1.从CISSP考试看,整个考试涉及8个领域,至少3个领域提出了业务连续性管理,从规划、运营到具体的实现技术及应用,涉及方方面面。业务连续性管理贯穿信息安全知识体系的所有部分,是CIA中可用性的重要保障。
2.从企业的运营看,信息技术作为当前企业生产运营的基础,业务连续性是保障。
业务连续性/应急管理能力(sp800-34)/连续性管理能力会随着企业信息化使用的深度和广度凸显越来越重要。举一个笔者身边的例子。
一个某传统的大型制造国有企业,在信息化刚开开始应用时,大部分人是比较排斥的,尤其一线车间人员。但时间长了,排斥声减小,但这个时候另一个有意思的事情发生了,大家特别盼望着系统不能用,为什么呢?因为系统不能用了,生产就要停产,生产停了,就不用干活了。这个时候企业的管理还很粗狂的,信息化还不能完全支撑企业运营;随着信息化的深入,企业把信息化融入到企业生产经营的各个环节,这个时候无论企业经营计划安排还是员工绩效监控均在信息系统,系统一旦不能用就会直接面临停工停产,员工没有工作量工资会减少,企业停产也承受巨大损失。这个时候假如做好了业务连续性管理,相信会将损失降低到最低。同时,这里也可以得出一个结论,信息化最终要改变人的行为和思想,提升企业的精细化管理程度,而这个过程是不能逾越的,对于不同企业只是时间长短而已。

复原力[7]是指能够迅速适应和从已知或未知的环境变化中恢复的能力。弹性不是一个过程,而是组织的最终状态。弹性组织的目标是在任何类型的中断期间,始终能保持基本的功能可用。有弹性的组织不断努力适应可能影响其继续履行关键职能能力的变化和风险。风险管理、应急和连续性规划是单独的安全和应急管理活动,也可以作为弹性计划的组成部分在整个组织中以整体的方式实施。
An organization must have the ability to withstand all hazards and sustain its mission through environmental changes. These changes can be gradual, such as economic or mission changes, or sudden, as in a disaster event. Rather than just working to identify and mitigate threats, vulnerabilities, and risks, organizations can work toward building a resilient infrastructure, minimizing the impact of any disruption on mission essential functions.
Resilience[7] is the ability to quickly adapt and recover from any known or unknown changes to the environment. Resiliency is not a process, but rather an end-state for organizations. The goal of a resilient organization is to continue mission essential functions at all times during any type of disruption. Resilient organizations continually work to adapt to changes and risks that can affect their ability to continue critical functions. Risk management, contingency, and continuity planning are individual security and emergency management activities that can also be implemented in a holistic manner across an organization as components of a resiliency program.
啰嗦了这么多,到底应急计划和风险管理有哪些关系呢?
风险管理包含了对系统风险进行识别、分析和控制、监控多项活动。按照原文的解释是与应急管理可独立运行也可联合一起运行。笔者的理解,风险管理和应急管理是相辅相成的,风险管理过程必然会影响到应急管理决策,应急管理的决策也会影响到风险管理的控制方法。实际上,当我们在做BIA的时候,其开始就要引用风险分析的结果作为输入。
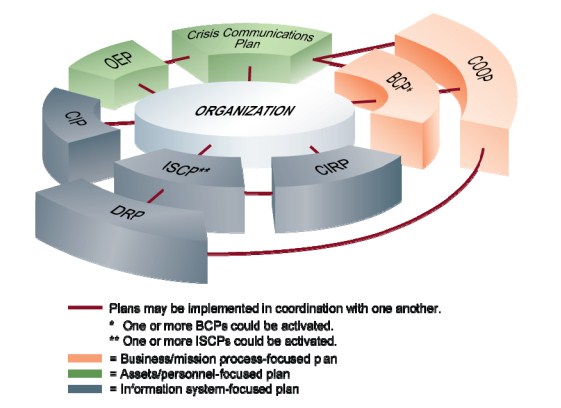
业务连续性计划的重点是在中断期间和中断之后维持组织的任务/业务流程连续性。任务/业务流程的示例可以是组织的工资单流程或客户服务流程。业务连续性计划可以针对单个业务单元内的任务/业务流程编写,也可以针对整个组织的流程。
The BCP focuses on sustaining an organization's mission/business processes during and after a disruption. An example of a mission/business process may be an organization's payroll process or customer service process. A BCP may be written for mission/business processes within a single business unit or may address the entire organization's processes.
一句话总结:中断前进和之后维持组织能运转的计划。
2)运营/操作连续性(COOP)计划
重点是在另一个地点恢复一个组织的基本职能,并在恢复正常运转之前能保障这些只能正常运转30天。其他职能或外地办事处一级的职能可由业务连续性计划处理。
COOP focuses on restoring an organization's mission essential functions (MEF) at an alternate site and performing those functions for up to 30 days before returning to normal operations. Additional functions, or those at a field office level, may be addressed by a BCP. Minor threats or disruptions that do not require relocation to an alternate site are typically not addressed in a COOP plan.
一句话总结:在灾备中心临时性恢复的计划。强调机构在备用站点恢复运行能力,计划不需要包括IT运行。
3)危机沟通计划
组织应使用危机沟通计划记录发生中断时内部和外部沟通的标准程序。危机沟通计划通常由负责公众宣传的组织制定。该计划提供了适合事件的各种通信格式。危机沟通计划通常指定特定个人作为回答公众提出的问题或向公众提供有关应急响应信息的唯一权威。它还可以包括向工作人员分发关于事件状况的报告的程序和公开新闻稿的模板。危机沟通计划程序应传达给组织的COOP和BCP策划人,以确保计划包括明确的指示,即只有经批准的声明才由授权官员向公众发布。
Organizations should document standard procedures for internal and external communications in the event of a disruption using a crisis communications plan. A crisis communications plan is often developed by the organization responsible for public outreach. The plan provides various formats for communications appropriate to the incident. The crisis communications plan typically designates specific individuals as the only authority for answering questions from or providing information to the public regarding emergency response. It may also include procedures for disseminating reports to personnel on the status of the incident and templates for public press releases. The crisis communication plan procedures should be communicated to the organization's COOP and BCP planners to ensure that the plans include clear direction that only approved statements are released to the public by authorized officials.
