前言
本篇是Kubernetes第八篇,大家一定要把环境搭建起来,看是解决不了问题的,必须实战。Pod篇暂时应该还缺少两篇,等Service和存储相关内容介绍以后,补充剩下的两篇,有状态的Pod会涉及这两块的内容。
Kubernetes系列文章:
Kubernetes介绍 Kubernetes环境搭建 Kubernetes-kubectl介绍 Kubernetes-Pod介绍(-) Kubernetes-Pod介绍(二)-生命周期 Kubernetes-Pod介绍(三)-Pod调度 Kubernetes-Pod介绍(四)-Deployment
为什么需要Service
在应用创建一个Nginx的Pod集合,由3个Pod组成,每个容器的端口端口号都是80;
编辑nginx-deployment.yaml;
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: backend
replicas: 3
template:
metadata:
labels:
app: backend
spec:
containers:
- name: nginx
image: nginx:latest
resources:
limits:
memory: "128Mi"
cpu: "128m"
ports:
- containerPort: 80
创建Deployment资源;
kubectl apply -f nginx-deployment.yaml
查看Pod的IP;
kubectl get pods -o wide

通过IP访问Pod;
curl 10.100.1.92:80
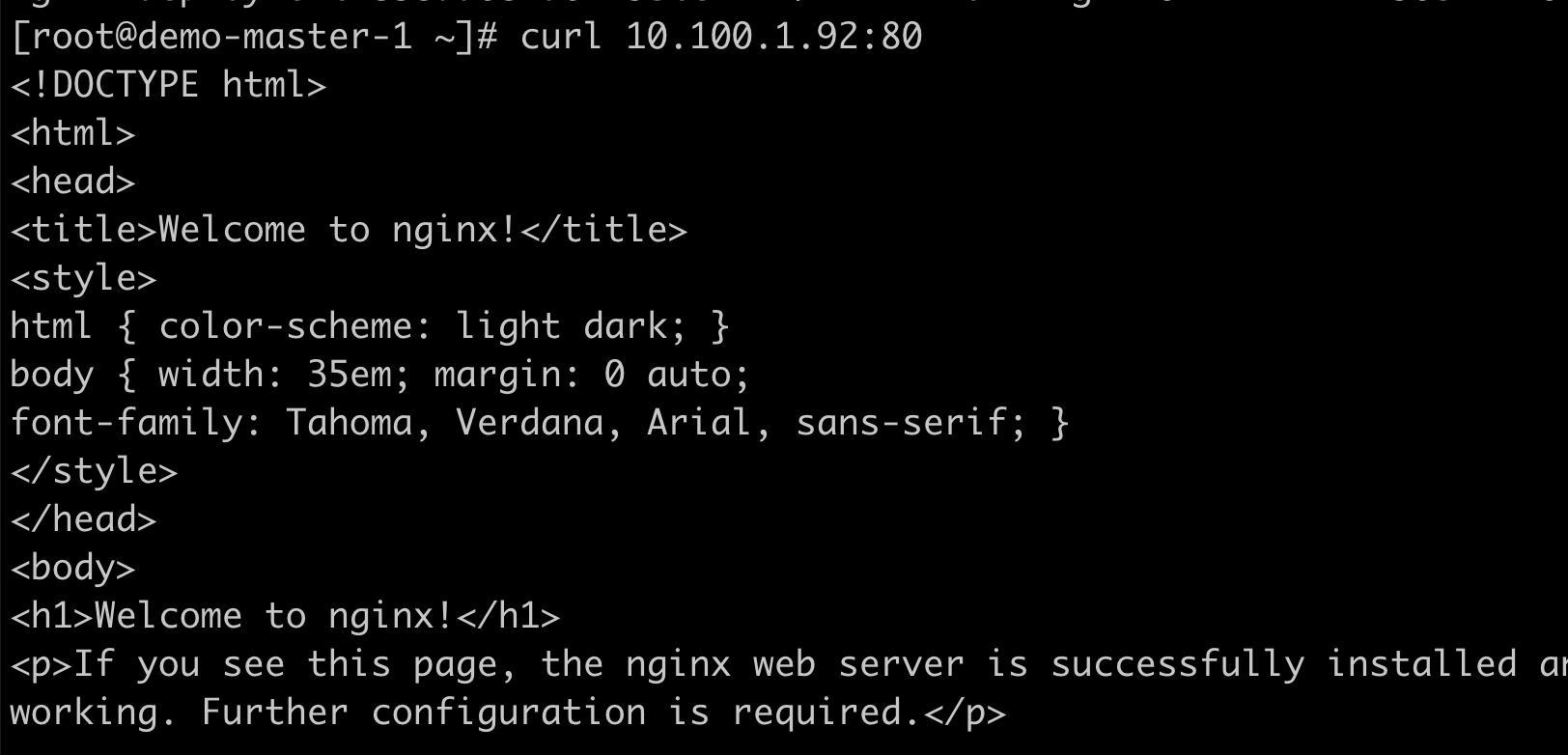
