1.Hive的分区表操作
Hive开发中,在存储数据时,为了更快地查询数据和更好地管理数据,都会对hive表中数据进行分区存储;所谓的分区,在hive表中体现的是多了一个字段;而在底层文件存储系统中,比如HDFS上,分区则是一个文件夹,或者说是一个文件目录,不同的分区,就是数据存放在根目录下的不同子目录里,可以通过show partitions查看;
hive分区分为静态分区和动态分区;
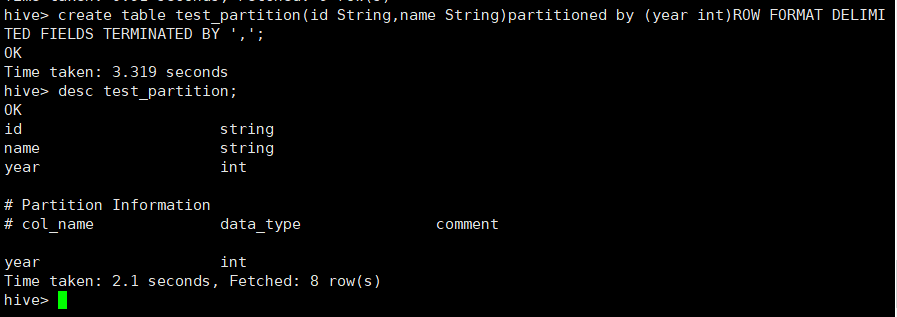
(1)创建分区表:静态分区和动态分区的建表语句一致;
create table test_partition(id String,name String)partitioned by (year int)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
(2)插入语句:由于静态分区和动态分区的插入语句不一样,所以分开了;
1.1 静态分区
在语句中指定分区字段为某个固定值
1.1.1 insert语句:
insert into table test_partition partition(year=2018) values('001','zhangsan');
insert into table test_partition partition(year=2018) values('001','张三');
insert into table test_partition partition(year=2018) values('002','李四');
1.1.2 load语句:
load data local inpath '/opt/module/hive/data/test_partition' into table test_partition partition(year=2018);
load data local inpath '/opt/module/hive/data/test_partition' into table test_partition partition(year=2018);
load data local inpath '/opt/module/hive/data/test_partition' into table test_partition partition(year=2017);
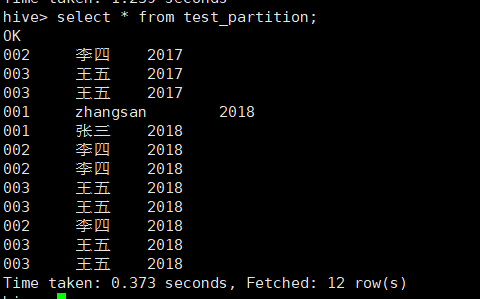
1.1.3 查看表数据:
select * from test_partition;
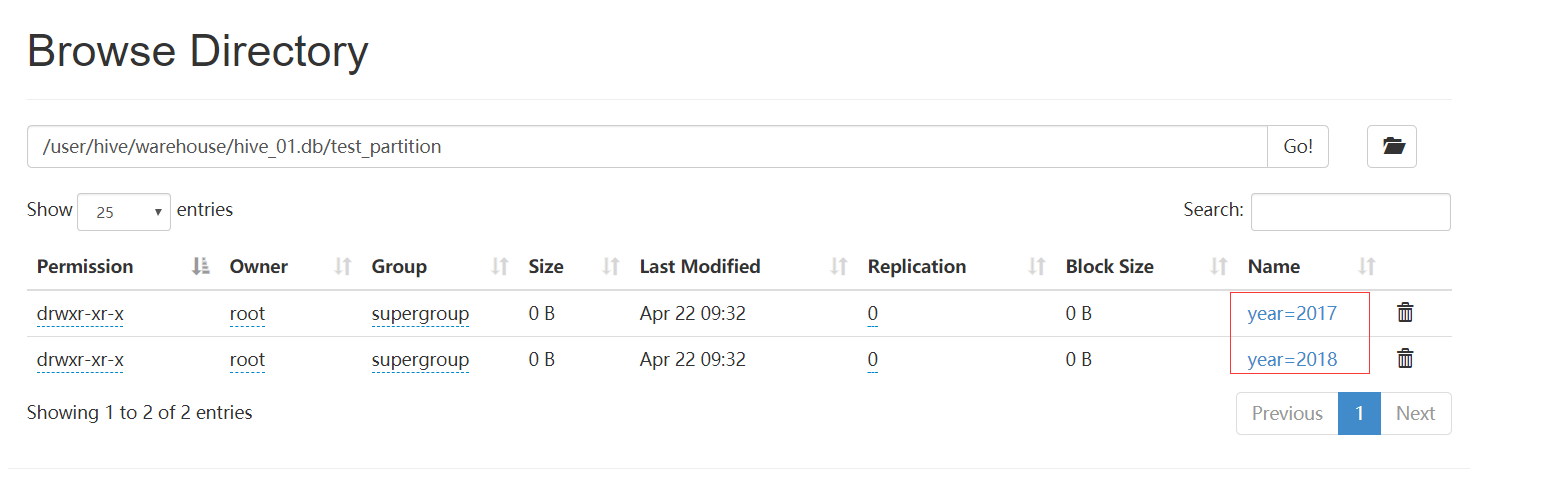
1.1.4 HDFS的存储形式:
1.2 动态分区
1.2.1 动态分区默认不开启,需要使用下列语句开启:(需退出hive,重新进入执行)
set hive.exec.dynamici.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.mode.local.auto=true;
