退役选手开始刷LeetCode重温算法,没想到KMP已经忘得一干二净了,整理一下思路
KMP算法就是对于下面用来匹配的串,因为我们已经知道比较到 P[j] 的时候, S[i - 1, i - j] 的部分和 P[j - 1, 0 ] 的部分是匹配的
那么我们如果知道P[j - 1] 的最长相等前缀(p[j - 1, j - k] = p[k - 1, 0]),那么不需要挪动 i, 需要把 j 移动到 k 开始比较就可以了。
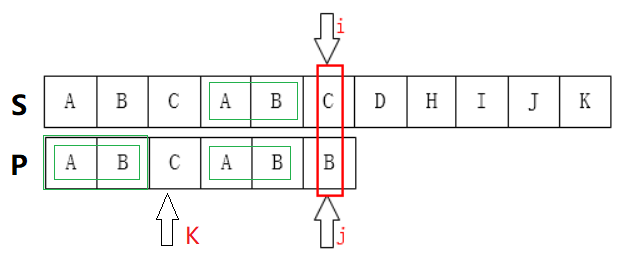
所以问题就在于我们要初始化一个数组 next 用来计算 P 每个位置对应的最长前缀
定义 next[j] = k 表示 P[j - 1, j - k] = P[k - 1, 0]
next 的求解代码如下
1 vector<int> getNext(string s) { 2 int j = 0; 3 int k = -1; 4 int m = s.length(); 5 vector<int> next(m); 6 next[0] = -1; 7 while(j < m - 1) { 8 if(k == -1 || s[j] == s[k]) 9 next[++j] = ++k; 10 else 11 k = next[k]; 12 } 13 return next; 14 }
例如上图的 P 计算得到的 next
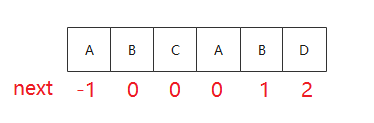
其中 next[0] = -1 是因为 j = 0 时无法再左移了, 因此需要移动 i 了

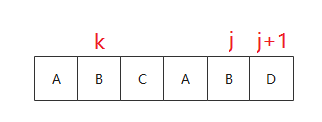
当 P[j] == P[k] 时很好解决 因为 P[j - 1, j - k - 1] = P[k - 1, 0], 所以 P[j, j - k - 1] = P[k , 0]
只需 next[j + 1] = k + 1 即可 如下图例子
当 P[j] != P[k] 时, 意味着当前的前缀不能再延长了, 为了获取新的最长前缀,我们需要查看下一个可能的最长前缀
所以这就是 k = next[k] 的原因
如下图,我们知道 P[j - 1, j - k] = p[k - 1, 0], 而 p[k - 1, k - next[k]] = p[next[k] - 1, 0] 所以这三部分是相同的, 因此next[k] 前面的部分就是可能的最长前缀。
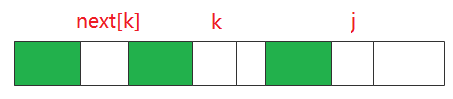
可以用下面的例子推导一下
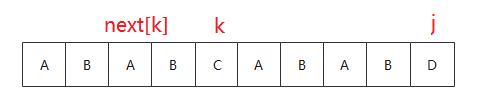
OK, KMP的部分就结束了,下面上代码
1 class Solution { 2 public: 3 4 vector<int> getNext(string s) { 5 int j = 0; 6 int k = -1; 7 int m = s.length(); 8 vector<int> next(m); 9 next[0] = -1; 10 while(j < m - 1) { 11 if(k == -1 || s[j] == s[k]) 12 next[++j] = ++k; 13 else 14 k = next[k]; 15 } 16 return next; 17 } 18 19 int strStr(string haystack, string needle) { 20 int n = haystack.length(), m = needle.length(); 21 if(m == 0) 22 return 0; 23 vector<int> next = getNext(needle); 24 int i = 0, j = 0; 25 while(i < n && j < m) { 26 if(j == -1 || haystack[i] == needle[j]) { 27 i++; 28 j++; 29 } else { 30 j = next[j]; 31 } 32 } 33 if(j == m) 34 return i - j; 35 return -1; 36 } 37 };