一句话总结:事件发生后,内部沟通(找谁)和外部沟通(和谁说,媒体应答)
4)关键基础设施保护(CIP)计划
关键基础设施和关键资源(CIKR)是国家基础设施的组成部分。CIP计划是一套政策和程序,用于保护和恢复这些国家资产,减轻风险和脆弱性。
Critical infrastructure and key resources (CIKR) are those components of the national infrastructure that are deemed so vital that their loss would have a debilitating effect of the safety, security, economy, and/or health of the United States.[10] A CIP plan is a set of policies and procedures that serve to protect and recover these national assets and mitigate risks and vulnerabilities.
一句话总结:关系国计民生的设施
5)网络事件响应计划
网络事件响应计划:建立了处理针对组织信息系统的网络攻击的程序。这些程序旨在使安全人员能够识别、减轻和恢复恶意计算机事件,如未经授权访问系统或数据、拒绝服务,或对系统硬件、软件或数据进行未经授权的更改(如恶意逻辑,如病毒、蠕虫或特洛伊木马)。本计划可作为业务连续性计划的附录。
The cyber incident response plan[11] establishes procedures to address cyber attacks against an organization's information system(s).[12] These procedures are designed to enable security personnel to identify, mitigate, and recover from malicious computer incidents, such as unauthorized access to a system or data, denial of service, or unauthorized changes to system hardware, software, or data (e.g., malicious logic, such as a virus, worm, or Trojan horse). This plan may be included as an appendix of the BCP.
一句话总结:针对网络攻击事件,可作为BCP的附录。
6)灾难恢复计划(DRP)
DRP通常适用于重要基础设施因物理损害且在较长时间内无法服务的场景。DRP是聚焦系统层面的规划,用于在紧急情况下恢复目标系统、应用和计算机设备在备用站点达到可用。DRP可面向多种信息系统应急规划,用于指导人们在建设好的备份设施上恢复受影响的各个系统。DRP或许能通过恢复辅助系统的业务过程或者重要任务功能来支持BCP或者COOP计划。DRP仅能通过迁移来解决信息系统的破坏问题。
The DRP applies to major, usually physical disruptions to service that deny access to the primary facility infrastructure for an extended period. A DRP is an information system-focused plan designed to restore operability of the target system, application, or computer facility infrastructure at an alternate site after an emergency. The DRP may be supported by multiple information system contingency plans to address recovery of impacted individual systems once the alternate facility has been established. A DRP may support a BCP or COOP plan by recovering supporting systems for mission/business processes or mission essential functions at an alternate location. The DRP only addresses information system disruptions that require relocation.
一句话总结:在备用设施临时性的恢复紧急的、重要的系统。
7)信息系统应急计划(ISCP)
ISCP与DRP的主要区别在于,信息系统应急计划程序是为恢复系统而制定的,而不考虑具体位置。ISCP可以在系统的当前位置或备用站点激活。相比之下,DRP主要是一个特定于现场的计划,将一个或多个信息系统的从受损或不适宜居住的位置移动到临时替代位置的程序。一旦DRP成功地将一个信息系统站点转移到另一个站点,每个受影响的系统将使用其各自的ISCP来恢复、恢复和测试系统,并将其投入运行。
An ISCP provides established procedures for the assessment and recovery of a system following a system disruption. The ISCP provides key information needed for system recovery, including roles and responsibilities, inventory information, assessment procedures, detailed recovery procedures, and testing of a system.
The ISCP differs from a DRP primarily in that the information system contingency plan procedures are developed for recovery of the system regardless of site or location. An ISCP can be activated at the system's current location or at an alternate site. In contrast, a DRP is primarily a site-specific plan developed with procedures to move operations of one or more information systems from a damaged or uninhabitable location to a temporary alternate location. Once the DRP has successfully transferred an information system site to an alternate site, each affected system would then use its respective ISCP to restore, recover, and test systems, and put them into operation.
一句话总结:系统中断后对系统的评价程序。
8)场所应急计划(OEP) Occupant Emergency Plan (OEP)
概述了人员、环境或财产的健康和安全受到威胁或发生事故时,设施占用者的第一反应程序。此类事件包括火灾、炸弹威胁、化学品泄漏、工作场所的家庭暴力或医疗紧急情况。OEP中还涉及了需要人员留在建筑物内而不是疏散的避难所到位程序。OEP是在设施层面制定的,具体针对建筑物的地理位置和结构设计。
The OEP outlines first-response procedures for occupants of a facility in the event of a threat or incident to the health and safety of personnel, the environment, or property. Such events include a fire, bomb threat, chemical release, domestic violence in the workplace, or a medical emergency. Shelter-in-place procedures for events requiring personnel to stay inside the building rather than evacuate are also addressed in an OEP. OEPs are developed at the facility level, specific to the geographic location and structural design of the building.
