当一切正常时,没有必要特别留意什么是事务日志,它是如何工作的。你只要确保每个数据库都有正确的备份。当出现问题时,事务日志的理解对于采取修正操作是重要的,尤其在需要紧急恢复数据库到指定点时。这系列文章会告诉你每个DBA应该知道的具体细节。
对于日志文件的最大日志吞吐量,我们从存储架构思路的简单回顾开始,然后进一步看下日志碎片如何影响需要日志读取操作的性能,例如日志备份,或者故障恢复过程。
最后,我们会谈下在日志大小和增长管理的最佳实践,还有对过渡日志增长和碎片的正确处理。
物理架构
正确的物理硬件和架构会帮你保证日志吞吐量的最大可能,还有一些“黄金法则”。在这之前,已经有人谈过了,尤其是Kimberly Tripp在她的《8步走向更好的事务日志吞吐》里,因此在这里不会更深入的探讨这个话题。
要注意的是,对于日志文件,在设计内在物理结构时,我们的首要目标是最优日志写吞吐量。对于每个添加、删除或修改数据的事务,SQL Server写入日志,这也包括数据库维护操作,例如索引重建或重组,统计信息更新等等。
你只需要一个日志文件
从多个日志文件,在日志吞吐量方面,不会获得性能。SQL Server不会并行写入多个日志文件。只有一个情况SQL Server会写入所有日志文件,那是当在每个日志文件里更新文件头时,SQL Server写入它来更新不同的LSN,例如最后检查点,最早打开的事务,最后一次日志备份等等。当只更新文件头时,很多人会误认为SQL Server会写入所有日志文件。
如果一个数据库有4个日志文件,SQL Server会写入日志到日志文件1,直到满了,然后日志文件2,日志文件3和日志文件4,然后尝试绕回重新写入日志文件1。我们可以通过创建有多个日志文件(或通过对现存数据库增加更多文件)的数据库来验证下。代码8.1创建一个Person数据库,有1个主数据文件和2个日志文件,每个在不同的硬盘上。
数据和备份文件位置
这篇文章里的例子都假设数据和日志文件位于D:SQLData,所有备份位于:D:SQLBackups,各自不同的位置。当运行这些例子时,直接修改这些位置到你系统合适的位置(并且注意,在实际的系统中,我们不会在同个硬盘上存储数据和日志文件)。
注意对于这些数据和日志文件的大小和文件增长率设置,我们是基于AdventureWorks2008的:
1 USE master 2 GO 3 IF DB_ID('Persons') IS NOT NULL 4 DROP DATABASE Persons; 5 GO 6 7 CREATE DATABASE [Persons] ON PRIMARY 8 ( NAME = N'Persons' 9 , FILENAME = N'D:SQLDataPersons.mdf' 10 , SIZE = 199680KB 11 , FILEGROWTH = 16384KB 12 ) 13 LOG ON 14 ( NAME = N'Persons_log' 15 , FILENAME = N'D:SQLDataPersons_log.ldf' 16 , SIZE = 2048KB 17 , FILEGROWTH = 16384KB 18 ), 19 ( NAME = N'Persons_log2' 20 , FILENAME = N'C:SQLDataPersons_log2.ldf' 21 , SIZE = 2048KB 22 , FILEGROWTH = 16384KB 23 ) 24 GO 25 26 ALTER DATABASE Persons SET RECOVERY FULL; 27 28 USE master 29 GO 30 BACKUP DATABASE Persons 31 TO DISK ='D:SQLBackupsPersons_full.bak' 32 WITH INIT; 33 GO
代码8.1:创建有2个日志文件的Persons数据库。
接下来,代码8.2创建一个范例Persons表。
1 USE Persons 2 GO 3 IF EXISTS ( SELECT * 4 FROM sys.objects 5 WHERE object_id = OBJECT_ID(N'dbo.Persons') 6 AND type = N'U' ) 7 DROP TABLE dbo.Persons; 8 GO 9 10 CREATE TABLE dbo.Persons 11 ( 12 PersonID INT NOT NULL 13 IDENTITY , 14 FName VARCHAR(20) NOT NULL , 15 LName VARCHAR(30) NOT NULL , 16 Email VARCHAR(7000) NOT NULL 17 ); 18 GO
代码8.2:创建Persions表。
现在,我们会增加15000行到表,并运行DBCC LOGINFO。注意在我们的测试里,我们从AdventureWorks2005数据库里的Person.Contact表里的数据来插入。你也可以使用AdventureWorks2008或AdventureWorks2012数据库。
1 INSERT INTO dbo.Persons 2 ( FName , 3 LName , 4 Email 5 ) 6 SELECT TOP 15000 7 LEFT(aw1.FirstName, 20) , 8 LEFT(aw1.LastName, 30) , 9 aw1.EmailAddress 10 FROM AdventureWorks2005.Person.Contact aw1 11 CROSS JOIN AdventureWorks2005.Person.Contact aw2; 12 GO 13 14 USE Persons 15 GO 16 DBCC LOGINFO;
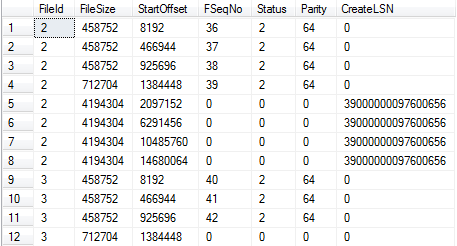
代码8.3:插入数据并检查VLF
SQL Server在主日志文件里(日志文件2)连续插入VLF,接下来插入第2个日志文件(日志文件3)。而且自动增长了主日志文件(SQL Server如何自动增长事务日志的,可以查看这个系列的第2篇文章)。
