问题发现
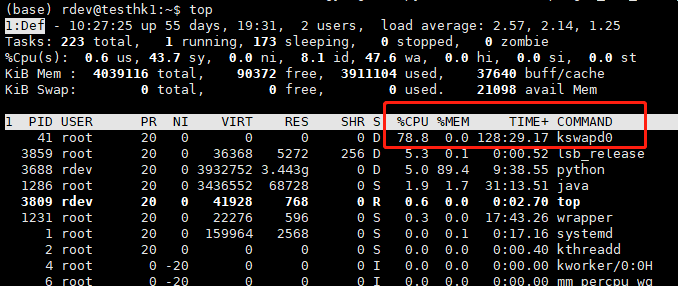
操作系统都用分页机制来管理物理内存,操作系统将磁盘的一部分划出来作为虚拟内存,由于内存的速度要比磁盘快得多,所以操作系统要按照某种换页机制将不需要的页面换到磁盘中,将需要的页面调到内存中,由于内存持续不足,这个换页动作持续进行,kswapd0是虚拟内存管理中负责换页的,当服务器内存不足的时候kswapd0会执行换页操作,这个换页操作是十分消耗主机CPU资源的。如果通过top发现该进程持续处于非睡眠状态,且运行时间较长,可以初步判定系统在持续的进行换页操作,可以将问题转向内存不足的原因来排查。
问题描述:kswapd0 进程占用了系统大量 CPU 资源。
处理办法:Linux 系统通过分页机制管理内存的同时,将磁盘的一部分划出来作为虚拟内存。而 kswapd0 是 Linux 系统虚拟内存管理中负责换页的进程。当系统内存不足时,kswapd0 会频繁的进行换页操作。而由于换页操作非常消耗 CPU 资源,所以会导致该进程持续占用较高 CPU 资源。如果通过 top 等监控发现 kswapd0 进程持续处于非睡眠状态,且运行时间较长并持续占用较高 CPU 资源,则通常是由于系统在持续的进行换页操作所致。则可以通过 free 、ps 等指令进一步查询系统及系统内进程的内存占用情况,做进一步排查分析。
kswapd0是什么
Linux uses kswapd for virtual memory management such that pages that have been recently accessed are kept in memory and less active pages are paged out to disk. (what is a page?)…Linux uses manages memory in units called pages. So,the kswapd process regularly decreases the ages of unreferenced pages…and at the end they are paged out(moved out) to disk
kswapd0进程的作用:
它是虚拟内存管理中,负责换页的,操作系统每过一定时间就会唤醒kswapd ,看看内存是否紧张,如果不紧张,则睡眠。
在 kswapd 中,有2 个阀值,pages_hige 和 pages_low,当空闲内存页的数量低于 pages_low 的时候,kswapd进程就会扫描内存并且每次释放出32 个free pages,直到 free page 的数量到达pages_high。
kswapd0 占用过高是因为 物理内存不足,使用swap分区与内存换页操作交换数据,导致CPU占用过高。
可以通过修改 /etc/sys/vm/swappiness 里面的数值来修改swap分区使用与否,默认 60,数值越大表示更多的使用swap分区
- swap 分区和内存 都有缓存区,缓存的内容为之前使用过的数据,用于加快第二次打开时访问速度。
- swap分区 可以使用多个交换区(使用多硬盘?) 来加快swap访问速度
- swap 分区使用的为硬盘的内容,速度比直接访问内存慢几千倍

物理内存和虚拟内存
内存的读写性能要比硬盘快的多,因此,在设计上会充分利用内存进行数据的读取和写入,提高性能,但是内存是有限的,这就引入了物理内存和虚拟内存的概念。
物理内存指通过物理内存条而获得的内存空间,称为RAM。
虚拟内存的概念,是为了满足物理内存不足的情况下,利用磁盘空间虚拟出的一块逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(swap space)。
就是指将硬盘的一块区域划分来作为内存。内存主要作用是在计算机运行时为操作系统和各种程序提供临时储存。当物理内存不足时,可以用虚拟内存代替。
vm.swappiness是Linux内核的一个参数,范围是0~100。它表示实际内存和虚拟内存区域进行数据交换的倾向性大小,数值越大表示倾向性越大,即交换的页面文件越多,反之亦然。一般默认值为60。可用'cat /proc/sys/vm/swappiness’查看。