一句话总结:关系人员、财产和环境安全
|
计划 |
目的 |
范围 |
计划关系 |
|
业务连续性计划(BCP) |
提供在从重大中断中恢复时维持任务/业务运作的程序。 |
在较低或扩大的层面上处理来自COOP MEF的任务/业务流程。 |
以任务/业务流程为重点的计划,可与合作计划协调启动,以维持非MEF。 |
|
连续性操作计划(COOP) |
提供程序和指导,使组织在备用站点维持30天; |
在一个设施中处理MEF;信息系统的处理仅基于它们对任务基本功能的支持。 |
以MEF为中心的计划,还可以根据需要激活多个业务部门级BCP、ISCP或DRP。 |
|
危机通讯-行动计划 |
提供传播内部和外部通信的程序;提供关键状态信息和控制谣言的方法。 |
处理与人员和公众的沟通;不是以信息系统为中心。 |
基于事件的计划通常由合作社或业务连续性计划激活,但在公共曝光事件期间可以单独使用。 |
|
关键的基础设施保护(CIP)计划 |
提供国家基础设施保护计划中定义的国家关键基础设施组件的保护政策和程序。 |
解决由机构或组织支持或操作的关键基础设施组件。 |
支持具有关键基础设施和关键资源资产的组织的合作计划的风险管理计划。 |
|
网络事件回应计划 |
提供减轻和更正网络攻击(如病毒、蠕虫或特洛伊木马)的过程。 |
解决受影响系统的缓解和隔离、清理和最小化信息丢失的问题。 |
以信息系统为中心的计划,可能激活ISCP或DRP,这取决于攻击的程度。 |
|
灾难恢复计划(DRP) |
提供将信息系统操作重新定位到备用位置的过程。 |
主要系统中断后激活,具有长期影响。 |
以信息系统为中心的计划,激活一个或多个ISCP以恢复单个系统。 |
|
问询处系统意外事故计划(ISCP) |
提供恢复信息系统的过程和功能。 |
在当前位置或适当的备用位置处理单个信息系统恢复。 |
以信息系统为中心的计划,可独立于其他计划或作为更大规模恢复的一部分而启动与DRP、COOP和/或BCP协调的工作。 |
|
居住者应急计划(OEP) |
提供协调的程序,以最大限度地减少生命或伤害的损失,并保护财产损失,以应对人身威胁。 |
专注于特定设施;不基于任务/业务流程或信息系统。 |
立即启动的基于事件的计划事件发生后,在合作社或DRP激活之前。 |
显示了每个计划的相互关系,这些计划是为了响应适用于其各自范围的事件而实现的。
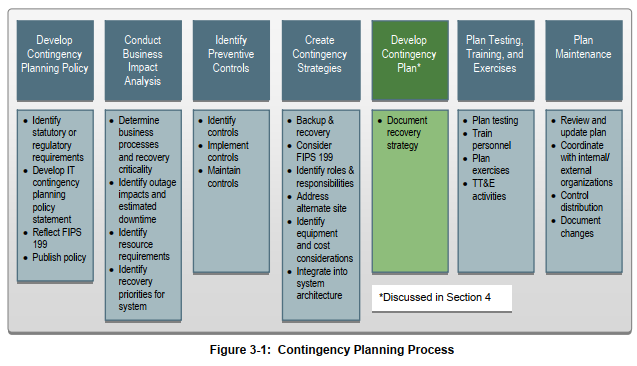
三、关于IT应急计划的七个步骤
制定和维护信息系统应急计划的过程,该过程的七个步骤是:
- 制定应急计划政策;
- 进行业务影响分析(BIA);
- 识别预防控制措施;
- 制定应急策略;
- 制定信息系统应急计划;
- 计划测试、培训和演习;
- 计划维护。
This section describes the process to develop and maintain an effective information system contingency plan. The process presented is common to all information systems. The seven steps in the process are:
1. Develop the contingency planning policy;
2. Conduct the business impact analysis (BIA);
3. Identify preventive controls;
4. Create contingency strategies;
5. Develop an information system contingency plan;
6. Ensure plan testing, training, and exercises; and
7. Ensure plan maintenance.
应急计划流程图
1.制定应急计划政策声明
为了有效并确保人员充分理解组织的应急计划要求,应急计划必须有明确定义。应急计划政策声明应定义组织的总体应急目标,并建立系统应急计划的组织框架和职责。
为了取得成功,高级管理层(很可能是首席信息官)必须支持应急计划,并将其纳入制定计划政策的过程中。
To
be effective and to ensure that personnel fully understand the
organization's contingency planning requirements, the contingency plan
must be based on a clearly defined policy. The
contingency planning policy statement should define the organization's
overall contingency objectives and establish the organizational
framework and responsibilities for system contingency planning. To
be successful, senior management, most likely the CIO, must support a
contingency program and be included in the process to develop the
program policy.
2.业务影响分析(BIA)
BIA通常需要三个步骤:
1.确定任务/业务流程和恢复关键性。确定系统的任务/业务流程,确定系统中断的影响以及估计停机时间。停机时间应反映一个组织在维持任务的同时能够容忍的最长时间。
总结:业务流程、中断影响、最长容忍时间。
2.确定资源需求。实际的恢复工作需要对恢复资源的需求疏理,评估企业的使命、业务流程和相关的相互依赖
应确定的资源示例包括设施、人员、设备、软件、数据文件、系统组件和重要记录。
3. 确定系统资源的恢复优先级。根据先前活动的结果,清楚地将系统资源与关键使命/业务流程相关联。可以为恢复活动和资源的顺序确定优先级。
1.Determine mission/business processes and recovery criticality.Mission/Business
processes supported by the system are identified and the impact of a
system disruption to those processes is determined along with outage
impacts and estimated downtime. The downtime should reflect the maximum time that an organization can tolerate while still maintaining the mission.
2.Identify resource requirements.Realistic recovery efforts require a thorough evaluation of the resources required to resumemission/business processes and related interdependencies as
quickly as possible. Examples of resources that should be identified include facilities, personnel, equipment, software, data files, system components, and vital records.
3.Identify recovery priorities for system resources.Based upon the results from the previous activities, system resources can be linked more clearly to criticalmission/business processes and functions. Priority levels can be established for sequencing recovery activities and resources.
下图展示了BIA流程和数据收集活动,由一个具有多个组件(服务器)的代表性信息系统组成,旨在帮助ISCP协调员简化和集中应急计划开发活动,以实现更有效的计划。
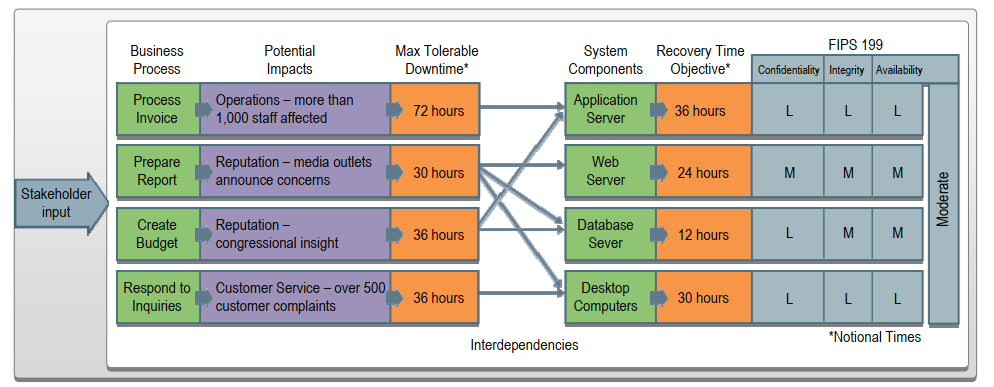
2.1.确定业务流程和恢复关键性
为了完成BIA并更好地了解系统中断或中断对组织的影响,ISCP协调员应与管理层以及内部和外部联络点(POC)合作,以确定和验证依赖或支持信息系统的任务/业务流程和流程。
To accomplish the BIA and better understand the impacts a system outage or disruption can have on the organization, the ISCP Coordinator should work with management and internal and external points of contact (POC) to identify and validate mission/business processes and processes that depend on or support the information system.