如果我们继续增加记录。SQL Server会继续增长需要的2个文件,按顺序填充VLF,一次一个VLF。图8.1展示在重新运行代码8.3,增加95000行后的情形(合计增加了110000行)。现在对于主日志文件,我们有12个VLF,对于第2个日志文件我们有8个VLF。
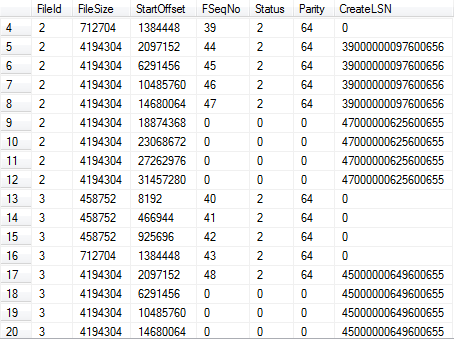
图8.12个日志文件的连续使用。
在这个情况里,读取日志的任何操作都会始于主日志里的4个VLF块开始(FSeqNo 36-39),接下来在第2个日志文件里的4个块(FSeqNo 40-43),再接下来是主日志里的4个块,以此循环。这是为什么多个日志文件会降低I/O效率,我们会在下个环节进一步讨论。
增加额外日志文件的唯一原因是一个例外场景,例如,磁盘上的日志文件满了(看下第6篇),我们又临时需要日志空间,增加额外日志文件是我们让SQL Server退出只读模式的最快方法。但是,一旦额外文件不需要后我们应该将它移除,我们稍后会讨论,在 如果出错了我们该怎么办 部分。
对于日志文件使用专用硬盘/磁盘阵列
把数据文件与日志文件分别放在不同的硬盘,有很多理由来解释它为什么是个很好的做法。首先,在硬盘故障时,这个架构提供更好的恢复机会。例如,如果存储数据文件的阵列遭受灾难性故障,但日志文件不会和它一起沉船。我们还是有机会进行尾日志备份,把数据库恢复到非常接近灾难发生的时间点(看下第5篇)。
其次,分离数据文件I/O和日志文件I/O可以用来优化I/O效率。SQL Server数据库同时进行随机和顺序I/O操作。顺序I/O是SQL Server可以读写块,而不需要请求磁盘上磁头的重新定位。SQL Server使用顺序I/O进行预读操作,还有所有的事务日志操作,使用传统硬盘来说,它是最快的I/O类型。
随机I/O是读写块时,需要请求磁盘头改变在磁盘上的位置。这会导致寻求延迟I/O,相对顺序I/O,同时降低输出(MB/s)和性能(IOPS)。一般来说读操作,尤其在OLTP系统里,是随机I/O,顺序读取相关的页小块是随机I/O请求的一小部分。
从主顺序I/O里分离主要的随机I/O,我们避免了2者之间的冲突,提高全局的I/O效率。更进一步,对于日志文件的优化配置并不必和数据文件一样。通过分离数据和日志文件,我们可以针对I/O活动类型为每个I/O子系统进行合适配置。例如,选择优化的RAID配置作为磁盘阵列(下一部分会详谈)。
最后,要提的是在专门磁盘/阵列上的单个日志文件允许磁头保持刚好稳定,因为SQL Server是顺序写入日志的。但是,在单个磁盘/阵列上的多个日志文件,磁头会在每个日志间跳跃;我们没有顺序写入,没有磁盘搜索的话,因此我们降低了顺序I/O的效率。
理想的情况,每个数据库都应该在专门的磁盘阵列上有一个日志文件,但是很多系统这个并不现实,只是个理想。
由于同样的原因,与顺序I/O效率相关,在我们创建日志文件前,我们要对物理硬盘磁盘碎片整理下,这非常重要。
可能的话,对于日志硬盘,使用RAID 10
RAID,独立磁盘冗余阵列(Redundant Array of Independent Disks)的缩写,是用来实现下列目标的技术:
- 提高I/O性能级别,用每秒输入/输出操作衡量(Input/Output Operations Per Second(IOPS)),单位大致是(MB/秒/IO以KB为单位的大小)*1024
- 提高I/O吞吐量,用MB/秒来衡量,单位大致是(IOPS * IO以KB为单位的大小)/1024
- 提高在单个硬盘里的可用存储量——你现在还不能购买5TB的单个硬盘,但你可以通过在RAID 5阵列里的6个1TB的硬盘,在操作系统里拥有5TB的硬盘。
- 获得数据冗余,通过在多个硬盘分布存储部分信息,或者在阵列里使用物理硬盘镜像。
RAID级别的选择很大程度上取决于磁盘必须支持的工作量,如刚才讨论的,对于数据和日志文件的具体不同I/O工作量,意味着在每个情况下会有不同的RAID配置。
在I/O吞吐量和性能方面,我们应该努力优化日志文件阵列的顺序写。很多专家认为RAID 1 + 0就这一点而言是最佳选择,尽管这个是以GB存储空间最贵花费。
深入RAID
每个RAID级别优劣的完整参考不是这个系列文章的讨论范围。了解更多信息,我们请你参考《SQL Server故障排除(Troubleshooting SQL Server)》的第2章。
RAID 1+0是个内嵌的RAID,被称为“镜像条带 ”。它通过每个硬盘的第一镜像提供冗余,即RAID 1,然后使用RAID 0条带化这些镜像硬盘来提高性能。由于只有磁盘的一半空间可以使用,所以会大大增加成本。然后,这个配置提高冗余的最佳配置,因为即使多个硬盘损坏,系统还是正常运行的,也不会降低系统性能。
常见的更实惠的备用方法是RAID 5,"部分条带",在多个硬盘间条带数据,如RAID 0,只存储部分数据,提供单个磁盘损坏保护。对于同样的存储,与RAID 1 + 0比,RAID 5需要更少的磁盘,且提供优异的读性能。但是,维护部分化数据引发了写性能上的损失。对于当下的存储阵列,这只是个小问题,这是对于事务日志文件,很多DBA不推荐它的原因,因为它主要进行的是顺序写,要求最小可能的写延迟。
假设,如我们刚才建议的,你能隔离每个数据库日志文件在特定的磁盘阵列,至少对于那些有最大I/O工作量的数据库,对于这些阵列是可以使用更昂贵的RAID 1 + 0,对于更小I/O工作量的数据库可以使用RAID 5或RAID 1。
了解下不同RAID级别提供的I/O性能的情况,邪猎的3个可用配置是针对进行混合随机读写操作性能平衡的400G的数据库,对于SQL Server,连同理论上的I/O输出率,基于64K的随机I/O工作量。
- RAID 1使用1个15K RPM的600G硬盘=>11.5MB/秒,185 IOPS
- RAID 5使用5个15K RPM的146G硬盘=>22MB/秒,345 IOPS
- RAID 1 0使用14个15K RPM的73G硬盘=>101M/秒,1609 IOPS