Linux会在物理内存不足的时,使用交换分区的虚拟内存,也就是说,内核会将暂时不用的内存块信息写到交换空间,以释放物理内存。
Linux的内存管理采取的是分页存取机制,为了保证物理内存能得到充分的利用,内核会在适当的时候将物理内存中不经常使用的数据块自动交换到虚拟内存中,而将经常使用的信息保留到物理内存。swap si/so 交换区的换进换出。
所有的进程都需要内存,但是不是每个进程都需要一直将对象加载到内存中。基于这点,kernel通过将进程的部分或全部内存换出到磁盘上,来释放物理内存,直到需要再次使用,然后再次读到内存中。
kernel采用分页和交换进行内存管理。其中:
- si:将分页被重新读取到物理内存。也称作page-in
- so:将内存的要交换的分页写到磁盘上。也称作page-out
Buffer与Cache
buffer 和 cache都是通过使用物理内存的一部分.
A buffer is something that has yet to be "written" to disk. A cache is something that has been "read" from the disk and stored for later use
但是我们平常对系统资源进行监控时看到的buffer cache,其实都是cache,其中,buffer是buffer cache,cache是page cache,例如free命令中展示的结果:

Mem是物理内存统计,如上面显示的,total表示物理内存总量是8006M,used表示总计分配给缓存(包括buffers和cached的)使用的数量,但其中可能部分缓存并未实际使用。
used使用的内存有7253M,free未被分配的内存为752M,共享内存shared 一般系统不会用到,总是0。
Buffer是系统分配但未被使用的buffer数量有183M,cache是系统分配但未被使用的cache数量有5153M,关系:total(8006M) = used(7253M) + free(752M),除去buffer和cache,真正使用的内存即-/+ buffers/cache中显示的used的值,也就是1934M。
即下面的关系:
(-buffers/cache) used内存数:1934M (指的第一部Mem行中的used–buffers– cached)
(+buffers/cache) free内存数: 6071M (指的第一部分Mem行中的free + buffers + cached) 所以-buffers/cache反映的是被程序实实在在吃掉的内存,而+buffers/cache反映的是可以挪用的内存总数。
Linux2.4.10之前的内核中,分两种disk cache, 分别为buffer cache和page cache。
但在2.4.10后的内核,buffer cache已经不存在了(或者说换了一种数据存放的方法) 而这种页面的叫法也变了,叫做 buffer page, 而buffer page放在什么地主呢? 它放在page cache中。
总结: 2.4.10之后的内核的disk cache 只有 page cache, 而page cache中有些页面被叫做buffer page的,是因为这些页面(buffer page)都有与其相关的buffer_head 描述符,也正是这样页面被free 统计为 buffer 占用。
如果没有buffer_head与该页相关,则被free统计为 cache占用。

Swap配置对性能的影响
分配太多的Swap空间会浪费磁盘空间,而Swap空间太少,则系统会发生错误。如果系统的物理内存用光了,系统就会跑得很慢,但仍能运行;
如果Swap空间用光了,那么系统就会发生错误。例如,Web服务器能根据不同的请求数量衍生出多个服务进程(或线程),如果Swap空间用完,则服务进程无法启动,通常会出现“application is out of memory”的错误,严重时会造成服务进程的死锁。因此Swap空间的分配是很重要的。