ISCP协调员接下来应分析受支持的任务/业务流程,并与流程所有者、领导层和业务经理一起确定,如果给定流程或特定系统数据被中断或以其他方式不可用,则可接受的停机时间。停机时间可以通过多种方式确定。
The ISCP
Coordinator should next analyze the supported mission/business processes
and with the process owners, leadership and business managers determine
the acceptable downtime if a given process or specific system data were
disrupted or otherwise unavailable.
恢复时间目标(RTO)。RTO定义在对其他系统资源、支持的任务/业务流程和MTD产生不可接受的影响之前,系统资源可以保持不可用的最长时间。确定信息系统资源RTO对于选择最适合满足MTD要求的适当技术很重要。
恢复点目标(RPO). RPO表示中断或系统中断前的时间点,在中断后,可以将任务/业务流程数据恢复到该时间点(给定数据的最新备份副本)。与RTO不同,RPO不被视为MTD的一部分。相反,它是任务/业务流程在恢复过程中能够容忍的数据丢失量的一个因素。
因为RTO必须确保没有超过MTD,所以RTO通常必须短于MTD。例如,系统中断可能会阻止某个特定过程的完成,并且由于重新处理数据需要时间,因此必须向RTO添加额外的处理时间,以保持在MTD确定的时间限制内。
ISCP协调员应与管理层合作,通过解决上述因素,确定恢复信息系统的最佳点,同时平衡系统不可用性成本与恢复系统所需资源成本及其对关键任务/业务流程的总体支持。这可以用一个简单的图表来描述,如图的例子。
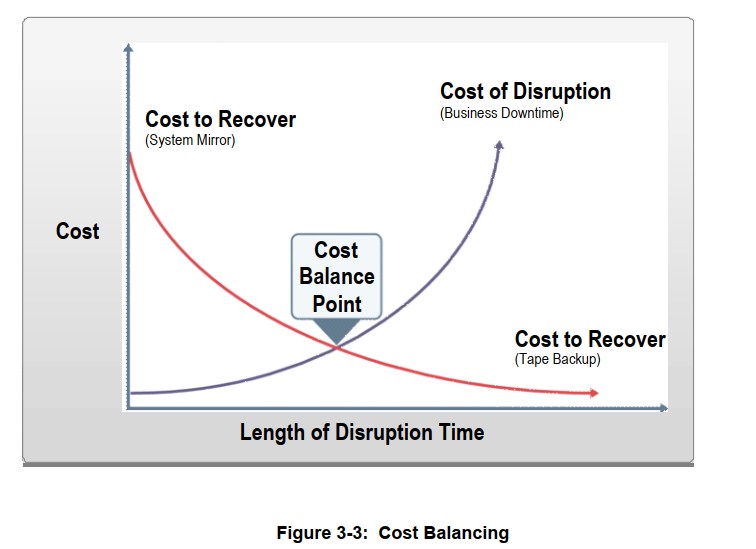
中断允许的时间越长,对组织及其运营造成的成本就越高。相反,RTO越短,实施恢复解决方案的成本就越高。
上面关于MTD、RPO、RTO说的比较啰嗦,直接上一张图。
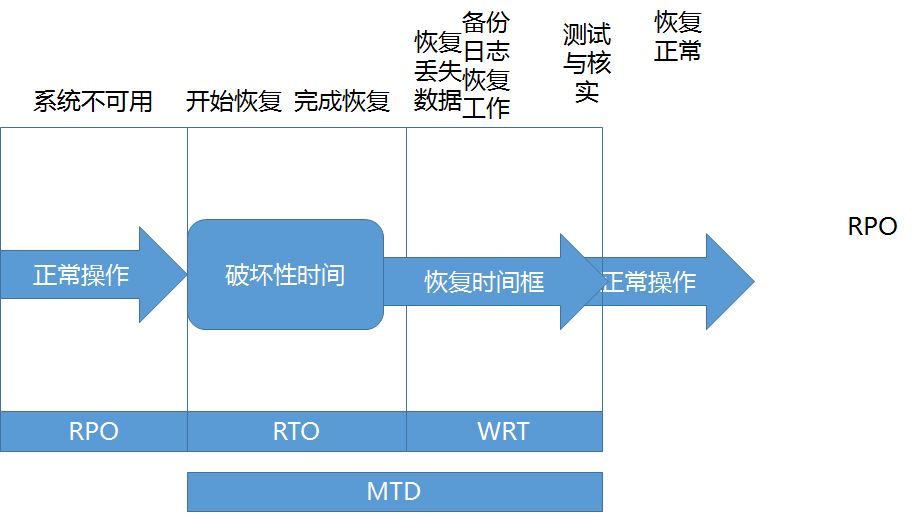
总结一下:RTO是系统从故障到能启动起来的时间,这个时候还有需要把数据恢复进来的时间是WRT,也就是说系统正常运行了,但还无法对外提供服务,系统数据还未恢复。RTO+WRT的合值是MTD,所以RTO+WRT要小于MTD。而具体允许恢复的最底线是多少呢,是RPO。举个例子。当系统故障后,将系统能运行起来的时间是RTO,这个时候把数据还原的时间是WRT,然后假如企业最多允许丢一天的时间,一天单位就是RPO了,是企业能承受的最大损失。
2.2.确定资源需求
实际的恢复工作需要对恢复所需的资源进行彻底的评估。
Realistic recovery efforts require a thorough evaluation of the resources required to resume
也就是说确定要满足恢复目标,需要哪些资源,包括人、财、物。
2.3.确定系统资源恢复优先级
制定恢复优先级是BIA流程的最后一步。考虑到任务/业务流程的关键性、中断影响、可容忍的停机时间和系统资源,可以有效地确定恢复优先级。结果是信息系统恢复优先级层次结构。
Developing recovery priorities is the last step of the BIA process. Recovery priorities can be effectively established taking into consideration mission/business process criticality, outage impacts, tolerable downtime, and system resources. The result is an information system recovery priority hierarchy. The ISCP Coordinator should consider system recovery measures and technologies to meet the recovery priorities.