请注意,这些值都是理论上的,在给出配置里尽基于硬盘的潜在I/O工作量。不考虑其他可能因素,对全局的工作量的影响,包括RAID控制器缓存大小和配置,RAID条带大小,硬盘分区对齐,NTF格式分配单元大小。确保你选择硬盘配置的唯一方法要处理好工作量位置,即对你的数据库的I/O子系统进行合适的基准验证,尤其是使用率。
对SQL Server进行存储配置基准验证
对给出的配置有很多现存的工具进行I/O输出的衡量,最常用的工具是SQLIO和IOmeter。另外,还有SQLIOSim,用来测试磁盘配置的可靠性和完整性。
日志碎片和读取日志操作
如第2篇所谈的,在内部SQL Server把日志文件分割为多个子文件,即所谓的虚拟日志文件(VLF)。对于一个日志文件,在创建时,SQL Server决定分配给它的VLF的个数的大小,每次日志增加时,然后增加决定好的VLF个数,基于自动增长率的大小,如下所示(尽管对于很小的增长率,有时候增加的VLF会小于4个):
- 小于64MB——每次自动增加会创建4个新的VLF
- 64MB至1GB——8个VLF
- 大于1GB——16个VLF
例如,如果我们创建一个64MB的日志文件,设置增长率是16MB,那么日志文件初始会有8个VLF,每个8MB大小,每次日志增长时,SQL Server会增加4个VLF,每个4MB大小。如果数据库吸引了比预期更多的用户,但是文件设置还是保持不变,当日志增长到10GB大小,增长了640倍时,会有超过2500个VLF。
另一方面,如果日志16GB大小,那么每次增长会增加16个VLF,每个1GB大小。使用大的VLF,我们会占用日志的大部分,SQL Server不能截断,如果一些因素进一步延迟截断,意味这日志还要增长,增长得更快。
秘诀是保持正确的平衡。推荐的最大增长大小是8GB(Paul Randal在他的《日志文件内部和维护》视频里建议的)。相反的,增长率必须足够大来避免不合理太多的VLF个数。
有2个主要原因来避免频繁小的日志增长。一个如在第7篇里谈到的,日志文件不能获得即时文件初始化的优势,因此在资源来说,和数据文件增长比,日志增长会相对昂贵。另一个是碎片日志会妨碍读取日志操作的性能。
很多操作会需要读取事务日志,包括:
- 完整,差异和日志备份——尽管只有后来会读取大量的日志部分。
- 故障恢复过程——为了保持数据和日志的一致性,撤销任何没有提交的事务,重做任何已经提交,写入日志但没有写入数据文件的事务(参考第1篇)
- 事务复制——当从发布者到订阅者移动修改时,事务复制日志阅读器读取日志
- 数据库镜像——在镜像数据库上,当从主到镜像传送最近的改变时,日志会被读取
- 创建数据库快照——在运行故障恢复过程时需要读取日志
- DBCC CHECKDB——当它运行时会创建数据库快照
- 修改数据抓取——使用事务复制日志阅读起来跟踪数据修改
最后,在一个日志文件里多少个VLF才合适的问题取决与日志的大小。通常,微软认为超过200个VLF可能会有问题,但在一个非常大的日志文件(例如500GB)只有200个VLF也会是个问题,VLF太大,限制了空间重用。
为了了解在日志读取时,碎片日志大小的影响,我们会运行一些测试,来看看在广泛阅读日志的两个过程的影响,即日志备份和故障恢复过程。
免责申明
接下来的测试无法反应现实中在服务器级别硬件上运行的多用户数据库,上面有特定的RAID配置等等。我们在安装在虚拟机上,独立的SQL Server 2008实例上运行。你的数据会不同,在速度慢的硬盘上测试效果会更明显。我们只想简单的演示下日志碎片问题的影响,还有如何调查这些潜在影响的方法。
最后注意,Linchi Shea已经演示了一个只有16个VLF和2000个VLF之间,数据修改性能上的影响。
日志备份影响
为了了解在日志备份上,碎片日志影响的大小,我们会创建PersonsLots数据库,故意创建一个小的2M日志文件,强制它在非常小的增长率来创建特别的碎片日志。我们会插入一些数据,运行大的更新来生成很多日志记录,然后运行日志备份来看看会花多少时间。然后我们在预制好正确大小的日志文件进行同样的测试。
首先,我们创建PersonsLots数据库,日志文件只有2M大小,自动增长率是2MB。
1 /* 2 mdf: initial size 195 MB, 16 MB growth 3 ldf: initial size 2 MB, 2 MB growth 4 */ 5 6 USE master 7 GO 8 IF DB_ID('PersonsLots') IS NOT NULL 9 DROP DATABASE PersonsLots; 10 GO 11 12 -- Clear backup history 13 EXEC msdb.dbo.sp_delete_database_backuphistory @database_name = N'PersonsLots' 14 GO 15 16 CREATE DATABASE [PersonsLots] ON PRIMARY 17 ( NAME = N'PersonsLots' 18 , FILENAME = N'C:SQLDataPersonsLots.mdf' 19 , SIZE = 199680KB 20 , FILEGROWTH = 16384KB 21 ) 22 LOG ON 23 ( NAME = N'PersonsLots_log' 24 , FILENAME = N'D:SQLDataPersonsLots_log.ldf' 25 , SIZE = 2048KB 26 , FILEGROWTH = 2048KB 27 ) 28 GO 29 30 ALTER DATABASE PersonsLots SET RECOVERY FULL; 31 32 USE master 33 GO 34 BACKUP DATABASE PersonsLots 35 TO DISK ='D:SQLBackupsPersonsLots_full.bak' 36 WITH INIT; 37 GO 38 39 DBCC SQLPERF(LOGSPACE) ; 40 --2 MB, 15% used 41 USE Persons 42 GO 43 DBCC LOGINFO; 44 -- 4 VLFs