这样就会存在问题,由于Pod的生命是有限的,如果Pod重启IP有可能会发生变化。如果我们的服务都是将Pod的IP地址写死,Pod的IP发生变化以后,后端服务也将会不可用。当然我们可以通过手动更新如nginx的upstream配置来改变后端的服务IP。也可以通过Consul,ZooKeeper、etcd等工具,把我们的服务注册到这些服务发现中心,然后让这些工具动态的去更新Nginx的配置就可以了,我们完全不用去手工的操作了。
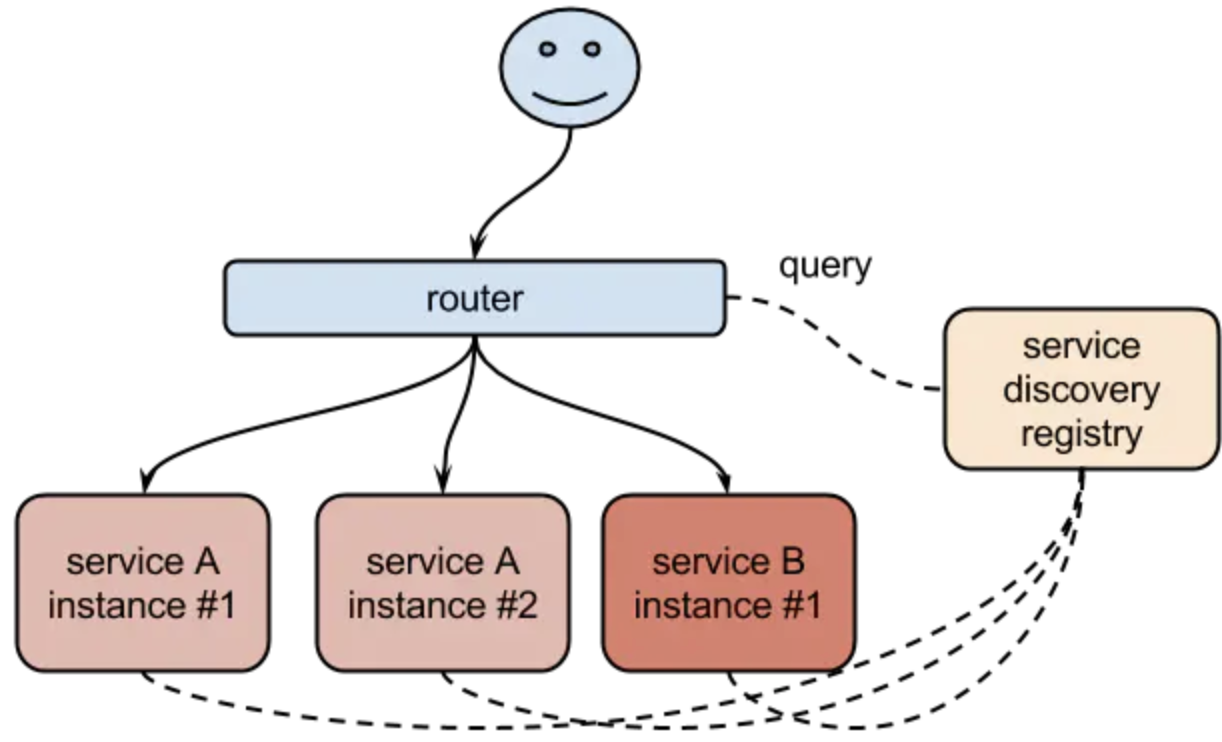
Kubernetes提供了Service对象,它定义了一组Pod的逻辑集合和一个用于访问它们的策略,这个概念和微服务非常类似。一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。这样就可以不用去管后端的Pod如何变化,只需要指定Service的地址就可以了,这厮因为我们在中间添加了一层服务发现的中间件,Pod销毁或者重启后,把这个Pod的地址注册到这个服务发现中心去。Service的这种抽象就可以帮我们达到这种解耦的目的。
Service原理初探
我们以前面创建的nginx为案例,通过创建一个Service来给3个Pod做负载:
创建Service方式有两种,一种是通过kubectl expose命令来创建,另外一个种通过yaml文件来创建,这里我们采用yaml方式来创建,创建一个nginx-service.yaml文件;
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
#定义后端pod标签为app=backend
selector:
app: backend
ports:
#service端口号
- port: 80
#pod的端口号