BIA中确定的优先级业务,可以通过预防措施来阻止、检测和/或降低影响。在可行且成本有效的情况下,预防方法比在系统中断后恢复所需的措施更可取。
In
some cases, the outage impacts identified in the BIA may be mitigated or
eliminated through preventive measures that deter, detect, and/or
reduce impacts to the system. Where
feasible and costeffective, preventive methods are preferable to
actions that may be necessary to recover the system after a disruption.
Step
2 of the RMF includes the identification of effective contingency
planning preventive controls and maintaining these controls on an
ongoing basis.
4.制定应急策略
制定应急策略以减轻应急计划的风险,涵盖备份、恢复、应急计划、测试和持续维护的全部范围。
Contingency
strategies are created to mitigate the risks for the contingency
planning family of controls and cover the full range of backup,
recovery, contingency planning, testing, and ongoing maintenance.
备份和恢复方法和策略是在服务中断后快速有效地恢复系统操作的一种方法。这些方法和策略应解决中断影响和BIA中确定的允许停机时间,并应在SDLC的开发/获取阶段集成到系统架构(architecture)中。
具体恢复方法,可包括具有备用的商业合同现场供应商,与内部或外部组织的互惠协议,以及与设备供应商的服务水平协议(sla)。此外,在制定系统恢复策略时,应考虑独立磁盘冗余阵列(RAID)、自动故障切换、UPS、服务器群集和镜像系统等技术。
在制定和比较策略时,应考虑几种替代方法,包括成本、最大停机时间、安全性、恢复优先级,以及与更大的组织级应急计划的集成。
Backup and recovery methods and strategies are a means to restore system operations quickly and effectively following a service disruption. The methods and strategies should address disruption impacts and allowable downtimes identified in the BIA and should be integrated into the system architecture during the Development/Acquisition phase of the SDLC. A wide variety of recovery approaches may be considered, with the appropriate choice being highly dependent upon the incident, type of system, BIA/FIPS 199 impact level, and the system's operational requirements.22 Specific recovery methods further described in Section 3.4.2 should be considered and may include commercial contracts with alternate site vendors, reciprocal agreements with internal or external organizations, and service-level agreements (SLAs) with equipment vendors. In addition, technologies such as redundant arrays of independent disks (RAID), automatic failover, UPS, server clustering, and mirrored systems should be considered when developing a system recovery strategy.
Several alternative approaches should be considered when developing and comparing strategies, including cost, maximum downtimes, security, recovery priorities, and integration with larger, organization-level contingency plans. Table is an example that can assist in identifying the linkage of FIPS 199 impact level for the availability security objective, recovery priority, backup, and recovery strategy.
系统数据应定期备份。策略应根据数据关键性和引入新信息的频率,指定备份的最低频率和范围(如每日或每周、增量或完整备份)。数据备份策略应指定存储数据的位置、文件命名约定、媒体轮换频率和异地传输数据的方法。数据可以备份在磁盘、磁带或光盘上。
将数据备份到异地是一个比较好的业务实践。商业数据存储设施专门用于存档媒体并保护数据免受威胁。如果使用异地存储,则将数据标记、打包后传输到异地的存储中。如果进行数据恢复和测试,访问存储,通过本地或异地获取特定的数据。
System data should be backed up regularly. Policies should specify the minimum frequency and scope of backups (e.g., daily or weekly, incremental or full) based on data criticality and the frequency that new information is introduced. Data backup policies should designate the location of stored data, file-naming conventions, media rotation frequency, and method for transporting data offsite. Data may be backed up on magnetic disk, tape, or optical disks, such as compact disks (CDs). The specific method chosen for conducting backups should be based on system and data availability and integrity requirements. These methods may include electronic vaulting, network storage, and tape library systems
It is good business practice to store backed-up data offsite. Commercial data storage facilities are specially designed to archive media and protect data from threatening elements. If using offsite storage, data is backed up at the organization's facility and then labeled, packed, and transported to the storage facility. If the data is required for recovery or testing purposes, the organization contacts the storage facility requesting specific data to be transported to the organization or to an alternate facility.
Commercial storage facilities often offer media transportation and response and recovery services. When selecting an offsite storage facility and vendor, the following criteria should be considered:
4.3.备用场地
NIST SP 800-53确定了信息系统的CP控制。可用性安全目标的FIPS 199安全分类确定了哪些控件适用于特定系统。
备用场地类型包括:
- 热站点
- 温站点
- 冷站点
As stated in Section 2.1, NIST SP 800-53 identifies the CP controls for information systems. The FIPS 199 security categorization for the availability security objective determines which controls apply to a particular system. For example, an information system categorized with a low-availability security objective does not require alternate storage or a processing site (CP-6 and CP-7, respectively), and an information system with a moderate-availability security objective requires the system backup and testing the backup (CP-9 [1]).
4.4.设备更换
如果信息系统损坏或毁坏,或主站点不可用,则需要快速激活或采购必要的硬件和软件,并将其交付到备份地。
If the information system is damaged or destroyed or the primary site is unavailable, necessary hardware and software will need to be activated or procured quickly and delivered to the alternate location. Three basic strategies exist to prepare for equipment replacement.
4.5.成本考虑
ISCP协调员应确保所选战略能够在现有人员和财政资源的帮助下得到有效实施。考虑中的每种备用场地、设备更换和存储方案的成本应与预算限制进行权衡。协调员应确定已知的应急计划费用,如备用现场合同费用,以及不太明显的费用,如实施机构范围的应急意识计划和承包商支持的费用。预算必须足以涵盖软件、硬件、行程和运输、测试、培训计划、认知计划、工时、其他合同服务和任何其他适用资源(如办公桌、电话、传真机、笔和纸)。
组织应进行成本效益分析,以确定最佳应急策略。
The ISCP Coordinator should ensure that the strategy chosen can be implemented effectively with available personnel and financial resources. The cost of each type of alternate site, equipment replacement, and storage option under consideration should be weighed against budget limitations. The coordinator should determine known contingency planning expenses, such as alternate site contract fees, and those that are less obvious, such as the cost of implementing an agency-wide contingency awareness program and contractor support. The budget must be sufficient to encompass software, hardware, travel and shipping, testing, plan training programs, awareness programs, labor hours, other contracted services, and any other applicable resources (e.g., desks, telephones, fax machines, pens, and paper). The organization should perform a cost-benefit analysis to identify the optimum contingency strategy. Table provides a template for evaluating cost considerations.
