上次去深圳招行面试。被问到了这个。中间讨论了几个关于贝叶斯的问题。可能我并不偏向知识图谱。然后就没有下文了。
结合李航的《统计学》和几篇博客,还有在凤凰网某位仁兄贡献新闻分类的源码。给自己复习一下。
为什么叫朴素贝叶斯和大学课本里的贝叶斯有什么不同?
朴素一词来源于==>假设各特征之间相互独立。这一假设使得朴素贝叶斯算法变得简单,但有时会牺牲一定的分类准确率。
招行的那位小姐姐有先验。说的就是这个。
大学里面的贝叶斯

算法使用的朴素贝叶斯(怎么我感觉叫条件特征独立贝叶斯更好呢):
条件独立假设:

就是说分类特征在类确定的条件下都是独立的。
朴素贝叶斯分类时,对于给定输出的x,通过学习得到的模型计算后验概率分布p(Y=ck|X=x),将后验概率最大的类作为x的类输出,后验概率计算根据贝叶斯定理进行:
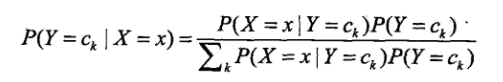
把特征独立条件带入上面公式:
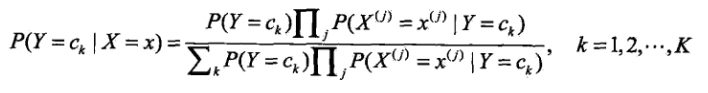
所以贝叶斯分类器可以表示为:

因为分母对于所有的K都是相同的,公式可以简化为
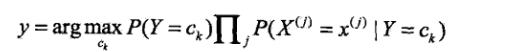
朴素贝叶斯法的参数估计
学习就意味着估计,使用极大似然估计法估计相应的概率。

先验概率的极大似然估计是

条件概率的极大似然估计是
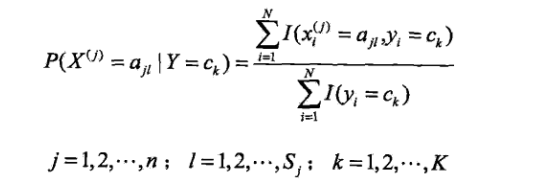
朴素贝叶斯的优缺点
优点:
(1) 算法逻辑简单,易于实现(算法思路很简单,只要使用贝叶斯公式转化即可!)
(2)分类过程中时空开销小(假设特征相互独立,只会涉及到二维存储)
缺点:
朴素贝叶斯假设属性之间相互独立,这种假设在实际过程中往往是不成立的。在属性之间相关性越大,分类误差也就越大。
朴素贝叶斯实战
sklearn中有3种不同类型的朴素贝叶斯:
高斯分布型:用于classification问题,假定属性/特征服从正态分布的。
多项式型:用于离散值模型里。比如文本分类问题里面我们提到过,我们不光看词语是否在文本中出现,也得看出现次数。如果总词数为n,出现词数为m的话,有点像掷骰子n次出现m次这个词的场景。
伯努利型:最后得到的特征只有0(没出现)和1(出现过)。
莺尾花Demo
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import cross_val_score from sklearn import datasets iris = datasets.load_iris() gnb = GaussianNB() scores=cross_val_score(gnb, iris.data, iris.target, cv=10) print(scores)
[ 0.93333333 0.93333333 1. 0.93333333 0.93333333 0.93333333 0.86666667 1. 1. 1. ]
kaggle比赛中旧金山犯罪
1.数据观察
import pandas as pd import numpy as np from sklearn import preprocessing from sklearn.metrics import log_loss from sklearn.cross_validation import train_test_split train = pd.read_csv('train.csv', parse_dates = ['Dates']) test = pd.read_csv('test.csv', parse_dates = ['Dates'])
train
特征为
Date: 日期
Category: 犯罪类型,比如 Larceny/盗窃罪 等.