targetPort: 80
创建Service对象;
kubectl apply -f nginx-service.yaml
查看Service的IP地址;
kubectl get svc
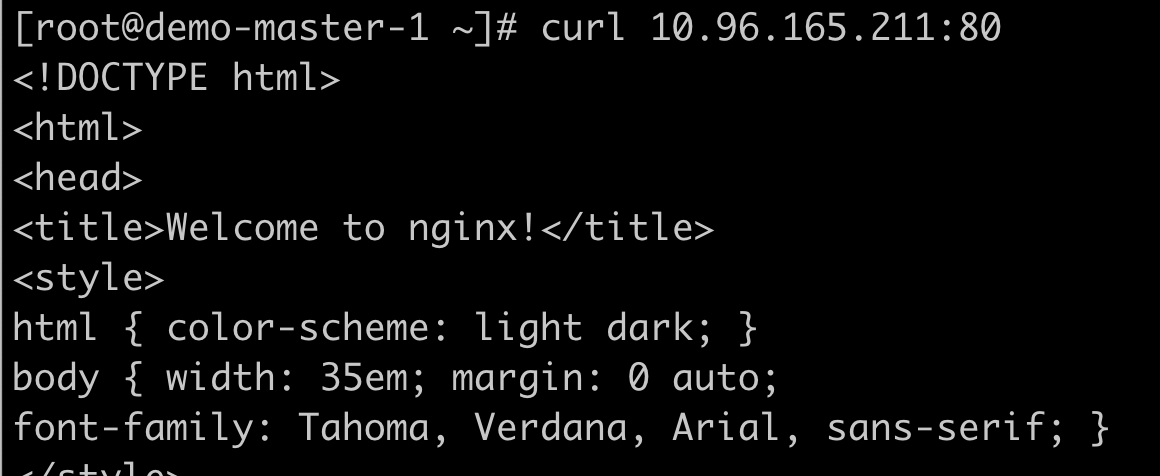
通过ServiceIP和端口号访问;
curl 10.96.165.211:80
查看Service的Endpoint的列表;
kubectl describe svc nginx-service
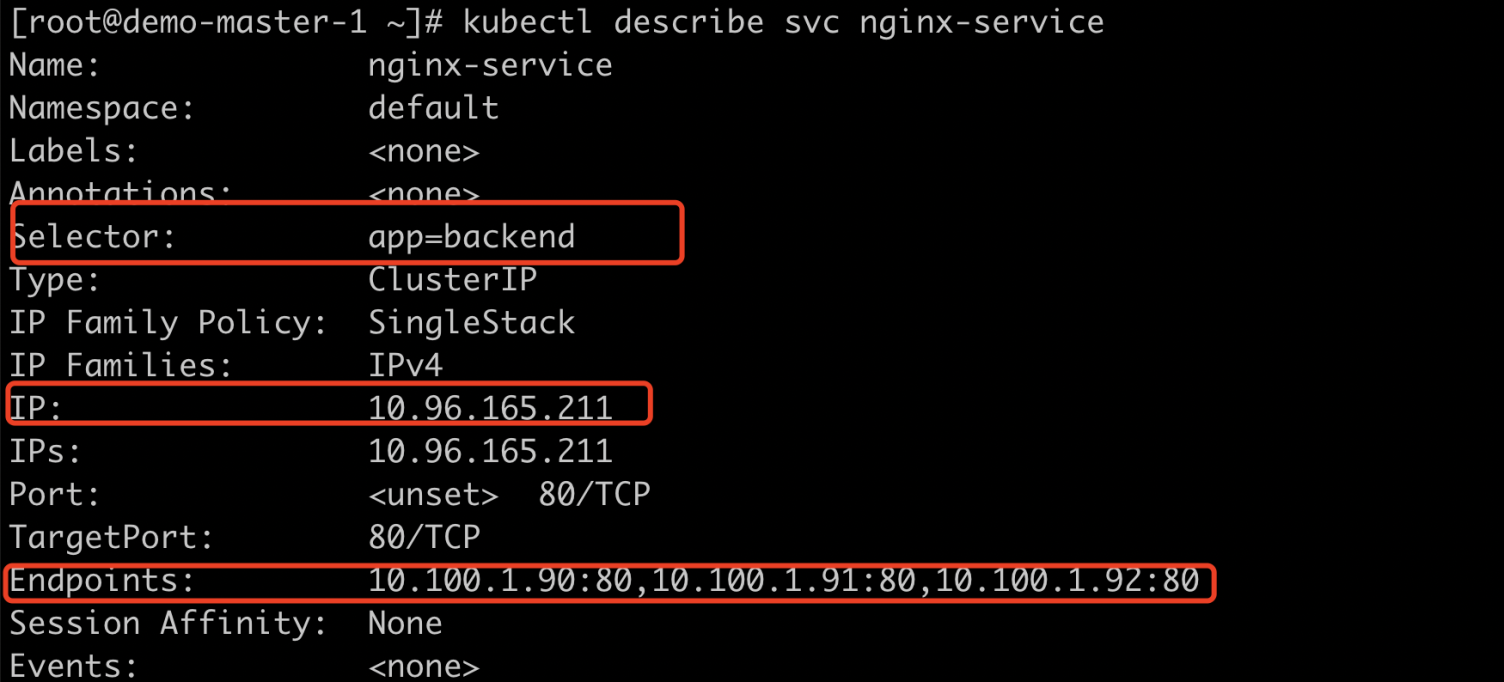
这里我们可以初步看出来Service的服务发现离不开Endpoint对象,Endpoint是Kubernetes中的一个资源对象,存储在Etcd中,用来记录一个Service对应的所有Pod的访问地址。Service配置Selector,Endpoint Controller才会自动创建对应的Endpoint对象;否则不会创建Endpoint对象。Endpoint Controller主要有以下作用:
负责生成和维护所有endpoint对象的控制器 负责监听Service和对应Pod的变化,监听到Service被删除,则删除和该Service同名的Endpoint对象;监听到新的Service被创建,则根据新建Service信息获取相关Pod列表,然后创建对应Endpoint对象;监听到Service被更新,则根据更新后的Service信息获取相关Pod列表,然后更新对应Endpoint对象;监听到Pod事件,则更新对应的Service的Endpoint对象,将Pod IP记录Eendpoint中;