4.6.角色和职责
在选择并实施备份和系统恢复策略,ISCP协调员必须指定适当的团队来实施该策略。每个团队都应接受培训,并准备好在出现需要启动计划的破坏性情况时做出响应。应将恢复人员分配到几个特定团队中的一个,这些团队将对事件作出响应,恢复能力,并使系统恢复正常运行。为此,恢复团队成员需要清楚地了解团队的恢复工作目标、团队将执行的各个过程,以及恢复团队之间的相互依赖性集对总体策略的影响。
Having selected and implemented the backup and system recovery strategies, the ISCP Coordinator must designate appropriate teams to implement the strategy. Each team should be trained and ready to respond in the event of a disruptive situation requiring plan activation. Recovery personnel should be assigned to one of several specific teams that will respond to the event, recover capabilities, and return the system to normal operations. To do so, recovery team members need to clearly understand the team's recovery effort goal, individual procedures the team will execute, and how interdependencies between recovery teams may affect overall strategies.
制定信息系统应急计划,这部分在第四部分进行了详细介绍。
5.测试、培训和演习(TT&E)
ISCP应保持在准备状态,包括对人员进行培训以履行其在计划中的角色和职责,实施计划以验证其内容,并对系统和系统组件进行测试,以确保其在ISCP规定的环境中的可操作性。
An
ISCP should be maintained in a state of readiness, which includes
having personnel trained to fulfill their roles and responsibilities
within the plan, having plans exercised to validate their content, and
having systems and system components tested to ensure their operability
in the environment specified in the ISCP.
各组织应在组织或系统变更、发布新的TT&E指南或其他需要时,定期进行TT&E活动。TT&E活动的执行有助于组织确定计划的有效性,并且所有人员都知道他们在执行每个信息系统计划中的角色。TT&E活动时间表通常由组织要求决定。
对于执行的每个TT&E活动,结果记录在行动后报告中,并收集经验教训纠正措施,以更新ISCP中的信息。
Organizations should conduct TT&E events periodically, following organizational or system changes, or the issuance of new TT&E guidance, or as otherwise needed. Execution of TT&E events assists organizations in determining the plan's effectiveness, and that all personnel know what their roles are in the conduct of each information system plan. TT&E event schedules are often dictated in part by organizational requirements.
5.1测试
ISCP测试是可行的应急能力的关键。测试能够通过验证一个或多个系统组件和计划的可操作性来识别和解决计划缺陷。测试可以采取多种形式并实现多种目标,但应尽可能接近实际操作环境。应对每个信息系统组件进行测试,以确认各个恢复程序的准确性。
ISCP testing is a critical element of a viable contingency capability. Testing enables plan deficiencies to be identified and addressed by validating one or more of the system components and the operability of the plan. Testing can take on several forms and accomplish several objectives but should be conducted in as close to an operating environment as possible. Each information system component should be tested to confirm the accuracy of individual recovery procedures. The following areas should be addressed in a contingency plan test, as applicable:
5.2.培训
对具有应急计划职责的人员的培训应侧重于使他们熟悉ISCP角色和完成这些角色所必需的技能。这种方法有助于确保员工参加测试和演习以及实际的应急事件做好了准备。应至少每年提供一次培训。
Training for personnel with contingency plan responsibilities should focus on familiarizing them with ISCP roles and teaching skills necessary to accomplish those roles. This approach helps ensure that staff is prepared to participate in tests and exercises as well as actual outage events. Training should be provided at least annually.
5.3.练习
NIST SP 800-84确定了单个组织在信息系统TT&E项目中广泛使用的以下类型的练习
NIST SP 800-84 identifies the following types of exercises widely used in information system TT&E programs by single organizations:
5.4.测试总结
测试项目提供了一个确定、安排和设定目标的总体框架
测试活动。NIST SP 800-84中提供了关于建立有效的ISCP TT&E计划以及进行TT&E活动的各种方法和途径的指南。ISCP TT&E活动的深度和严密性随着FIPS 199可用性安全目标的实现而增加。所有的测试和练习都应该包括确定对组织运作的影响,并提供一种机制来更新和改进计划。
A TT&E program provides an overall framework for determining, scheduling, and setting objectives for
TT&E activities. Guidance on establishing an effective ISCP TT&E program and the various methods and approaches for conducting TT&E activities is provided in NIST SP 800-84. The depth and rigor of ISCP TT&E activities increases with the FIPS 199 availability security objective. All tests and exercises should include some kind of determination of the effects on the organization's operations and provide for a mechanism to update and improve the plan as a result.
6.计划维护
为了有效,计划必须保持就绪状态,准确反映系统需求、程序、组织结构和政策。在SDLC的运行/维护阶段,由于业务需求的变化、技术升级或新的内部或外部政策,信息系统经常发生变化。因此,作为组织变更管理过程的一部分,必须定期审查和更新ISCP,以确保记录新信息,并在需要时修订应急措施。
作为一般规则,应以组织规定的频率或当计划的任何要素发生重大变化时,审查计划的准确性和完整性。某些元素,如联系人列表,将需要更频繁的审查。应对中等或高等影响系统的计划进行更频繁的审查。
To be effective, the plan must be maintained in a ready state that accurately reflects system requirements, procedures, organizational structure, and policies. During the Operation/Maintenance phase of the SDLC, information systems undergo frequent changes because of shifting business needs, technology upgrades, or new internal or external policies. Therefore, it is essential that the ISCP be reviewed and updated regularly as part of the organization's change management process to ensure that new information is documented and contingency measures are revised if required. As identified as part of RMF Step 6 (Continuous Monitoring), a continuous monitoring process can provide organizations with an effective tool for plan maintenance, producing ongoing updates to security plans, security assessment reports, and plans of action and milestone documents.
四、应急计划
该计划包含与中断后恢复信息系统相关的详细角色、职责、团队和过程。ISCP应记录旨在支持应急行动的技术能力,并应根据组织及其要求进行调整。计划需要平衡细节和灵活性;通常,计划越详细,可扩展性和通用性就越差。此处提供的信息旨在作为指南;然而,本文件中的计划格式可根据需要进行修改,以更好地满足用户的特定系统、操作和组织要求。
The plan
contains detailed roles, responsibilities, teams, and procedures
associated with restoring an information system following a disruption.
