HDFS HA 集群搭建:
DN(DataNode):3个;NN(NameNode):2;ZK(ZooKeeper):3(大于1的奇数个);ZKFC:和NN在同一台机器;JN:3;RM(ResourceManager):1;DM(DataManager):3个;与DN在同一台,就近原则
√表示在该机器上有该进程。
| NN | DN | ZK | ZKFC | JN | RM | DM | |
| Node1 | √ | √ | √ | √ | |||
| Node2 | √ | √ | √ | √ | √ | √ | |
| Node3 | √ | √ | √ | √ | |||
| Node4 | √ | √ | √ |
1.解压 hadoop-2.5.2.tar.gz
[hadoop@node1 software]$ tar -zxvf hadoop-2.5.2.tar.gz
其中 -zxvf 含义如下:
-z, gzip : 对归档文件使用 gzip 压缩
-x, --extract, --get : 释放归档文件中文件及目录
-v, --verbose : 显示命令整个执行过程
-f, --file=ARCHIVE : 指定 (将要创建或已存在的) 归档文件名
这里注意,我们的环境为CentOS7 64位系统,这里的tar包也需要为64位,可以使用如下方法查看hadoop tar包是32位还是64位:
/hadoop-2.5.2/lib/native [hadoop@node1 native]$ ls libhadoop.a libhadoop.so libhadooputils.a libhdfs.so libhadooppipes.a libhadoop.so.1.0.0 libhdfs.a libhdfs.so.0.0.0
[hadoop@node1 native]$ file libhadoop.so.1.0.0 libhadoop.so.1.0.0: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, BuildID[sha1]=29e15e4c9d9840a7b96b5af3e5732e5935d91847, not stripped
2.进入hadoop解压后的目录修改hadoop-env.sh,主要修改JAVA_HOME
[hadoop@node1 hadoop]$ echo $JAVA_HOME /usr/java/jdk1.7.0_75 [hadoop@node1 hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_75
2. 修改hdfs-site.xml,可以参照官档 http://hadoop.apache.org/docs/r2.5.2/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
<configuration> <!--配置服务名称,名称可以随意--> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!--配置所有NameNode名称,这里名称随意--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!--配置所有NameNode的RPC协议端口--> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1.example.com:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2.example.com:i8020</value> </property> <!--配置Http协议端口和主机--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1.example.com:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2.example.com:50070</value> </property> <!--配置JournalNodes 的地址--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node2:8485;node3:8485;node4:8485/mycluster</value> </property> <!--配置客户端要使用的类,客户端使用这个类找到Active NodeName--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--配置sshfence--> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_dsa</value> </property> <!--配置JournalNodes的工作目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/jn/data</value> </property> <!--开启自动切换,当然手动切换也是可用用的--> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
3.配置core-site.xml
<configuration> <!--配置NameNode入口,这里配置集群名称,不能配置具体的ip--> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!--配置zk,表明zk在哪些机器上有--> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <!--修改hadoop的临时目录,默认目录在系统的tmp目录下--> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop</value> </property> </configuration>
4.配置zk
initLimit=10 syncLimit=5 dataDir=/opt/zookeeper clientPort=2181 server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888
在配置的dataDir目录下创建myid文件,在node1上配置,稍后还要在node2,node3做相应配置
[hadoop@node1 zookeeper]$ cat /opt/zookeeper/myid 1
将node1上的zookeeper目录拷贝的node2,及node3上
[root@node1 opt]# scp -r zookeeper/ root@node2:/opt/ [root@node1 opt]# scp -r zookeeper/ root@node3:/opt/
并在node2及node3上分别修改myid文件,node2修改为2,node3修改为3
将node1上的zk的目录拷贝到node2,node3上
[hadoop@node1 software]$ scp -r zookeeper-3.4.9 hadoop@node2:/home/hadoop/software/ [hadoop@node1 software]$ scp -r zookeeper-3.4.9 hadoop@node3:/home/hadoop/software/
配置3台节点的ZK_HOME的环境变量:
[root@node1 bin]# vim /etc/profile export ZK_HOME=/home/hadoop/software/zookeeper-3.4.9 export PATH=$PATH:$ZK_HOME/bin
关闭防火墙,并在3台机器上分别启动zk
# zkServer.sh start ZooKeeper JMX enabled by default Using config: /home/hadoop/software/zookeeper-3.4.9/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
# jps 2791 Jps 2773 QuorumPeerMain
5.配置slaves
