一、什么是模型复杂度
机器学习是通过学习训练集的数据从而得到具体的模型,最终达到预测未知数据的能力;这就涉及到模型对训练数据的拟合能力了;从数理统计的角度来看,不同的训练数据集会有不同的概率分布规律;只有我们的模型的具有表达训练集的数据分布规律的能力才能训练得到一个好的模型,而模型的这个能力就是模型复杂度;
二、从泰勒中值定理看模型复杂度
对于一些比较复杂的函数,为了便于计算和研究,往往希望将其用一些简单的函数来近似表达。多项式是最为简单的一类函数,它只要对自变量进行有限次的加、减、乘三种算术运算,就能求出其函数值。因此多项式经常被用于近似地表达函数,这种近似表达在数学上称为多项式逼近。
英国数学家泰勒在多项式逼近方面做出了开创性贡献。 他的研究结果表明:具有n+1阶导数的函数在一个点的邻域内的值可以用函数在该点的函数值及各阶导数值组成的n次多项式近似表达,即泰勒中值定理。
泰勒中值定理
如果函数f(x)在含有x0的开区间(a,b)内具有直到n+1阶的导数,则对任一x∈(a,b),有
其中
所有光滑的函数图像都可以使用泰勒中值定理以任意精度去逼近模拟,展开成泰勒多项式的形式后,我们就可以看到一个模型复杂程度由以下两个因素决定了
● 模型多项式系数数量的多少,系数越少,相应地多项式项数就越少,意味着模型函数图像的曲线形状越简单。
● 模型多项式系数数值的大小,系数越小,意味着该多项式项对结果影响越轻微,模型函数图像的曲线越平滑。
我们只有恰当地做好模型复杂度的权衡决策,才能令模型既能正确地识别样本,又不至于过度复杂,学习到了属于训练集本身的特征。
三、模型复杂度对数据拟合的影响
机器学习更加关注模型在未知数据上的泛化能力,而不仅仅是在训练数据集上的拟合能力;虽然训练集和测试集遵循统一数据生成分布,理论上两者的误差的期望应该是一样的,但是由于模型是基于训练集进行训练拟合的,所以一般情况下测试误差要比训练误差大;为了得到一个更好模型,我们需要从以下两方面进行努力
● 降低训练误差。
● 缩小训练误差和测试误差的差距。
这两个因素对应机器学习的两个主要挑战:欠拟合(underfitting)和过拟合(overfitting)。欠拟合是指模型不能在训练集上获得足够低的训练误差,而过拟合是指训练误差和测试误差之间的差距太大。
通过调整模型的复杂度,我们可以控制模型是否偏向于过拟合或者欠拟合。过于简单的模型可能很难拟合训练集。太复杂的模型可能会过拟合,因为记住了不适用于测试集的训练集性质。
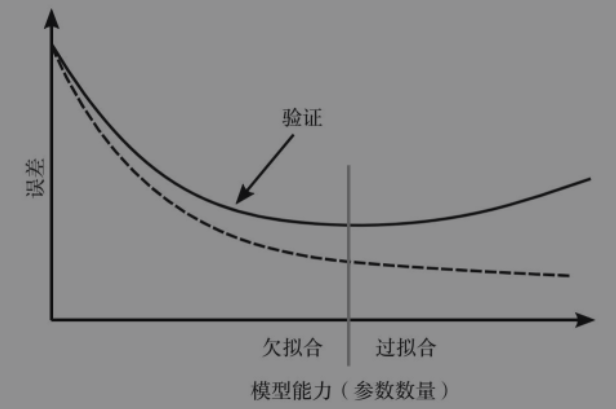
对于相同数量的训练数据,随着使用更复杂的模型,训练误差会逐步减少。但是测试误差会经过一个最小值后开始上升。上升就是所谓的过拟合:机器从学习示例中学习了太多细节,并且忽视了我们要其完成的任务的一般性。它开始死记硬背地学习,而不是试图从中提取规律。该曲线的最低点给出了我们应该选择的模型的复杂度。