Endpoint完成服务发现,真正从服务IP到后端Pod的负载均衡的实现则是由每个Node节点上的kube-proxy负责实现的,kube-proxy会监听Service和Endpoints的更新并调用其代理模块在主机上刷新路由转发规则,从而实现动态跟新服务列表,整体访问情况可以参考下图,这是第一代kube-proxy实现方式,现在的实现方式有所调整,但是我觉得这个是最容易让人明白的方式。
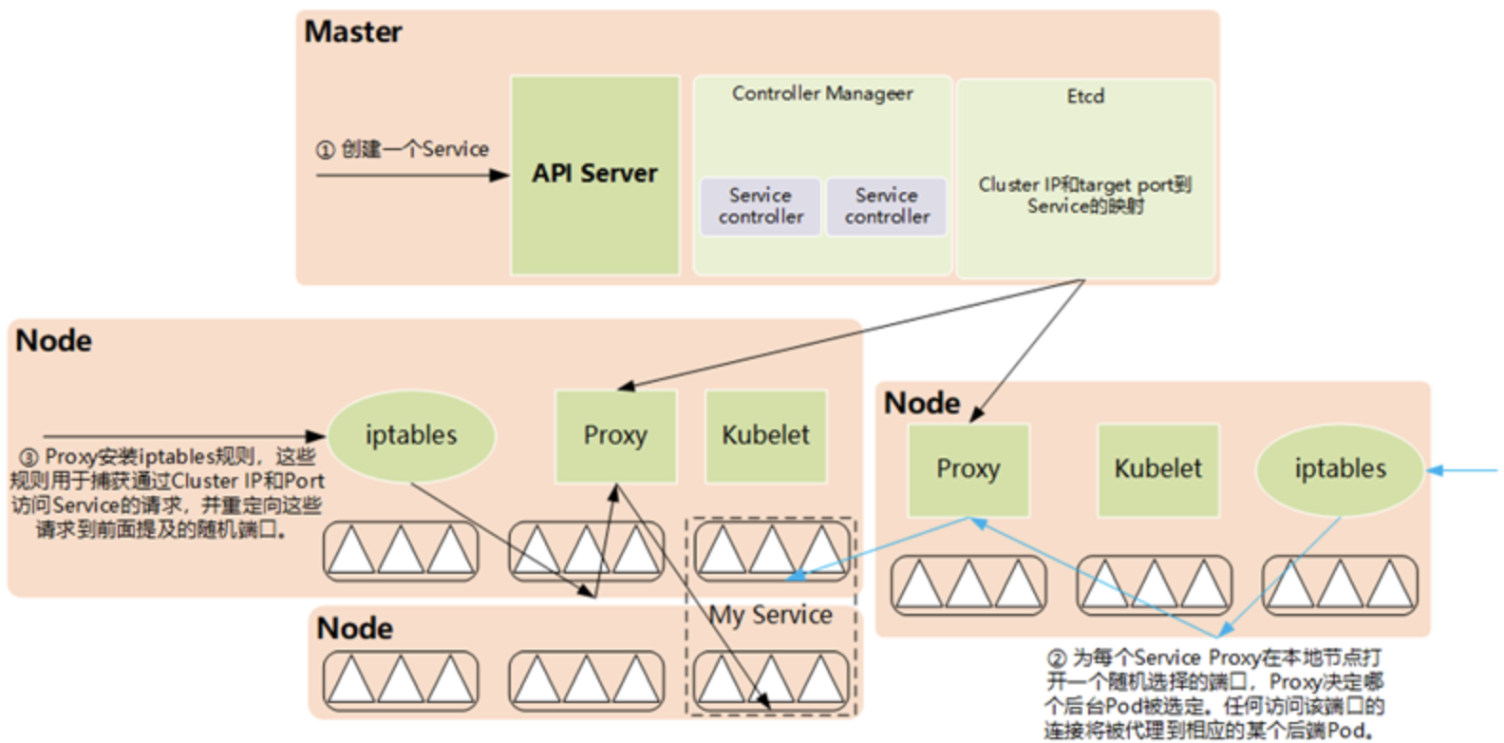
下图是第二代或者第三代实现方式,实现方式:
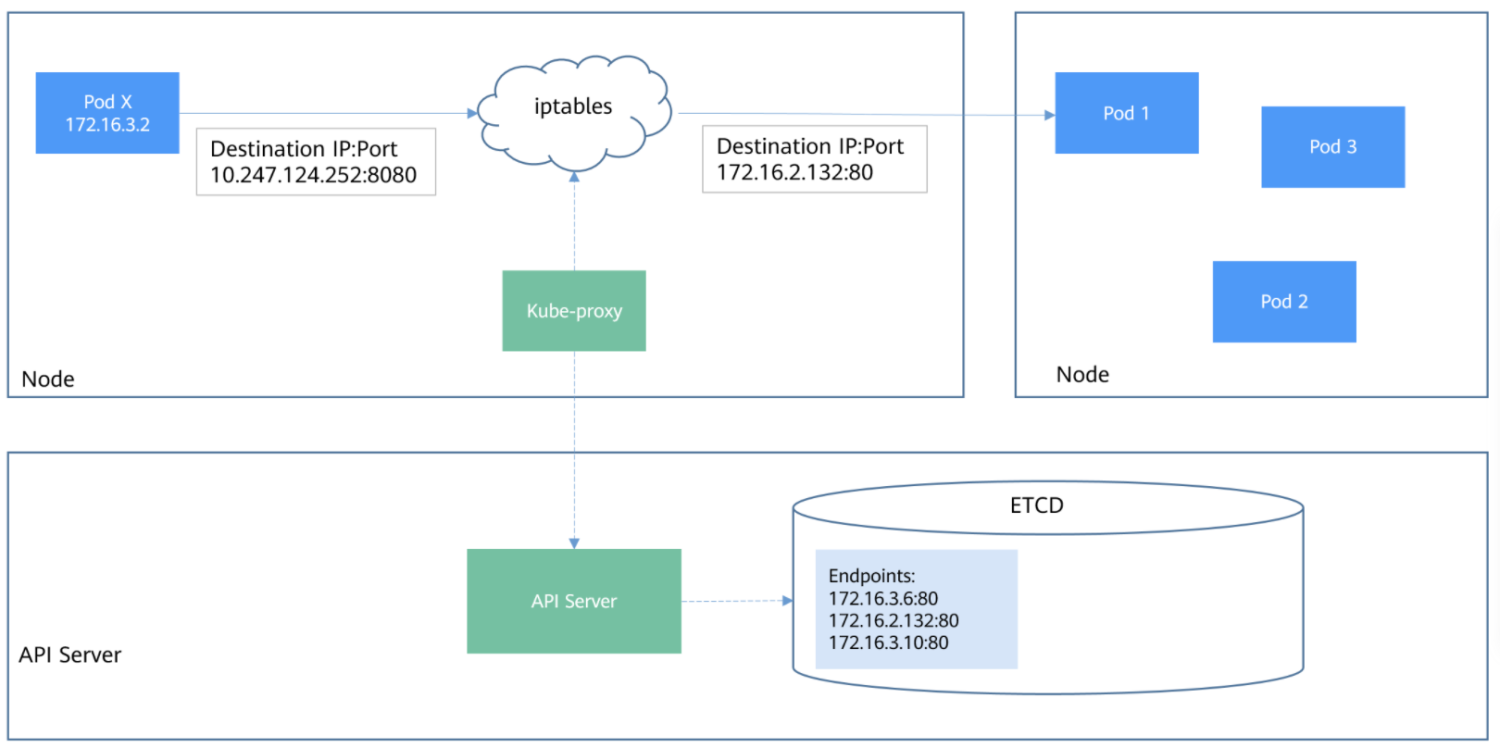
Service负载均衡
Service路由转发都是由 kube-proxy 组件来实现的,Service 仅以一种 ClusterIP 的形式存在,kube-proxy 将Service访问请求转发到后端的多个Pod的实例上,kube-proxy 的路由转发规则是通过其后端的代理模块实现的,kube-proxy 的代理模块目前有三种实现方案:
userspace
在userspace(用户空间代理)模式下,kube-proxy进程是一个真实的TCP/UDP代理,负责从Service到Pod的访问流量的转发,如下图:
userspace模式下kube-proxy通过API Server的Watch接口实时跟踪Service与Endpoint的变更信息,来实现动态更新iptables规则;对每个Service它都为其所在Node节点开放一个端口,作为其服务代理端口;发往该端口的请求会采用一定的策略转发给与该服务对应的后端Pod实体。kube-proxy同时会在本地节点设置 iptables 规则,这个规则用于捕获通过Cluter IP和Port访问Service请求,并将这些转发到对应的端口上,如果采用DNS形式,前面还有DNS解析层。
