Hadoop是一个能够对大量数据进行分布式处理的软件框架。以一种可靠、高效、可伸缩的方式进行数据处理。主要包括三部分内容:Hdfs,MapReduce,Yarn
hadoop版本
Hadoop2.0即为克服Hadoop1.0中的不足,提出了以下关键特性:
-
Yarn:它是Hadoop2.0引入的一个全新的通用资源管理系统,完全代替了Hadoop1.0中的JobTracker。在MRv1 中的 JobTracker 资源管理和作业跟踪的功能被抽象为 ResourceManager 和 AppMaster 两个组件。Yarn 还支持多种应用程序和框架,提供统一的资源调度和管理功能
-
NameNode 单点故障得以解决:Hadoop2.2.0 同时解决了 NameNode 单点故障问题和内存受限问题,并提供 NFS,QJM 和 Zookeeper 三种可选的共享存储系统
-
HDFS 快照:指 HDFS(或子系统)在某一时刻的只读镜像,该只读镜像对于防止数据误删、丢失等是非常重要的。例如,管理员可定时为重要文件或目录做快照,当发生了数据误删或者丢失的现象时,管理员可以将这个数据快照作为恢复数据的依据
-
支持Windows 操作系统:Hadoop 2.2.0 版本的一个重大改进就是开始支持 Windows 操作系统
-
Append:新版本的 Hadoop 引入了对文件的追加操作
同时,新版本的Hadoop对于HDFS做了两个非常重要的「增强」,分别是支持异构的存储层次和通过数据节点为存储在HDFS中的数据提供内存缓冲功能
相比于Hadoop2.0,Hadoop3.0 是直接基于 JDK1.8 发布的一个新版本,同时,Hadoop3.0引入了一些重要的功能和特性
-
HDFS可擦除编码:这项技术使HDFS在不降低可靠性的前提下节省了很大一部分存储空间
-
多NameNode支持:在Hadoop3.0中,新增了对多NameNode的支持。当然,处于Active状态的NameNode实例必须只有一个。也就是说,从Hadoop3.0开始,在同一个集群中,支持一个 ActiveNameNode 和 多个 StandbyNameNode 的部署方式。
-
MR Native Task优化
-
Yarn基于cgroup 的内存和磁盘 I/O 隔离
-
Yarn container resizing
Hadoop常用的端口号
dfs.namenode.http-address:50070 dfs.datanode.http-address:50075 SecondaryNameNode:50090 dfs.datanode.address:50010 fs.defaultFS:8020 或者9000 yarn.resourcemanager.webapp.address:8088 历史服务器web访问端口:19888