The
ISCP should document technical capabilities designed to support
contingency operations and should be tailored to the organization and
its requirements. Plans
need to balance detail with flexibility; usually, the more detailed the
plan, the less scalable and versatile the approach. The
information presented here is meant to be a guide; nevertheless, the
plan format in this document may be modified as needed to better meet
the user's specific system, operational, and organization requirements.
本指南确定了应急计划的五个主要组成部分。
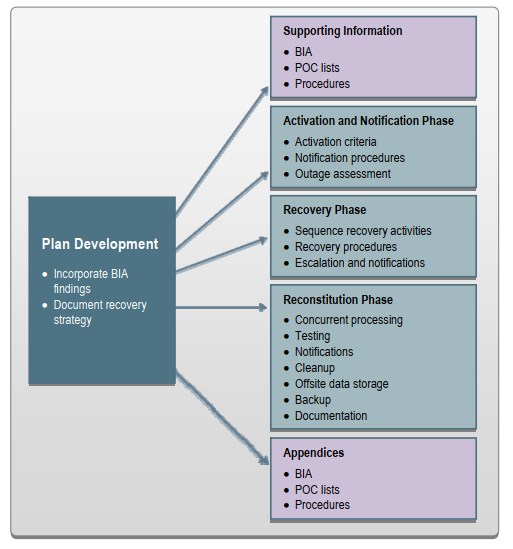
应对计划进行标准化,以便不熟悉计划或系统的人员执行恢复操作时提供快速而清晰的指示。计划应清晰、简明,并且在紧急情况下易于实施。如有可能,应使用检查表和分步程序。简洁且格式良好的计划可以减少创建过于复杂或令人困惑的计划的可能性。
Plans should be formatted to provide quick and clear directions in the event that personnel unfamiliar with the plan or the systems are called on to perform recovery operations. Plans should be clear, concise, and easy to implement in an emergency. Where possible, checklists and step-by-step procedures should be used. A concise and well-formatted plan reduces the likelihood of creating an overly complex or confusing plan.
1.支持信息
辅助信息部分包括“操作简介和概念”部分,提供基本背景或上下文信息,使应急计划更易于理解、实施和维护。这些细节有助于理解本指南的适用性,有助于就如何使用本计划作出决定,也有助于提供有关在何处可以找到相关计划和本计划范围以外的信息。
The supporting information component includes an introduction and concept of operations section providing essential background or contextual information that makes the contingency plan easier to understand, implement, and maintain. These details aid in understanding the applicability of the guidance, in making decisions on how to use the plan, and in providing information on where associated plans and information outside the scope of the plan may be found.
2.激活和通知阶段
激活和通知阶段定义了一旦检测到系统中断或停机或似乎即将发生时所采取的初始操作。此阶段包括通知恢复人员、进行应急评估和激活计划的活动。在激活和通知阶段结束时,ISCP工作人员将准备执行恢复措施以恢复系统功能。
The Activation and Notification Phase defines initial actions taken once a system disruption or outage has been detected or appears to be imminent. This phase includes activities to notify recovery personnel, conduct an outage assessment, and activate the plan. At the completion of the Activation and Notification Phase, ISCP staff will be prepared to perform recovery measures to restore system functions.
2.1.激活标准和程序
如果满足该系统的一个或多个激活标准,则应激活ISCP。如果满足激活标准,指定机构应激活计划。系统中断或中断的激活标准对于每个组织都是唯一的,应在应急计划策略中说明。
The ISCP should be activated if one or more of the activation criteria for that system are met. If
an activation criterion is met, the designated authority should
activate the plan.[29] Activation criteria for system outages or
disruptions are unique for each organization and should be stated in the
contingency planning policy.
2.2.通知程序
在事先通知或不通知的情况下,可能会发生中断或中断。例如,通常会提前通知,飓风预计会影响一个地区,或者电脑病毒预计会在某一天出现。但是,可能没有设备故障或犯罪行为的通知。两种情况的通知程序应记录在计划中。程序应描述在营业时间和非营业时间通知恢复人员的方法。及时通知对于减少中断对系统的影响非常重要;在某些情况下,它可以提供足够的时间,允许系统人员从容地关闭系统,以避免发生硬崩溃。在故障或中断之后,应向恢复评估小组发出通知,以便其确定情况的状态和适当的下一步措施。
An outage or disruption may occur with or without prior notice. For example, advance notice is often given that a hurricane is predicted to affect an area or that a computer virus is expected on a certain date. However, there may be no notice of equipment failure or a criminal act. Notification procedures should be documented in the plan for both types of situation. The procedures should describe the methods used to notify recovery personnel during business and non business hours. Prompt notification is important for reducing the effects of a disruption on the system; in some cases, it may provide enough time to allow system personnel to shut down the system gracefully to avoid a hard crash. Following the outage or disruption, notification should be sent to the Outage Assessment Team[30] so that it may determine the status of the situation and appropriate next steps. Outage assessment procedures are described in Section 4.2.3. When outage assessment is complete, the appropriate recovery and system support personnel should be notified.
2.3.恢复评估
为了确定系统中断或停机后如何实施ISCP,必须评估中断的性质和程度。恢复评估应在给定条件允许的情况下尽快完成,人员安全仍然是最高优先级。在可能的情况下,应急评估小组是第一个收到中断通知的小组。应急评估程序对于特定系统可能是唯一的,但至少应考虑以下方面:
To determine how the ISCP will be implemented following a system disruption or outage, it is essential to assess the nature and extent of the disruption. The outage assessment should be completed as quickly as the given conditions permit, with personnel safety remaining the highest priority. When possible, the Outage Assessment Team is the first team notified of the disruption. Outage assessment procedures may be unique for the particular system, but the following minimum areas should be addressed:
3.恢复阶段
正式恢复操作在ISCP启动、恢复评估完成(如有可能)、人员得到通知和适当的团队调动之后开始。恢复阶段活动的重点是实施恢复策略,以恢复系统能力、修复损坏并在原始或新的备用位置恢复操作能力。在恢复阶段结束时,信息系统将发挥作用,能够执行计划中确定的各项功能。根据计划中定义的恢复策略,这些功能可以包括临时手动处理、在备用系统上的恢复和操作,或在备用站点上的重新定位和恢复。在这个阶段,只有在BIA中被确定为高优先级的系统资源才可以被恢复。
Formal recovery operations begin after the ISCP has been activated, outage assessments have been completed (if possible), personnel have been notified, and appropriate teams have been mobilized. Recovery Phase activities focus on implementing recovery strategies to restore system capabilities, repair damage, and resume operational capabilities at the original or new alternate location. At the completion of the Recovery Phase, the information system will be functional and capable of performing the functions identified in the plan. Depending on the recovery strategies defined in the plan, these functions could include temporary manual processing, recovery and operation at an alternate system, or relocation and recovery at an alternate site. It is feasible that only system resources identified as high priority in the BIA will be recovered at this stage.