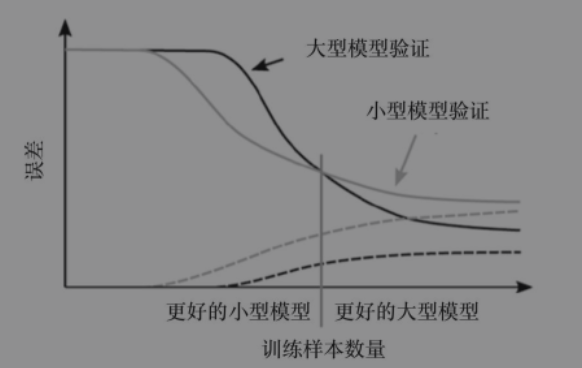
对于一个给定的模型,随着训练集数量的增加,训练误差(虚线)缓慢上升,而测试误差(实线)缓慢下降。对于较简单的小型模型(灰色线),曲线在较少的训练数量上开始变得越来越近,并且越来越快,但是最终误差是相当大的。对于比较复杂的大型模型(具有更多参数),两条曲线开始逼近之前需要更多的示例。它们彼此靠近的速度较慢,但最终的误差较小。测试误差的两条曲线相交。交点之前,优选小型模型;交点之后,大型模型更佳。
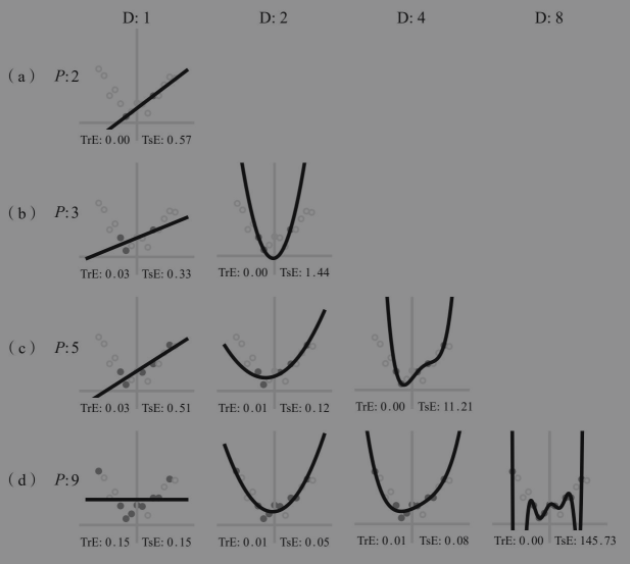
通过下边一个简单的示例,我们从整体上来感受一下;下边图中,P代表参与训练的数据数量,D代表模型的复杂程度(代表多项式的最高次数),TrE代表训练误差,TsE代表测试误差;
从图中我们可以看到
随着训练数据集点数的增加,数据的分布规律变的更加复杂;
随着训练数据集点数的增加,突破了简单模型的表达能力,导致训练误差随之增大,这就是欠拟合问题;
如果模型的复杂度太大,超过了训练数据集的数据分布的复杂度,会导致模型过度的解读局部的数据点,导致模型的训练误差为0,但是测试误差增大,这就是过拟合问题;
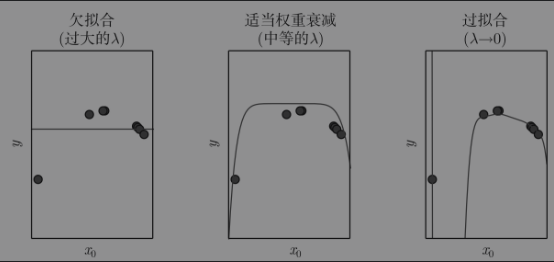
四、使用正则化避免过拟合
正则化是避免过拟合的有效方式,是在训练误差上加一个正则化项(regularizer)或罚项(penalty term)。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数向量的范数。
其中,第1项是经验风险,第2项是正则化项,λ≥0为调整两者之间关系的系数。
正则化项可以取不同的形式。例如,回归问题中,损失函数是平方损失,正则化项可以是参数向量的L2范数:
第1项的模型可能较复杂(有多个非零参数),这时第2项的模型复杂度会较大。正则化的作用是选择训练误差与模型复杂度同时较小的模型。
具体为什么可以直接通过添加一个正则化项可以实现控制模型复杂度,可以参考拉格朗日乘数法,一种计算条件极值的方式。
在下边的图中,我们使用9阶多项式加L2范数来拟合按照二次函数分布的训练数据;在左图中,当λ非常大时,我们可以强迫模型学习到一个没有斜率的函数。由于它只能表示一个常数函数,所以会导致欠拟合。在中间的图中,取一个适当的λ时,学习算法能够用一个正常的形状来恢复曲率。即使模型能够用更复杂的形状来表示函数,L2范数也鼓励用一个带有更小参数的更简单的模型来描述它。在右图中,当权重衰减趋近于0时,这个9阶多项式会导致严重的过拟合。