搭建Hadoop集群的流程
HDFS读写流程
-
HDFS读数据流程
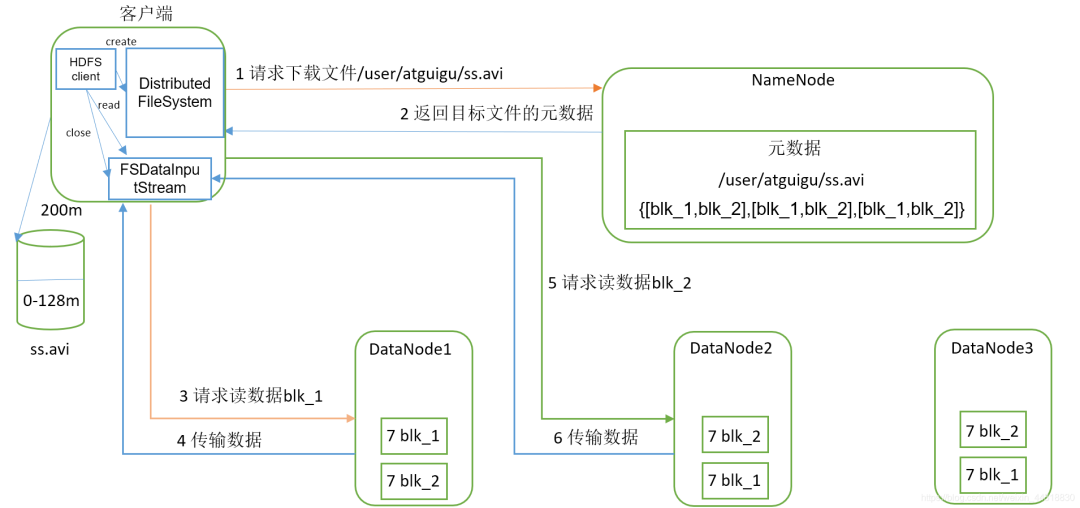
-
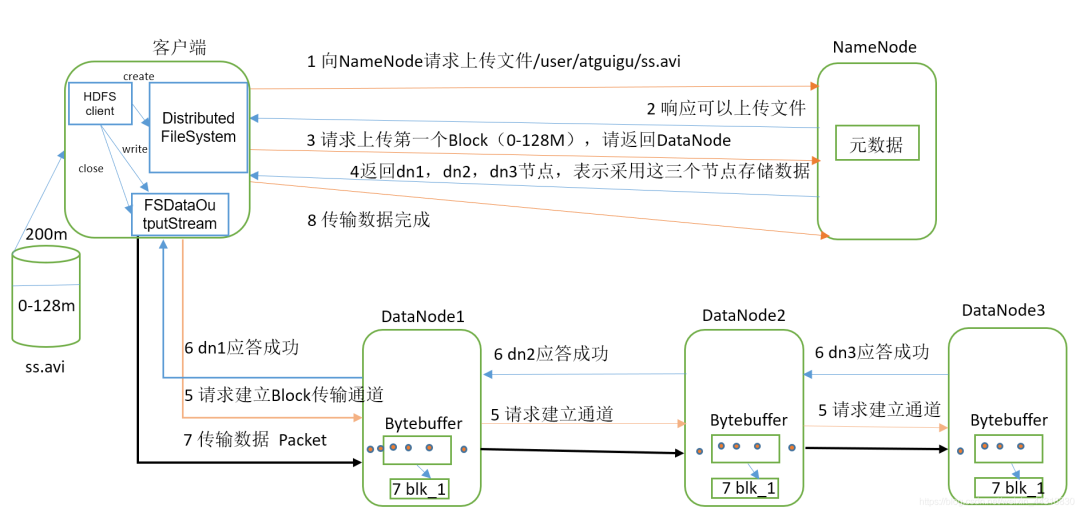
HDFS写数据流程
MapReduce的Shuffle过程
MapReduce数据读取并写入HDFS流程实际上是有10步
 其中最重要,也是最不好讲的就是 shuffle 阶段,当面试官着重要求你介绍 Shuffle 阶段时,可就不能像上边图上写的那样简单去介绍了。
其中最重要,也是最不好讲的就是 shuffle 阶段,当面试官着重要求你介绍 Shuffle 阶段时,可就不能像上边图上写的那样简单去介绍了。
你可以这么说:
-
Map方法之后Reduce方法之前这段处理过程叫「Shuffle」
-
Map方法之后,数据首先进入到分区方法,把数据标记好分区,然后把数据发送到环形缓冲区;环形缓冲区默认大小100m,环形缓冲区达到80%时,进行溢写;溢写前对数据进行排序,排序按照对key的索引进行字典顺序排序,排序的手段「快排」;溢写产生大量溢写文件,需要对溢写文件进行「归并排序」;对溢写的文件也可以进行Combiner操作,前提是汇总操作,求平均值不行。最后将文件按照分区存储到磁盘,等待Reduce端拉取。
3)每个Reduce拉取Map端对应分区的数据。拉取数据后先存储到内存中,内存不够了,再存储到磁盘。拉取完所有数据后,采用归并排序将内存和磁盘中的数据都进行排序。在进入Reduce方法前,可以对数据进行分组操作。
Hadoop优化的方案(包括:压缩、小文件、集群的优化)
1)HDFS小文件影响
-
影响NameNode的寿命,因为文件元数据存储在NameNode的内存中
-
影响计算引擎的任务数量,比如每个小的文件都会生成一个Map任务
2)数据输入小文件处理
-
合并小文件:对小文件进行归档(Har)、自定义Inputformat将小文件存储成SequenceFile文件。
-
采用ConbinFileInputFormat来作为输入,解决输入端大量小文件场景
-
对于大量小文件Job,可以开启JVM重用
3)Map阶段
-
增大环形缓冲区大小。由100m扩大到200m
-
增大环形缓冲区溢写的比例。由80%扩大到90%
-
减少对溢写文件的merge次数。(10个文件,一次20个merge)
-
不影响实际业务的前提下,采用Combiner提前合并,减少 I/O
4)Reduce阶段
-
合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
-
设置Map、Reduce共存:调整
slowstart.completedmaps参数,使Map运行到一定程度后,Reduce也开始运行,减少Reduce的等待时间 -