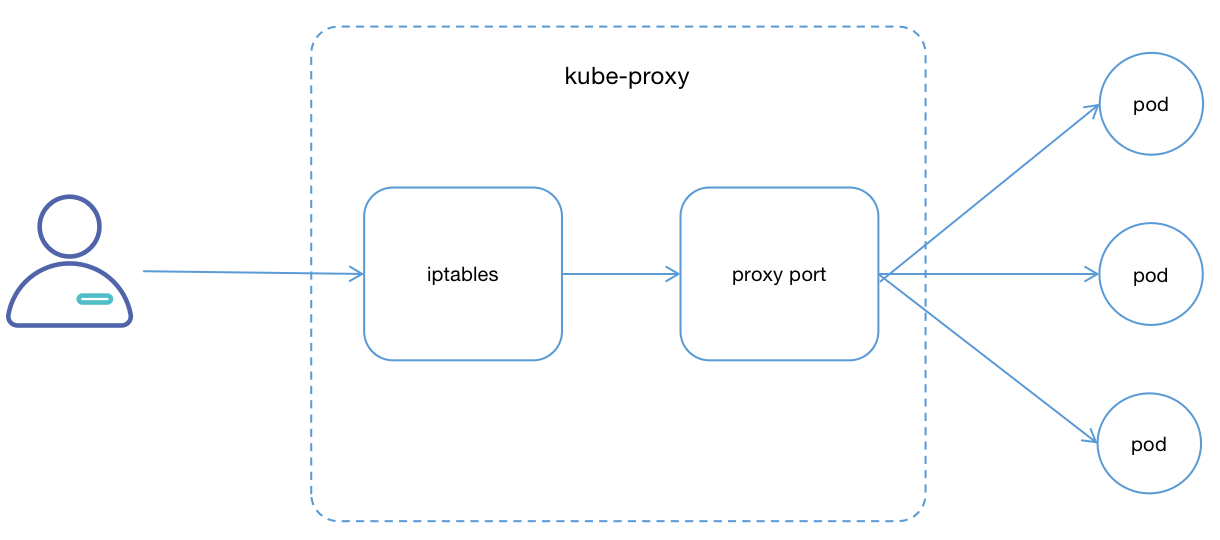
userspace该模式下最大的问题是,Service的请求会先从用户空间进入内核iptables,然后再回到用户空间,最后在由kube-proxy完成后端Endpoints的选择和代理工作,这样需要用户空间和内核态一直来回切换,这样带来的系统开销会很大。
iptables
Kubernetes从1.2版本开始,将iptables作为kube-proxy的默认模式。iptables模式下的kube-proxy不再起到Proxy的作用,其核心功能:通过API Server的Watch接口实时跟踪Service与Endpoint的变更信息,并更新对应的iptables规则,Client的请求流量则通过iptables的NAT机制“直接路由”到目标Pod。
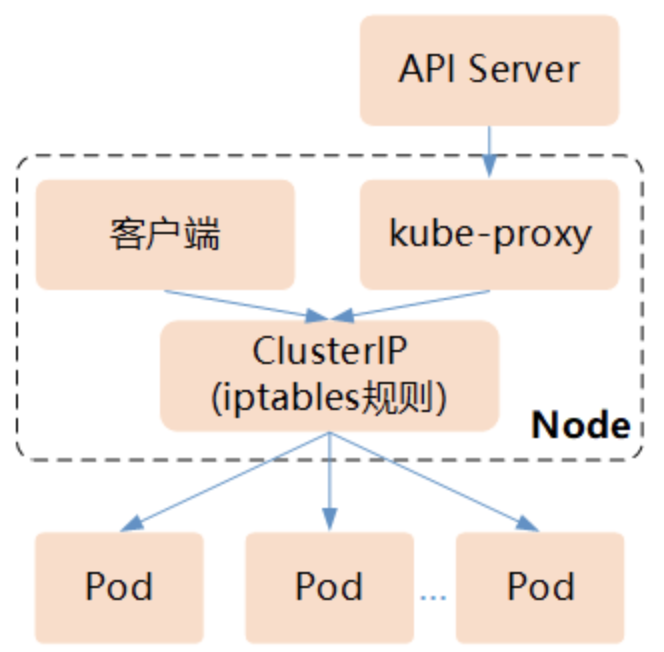
与第1代的userspace模式相比,iptables模式完全工作在内核态,不用再经过用户态的kube-proxy中转,因而性能更强。iptables模式虽然实现起来简单,但存在无法避免的缺陷:在集群中的Service和Pod大量增加以后,iptables中的规则会急速膨胀,导致性能显著下降,在某些极端情况下甚至会出现规则丢失的情况,并且这种故障难以重现与排查。
IPVS
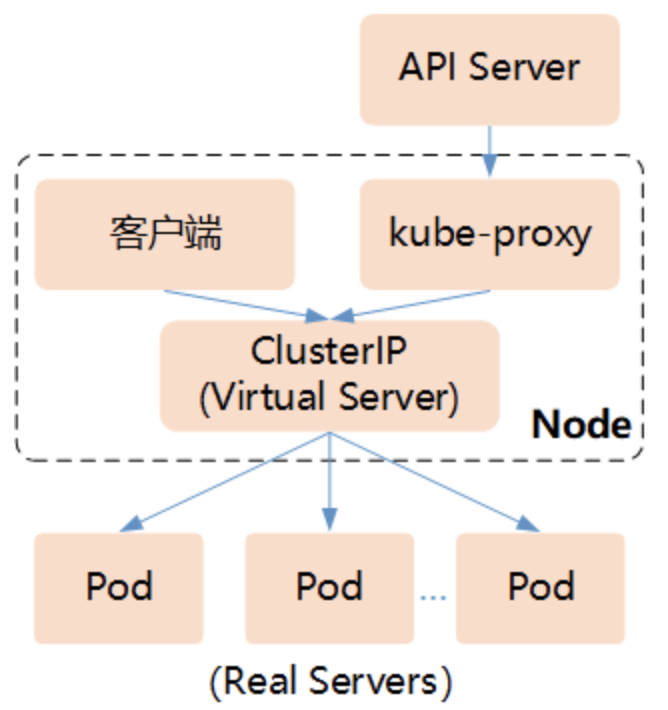
Kubernetes从1.8版本开始引入第3代的IPVS(IPVirtualServer)模式,IPVS在Kubernetes1.11中升级为GA稳定版。iptables与IPVS虽然都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张。由此解决掉了iptables的弊病。
