为什么进程间需要通信
- 数据传输
- 资源共享
- 通知事件
- 进程控制
进程间通信的原理
每一个进程都有不同的用户地址空间,任何一个进程的全局变量在另外一个进程都看不到,所以进程之间要交换数据必须通过内核,在内核中开辟一块缓冲区,进程1把数据从用户空间拷贝到内核缓冲区,进程2再冲内核缓冲区吧数据读走,内核提供这种机制成为进程间的通信机制。
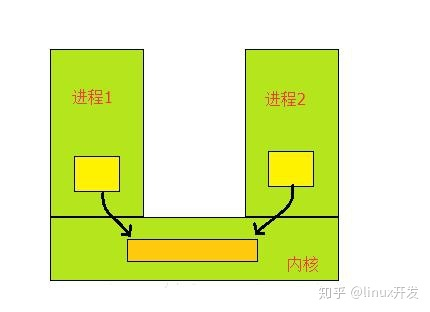
进程间通信的几种方式
管道又名匿名管道,这是一种最基本的IPC,由pipe 函数创建
#include <unistd.h>
int pipe(int pipefd[2]);
返回值:成功返回0,失败返回-1;
调用pipe 函数相当于在内核中开辟一块缓冲区用于通信,它有一个读端,一个写端:pipefd[0] 指向管道的读端,pipefd[1]指向管道的写端,所以管道在用户程序看起来像一个文件,通过read(pipefd[1])向这个文件读取数据,或者write(pipefd[1]) 向这个文件读写数据,其实是在读写内核缓冲区
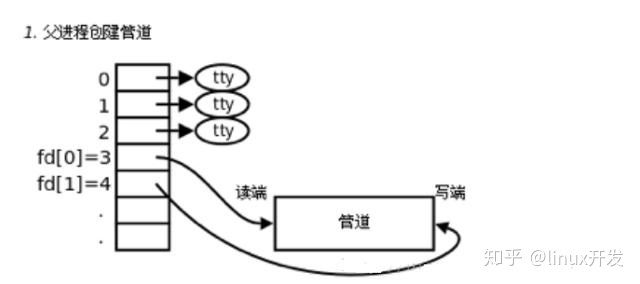
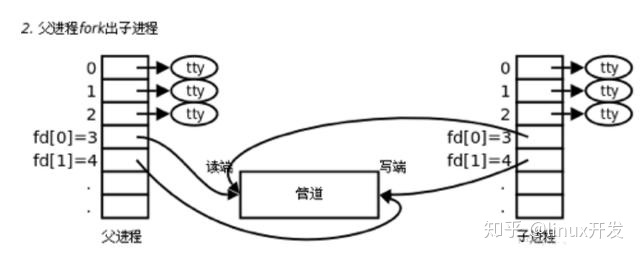
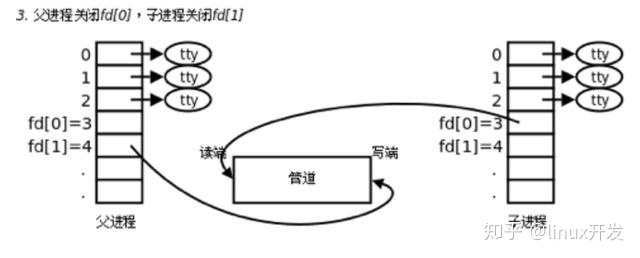
1.父进程调用pipe开辟管道,得到两个文件描述符指向管道的两端。
2.父进程调用fork创建子进程,那么子进程也有两个文件描述符指向同一管道。
3.父进程关闭管道读端,子进程关闭管道写端。父进程可以往管道里写,子进程可以从管道里读,管道是用环形队列实现的,数据从写端流入从读端流出,这样就实现了进程间通信。
使用管道的缺点
1、两个进程通过一个管道智能实现单向通信,如果想双向通信必须重新创建一个管道或者使用sockpair 才可以解决这类问题;
2、只能用于具有亲缘关系的进程间通信,比如父子兄弟进程。
一个关于管道的例子,代码如下:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main()
{
int _pipe[2]={0,0};
int ret=pipe(_pipe); //创建管道
if(ret == -1) {
perror("create pipe error");
return 1;
}
printf("_pipe[0] is %d,_pipe[1] is %d
",_pipe[0],_pipe[1]);
pid_t id=fork(); //父进程fork子进程
if(id < 0)
{
perror("fork error");
return 2;
}
else if(id == 0) //child,写
{
printf("child writing
");
close(_pipe[0]);
int count=5;
const char *msg="i am from XATU";
while(count--)
{
write(_pipe[1],msg,strlen(msg));
sleep(1);
}
close(_pipe[1]);
exit(1);
}
else //father,读
{
printf("father reading
");
close(_pipe[1]);
char msg[1024];
int count=5;
while(count--)
{
ssize_t s = read(_pipe[0],msg,sizeof(msg)-1);
if(s > 0){
msg[s]='�';
printf("client# %s
",msg);
}
else
{
perror("read error");
exit(1);
}
}
if (waitpid(id,0,NULL) != -1) {
printf("wait success
");
}
}
return 0;
}
命名管道(FIFO)
FIFO 不同于管道之处在于它提供一个路径名与之关联,以FIFO的文件形式存储于文件系统中,命名管道是一个设备文件,因此即使进程与创建FIFO的进程不存在亲缘关系,只要可以访问该路径就能够通过FIFO相互通信。
命名管道的创建和读写:
1)是在程序中使用系统函数建立命名管道;
2)是在Shell下交互的建立一个命名管道,Shell方式下可使用mknod 或 mkfifo命令创建管道
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int mknod(const char *pathname, mode_t mode, dev_t dev);
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
命名管道的特点:
1、命名管道是一个存在于硬盘上的文件,而管道是存在于内存中的特殊文件,所以使用命名管道必须先open 先将其打开