代码8.4:创建PersonsLots数据库
现在我们在很小的增长率里进行日志增长,如代码8.5所示,为了创建特别的碎片日志文件。
1 DECLARE @LogGrowth INT = 0; 2 DECLARE @sSQL NVARCHAR(4000) 3 WHILE @LogGrowth < 4096 4 5 BEGIN 6 7 SET @sSQL = 'ALTER DATABASE PersonsLots MODIFY FILE (NAME = PersonsLots_log, SIZE = ' + CAST(4096+2048*@LogGrowth AS VARCHAR(10)) + 'KB );' 8 EXEC(@sSQL); 9 SET @LogGrowth = @LogGrowth + 1; 10 END 11 USE PersonsLots 12 GO 13 DBCC LOGINFO 14 --16388 VLFs 15 16 DBCC SQLPERF (LOGSPACE); 17 -- 8194 MB, 6.3% full
代码8.5:对数据库PersonsLots创建非常大的碎片日志。
这里我们增长日志在4096增长率,总大小是8GB(4096+2048*4096KB)。日志增加了4096倍,每次增加4个VLF,移动有了4+(4096*4)=16388个VLF。
现在重新运行代码8.2来重建Persons表,但这次在PersonLots数据库,然后调整代码8.3来在表里插入100万条记录。现在我们将更新Person表来创建很多日志记录。取决于你机器配置,当你运行代码8.6时,你可以泡上一杯咖啡。
1 USE PersonsLots 2 GO 3 /* this took 6 mins*/ 4 DECLARE @cnt INT; 5 6 SET @cnt = 1; 7 8 WHILE @cnt < 6 9 BEGIN; 10 SET @cnt = @cnt + 1; 11 UPDATE dbo.Persons 12 SET Email = LEFT(Email + Email, 7000) 13 END; 14 15 DBCC SQLPERF(LOGSPACE) ; 16 --8194 MB, 67% used 17 DBCC LOGINFO; 18 -- 16388 VLFs
代码8.6:在Persons表上的一个大更新。
最后,我们可以进行一次日志备份看看会花多少时间。我们在备份代码后包含了注释掉的备份统计信息。
1 USE master 2 GO 3 BACKUP LOG PersonsLots 4 TO DISK ='D:SQLBackupsPersonsLots_log.trn' 5 WITH INIT; 6 7 /*Processed 666930 pages for database 'PersonsLots', file 'PersonsLots_log' on file 1. 8 BACKUP LOG successfully processed 666930 pages in 123.263 seconds (42.270 MB/sec).*/
代码8.7:PersonsLots的日志备份(碎片日志)
作为比较,我们重复同样的测试,但这次我们会仔细调整数据库日志大小,让它有合理的数目的大小合适的VLF。在代码8.8,我们重建Persons数据库,初始日志大小为2GB(16个VLF,每个128M大小)。然后我们人为增长日志,只有3步就到8GB大小,包含64个VLF(每个128M的大小)。
1 USE master 2 GO 3 IF DB_ID('Persons') IS NOT NULL 4 DROP DATABASE Persons; 5 GO 6 7 CREATE DATABASE [Persons] ON PRIMARY 8 ( NAME = N'Persons' 9 , FILENAME = N'C:SQLDataPersons.mdf' 10 , SIZE = 2097152KB 11 , FILEGROWTH = 1048576KB 12 ) 13 LOG ON 14 ( NAME = N'Persons_log' 15 , FILENAME = N'D:SQLDataPersons_log.ldf' 16 , SIZE = 2097152KB 17 , FILEGROWTH = 2097152KB 18 ) 19 GO 20 USE Persons 21 GO 22 DBCC LOGINFO; 23 -- 16 VLFs 24 25 USE master 26 GO 27 ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 4194304KB ) 28 GO 29 -- 32 VLFs 30 31 ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 6291456KB ) 32 GO 33 -- 48 VLFs 34 35 ALTER DATABASE Persons MODIFY FILE ( NAME = N'Persons_log', SIZE = 8388608KB ) 36 GO 37 -- 64 VLFs 38 39 ALTER DATABASE Persons SET RECOVERY FULL; 40 41 USE master 42 GO 43 BACKUP DATABASE Persons 44 TO DISK ='D:SQLBackupsPersons_full.bak' 45 WITH INIT; 46 GO
代码8.8:创建Persons数据库并人为增长日志。
现在重新运行代码8.2,8.3(有100万条记录)和8.6和我们刚才测试的一样。你会发现,没有发生日志增长。
代码8.6运行得很快(在我们的测试里,只要一半的时间)。最后,重新运行日志备份。
