1.html下载后乱码
直接用浏览器检查原网页的编码,然后把你下载下来的网页数据设置为网页上显示的编码,result.encoding=“网页上的编码”
2.直接获取api的json数据乱码
最近几年网页传输出现了新的br压缩方式,在请求的时候如果你的headers里面
Accept-Encoding是“gzip, deflate, br”,
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0', 'Accept': '*/*', 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Accept-Encoding': 'gzip, deflate, br', 'X-Requested-With': 'XMLHttpRequest', 'Connection': 'keep-alive', }
服务器会在其中选择一种方式压缩,将数据传输回来,有的服务器会选择br方式将数据传输回来,由于现在一些库还暂时不认识br这种压缩方式,所以下载下来就会乱码,就像这样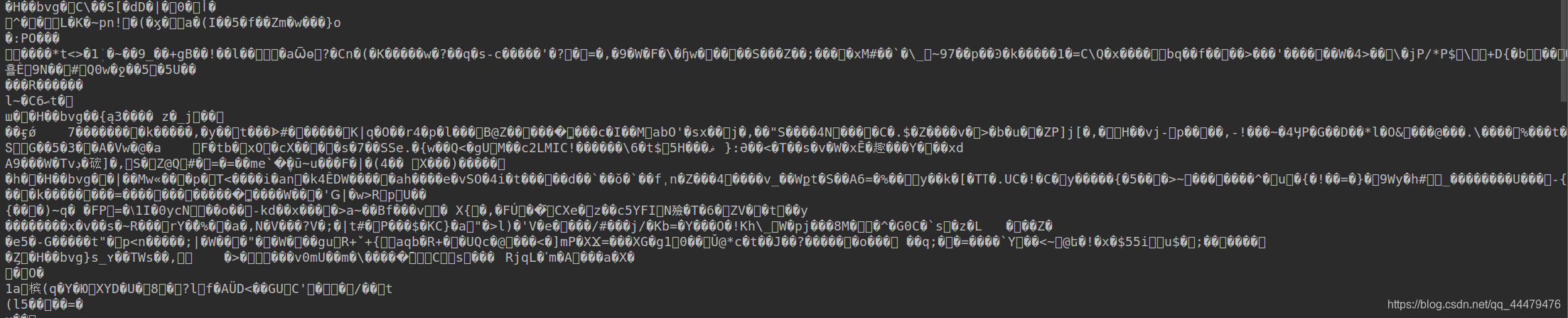 解决的办法有两个:
解决的办法有两个:
①将headers中的’Accept-Encoding’属性的值修改一下
改为’gzip’或者是‘deflate’,像这样:
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0', 'Accept': '*/*', 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Accept-Encoding': 'gzip', 'X-Requested-With': 'XMLHttpRequest', 'Connection': 'keep-alive', }
这样返回的数据的压缩方式就使用的是gzip,数据就可以正常被解压,从而可以正常读取
②安装brotli库进行解压
先安装库pip install brotli,现在我们的headers就改成这样,Accept-Encoding就只用br,因为我们要使用返回的用br压缩的数据,这里用一段代码演示
import requests import brotli start_url = "url" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0', 'Accept': '*/*', 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Accept-Encoding': 'br', 'X-Requested-With': 'XMLHttpRequest', 'Connection': 'keep-alive', } r = requests.get(start_url, headers) content = brotli.decompress(r.content) content = content.decode("utf-8") print(content)