与iptables相比,IPVS拥有以下明显优势:
为大型集群提供了更好的可扩展性和性能;
支持比iptables更复杂的复制均衡算法(最小负载、最少连接、加权等);
支持服务器健康检查和连接重试等功能;
可以动态修改ipset的集合,即使iptables的规则正在使用这个集合;
由于IPVS无法提供包过滤、airpin-masqueradetricks(地址伪装)、SNAT等功能,因此在某些场景(如NodePort的实现)下还要与iptables搭配使用。
在IPVS模式下,kube-proxy又做了重要的升级,即使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹配。
会话保持机制
Service支持通过设置sessionAffinity实现基于客户端的IP的会话保持,首次将某个客户端来源的IP发起请求转发到后端某个Pod上,之后从相同的客户端IP发起的请求都被转发到相同的Pod上,配置参数为spec.sessionAffinity,也可以设置会话保持的最长时间,在此之后重新设置访问规则,通过配置spec.sessionAffinityConfig.clientIP.timeoutSeconds来实现,可以参考以下配置:
Service支持通过设置sessionAffinity实现基于客户端的IP的会话保持,首次将某个客户端来源的IP发起请求转发到后端某个Pod上,之后从相同的客户端IP发起的请求都被转发到相同的Pod上,配置参数为spec.sessionAffinity,也可以设置会话保持的最长时间,在此之后重新设置访问规则,通过配置spec.sessionAffinityConfig.clientIP.timeoutSeconds来实现,可以参考以下配置:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