1 USE master 2 GO 3 BACKUP LOG Persons 4 TO DISK ='D:SQLBackupsPersons_log.trn' 5 WITH INIT; 6 7 /*Processed 666505 pages for database 'Persons', file 'Persons_log' on file 1. BACKUP LOG successfully processed 666505 pages in 105.706 seconds (49.259 MB/sec). 8 */
代码8.9:Persons数据库的日志备份(无碎片日志)
在日志备份的影响相对小,对这个大小的日志是可复写的,与只有64个的,14292个VLF的日志,备份时间有近15-20%的增长,当然,这个是相对于小数据库(固然有很严重的日志碎片)。
故障恢复影响
在这些测试里,我们调查在故障恢复上碎片的影响,因为这个过程需要SQL Server读取活动日志,重做或撤销需要的日志记录来返回数据库到一致的状态。
大量重做
在第一个例子里,我们重用PersonsLots数据库,删除并重建,设置恢复模式为完整,进行完整备份然后插入100万条记录,如刚才所示代码。
现在,在我们更新这些行前,我们将禁止自动化检查点。
绝不禁止自动化检查点!
这里我们这样做纯粹是测试为目的。在任何正常运行的SQL Server数据库里我们绝不推荐禁止自动化检查点。
当我们提交随后的更新时,我们立即关闭数据库,这样的话,所有的更新已经写入日志但没有写入数据文件。因此,在故障恢复期间,SQL Server会需要读取所有相关的日志来重做所有的操作。
1 USE PersonsLots 2 Go 3 /*Disable Automatic checkpoints*/ 4 DBCC TRACEON( 3505 ) 5 6 /*Turn the flag off once the test is complete!*/ 7 --DBCC TRACEOFF (3505) 8 9 /* this took 5 mins*/ 10 BEGIN TRANSACTION 11 DECLARE @cnt INT; 12 13 SET @cnt = 1; 14 15 WHILE @cnt < 6 16 BEGIN; 17 SET @cnt = @cnt + 1; 18 UPDATE dbo.Persons 19 SET Email = LEFT(Email + Email, 7000) 20 END; 21 22 DBCC SQLPERF(LOGSPACE) ; 23 --11170 MB, 100% used 24 USE PersonsLots 25 GO 26 DBCC LOGINFO; 27 -- 22340 VLFs
代码8.10:PersonsLots——禁止自动化检查点,在显性事务里运行更新。
现在我们提交事务,关闭数据库。
1 /*Commit and immediately Shut down*/ 2 COMMIT TRANSACTION; 3 SHUTDOWN WITH NOWAIT
代码8.11:提交事务,关闭SQL Server
在重启SQL Server服务后,在恢复期间,尝试访问PersonsLots,你会看到如下信息。
1 USE PersonsLots 2 Go 3 /*Msg 922, Level 14, State 2, Line 1 4 Database 'PersonsLots' is being recovered. Waiting until recovery is finished.*/
代码8.12:PersonsLots正在进行恢复操作。
在SQL Server开始恢复数据库前,它需要打开日志,读取每个VLF。因为多个VLF的影响会延伸到SQL Server重启数据库和开始恢复过程之间的时间。
因此,一旦数据库是可访问的,我们可以查看这2个事件之间的错误日志,即总的恢复时间。
1 EXEC sys.xp_readerrorlog 0, 1, 'PersonsLots' 2 3 /* 4 2012-10-03 11:28:14.240 Starting up database 'PersonsLots'. 5 2012-10-03 11:28:26.710 Recovery of database 'PersonsLots' (6) is 0% 6 complete (approximately 155 seconds remain). 7 2012-10-03 11:28:33.000 140 transactions rolled forward in database 8 'PersonsLots' (6). 9 2012-10-03 11:28:33.010 Recovery completed for database PersonsLots 10 (database ID 6) in 6 second(s) 11 (analysis 2238 ms, redo 4144 ms, undo 12 ms.) 12 */
代码8.13:对PersonsLots信息进行错误日志查看。
在SQL Server启动数据库和开始恢复进程之间有近12.5秒。这是为什么会看到数据库列为“in recovery(在恢复中)”,在错误日志里没有看到任何初始恢复信息。恢复进程在7秒内完成。注意,在这三个恢复阶段,SQL Server花费更多的时间在重做。
现在让我们对Persons数据库(预制日志文件大小)重做同样的测试。
