Java并不支持无符号整型,如果要在Java中编码和解码无符号数,则需要做一点额外的工作。在此假设我们处理的都是有符号整数数据。
那么我们怎样才能将消息的正确值存入字节数组呢?为了清楚地展示需要做的步骤,我们将对如何使用"位操作(bit-diddling)"(移位和屏蔽)来显式编码进行介绍。示例程序BruteForceCoding.java中有一个特殊的方法encodeIntBigEndian()能够对任何值的基本类型数据进行编码。它的参数包括用来存放数值的字节数组,要进行编码的数值(表示为long型,它是最长的整型,能够保存其他整型的值),数值在字节数组中开始位置的偏移量,以及该数值写到数组中的字节数。如果我们在发送端进行了编码,那么必须能够在接收端进行解码。BruteForceCoding类同时还提供了decodeIntBigEndian()方法,用来将字节数组的子集解码到一个Java的long型整数中。
BruteForceCoding.java
0 public class BruteForceCoding {
1 private static byte byteVal = 101; // one hundred and
one
2 private static short shortVal = 10001; // ten thousand
and one
3 private static int intVal = 100000001; // one hundred
million and one
4 private static long longVal = 1000000000001L;// one
trillion and one
5
6 private final static int BSIZE = Byte.SIZE / Byte.SIZE;
7 private final static int SSIZE = Short.SIZE / Byte.SIZE;
8 private final static int ISIZE = Integer.SIZE /
Byte.SIZE;
9 private final static int LSIZE = Long.SIZE / Byte.SIZE;
10
11 private final static int BYTEMASK = 0xFF; // 8 bits
12
13 public static String byteArrayToDecimalString(byte[]
bArray) {
14 StringBuilder rtn = new StringBuilder();
15 for (byte b : bArray) {
16 rtn.append(b & BYTEMASK).append(" ");
17 }
18 return rtn.toString();
19 }
20
21 // Warning: Untested preconditions (e.g., 0 <= size <=
8)
22 public static int encodeIntBigEndian(byte[] dst,
long val, int offset, int size) {
23 for (int i = 0; i < size; i++) {
24 dst[offset++] = (byte) (val >> ((size - i - 1) *
Byte.SIZE));
25 }
26 return offset;
27 }
28
29 // Warning: Untested preconditions (e.g., 0 <= size <=
8)
30 public static long decodeIntBigEndian(byte[]
val, int offset, int size) {
31 long rtn = 0;
32 for (int i = 0; i < size; i++) {
33 rtn = (rtn << Byte.SIZE) | ((long) val[offset + i] &
BYTEMASK);
34 }
35 return rtn;
36 }
37
38 public static void main(String[] args) {
39 byte[] message = new byte[BSIZE + SSIZE + ISIZE + LSIZE];
40 // Encode the fields in the target byte array
41 int offset = encodeIntBigEndian(message, byteVal, 0,
BSIZE);
42 offset = encodeIntBigEndian(message, shortVal, offset,
SSIZE);
43 offset = encodeIntBigEndian(message, intVal, offset,
ISIZE);
44 encodeIntBigEndian(message, longVal, offset, LSIZE);
45 System.out.println("Encoded message: " +
byteArrayToDecimalString(message));
46
47 // Decode several fields
48 long value = decodeIntBigEndian(message, BSIZE, SSIZE);
49 System.out.println("Decoded short = " + value);
50 value = decodeIntBigEndian(message, BSIZE + SSIZE +
ISIZE, LSIZE);
51 System.out.println("Decoded long = " + value);
52
53 // Demonstrate dangers of conversion
54 offset = 4;
55 value = decodeIntBigEndian(message, offset, BSIZE);