规避使用Reduce,因为Reduce在用于连接数据集的时候将会产生大量的网络消耗。
-
增加每个Reduce去Map中拿数据的并行数
-
集群性能可以的前提下,增大Reduce端存储数据内存的大小
5) IO 传输
-
采用数据压缩的方式,减少网络IO的的时间
-
使用SequenceFile二进制文件
6) 整体
-
MapTask默认内存大小为1G,可以增加MapTask内存大小为4
-
ReduceTask默认内存大小为1G,可以增加ReduceTask内存大小为4-5g
-
可以增加MapTask的cpu核数,增加ReduceTask的CPU核数
-
增加每个Container的CPU核数和内存大小
-
调整每个Map Task和Reduce Task最大重试次数
7) 压缩
压缩,可以参考这张图
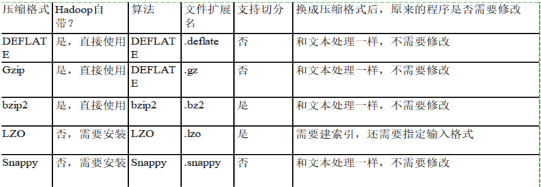 「提示」:如果面试过程问起,我们一般回答压缩方式为Snappy,特点速度快,缺点无法切分(可以回答在链式MR中,Reduce端输出使用bzip2压缩,以便后续的map任务对数据进行split)
「提示」:如果面试过程问起,我们一般回答压缩方式为Snappy,特点速度快,缺点无法切分(可以回答在链式MR中,Reduce端输出使用bzip2压缩,以便后续的map任务对数据进行split)
介绍一下 Yarn 的 Job 提交流程
这里一共也有两个版本,分别是详细版和简略版,具体使用哪个还是分不同的场合。正常情况下,将简略版的回答清楚了就很OK,详细版的最多做个内容的补充:
-
详细版
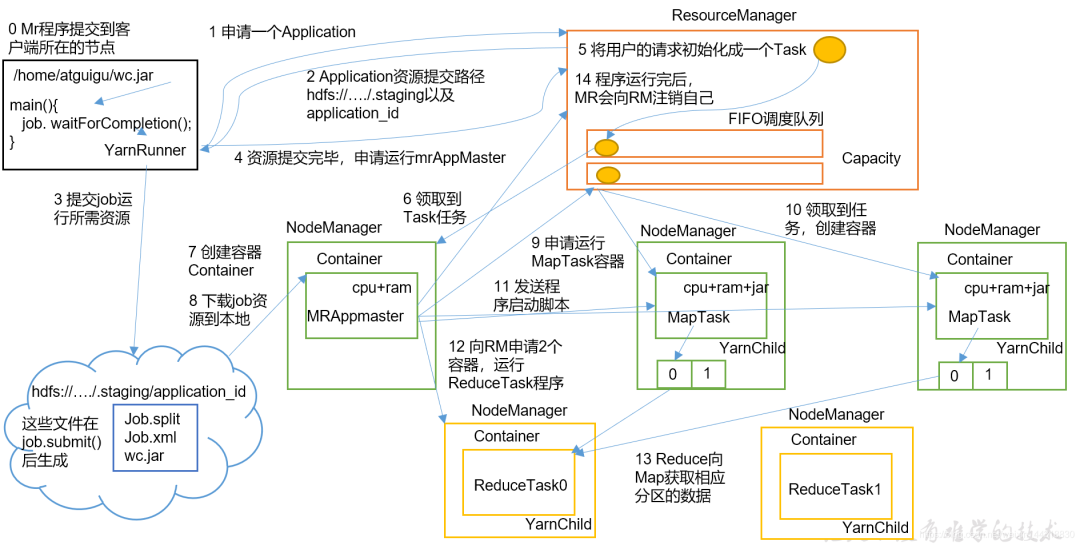
-
简略版
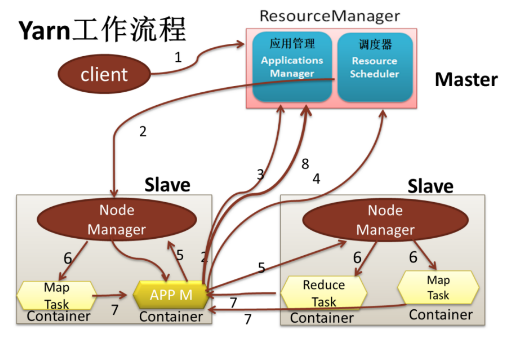 其中简略版对应的步骤分别如下:
其中简略版对应的步骤分别如下:
-
client向RM提交应用程序,其中包括启动该应用的ApplicationMaster的必须信息,例如ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等
-
ResourceManager启动一个container用于运行ApplicationMaster
-
启动中的ApplicationMaster向ResourceManager注册自己,启动成功后与RM保持心跳
-
ApplicationMaster向ResourceManager发送请求,申请相应数目的container
-
申请成功的container,由ApplicationMaster进行初始化。container的启动信息初始化后,AM与对应的NodeManager通信,要求NM启动container
-
NM启动container
-