2、命名挂到可以用于两个任意进程的通信,不管整俩进程是不是父子进程也不管这两个进程之间有没有关系
server.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
void testserver()
{
int namepipe=mkfifo("myfifo",S_IFIFO|0666); //创建一个存取权限为0666的命名管道
if(namepipe == -1){
perror("mkfifo error");
exit(1);
}
int fd=open("./myfifo",O_RDWR); //打开该命名管道
if(fd == -1){
perror("open error");
exit(2);
}
char buf[1024];
while(1)
{
printf("sendto# ");
fflush(stdout);
ssize_t s = read(0,buf,sizeof(buf)-1); //从标准输入获取消息
if(s > 0){
buf[s-1]='�'; //过滤掉从标准输入中获取的换行
if(write(fd,buf,s) == -1){ //把该消息写入到命名管道中
perror("write error");
exit(3);
}
}
}
close(fd);
}
int main()
{
testserver();
return 0;
}
client.c
#include<stdio.h>
#include<stdlib.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
void testclient()
{
int fd=open("./myfifo",O_RDWR);
if(fd == -1){
perror("open error");
exit(1);
}
char buf[1024];
while(1){
ssize_t s=read(fd,buf,sizeof(buf)-1);
if(s > 0){
printf("client# %s
",buf);
}
else{ //读失败或者是读取到字符结尾
perror("read error");
exit(2);
}
}
close(fd);
}
int main()
{
testclient();
return 0;
}
消息队列
信号量
信号量本质是一种数据操作锁,用来负责数据操作过程中的互斥,同步等功能。
信号量用来管理邻接资源,它本身知识一种外部资源的标识,不具有数据交换功能,而是通过控制其他的通信资源实现进程间的通信,可以这样理解,信号量就相当于一个计数器,当进程对他所管理的资源进行请求时,进程先要读取信号量的数值,大于0,资源可以请求,等于0,资源不可以用,这时进程会进入睡眠状态直至资源可用。
当一个进程不再使用资源时,信号量++(对应的操作为V操作),反之当有进程使用资源时候,信号量-1,(对应操作为P操作),对信号量的值的操作均为原子操作
为什么要使用信号量
为了防止出现多个程序同时访问一个共享资源而引发的一些列问题,我们需要一种方法,它可以通过生成并使用令牌来授权,在任意时刻,智能有一个执行线程访问代码的临界区域。
什么是临界区,什么是临界资源?
临界资源:一次只允许一个进程使用的资源
临界区:访问临界资源的程序代码片段。
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int semget(key_t key, int nsems, int semflg);
返回值:成功返回信号量集合的semid,失败返回-1。
共享内存(shm)
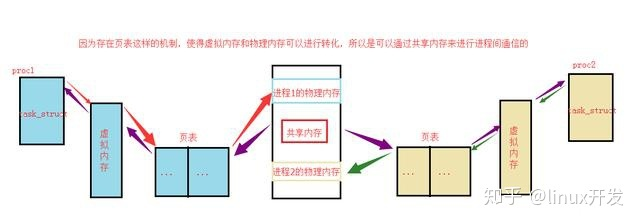
与共享内存有关的函数:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
返回值:成功返回共享内存的id,失败返回-1
size: 表示要申请的内存的大小,一般是4K的整数倍
共享内存的特点
共享内存是这五种通信方式中最高效的,但是因为共享内存没有提供相应的互斥机制,所以一般共享内存一般都和信号量配合使用
为什么共享内存的方式比其他进程间通信的方式效率高
消息队列,FIFO,管道的消息传递方式一般为:
- 服务器获取输入的消息
2)通过管道,消息队列将内存写入内存中,数据通常需要价格数据拷贝到内核中;
3)客户从内核中将树拷贝到自己的客户进程中
4)然后再从进程中拷贝到输出文件
上述过程通常要经过4次拷贝,才能完成文件的传输。
共享内存一般只需要: - 输入内容到共享内存区
2)从共享内存输出到文件
上述过程不涉及到内核的拷贝,这些进程间数据的输出就不再通过执行任何进入内核的系统调用来传输彼此的数据,节省了时间,所以共享内存是这五种进程间通讯方式最高的。