[root@node1 hadoop]# vim slaves
node2
node3
node4
6,将配置好的hadoop目录拷贝到其他节点
[hadoop@node1 hadoop]$ scp * hadoop@node2:/home/hadoop/software/hadoop-2.5.2/etc/hadoop/ [hadoop@node1 hadoop]$ scp * hadoop@node3:/home/hadoop/software/hadoop-2.5.2/etc/hadoop/ [hadoop@node1 hadoop]$ scp * hadoop@node4:/home/hadoop/software/hadoop-2.5.2/etc/hadoop/
7. 启动JournalNode
分别在node2,node3,node4机器上上启动JournalNode
[hadoop@node2 sbin]$ ./hadoop-daemon.sh start journalnode starting journalnode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-journalnode-node2.out [hadoop@node2 sbin]$ jps 2581 JournalNode 2627 Jps 2378 QuorumPeerMain [hadoop@node2 sbin]$
8.在其中一台含有Namenode的机器上进行格式化
[hadoop@node1 bin]$ ./hdfs namenode -format
9.将刚才格式化好的元数据文件拷贝到其他的namenode节点上
9.1 先启动刚才格式化后的Namenode节点(只启动NameNode)
[hadoop@node1 sbin]$ ./hadoop-daemon.sh start namenode
[hadoop@node1 sbin]$ jps 2315 QuorumPeerMain 2790 NameNode 2859 Jps
9.2 再在未格式化的节点上执行以下命令:
[hadoop@node2 bin]$ ./hdfs namenode -bootstrapStandby
检查是否有相应目录生成
10.先停止所有的服务,除了ZK
[hadoop@node1 sbin]$ ./stop-dfs.sh Stopping namenodes on [node1 node2] node2: no namenode to stop node1: stopping namenode node2: no datanode to stop node4: no datanode to stop node3: no datanode to stop Stopping journal nodes [node2 node3 node4] node3: stopping journalnode node2: stopping journalnode node4: stopping journalnode Stopping ZK Failover Controllers on NN hosts [node1 node2] node2: no zkfc to stop node1: no zkfc to stop [hadoop@node1 sbin]$
11.格式化zkfc ,在任意一台有Namenode机器上进行格式化
[hadoop@node1 bin]$ ./hdfs zkfc -formatZK
12.启动hdfs
[hadoop@node1 sbin]$ ./start-dfs.sh Starting namenodes on [node1 node2] node1: starting namenode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-namenode-node1.out node2: starting namenode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-namenode-node2.out node4: starting datanode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-datanode-node4.out node2: starting datanode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-datanode-node2.out node3: starting datanode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-datanode-node3.out Starting journal nodes [node2 node3 node4] node3: starting journalnode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-journalnode-node3.out node2: starting journalnode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-journalnode-node2.out node4: starting journalnode, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-journalnode-node4.out Starting ZK Failover Controllers on NN hosts [node1 node2] node1: starting zkfc, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-zkfc-node1.out node2: starting zkfc, logging to /home/hadoop/software/hadoop-2.5.2/logs/hadoop-hadoop-zkfc-node2.out [hadoop@node1 sbin]$ jps 3662 Jps 2315 QuorumPeerMain 3345 NameNode 3616 DFSZKFailoverController [hadoop@node1 sbin]$
通过jps查看需要的节点是否启动成功
[hadoop@node2 opt]$ jps 3131 JournalNode 3019 DataNode 3217 DFSZKFailoverController 2955 NameNode 3276 Jps 2378 QuorumPeerMain [hadoop@node2 opt]$
[hadoop@node3 opt]$ jps 66237 JournalNode 2340 QuorumPeerMain 66148 DataNode 66294 Jps [hadoop@node3 opt]$
[hadoop@node4 sbin]$ jps 2762 Jps 2618 DataNode 2706 JournalNode [hadoop@node4 sbin]$
13,通过浏览器访问
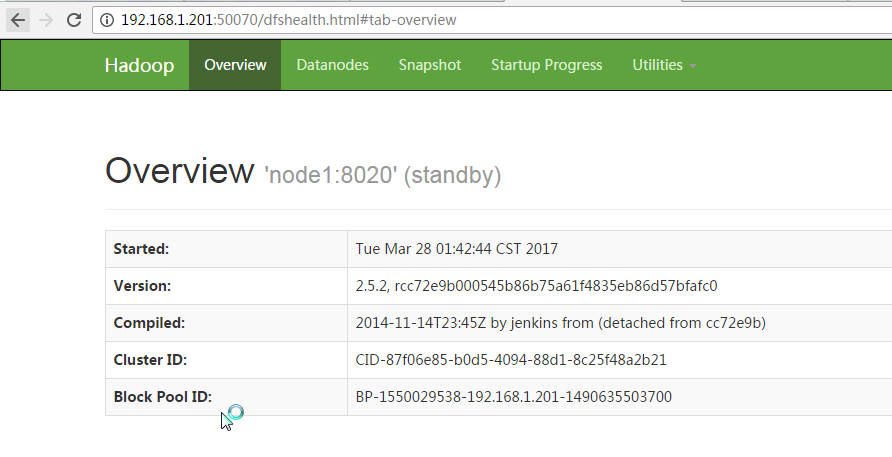

哪个节点为 Standby,哪个为active是通过CPU竞争机制。
测试创建目录和上传文件:
[hadoop@node1 bin]$ ./hdfs dfs -mkdir -p /usr/file [hadoop@node1 bin]$ ./hdfs dfs -put /home/hadoop/software/jdk-7u75-linux-x64.rpm /usr/file/

到此 Hadoop2.x HA 就搭建完成。