1 USE Persons 2 Go 3 /*Disable Automatic checkpoints*/ 4 DBCC TRACEON( 3505 ) 5 --DBCC TRACEOFF (3505) 6 7 USE Persons 8 Go 9 BEGIN TRANSACTION 10 DECLARE @cnt INT; 11 12 SET @cnt = 1; 13 14 WHILE @cnt < 6 15 BEGIN; 16 SET @cnt = @cnt + 1; 17 UPDATE dbo.Persons 18 SET Email = LEFT(Email + Email, 7000) 19 END; 20 21 DBCC SQLPERF(LOGSPACE) ; 22 -- 12288 MB, 87.2% used 23 USE Persons 24 GO 25 DBCC LOGINFO; 26 -- 96 VLFs 27 28 /*Commit and immediately Shut down*/ 29 COMMIT TRANSACTION; 30 SHUTDOWN WITH NOWAIT
代码8.14:Persons:禁用自动化检查点,运行并提交显式事务,关闭SQL Server。
最后,我们再次查看错误日志,看下这2个之间的时间,即总的恢复时间。
1 EXEC sys.xp_readerrorlog 0, 1, 'Persons' 2 3 /* 4 2012-10-03 11:54:21.410 Starting up database 'Persons'. 5 2012-10-03 11:54:21.890 Recovery of database 'Persons' (6) is 0% 6 complete (approximately 108 seconds remain). 7 2012-10-03 11:54:30.690 1 transactions rolled forward in database 8 'Persons' (6). 9 2012-10-03 11:54:30.710 Recovery completed for database Persons 10 (database ID 6) in 3 second(s) 11 (analysis 2177 ms, redo 1058 ms, undo 10 ms.) 12 */
代码8.15:对于Persons信息查看错误日志。
注意这次在SQL Server启动数据库和开始恢复的时间小于0.5秒。恢复过程只花了9秒。
注意在这些测试中,我们并没有创建其他一样的情形,除日志碎片外。对于开始,对于碎片日志数据库,恢复过程前滚了140个事务,在第2个测试中,只前滚了1个。
不管怎样,从测试里可以看出碎片日志会明显延迟数据库的实际恢复过程,在SQL Server读取所有VLF时。
大量撤销
作为另一个例子,我们可以执行我们长的更新事务,运行检查点然后关闭SQL Server,让事务未提交,来看看SQL Server会花多长时间来恢复数据库,首先当日志是碎片时,然后当不是时。在每个情况里,这会强制SQL Server进行大量撤销来进行恢复,我们来看下影响,内部是否有任何碎片日志。
对于这些测试我们不展示完整代码了,因为和刚才的代码基本一致。
1 /* (1) Recreate PersonsLots, with a fragmented log (Listing 8.4 and 8.5) 2 (2) Create Persons table, Insert 1 million rows (Listings 8.2 and 8.3) 3 */ 4 5 BEGIN TRANSACTION 6 7 /* run update from listing 8.6*/ 8 9 /*Force a checkpoint*/ 10 CHECKPOINT; 11 12 /*In an second session, immediately Shutdown without commiting*/ 13 SHUTDOWN WITH NOWAIT
代码8.16:在PersonsLot上测试“大量撤销”(碎片日志)
对Persons数据库运行同个测试(代码8.8,8.2,8.3,8.16),代码8.17展示了每个数据库结果的错误信息。
1 /* 2 PersonsLots (fragmented log) 3 4 2012-10-03 12:51:35.360 Starting up database 'PersonsLots'. 5 2012-10-03 12:51:46.920 Recovery of database 'PersonsLots' (17) is 0% 6 complete (approximately 10863 seconds remain). 7 2012-10-03 12:57:12.680 1 transactions rolled back in database 8 'PersonsLots' (17). 9 2012-10-03 12:57:14.680 Recovery completed for database PersonsLots 10 (database ID 17) in 326 second(s) 11 (analysis 30 ms, redo 78083 ms, undo 246689 ms.) 12 13 Persons (non-fragmented log) 14 15 2012-10-03 13:21:23.250 Starting up database 'Persons'. 16 2012-10-03 13:21:23.740 Recovery of database 'Persons' (6) is 0% 17 complete (approximately 10775 seconds remain). 18 2012-10-03 13:26:03.840 1 transactions rolled back in database 19 'Persons' (6). 20 2012-10-03 13:26:03.990 Recovery completed for database Persons 21 (database ID 6) in 279 second(s) 22 (analysis 24 ms, redo 57468 ms, undo 221671 ms.) 23 */