sessionAffinity: ClientIP
sessionAffinityConfig:
clientIP:
timeoutSeconds: 1000
#定义后端pod标签为app=backend
selector:
app: backend
ports:
#service端口号
- port: 80
#pod的端口号
targetPort: 80
Service类型
Service支持的类型也就是Kubernetes 中将服务暴露的方式,默认有四种 ClusterIP、NodePort、LoadBalancer、ExternelName,下面会详细介绍每种类型Service的使用场景。
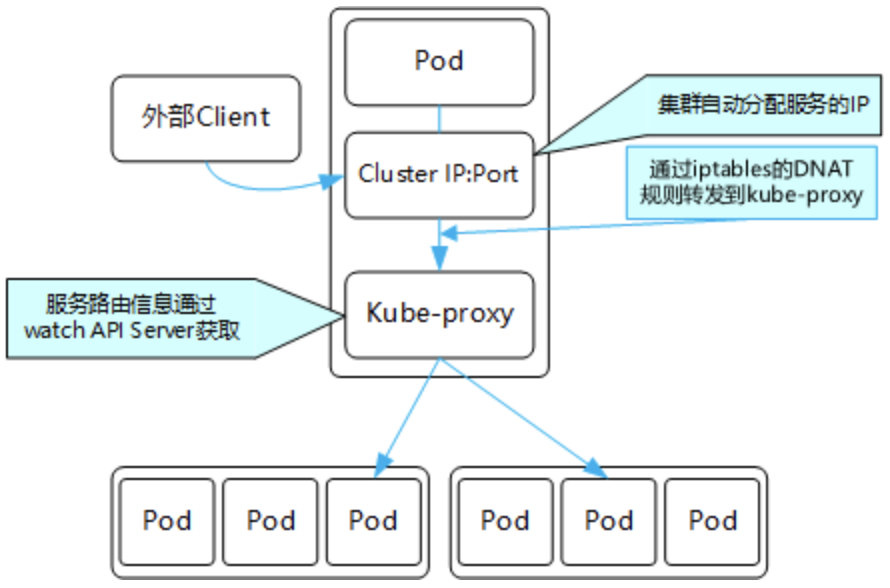
ClusterIP
ClusterIP类型的Service是Kubernetes集群默认的服务暴露方式,它只能用于集群内部通信,可以被各 Pod 访问,也可以手动指定ClusterIP,不过要确保该IP在Kubernetes集群设置ClusterIP的范围内部,并且没有被其他Service使用,整个访问流程如下:
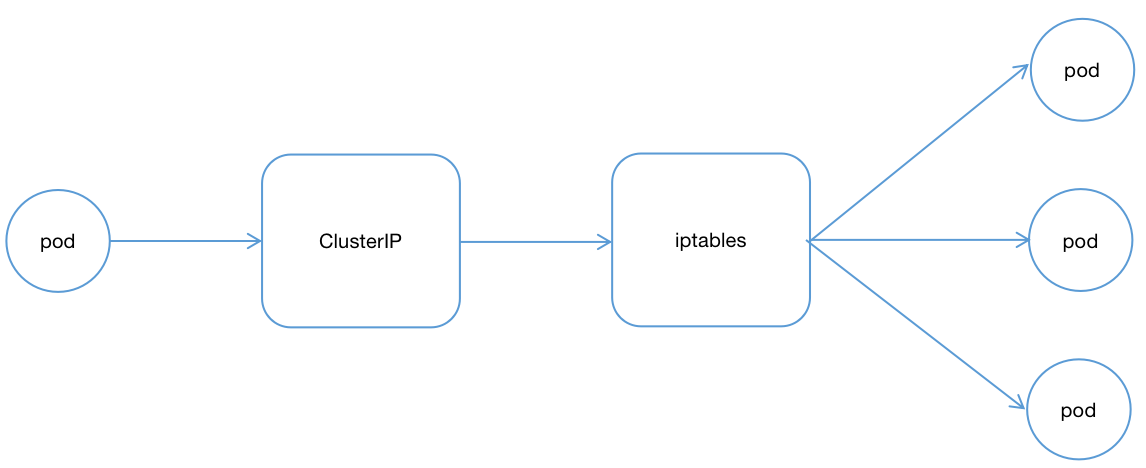
集群内部整体结构可参考以下模型:
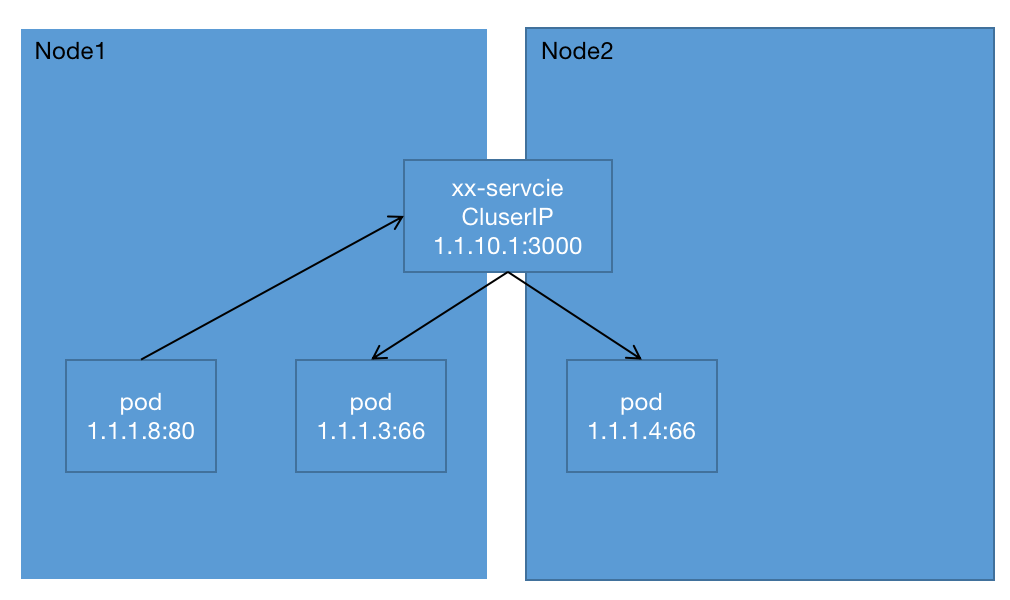
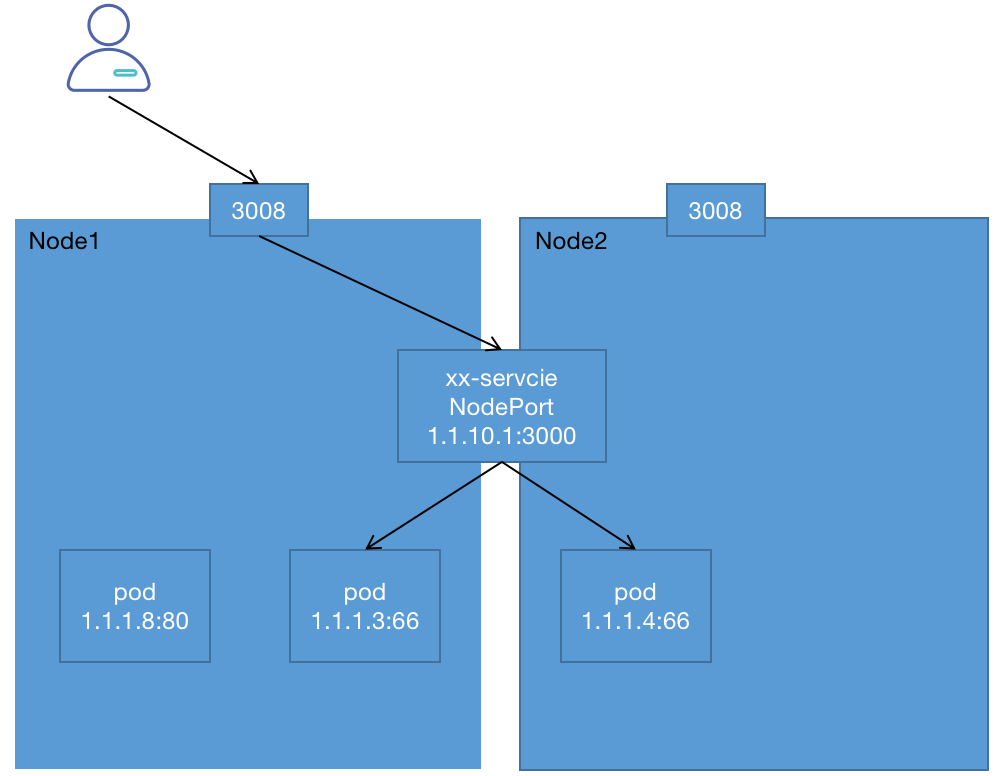
NodePort