SET hive.exec.max.dynamic.partitions=100000;
SET hive.exec.max.dynamic.partitions.pernode=100000;
set hive.exec.max.created.files=100000;
1.2.2 insert语句插入数据:
insert into table test_partition partition(year) values('001','张三',2016);
1.2.3 load语句插入:
load data local inpath '/opt/module/hive/data/test_partition' into table test_partition pattition(year);
在这里执行会出现错误,如下解决方案:
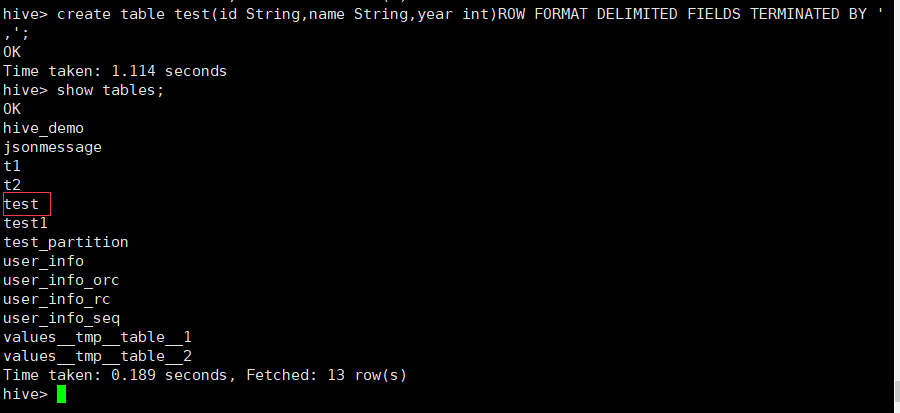
创建一张没有分区的表:
create table test(id String,name String,year int)ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
将数据载入到没有分区的表中:

load data local inpath '/opt/module/hive/data/test' into table test;
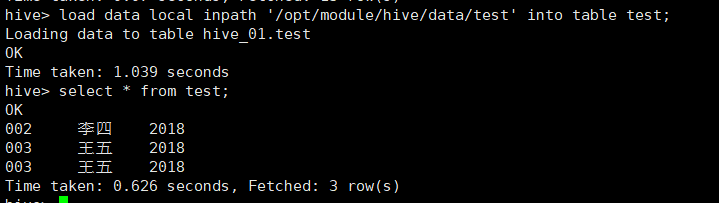
然后从表test,动态分区的插入到test_partition表中:
insert into table test_partition partition(year) select * from test;

1.3 总结
静态分区中的数据需要手动指定,当分区的值很多的情况下,就要不停的使用insert语句进行显示指定;
动态分区可以通过select语句实现数据的一次性导入,而且可以通过数据源中不同分区列的值动态的生成响应的目录,并把对应的数据写入对应目录中;
简单的来说:静态分区是给与固定的值,而动态分区可实现分区数据的动态指定;
1.4 分区的其他操作
1.4.1 修改分区
语法:Alter table 表名 partition (分区列=分区值) set location 新分区地址;
注意:此时原先的分区文件夹仍存在,但是在往分区添加数据时,只会添加到新的分区目录;
1.4.2 删除分区
语法:Alter table 表名 drop partition(分区列=分区值);
alter table test_partition drop partition(year='2017');

2.分桶表
2.1 分桶表描述
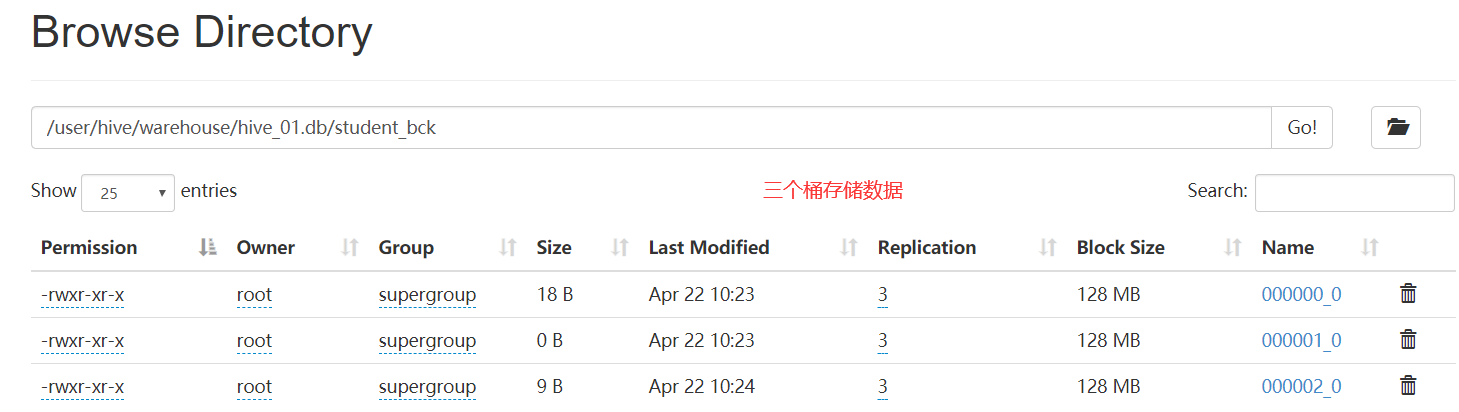
分桶是相对分区进行更细粒度的划分;分桶将整个数据内容按照某列属性值得hash值进行分区,如要按照name属性分为三个桶,就是对name属性值的hash值对三取模,按照取模结果对数据分桶;如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件;