56 System.out.println("Decoded value (offset " +
offset + ", size " + BSIZE + ") = "
57 + value);
58 byte bVal = (byte) decodeIntBigEndian(message, offset,
BSIZE);
59 System.out.println("Same value as byte = " + bVal);
60 }
61
62 }
BruteForceCoding.java
1. 数据项编码:第1-4行
2. Java中的基本整数所占字节数:第6-9行
3. byteArrayToDecimalString():第13-19行
该方法把给定数组中的每个字节作为一个无符号十进制数打印出来。BYTEMASK的作用是防止在字节数值转换成int类型时,发生符号扩展(sign-extended),即转换成无符号整型。
4.encodeIntBigEndian():第22-27行
赋值语句的右边,首先将数值向右移动,以使我们需要的字节处于该数值的低8位中。然后,将移位后的数转换成byte型,并存入字节数组的适当位置。在转换过程中,除了低8位以外,其他位都将丢弃。这个过程将根据给定数值所占字节数迭代进行。该方法还将返回存入数值后字节数组中新的偏移位置,因此我们不必做额外的工作来跟踪偏移量。
5. decodeIntBigEndian():第30-36行
根据给定数组的字节大小进行迭代,通过每次迭代的左移操作,将所取得字节的值累积到一个long型整数中。
6. 示例方法:第38-60行
准备接收整数序列的数组:第39行
对每项进行编码:第40-44行
对byte,short,int以及long型整数进行编码,并按照前面描述的顺序存入字节数组。
打印编码后数组的内容:第45行
对编码字节数组中的某些字段进行解码:第47-51行
解码后输出的值应该与编码前的原始值相等。
转换问题:第53-59行
在字节数组偏移量为4的位置,该字节的十进制值是245,然而,当将其作为一个有符号字节读取时,其值则为-11(回忆有符号整数的二进制补码表示方法)。如果我们将返回值直接存入一个long型整数,它只是简单地变成这个long型整数的最后一个字节,值为245。如果将返回值放入一个字节型整数,其值则为-11。到底哪个值正确取决于你的应用程序。如果你从N个字节解码后希望得到一个有符号的数值,就必须将解码结果(长的结果)存入一个刚好占用N个字节的基本整型中。如果你希望得到一个无符号的数组,就必须将解码结果存入更长的基本整型中,该整型至少要占用N+1个字节。
注意,在encodeIntBigEndian() 和 decodeIntBigEndian()方法的开始部分,我们可能需要做一些前提条件检测,如0 ≤ size ≤ 8 和 dst ≠ null等。你能举出需要做的其他前期检测吗?
运行以上程序,其输出显示了一下字节的值(以十进制形式):
如你所见,上面的强制(brute-force)编码方法需要程序员做很多工作:要计算和命名每个数值的偏移量和大小,并要为编码过程提供合适的参数。如果没有将encodeIntBigEndian()方法提出来作为一个独立的方法,情况会更糟。基于以上原因,强制编码方法是不推荐使用的,而且Java也提供了一些更加易用的内置机制。不过,值得注意的是强制编码方法也有它的优势,除了能够对标准的Java整型进行编码外,encodeIntegerBigEndian()方法对1到8字节的任何整数都适用--例如,如果愿意的话,你可以对一个7字节的整数进行编码。
构建本例中的消息的一个相对简单的方法是使用DataOutputStream类和ByteArrayOutputStream类。DataOutputStream 类允许你将基本数据类型,如上述整型,写入一个流中:它提供了writeByte(),writeShort(),writeInt(),以及writeLong()方法,这些方法按照big-endian顺序,将整数以适当大小的二进制补码的形式写到流中。ByteArrayOutputStream类获取写到流中的字节序列,并将其转换成一个字节数组。用这两个类来构建我们的消息的代码如下:
ByteArrayOutputStream buf = new ByteArrayOutputStream();
DataOutputStream out = new DataOutputStream(buf);
out.writeByte(byteVal);
out.writeShort(shortVal);
out.writeInt(intVal);
out.writeLong(longVal);
out.flush();
byte[] msg = buf.toByteArray();
也许你想运行这段代码,来证实它与BruteForceEncoding.java的输出结果一样。
讲了这么多发送方相关的内容,那么接收方将如何恢复传输的数据呢?正如你想的那样,Java中也提供了与输出工具类相似的输入工具类,分别是DataInputStream类和ByteArrayInputStream类。在后面讨论如何解析传入的消息时,我们将对这两个类的使用举例。并且,在第5章中,我们还会看到另一种方法,使用ByteBuffer类将基本数据类型转换成字节序列。
最后,本节的所有内容基本上也适用于BigInteger类,该类支持任意大的整数。对于基本整型,发送者和接收者必须在使用多大空间(字节数)来表示一个数值上达成共识。但是这又与使用BigInteger相矛盾,因为BigInteger可以是任意大小。一种解决方法是使用基于长度的帧,我们将在第3.3节看到这种方法。
相关下载:
 Java_TCPIP_Socket编程(doc)
Java_TCPIP_Socket编程(doc)
http://download.csdn.net/detail/undoner/4940239
文献来源:
UNDONER(小杰博客) :http://blog.csdn.net/undoner
LSOFT.CN(琅软中国) :http://www.lsoft.cn