代码8.17:对于PersonsLot和Person数据库启动和恢复信息的错误日志
对于PersongsLots数据库启动和开始恢复进程之间的延迟是11秒,Person只有0.5秒。
在这些撤销例子里,和刚才重做例子比,整个恢复时间更长。对于PersonsLots,总恢复时间是326秒,没有碎片日志的Person只有279秒。
修正日志大小
我们希望这篇文章里,刚才的例子已经清楚演示了事务日志文件太小是个非常坏的做法,那样的话会允许在小增长率里增长。另外从model数据库继承下来的自动增长设置也是个非常坏的做法,这会允许当前事务日志大小以10%的步骤增长,
因为:
- 初始化时,当日志文件是小时,增长率增长会是小的,导致在日志里创建了大量的小的VLF,引起刚才谈到的碎片问题。
- 当日志文件很大时,增长增长会相应的大,在初始化期间,事务日志需要归零,大的增长会花费时间,如果日志不能增长的足够快,这会导致9002错误(事务日志满),即使在自动增长超时并回滚。
避免日志过分增长和日志碎片的方法是对日志(和数据)文件设置正确的初始大小,满足当前的需求,并预计未来的增长情况。
理想上,做了这些,日志会从不增长,这并不说我们应该禁用自动增长功能。这肯定是个安全机制,我们应该正确设置日志的合适大小,这样的话我们不会完全依赖控制日志增长的自动增长。我们可以配置自动增长为固定大小来允许日志文件快速增长,如果必要的话,对每个增长事件会最小化SQL Server增加到日志文件的VLF数。如刚才谈到的,自动增长事件非常昂贵,因为有0初始化。为了在自动增长期间最小化超时发生的几率,可以通过不同的大小设置衡量下事务日志增长所需要的时间,数据库在正常工作量下运行,基于当前I/O子系统的配置,这是个很好的做法。
因此,我们如何正确调整大小?这个问题并不简单。在例如“日志应该至少是数据库大小的25%”这样的建议后并没有逻辑可言。我们必须直接基于下列考虑条件跟踪日志增长来选择合理的大小:
- 日志必须足够大可以容下最大的单条事务。例如最大索引重建。这意味着日志必须大于数据库里最大的索引,允许记录在完整恢复下重建索引,并且足够大容下可能同时大事务运行的所有活动。
- 日志大小必须对在日志备份间生成的日志负责(例如30分钟,或者1个小时)。
- 日志大小必须对任何延误事务的进程负责。例如复制,日志读取器代理作业会一小时运行一次。
我们还要记住日志预留因素。当记录事务时,日志子系统预留空间保证日志回滚时不会用完空间。这样的话,需要的日志空间比操作的日志记录的总大小要大。
简单来说,回滚操作记录补偿日志记录(compensation log record),如果回滚用完了日志空间,SQL Server会标记数据库为可疑。这个日志注册不是实际“使用的”日志空间,这是必须保留可用的空间量,但如果日志填充到点(已用空间+保留空间=日志大小)它会触发自动增长事件,会被标记为已用空间,用于DBCC SQLPERF(LOGSPACE)。
因此,可用通过DBCC SQLPERF(LOGSPACE)来查看可用空间,在事务提交后,即使数据库在完整恢复模式,没有日志备份已运行。为了验证这个,我们需要完整恢复模式的数据库,表有50000条记录。
1 BACKUP LOG Persons 2 TO DISK='D:SQLBackupsPersons_log.trn' 3 WITH INIT; 4 5 -- start a transaction 6 BEGIN TRANSACTION 7 8 DBCC SQLPERF(LOGSPACE) 9 /*LogSize: 34 MB ; Log Space Used: 12%*/ 10 11 -- update the Persons table 12 UPDATE dbo.Persons 13 SET email = ' __ ' 14 15 DBCC SQLPERF(LOGSPACE) 16 /*LogSize: 34 MB ; Log Space Used: 87%*/ 17 18 COMMIT TRANSACTION 19 20 DBCC SQLPERF(LOGSPACE) 21 /*LogSize: 34 MB ; Log Space Used: 34%*/
代码8.18:日志保留测试。
注意日志空间使用率从87%掉到34%,即使这是个完整恢复模式的数据库,事务提交后没有日志备份。SQL Server在这个情况下没有截断日志,仅仅在事务提交后,释放了保留的日志空间。
已经设置了初始日志大小,基于这些需求,设置了合理的自动增长机制,监控下日志使用更加明智,对于日志自动增长事件设置警告,因为,如果我们已经正确做好我们的工作,日志增长会很少见。第9篇会详细讨论日志监控。
如果出问题要做什么
在这个最后的部分里,我们谈下暴涨和碎片化日志文件的正确处理方法。或许数据库最近才被我们关注;我们发现一些监控异常,并意识到日志已经近满,磁盘上已经没有空间进行紧急的索引维护操作。我们尝试日志备份,但基于某些原因我们要进一步调查(查看第7篇),SQL Server不会截断日志。为了赢得点时间,我们增加第2个日志文件,在独立的硬盘上,操作如期继续。
我们调查为什么日志大小会暴涨,原因是一个程序在数据库里留下了“孤立的事务”。这个问题修正后,接下来日志备份会截断日志,创造大量可重用空间。
下个问题是接下来做什么?现在我们的数据库有多个日志文件,主日志文件已经满了且有大量的碎片。
第一点我们想要的是尽快甩掉第2个日志文件。如刚才所说,有多个日志文件并没有性能上的优势,现在已经不需要了,它真的会降低任何还原操作,因为爱完整和差异还原操作期间,SQL Server需要0初始化掉日志。
运行代码8.4重建PersonsLots数据库,接下来运行代码8.2和8.3来创建和插入数据到Persons表(文末有完整代码)
我们假设,在这一点,DBA增加第2个3G的日志文件来容纳数据库维护操作。
1 USE master 2 GO 3 ALTER DATABASE PersonsLots 4 ADD LOG FILE ( NAME = N'PersonsLots_Log2', 5 FILENAME = N'D:SQLDataPersons_lots2.ldf' , SIZE = 3146000KB , FILEGROWTH = 314600KB ) 6 GO