2.2 创建分桶表
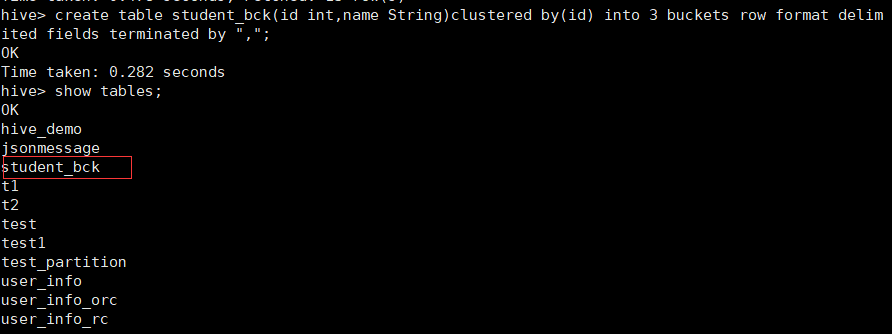
create table student_bck(id int,name String)clustered by(id) into 3 buckets row format delimited fields terminated by ",";
2.3 向桶中插入数据
insert overwrite table student_bck select id,name from test;
2.4 查看存储信息
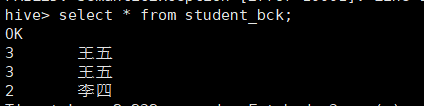
2.5 查看分桶数据
select * from student_bck;
3.Hive的连接方式
3.1 CLI连接
上面的hive命令相当于在启动的时候执行:hive --service cli
使用hive --help,可以查看hive命令可以启动那些服务
通过hive --service serviceName --help可以查看某个具体命令的使用方式;
3.2 HiveServer2/beeline
hive-2.3.3版本中:都需要对hadoop集群做如下改变,否则无法使用;
(1)编辑hadoop集群的hdfs-site.xml文件:
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
(2)编辑hadoop集群的core-site.xml文件,设置hdfs的代理用户:
<property> #此处的root必须与master主机用户名相同
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
(3)通过scp命令远程传递到hadoop103和hadoop104节点上:
scp hdfs-site.xml core-site.xml root@hadoop103:/opt/module/hadoop/etc/hadoop/
scp hdfs-site.xml core-site.xml root@hadoop104:/opt/module/hadoop/etc/hadoop/
(4)重启hadoop集群,并格式化NameNode节点:
(5)启动hiveserver2服务:
hiveserver2
以上方式基于前台线程启动hive服务,我们可以使用nohup命令基于后台启动;
nohup hiveserver2 1>/opt/module/hadoop/hiveserver.log 2>/opt/module/hadoop/hiveserver.err &
(6)启动beeline客户端去连接
方式1:
beeline #进入hive的客户端
!connect jdbc:hive2://master:10000 #设置连接URL
root #输入用户名 密码省略
方式2:直接连接
beeline -u 'jdbc:hive2://master:10000/hive_01' -n root