对于我们来说,不全是集群内访问,也需要集群外业务访问。那么ClusterIP就满足不了了。NodePort是一种对外提供访问的方式,NodePort类型的Service可以让Kubemetes集群每个节点上保留一个相同的端口,外部访问连接首先访问节点IP:Port,然后将这些连接转发给服务对应的Pod。整体的访问流程:
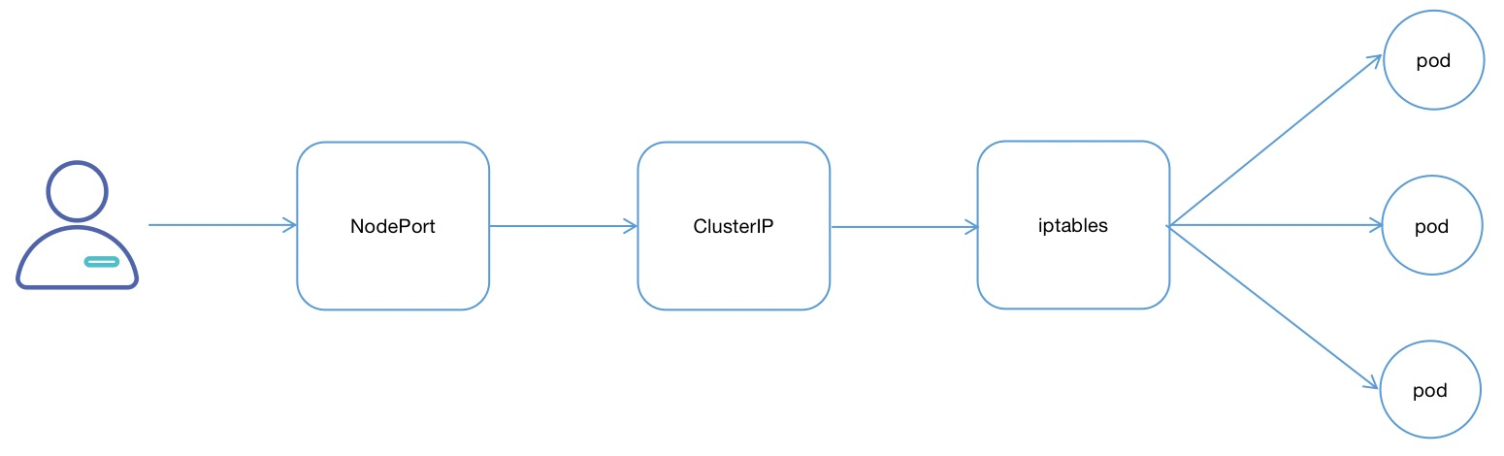
集群内部整体结构可参考以下模型:
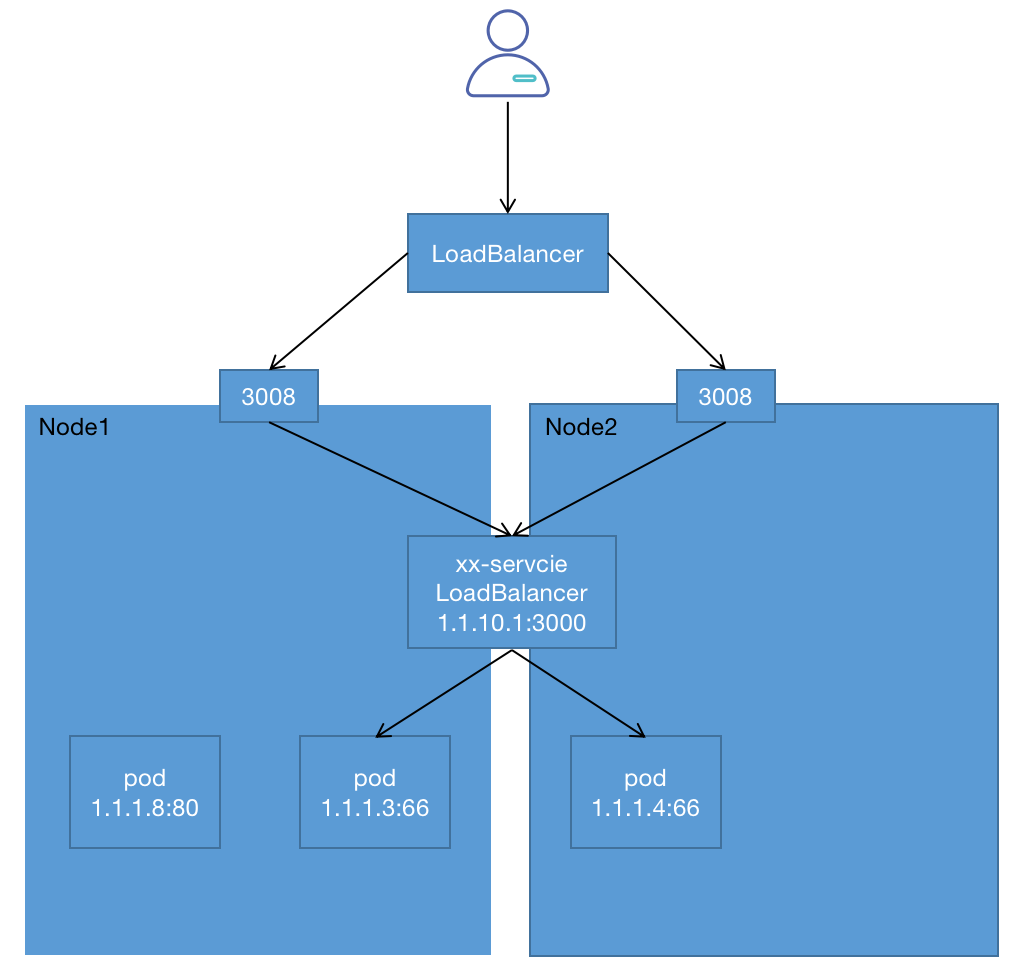
LoadBalancer
LoadBalancer类型的Service其实是NodePort类型Service的扩展,通过一个特定的LoadBalancer访问Service,这个LoadBalancer将请求转发到节点的NodePort,可以理解为端口的Nginx负载均衡器。
LoadBalancer本身不是属于Kubernetes的组件,这部分通常是由具体厂商(云服务提供商)提供,不同厂商的Kubernetes集群与LoadBalancer的对接实现各不相同,被提供的负载均衡器的信息将会通过Service的status.loadBalancer字段被发布出去。
整体结构可参考以下模型:
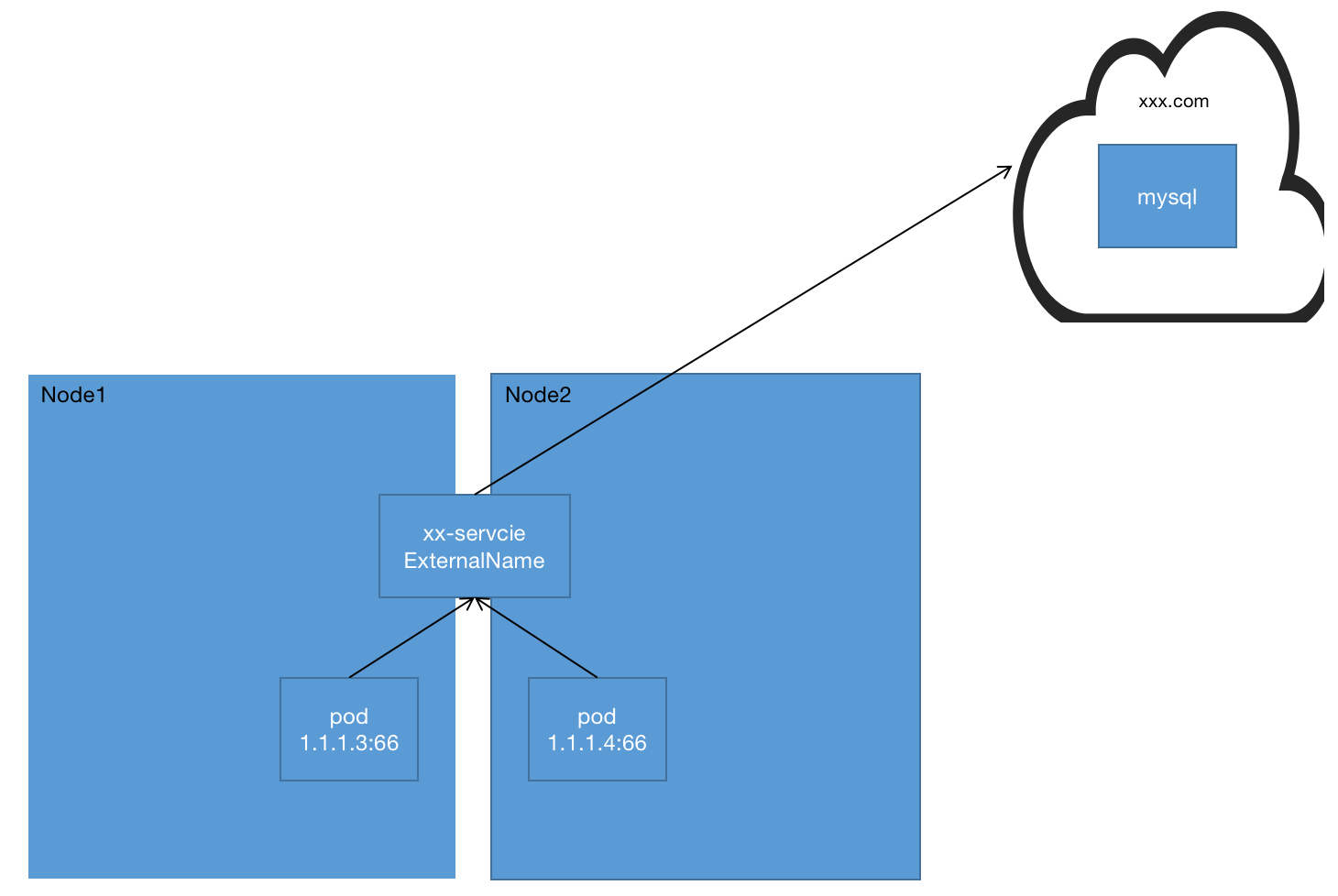
ExternalName
ExternalName类型的服务用于将集群外的服务定义为Kubernetes集群的Service,并且通过externalName字段指定外部服务的地址,可以是域名也可以是IP格式。集群内部的客户端可以通过这个Service访问外部服务,这种类型的服务没有后端Pod,因此也不需要设置Label Selector。
整体结构可参考以下模型:
结束
欢迎大家点点关注,点点赞!