3.1.恢复活动的顺序
当恢复复杂系统时,例如涉及多个独立组件的广域网(WAN)或虚拟局域网(VLAN),恢复过程应反映BIA中确定的系统优先级。活动顺序应反映系统的MTD,以避免对相关系统产生重大影响。过程应以逐步的顺序格式编写,以便系统组件可以逻辑方式还原。例如,如果局域网在中断后正在恢复,那么最关键的服务器应该在其他不太关键的设备(如打印机)之前恢复。
When recovering a complex system, such as a wide area network (WAN) or virtual local area network (VLAN) involving multiple independent components, recovery procedures should reflect system priorities identified in the BIA. The sequence of activities should reflect the system's MTD to avoid significant impacts to related systems. Procedures should be written in a stepwise, sequential format so system components may be restored in a logical manner. For example, if a LAN is being recovered after a disruption, then the most critical servers should be recovered before other, less critical devices, such as printers. Similarly, to recover an application server, procedures first should address operating system restoration and verification before the application and its data are recovered. The procedures should also include escalation steps and instructions to coordinate with other teams where relevant when certain situations occur, such as:
3.2.恢复程序
为方便恢复阶段的操作,ISCP应提供详细的过程,以将信息系统或组件还原到已知状态。
To facilitate Recovery Phase operations, the ISCP should provide detailed procedures to restore the information system or components to a known state. Given the extensive variety of system types, configurations, and applications, this planning guide does not provide specific recovery procedures.
3.3.恢复升级和通知
作为BIA的一部分,系统组件、基础设施和相关设施是支持日常任务/业务流程的关键组件。将用户连接到这些系统、应用程序和基础结构的系统、应用程序和基础结构会受到导致服务中断和中断的事件的影响。在恢复阶段包含一个升级和通知组件有助于确保遵循一个总体的、可重复的、结构化的、一致的和可测量的恢复过程。
As identified as part of the BIA, system components, infrastructure, and associated facilities are critical components supporting daily mission/business processes. The systems, applications, and infrastructure that connect users to these are subject to events causing service interruptions and outages. Including an escalation and notification component within the Recovery Phase helps to ensure that overall, a repeatable, structured, consistent, and measurable recovery process is followed.
有效的升级和通知过程应该定义和描述附加操作所必需的事件、阈值或其他类型的触发器。行动将包括更多恢复人员的附加通知、向领导层发送的消息和状态更新,以及附加资源的通知。应包括建立一套明确的事件、行动和结果的程序,并应酌情为团队或个人记录。
Effective escalation and notification procedures should define and describe the events, thresholds, or other types of triggers that are necessary for additional action. Actions would include additional notifications for more recovery staff, messages and status updates to leadership, and notices for additional resources. Procedures should be included to establish a clear set of events, actions and results, and should be documented for teams or individuals as appropriate.
4.重建阶段
重构阶段是ISCP实现的第三个也是最后一个阶段,定义了测试和验证系统能力和功能所采取的措施。在重建过程中,恢复活动完成,恢复正常的系统操作。如果原始设施无法恢复,则此阶段的活动也可用于准备新的永久性位置,以支持系统处理需求。此阶段包括两个主要活动:验证计划的成功恢复和停用。
恢复验证通常包括以下步骤:
并行处理并发处理是指在两个独立的位置同时运行一个系统,直到能够保证恢复的系统正常、安全地运行为止的过程。
验证数据测试. 数据测试是测试和验证已恢复数据的过程,以确保数据文件或数据库已完全恢复,并且是最新的可用备份。
验证功能测试. 功能测试是一个过程,用于验证所有系统功能都已测试,并且系统已准备好恢复正常操作。
The
Reconstitution Phase is the third and final phase of ISCP
implementation and defines the actions taken to test and validate system
capability and functionality. During Reconstitution, recovery activities are completed and normal system operations are resumed. If
the original facility is unrecoverable, the activities in this phase
can also be applied to preparing a new permanent location to support
system processing requirements. This phase consists of two major activities: validating successful recovery and deactivation of the plan. Validation of recovery typically includes these steps:
5.计划附录
应急计划附录提供了计划正文中未包含的关键细节。通用应急计划附录包括以下内容:
Contingency plan appendices provide key details not contained in the main body of the plan.
- 应急计划小组人员联系方式;
- 供应商联系信息,包括场外存储和备用现场POC;
- BIA;
- 详细的恢复程序和清单;
- 详细的验证测试程序和检查表;
- 设备和系统需求支持系统操作所需的硬件、软件、固件和其他资源的列表。应提供每个条目的详细信息,包括型号或版本号、规格和数量;
- 对系统进行恢复时可能发生的备用任务/业务处理程序;
- ISCP测试和维护程序;
- 系统互连(直接互连或交换信息的系统);以及
- 供应商服务水平协议、与其他组织的互惠协议以及其他重要记录。
总结:
1.应急计划的步骤:1)激活和通知 2)恢复阶段(一般备用设施) 3)重建阶段(一般是将系统从备用站点迁移到主站点)
2.而整个ISCP中,应急策略是保障措施,通过一些预防措施将灾难的影响降低到可接受程度,应急计划是灾难发生后处理方法、流程,而如何处理采取那些措施的决策依据是BIA的分析结果。而这些措施的实施需要企业战略层面的保障,同时通过日常的培训、测试和演练来保障计划的有效性、可行性。
3.在开篇提到的各种计划,其内在有什么关系内,BCP的具体执行层面是COOP,BCP关注业务,COOP关注具体系统,而对于重要、紧急的系统在灾备中应用则在DRP中说明,而过错中无论是对外、对内沟通还是针对网络事件有相应的针对性计划。整体形成了ISCP。
https://www.nist.gov/ NIST Special Publication 800-34 Rev.1
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">