代码8.19:增加3GB的日志文件到PersonsLots
等下,我们会解决延迟日志截断的问题,现在在第一个日志文件里有足够的可用空间,我们已经不再需要第2个日志文件,但它是存在的,我们来还原PersonsLots数据库。
1 USE master 2 GO 3 RESTORE DATABASE PersonsLots 4 FROM DISK ='D:SQLBackupsPersonsLots_full.bak' 5 WITH NORECOVERY; 6 7 RESTORE DATABASE PersonsLots 8 FROM DISK='D:SQLBackupsPersonsLots.trn' 9 WITH Recovery; 10 11 /*<output truncated>… 12 Processed 18094 pages for database 'PersonsLots', file 'PersonsLots_log' on file 1. 13 Processed 0 pages for database 'PersonsLots', file 'PersonsLots_Log2' on file 1. 14 RESTORE LOG successfully processed 18094 pages in 62.141 seconds (2.274 MB/sec).*/
代码8.20:还原PersonsLots(有第2个日志文件)
还原花费了60秒。如果我们重复同样的步骤,但不增加第2个日志文件,相比而言,在我们的测试里,花了近8秒。
为了移除第2个日志文件,我们需要等待直到它已经不包含任何活动日志。因为我们的目标是移除它,我们可以收缩第2个日志文件文件为0(稍后会演示),对这个文件关闭自动增长,因为这会“鼓励”活动日志完全移回到第1个日志文件。这点非常重要:这不会移动任何在第2个日志文件里的记录到第1个日志文件。(有些人会这样认为,因为当我们收缩数据文件时,如果我们指定EMPTYFILE参数,SQL Server会移动数据到同个文件组里的另一个数据文件)。
一旦第2个日志文件没有包含任何活动日志,我们可以直接删除它。
1 USE PersonsLots 2 GO 3 ALTER DATABASE PersonsLots REMOVE FILE PersonsLots_Log2 4 GO
代码8.21:移除第2个日志文件。
这是解决的一个问题,但我们还是有暴涨和碎片话的主日志文件。在第7篇里我们就谈到,收缩日志文件不应该是我们标准维护操作,在我们这个情况下是可以,在理论上我们已经调查并解决了日志过度增长的原因,因此收缩日志应该是一次性的事件。
推荐的方法是使用DBCC SHRINKFILE来重获空间。如果我们不指定目标大小,或指定0作为目标大小,我们可以收缩日志到初始大小(在这个情况下是2MB)并最小化日志文件的碎片。如果初始日志初始大小很大,我们想收缩得更小,我们可以指定target_sise,例如1。
1 USE PersonsLots 2 GO 3 DBCC SHRINKFILE (N'PersonsLots_log' , target_size=0) 4 GO

代码8.22:收缩主日志文件(部分成功)
从这个命令的输出,我们看到当前数据库大小(24128*8 KB个页),收缩后的最小可能大小(256 * 8 KB个页)。这表示我们的收缩不会完全。SQL Server收缩日志到包含活动日志部分的最后一个VLF的位置点,然后停止了。检查下信息页:
1 /*Cannot shrink log file 2 (PersonsLots_log) because the logical log file located at the end of the file is in use. 2 3 (1 row(s) affected) 4 DBCC execution completed. If DBCC printed error messages, contact your system administrator.*/
进行日志备份然后再次尝试。
1 USE master 2 GO 3 BACKUP DATABASE PersonsLots 4 TO DISK ='D:SQLBackupsPersonsLots_full.bak' 5 WITH INIT; 6 GO 7 8 BACKUP LOG PersonsLots 9 TO DISK = 'D:SQLBackupsPersonsLots.trn' 10 WITH init 11 12 USE PersonsLots 13 GO 14 DBCC SHRINKFILE (N'PersonsLots_log' , 0) 15 GO

代码8.23:日志备份后收缩主日志文件。
做完这个后,现在我们可以人为调整日志到需要的大小,如刚才代码8.8所示。
小结
我们从会影响日志吞吐量的物理架构因素的简述开始,例如需要分离日志文件I/O到各自的阵列,为这些阵列选择最优的RAID级别。
这篇文章然后强调管理事务日志增长的必要性,而不是让SQL Server的自动增长事件为我们管理。如果初始日志太小,然后让SQL Server自动在小量的增长,我们会有大量的碎片日志。在这篇文章的日志里演示了它会如何影响需要读取日志的任何SQL Server操作。
最后,我们讨论了决定正确日志大小的因素,对一个给出的数据库修正了自动增长率,我们提供了如何恢复有多个日志文件的数据库到一个日志文件,并重新调整日志文件的大小和碎片。
下一篇文章,这个系列文章的最后一篇,我们会介绍监控日志活动、吞吐量和碎片的各个不同工具和技术。
扩展阅读
致谢
非常感谢Jonathan Kehayias,为本文提供RAID部分内容。
(博主注:也非常感谢您这么耐心看完这篇文章,最近博主非常忙,原计划上个月就应该更新这篇文章,现在才完成,新的一年,欢迎大家和我继续前行!)