Descript: 对于犯罪更详细的描述
DayOfWeek: 星期几
PdDistrict: 所属警区
Resolution: 处理结果『逮捕』『逃了』
Address: 发生街区位置
X and Y: GPS坐标
2.特征处理
sklearn.preprocessing模块中的 LabelEncoder函数可以对类别做编号,我们用它对犯罪类型做编号;
pandas中的get_dummies( )可以将变量进行二值化01向量,我们用它对”街区“、”星期几“、”时间点“进行因子化。
#对犯罪类别:Category; 用LabelEncoder进行编号 leCrime = preprocessing.LabelEncoder() crime = leCrime.fit_transform(train.Category) #39种犯罪类型 #用get_dummies因子化星期几、街区、小时等特征 days=pd.get_dummies(train.DayOfWeek) district = pd.get_dummies(train.PdDistrict) hour = train.Dates.dt.hour hour = pd.get_dummies(hour) #组合特征 trainData = pd.concat([hour, days, district], axis = 1) #将特征进行横向组合 trainData['crime'] = crime #追加'crime'列 days = pd.get_dummies(test.DayOfWeek) district = pd.get_dummies(test.PdDistrict) hour = test.Dates.dt.hour hour = pd.get_dummies(hour) testData = pd.concat([hour, days, district], axis=1) trainData
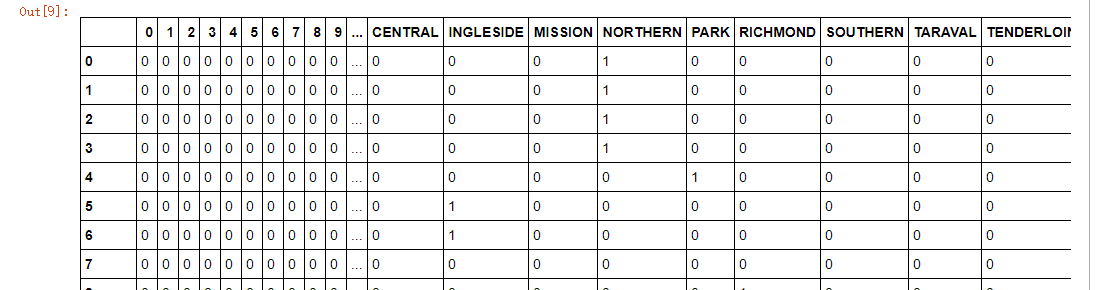
3.建立贝叶斯模型
from sklearn.naive_bayes import BernoulliNB import time features=['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday', 'BAYVIEW', 'CENTRAL', 'INGLESIDE', 'MISSION', 'NORTHERN', 'PARK', 'RICHMOND', 'SOUTHERN', 'TARAVAL', 'TENDERLOIN'] X_train, X_test, y_train, y_test = train_test_split(trainData[features], trainData['crime'], train_size=0.6) NB = BernoulliNB() nbStart = time.time() NB.fit(X_train, y_train) nbCostTime = time.time() - nbStart print(X_test.shape) propa = NB.predict_proba(X_test) #X_test为263415*17; 那么该行就是将263415分到39种犯罪类型中,每个样本被分到每一种的概率 print("朴素贝叶斯建模%.2f秒"%(nbCostTime)) predicted = np.array(propa) logLoss=log_loss(y_test, predicted) print("朴素贝叶斯的log损失为:%.6f"%logLoss)
输出:
(351220, 17) 朴素贝叶斯建模0.87秒 朴素贝叶斯的log损失为:2.615733
凤凰新闻的文章


package com.ifeng.classify.Util; import java.io.Serializable; import java.util.HashMap; import java.util.HashSet; import java.util.List; import java.util.Map; import java.util.Set; public class NativeBayes implements Serializable { /** * 序列化ID */ private static final long serialVersionUID = -5809782578272943999L; /** * 默认频率 */ private double defaultFreq = 0.1; /** * 训练数据的比例 */ private Double trainingPercent = 0.8; private Map<String, List<String>> files_all = new HashMap<String, List<String>>(); private Map<String, List<String>> files_train = new HashMap<String, List<String>>(); private Map<String, List<String>> files_test = new HashMap<String, List<String>>(); public NativeBayes() { } /** * 每个分类的频数 */ private Map<String, Integer> classFreq = new HashMap<String, Integer>(); /** * 每个分类所占的百分比 先验概率 p(yi) */ private Map<String, Double> ClassProb = new HashMap<String, Double>(); /** * 特征总数 */ private Set<String> WordDict = new HashSet<String>(); /** * 每个分类中每个特征的频数 */ private Map<String, Map<String, Integer>> classFeaFreq = new HashMap<String, Map<String, Integer>>(); /** * 每个分类中每个特征的概率 p(xi/yi) */ private Map<String, Map<String, Double>> ClassFeaProb = new HashMap<String, Map<String, Double>>(); /** * 每个分类默认的概率 */ private Map<String, Double> ClassDefaultProb = new HashMap<String, Double>(); public double getDefaultFreq() { return defaultFreq; } public void setDefaultFreq(double defaultFreq) { this.defaultFreq = defaultFreq; } public Double getTrainingPercent() { return trainingPercent; } public