container运行期间,ApplicationMaster对container进行监控。container通过RPC协议向对应的AM汇报自己的进度和状态等信息
-
应用运行结束后,ApplicationMaster向ResourceManager注销自己,并允许属于它的container被收回
Yarn默认的调度器,调度器分类,以及它们之间的区别
以下回答做个参考:
1)Hadoop调度器主要分为三类:
-
FIFO Scheduler:先进先出调度器:优先提交的,优先执行,后面提交的等待【生产环境不会使用】
-
Capacity Scheduler:容量调度器:允许看创建多个任务对列,多个任务对列可以同时执行。但是一个队列内部还是先进先出。【Hadoop2.7.2默认的调度器】
-
Fair Scheduler:公平调度器:第一个程序在启动时可以占用其他队列的资源(100%占用),当其他队列有任务提交时,占用资源的队列需要将资源还给该任务。还资源的时候,效率比较慢。【CDH版本的yarn调度器默认】
Hadoop的参数优化
我们常见的「Hadoop参数调优」有以下几种:
-
在hdfs-site.xml文件中配置多目录,最好提前配置好,否则更改目录需要重新启动集群
-
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作
dfs.namenode.handler.count=20 * log2(Cluster Size)
处理Hadoop宕机
如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存量,默认是8192MB)。
如果写入文件过量造成NameNode宕机。那么调高Kafka的存储大小,控制从Kafka到HDFS的写入速度。高峰期的时候用Kafka进行缓存,高峰期过去数据同步会自动跟上。
Hadoop数据倾斜的问题的
家可以借鉴下:
1)提前在map进行combine,减少传输的数据量
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key 大量分布在不同的mapper的时候,这种方法就不是很有效了
2)数据倾斜的key 大量分布在不同的mapper
在这种情况,大致有如下几种方法:
-
「局部聚合加全局聚合」
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer 中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
「思想」:二次mr,第一次将key随机散列到不同 reducer 进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差
JobConf.setNumReduceTasks(int)
-
「实现自定义分区」