1.复杂的迭代计算
假如我们计算的需要100步的计算,但是当我执行到第99步的时候,突然数据消失,
根据血统,从头进行恢复,代价很高
sc.setCheckpointDir("共享存储文件系统的路径") //这些地址存储已经执行过的rdd
2.离线计算和实时计算
storm(实时计算) Flink -> Scala
spark-Streaming(实时计算,时效性低于storm,但吞吐量大)
kafka(消息队列,高吞吐),其实就相当于有很多数据源过来,但是如果一时处理不过来,则此时
我们就需要一个消息队列,让一部分先进行等待,其实就跟线程的任务队列差不多
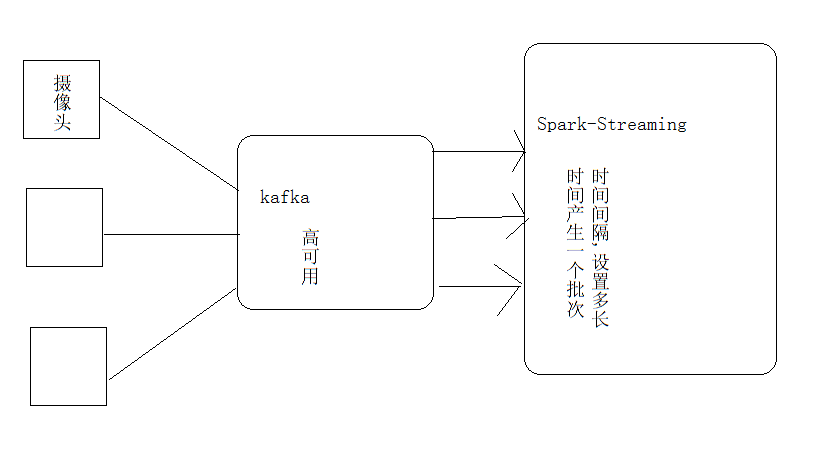
spark-streaming其实就是一个个连续的rdd
3.spark-streaming的操作
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>${spark.version}</version>
</dependency>