void setTrainingPercent(Double trainingPercent) { this.trainingPercent = trainingPercent; } public Map<String, List<String>> getFiles_all() { return files_all; } public void setFiles_all(Map<String, List<String>> files_all) { this.files_all = files_all; } public Map<String, List<String>> getFiles_train() { return files_train; } public void setFiles_train(Map<String, List<String>> files_train) { this.files_train = files_train; } public Map<String, List<String>> getFiles_test() { return files_test; } public void setFiles_test(Map<String, List<String>> files_test) { this.files_test = files_test; } public Map<String, Integer> getClassFreq() { return classFreq; } public void setClassFreq(Map<String, Integer> classFreq) { this.classFreq = classFreq; } public Map<String, Double> getClassProb() { return ClassProb; } public void setClassProb(Map<String, Double> classProb) { ClassProb = classProb; } public Set<String> getWordDict() { return WordDict; } public void setWordDict(Set<String> wordDict) { WordDict = wordDict; } public Map<String, Map<String, Integer>> getClassFeaFreq() { return classFeaFreq; } public void setClassFeaFreq(Map<String, Map<String, Integer>> classFeaFreq) { this.classFeaFreq = classFeaFreq; } public Map<String, Map<String, Double>> getClassFeaProb() { return ClassFeaProb; } public void setClassFeaProb(Map<String, Map<String, Double>> classFeaProb) { ClassFeaProb = classFeaProb; } public Map<String, Double> getClassDefaultProb() { return ClassDefaultProb; } public void setClassDefaultProb(Map<String, Double> classDefaultProb) { ClassDefaultProb = classDefaultProb; } }
package com.ifeng.classify.trainModel; import com.ifeng.classify.Util.NativeBayes; import java.io.File; import java.io.FileNotFoundException; import java.util.*; import java.util.Map.Entry; import java.util.regex.Matcher; import java.util.regex.Pattern; public class TrainModel { private static String dataDir = "E:/data/data"; /** * 将数据分为训练数据和测试数据 * * @param */ public static void splitData(NativeBayes nativeBayes) { // 用文件名区分类别 File f = new File(dataDir); File[] files = f.listFiles(); assert files != null; for (File file : files) { String fname = file.getName().replaceAll(".txt", ""); ArrayList<String> list = new ArrayList<String>(); Scanner scanner = null; try { scanner = new Scanner(file); while(scanner.hasNext()){ String line = scanner.nextLine().trim(); list.add(line); } } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } if (nativeBayes.getFiles_all().containsKey(fname)) { nativeBayes.getFiles_all().get(fname).addAll(list); } else { nativeBayes.getFiles_all().put(fname, list); } } System.out.println("统计数据:"); for (Entry<String, List<String>> entry : nativeBayes.getFiles_all().entrySet()) { String cname = entry.getKey(); List<String> value = entry.getValue(); // System.out.println(cname + " : " + value.size()); // 训练集 List<String> train = new ArrayList<String>(); // 测试集 List<String> test = new ArrayList<String>(); for (String str : value) { if (Math.random() <= nativeBayes.getTrainingPercent()) {// 80%用来训练 , 20%测试 train.add(str); } else { test.add(str); } } nativeBayes.getFiles_train().put(cname, train); nativeBayes.getFiles_test().put(cname, test); } System.out.println("所有文件数:"); printStatistics(nativeBayes.getFiles_all()); System.out.println("训练文件数:"); printStatistics(nativeBayes.getFiles_train()); System.out.println("测试文件数:"); printStatistics(nativeBayes.getFiles_test()); } /** * 将数据分为训练数据和测试数据 * * @param dataDir */ public static void splitDataTwo(NativeBayes nativeBayes, String dataDir) { // 用文件名区分类别 Pattern pat = Pattern.compile("\d+([a-z]+?)