通常情况下,Swap空间应大于或等于物理内存的大小,最小不应小于64M,通常Swap空间的大小应是物理内存的2-2.5倍。
但根据不同的应用,应有不同的配置:如果是小的桌面系统,则只需要较小的Swap空间,而大的服务器系统则视情况不同需要不同大小的Swap空间。特别是数据库服务器和Web服务器,随着访问量的增加,对Swap空间的要求也会增加,一般来说对于4G 以下的物理内存,配置2倍的swap,4G 以上配置1倍。
另外,Swap分区的数量对性能也有很大的影响。
因为Swap交换的操作是磁盘IO的操作,如果有多个Swap交换区,Swap空间的分配会以轮流的方式操作于所有的Swap,这样会大大均衡IO的负载,加快Swap交换的速度。
如果只有一个交换区,所有的交换操作会使交换区变得很忙,使系统大多数时间处于等待状态,效率很低。用性能监视工具就会发现,此时的CPU并不很忙,而系统却慢。这说明,瓶颈在IO上,依靠提高CPU的速度是解决不了问题的。
解决方案(存疑)
/proc是一个虚拟文件系统,我们可以通过对它的读写操作做为与kernel实体间进行通信的一种手段。也就是说可以通过修改/proc中的文件,来对当前kernel的行为做出调整。那么我们可以通过调整/proc/sys/vm/drop_caches来释放内存。操作如下:
cat1 /proc/sys/vm/drop_caches 0
#drop_caches的值可以是0-3之间的数字,代表不同的含义: #0:不释放(系统默认值) #1:释放页缓存 #2:释放dentries和inodes #3:释放所有缓存
手动执行命令
sync
输入手动释放内存的命令
echo 1 > /proc/sys/vm/drop_caches
释放完内存后改回去让系统重新自动分配内存
echo 0 >/proc/sys/vm/drop_caches
原理:
在Linux系统下,我们一般不需要去释放内存,因为系统已经将内存管理的很好。
但是凡事也有例外,有的时候内存会被缓存占用掉,导致系统使用SWAP空间影响性能,例如当你在linux下频繁存取文件后,物理内存会很快被用光,当程序结束后,内存不会被正常释放,而是一直作为caching。
此时就需要执行释放内存(清理缓存)的操作了。
Linux系统的缓存机制是相当先进的,他会针对dentry(用于VFS,加速文件路径名到inode的转换)、Buffer Cache(针对磁盘块的读写)和Page Cache(针对文件inode的读写)进行缓存操作。
但是在进行了大量文件操作之后,缓存会把内存资源基本用光。但实际上我们文件操作已经完成,这部分缓存已经用不到了。
这个时候,我们难道只能眼睁睁的看着缓存把内存空间占据掉吗?
所以,我们还是有必要来手动进行Linux下释放内存的操作,其实也就是释放缓存的操作了。
/proc是一个虚拟文件系统,我们可以通过对它的读写操作做为与kernel实体间进行通信的一种手段.
也就是说可以通过修改/proc中的文件,来对当前kernel的行为做出调整.那么我们可以通过调整/proc/sys/vm/drop_caches来释放内存。
要达到释放缓存的目的,我们首先需要了解下关键的配置文件/proc/sys/vm/drop_caches。这个文件中记录了缓存释放的参数,默认值为0,也就是不释放缓存。
一般复制了文件后,可用内存会变少,都被cached占用了,这是linux为了提高文件读取效率的做法:
为了提高磁盘存取效率, Linux做了一些精心的设计, 除了对dentry进行缓存(用于VFS,加速文件路径名到inode的转换), 还采取了两种主要Cache方式:Buffer Cache和Page Cache。前者针对磁盘块的读写,后者针对文件inode的读写。
这些Cache有效缩短了I/O系统调用(比如read,write,getdents)的时间。
释放内存前先使用sync命令做同步,以确保文件系统的完整性,将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-node、已延迟的块 I/O 和读写映射文件;否则在释放缓存的过程中,可能会丢失未保存的文件。