\."); dataDir = "testdata/allfiles"; File f = new File(dataDir); File[] files = f.listFiles(); assert files != null; for (File file : files) { String fname = file.getName(); Matcher m = pat.matcher(fname); if (m.find()) { String cname = m.group(1); if (nativeBayes.getFiles_all().containsKey(cname)) { nativeBayes.getFiles_all().get(cname).add(file.toString()); } else { List<String> tmp = new ArrayList<String>(); tmp.add(file.toString()); nativeBayes.getFiles_all().put(cname, tmp); } } else { System.out.println("err: " + file); } } System.out.println("统计数据:"); for (Entry<String, List<String>> entry : nativeBayes.getFiles_all().entrySet()) { String cname = entry.getKey(); List<String> value = entry.getValue(); // System.out.println(cname + " : " + value.size()); List<String> train = new ArrayList<String>(); List<String> test = new ArrayList<String>(); for (String str : value) { if (Math.random() <= nativeBayes.getTrainingPercent()) {// 80%用来训练 , 20%测试 train.add(str); } else { test.add(str); } } nativeBayes.getFiles_train().put(cname, train); nativeBayes.getFiles_test().put(cname, test); } System.out.println("所有文件数:"); printStatistics(nativeBayes.getFiles_all()); System.out.println("训练文件数:"); printStatistics(nativeBayes.getFiles_train()); System.out.println("测试文件数:"); printStatistics(nativeBayes.getFiles_test()); } /** * 加载训练数据 */ public static void loadTrainData(NativeBayes nativeBayes){ for (Entry<String, List<String>> entry : nativeBayes.getFiles_train().entrySet()) { //{体育:[11,,22,33]} String classname = entry.getKey(); List<String> docs = entry.getValue(); nativeBayes.getClassFreq().put(classname, docs.size()); Map<String, Integer> feaFreq = new HashMap<String, Integer>(); nativeBayes.getClassFeaFreq().put(classname, feaFreq); //ClassFeaFreq 每个分类中每个特征的频数 for (String doc : docs) { String[] words = doc.split(" "); // String[] words = null; for (String word : words) { nativeBayes.getWordDict().add(word); if(feaFreq.containsKey(word)){ int num = feaFreq.get(word) + 1; feaFreq.put(word, num); }else{ feaFreq.put(word, 1); } } } } System.out.println(nativeBayes.getClassFreq().size()+" 分类, " + nativeBayes.getWordDict().size()+" 特征词"); } /** * 模型训练 */ public static void createModel(NativeBayes nativeBayes) { double sum = 0.0; //每个分类的频数相加 for (Entry<String, Integer> entry : (nativeBayes.getClassFreq().entrySet())) { sum+=entry.getValue(); } //每个分类的频率 for (Entry<String, Integer> entry : nativeBayes.getClassFreq().entrySet()) { nativeBayes.getClassProb().put(entry.getKey(), entry.getValue()/sum); } //循环类--->Map<String, Map<String, Integer>> ClassFeaFreq for (Entry<String, Map<String, Integer>> entry : nativeBayes.getClassFeaFreq().entrySet()) { //sum是一个类下所有的特征总和数 sum = 0.0; // String classname = entry.getKey(); //循环一个类下的所有 特征map for (Entry<String, Integer> entry_1 : entry.getValue().entrySet()){ sum += entry_1.getValue(); } //不做平滑处理 double newsum = sum ; // 用于做平滑处理,防止分母为零 // double newsum = sum + nativeBayes.getWordDict().size()*nativeBayes.getDefaultFreq(); // 在训练集中每个分类中每个特征词出现的概率值 p(xi/yi) Map<String, Double> feaProb = new HashMap<String, Double>(); nativeBayes.getClassFeaProb().put(classname, feaProb); for (Entry<String, Integer> entry_1 : entry.getValue().entrySet()){ String word = entry_1.getKey(); //不做平滑处理 feaProb.put(word, entry_1.getValue()/newsum); //做平滑处理 // feaProb.put(word, (entry_1.getValue() + nativeBayes.getDefaultFreq()) /newsum); } nativeBayes.getClassDefaultProb().put(classname, nativeBayes.getDefaultFreq()/newsum); } } /** * 打印统计信息 * * @param m */ public static void printStatistics(Map<String, List<String>> m) { for (Entry<String, List<String>> entry : m.entrySet()) { String cname = entry.getKey(); List<String> value = entry.getValue(); System.out.println(cname + " : " + value.size()); } System.out.println("--------------------------------"); } }
package com.ifeng.classify.trainModel; import com.ifeng.classify.Util.NativeBayes; import java.io.*; public class NBModel { private static String path = "E:/data/NB.model.bin"; /** * MethodName: SerializePerson * Description: 序列化Person对象 * @author * @throws FileNotFoundException * @throws IOException */ public static void SerializeNativeBayes(NativeBayes nativeBayes){ // ObjectOutputStream 对象输出流,将Person对象存储到E盘的Person.txt文件中,完成对Person对象的序列化操作 ObjectOutputStream oo = null; try { oo = new ObjectOutputStream(new FileOutputStream( new File(path))); oo.writeObject(nativeBayes); System.out.println("NativeBayes对象序列化成功!"); oo.close(); } catch (FileNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } /** * MethodName: DeserializePerson * Description: 反序列Perons对象 * @author * @return * @throws Exception * @throws IOException */ public static NativeBayes DeserializeNativeBayes(){ ObjectInputStream ois = null; NativeBayes nativeBayes = null; try{ ois = new ObjectInputStream(new FileInputStream( new File(path))); nativeBayes = (NativeBayes) ois.readObject(); System.out.println("NativeBayes对象反序列化成功!"); }catch(Exception e){ e.printStackTrace(); } return nativeBayes; } }
package com.ifeng.classify.evaluate; import java.util.List; public class CheckUp { /** * 计算准确率 * @param reallist 真实类别 * @param pridlist 预测类别 */ public static void Evaluate(List<String> reallist, List<String> pridlist){ double correctNum = 0.0; for (int i = 0; i < reallist.size(); i++) { if(reallist.get(i).equals(pridlist.get(i))){ correctNum += 1; } } double accuracy = correctNum / reallist.size(); System.out.println("准确率为:" + accuracy); } /** * 计算精确率和召回率 * @param reallist * @param pridlist * @param classname */ public static void CalPreRec(List<String> reallist, List<String> pridlist, String classname){ double correctNum = 0.0; double allNum = 0.0;//测试数据中,某个分类的文章总数 double preNum = 0.0;//测试数据中,预测为该分类的文章总数 for (int i = 0; i < reallist.size(); i++) { if(reallist.get(i).equals(classname)){ allNum += 1; if(reallist.get(i).equals(pridlist.get(i))){ correctNum += 1; } } if(pridlist.get(i).equals(classname)){ preNum += 1; } } System.out.println(classname + " 精确率(跟预测分类比较):" + correctNum / preNum + " 召回率(跟真实分类比较):" + correctNum / allNum); } }
package com.ifeng.classify.evaluate; import com.ifeng.classify.Util.NativeBayes; import com.ifeng.classify.trainModel.TrainModel; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.Map.Entry; public class predict { /** * 用模型进行预测 * 用于训练测试样本 */ public static void PredictTestData(NativeBayes nativeBayes) { List<String> reallist=new ArrayList<String>(); List<String> pridlist=new ArrayList<String>(); for (Entry<String, List<String>> entry : nativeBayes.getFiles_test().entrySet()) { String realclassname = entry.getKey(); List<String> files = entry.getValue(); for (String file : files) { reallist.add(realclassname); List<String> classnamelist=new ArrayList<String>(); List<Double> scorelist=new ArrayList<Double>(); for (Entry<String, Double> entry_1 : nativeBayes.getClassProb().entrySet()) { String classname = entry_1.getKey(); //先验概率 Double score = Math.log(entry_1.getValue()); String[] words = file.split(" "); // String[] words = null; for (String word : words) { //在全集则计算该Word权重 if(!nativeBayes.getWordDict().contains(word)){ continue; } if(nativeBayes.getClassFeaProb().get(classname).containsKey(word)){ score += Math.log(nativeBayes.getClassFeaProb().get(classname).get(word)); }else{ score += Math.log(nativeBayes.getClassDefaultProb().get(classname)); } } classnamelist.add(classname); scorelist.add(score); } Double maxProb = Collections.max(scorelist); int idx = scorelist.indexOf(maxProb); pridlist.add(classnamelist.get(idx)); } } CheckUp.Evaluate(reallist, pridlist); for (String cname : nativeBayes.getFiles_test().keySet()) { CheckUp.CalPreRec(reallist, pridlist, cname); } } public static void main(String[] args) { NativeBayes bayes = new NativeBayes(); TrainModel.splitData(bayes); TrainModel.loadTrainData(bayes); TrainModel.createModel(bayes); predict.PredictTestData(bayes); // NBModel.SerializeNativeBayes(bayes); // NBModel.DeserializeNativeBayes(); } }
统计数据:
所有文件数:
科技 : 10000
社会 : 10000
娱乐 : 10000
汽车 : 10000
体育 : 10000
教育 : 10000
时政 : 10000
时尚 : 10000
游戏 : 10000
财经 : 10000
--------------------------------
训练文件数:
科技 : 7946
社会 : 8016
娱乐 : 8062
汽车 : 8041
体育 : 7995
教育 : 7962
时政 : 8004
时尚 : 7906
游戏 : 7922
财经 : 7955
--------------------------------
测试文件数:
科技 : 2054
社会 : 1984
娱乐 : 1938
汽车 : 1959
体育 : 2005
教育 : 2038
时政 : 1996
时尚 : 2094
游戏 : 2078
财经 : 2045
--------------------------------
10 分类, 325496 特征词
准确率为:0.9202119756327076
科技 精确率(跟预测分类比较):0.8898305084745762 召回率(跟真实分类比较):0.9201557935735151
社会 精确率(跟预测分类比较):0.8351111111111111 召回率(跟真实分类比较):0.9470766129032258
娱乐 精确率(跟预测分类比较):0.8614547253834736 召回率(跟真实分类比较):0.8983488132094943
汽车 精确率(跟预测分类比较):0.9768177028451 召回率(跟真实分类比较):0.9464012251148545
体育 精确率(跟预测分类比较):0.9811512990320937 召回率(跟真实分类比较):0.9605985037406484
教育 精确率(跟预测分类比较):0.945646703573226 召回率(跟真实分类比较):0.92198233562316
时政 精确率(跟预测分类比较):0.9029850746268657 召回率(跟真实分类比较):0.8486973947895792
时尚 精确率(跟预测分类比较):0.9110588235294118 召回率(跟真实分类比较):0.9245463228271251
游戏 精确率(跟预测分类比较):0.9805970149253731 召回率(跟真实分类比较):0.9485081809432147
财经 精确率(跟预测分类比较):0.9344346928239545 召回率(跟真实分类比较):0.8850855745721271