下文的原文来自: http://blog.csdn.net/preterhuman_peak/article/details/40857117
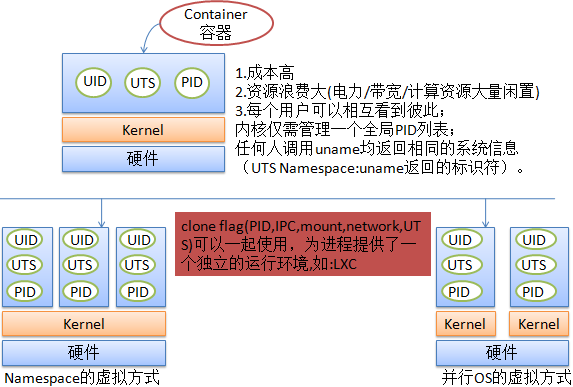
采用Namespace的方式
1.全局资源通过命名空间来抽象,将各种全局资源放入容器中,实现隔离,但在容器外将不能为这些全局资源提供唯一性的ID.
2.本质上,命名空间建立了系统的不同视图. 【注:命名空间就是一个容器.】
3.此前的每一项全局资源都必须包装到容器数据结构中,只有资源和包含资源的命名空间构成的二元组仍然是全局唯一的。
4.隔离可让容器间毫无关系,也允许容器间进行适度共享。
5. Chroot就是一种简单的容器隔离机制。
命名空间的实现需要两个部分:每个子系统的命名空间结构,将此前所有的全局组件包装到命名空间中;将给定进程关联到所属各个命名空间的机制。图 2说明了具体情形。
<nsproxy.h>
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns;
struct user_namespace *user_ns;
struct net *net_ns;
};
PID Namespace

当调用clone时,设定了CLONE_NEWPID,就会创建一个新的PID Namespace,clone出来的新进程将成为Namespace里的第一个进程。一个PID Namespace为进程提供了一个独立的PID环境,PID Namespace内的PID将从1开始,在Namespace内调用fork,vfork或clone都将产生一个在该Namespace内独立的PID。新创建的Namespace里的第一个进程在该Namespace内的PID将为1,就像一个独立的系统里的init进程一样。该Namespace内的孤儿进程都将以该进程为父进程,当该进程被结束时,该Namespace内所有的进程都会被结束。PID Namespace是层次性,新创建的Namespace将会是创建该Namespace的进程属于的Namespace的子Namespace。子Namespace中的进程对于父Namespace是可见的,一个进程将拥有不止一个PID,而是在所在的Namespace以及所有直系祖先Namespace中都将有一个PID。系统启动时,内核将创建一个默认的PID Namespace,该Namespace是所有以后创建的Namespace的祖先,因此系统所有的进程在该Namespace都是可见的。
IPC Namespace
当调用clone时,设定了CLONE_NEWIPC,就会创建一个新的IPC Namespace,clone出来的进程将成为Namespace里的第一个进程。一个IPC Namespace有一组System V IPC objects 标识符构成,这标识符有IPC相关的系统调用创建。在一个IPC Namespace里面创建的IPC object对该Namespace内的所有进程可见,但是对其他Namespace不可见,这样就使得不同Namespace之间的进程不能直接通信,就像是在不同的系统里一样。当一个IPC Namespace被销毁,该Namespace内的所有IPC object会被内核自动销毁。
PID Namespace和IPC Namespace可以组合起来一起使用,只需在调用clone时,同时指定CLONE_NEWPID和CLONE_NEWIPC,这样新创建的Namespace既是一个独立的PID空间又是一个独立的IPC空间。不同Namespace的进程彼此不可见,也不能互相通信,这样就实现了进程间的隔离。
注:
<1>Uinx IPC
IPC(Inter-Process Communication)是共享"命名管道"的资源,它是为了让进程间通信而开放的命名管道,通过提供可信任的用户名和口令,连接双方可以建立安全的通道并以此通道进行加密数据的交换,从而实现对远程计算机的访问。
Uinx IPC包含三种: 信号,命名管道和匿名管道.
<2> System V
System V和POSIX类似,但POSIX是专注于Linux系统设计的标准化.而System V和BSD则是UNIX设计标准化的一种范本.
System V它是AT&T公司开发的UNIX系统,是UNIX众多版本中的一种,AT&T共发行了4个版本,System V4是最成功的,它采用SysV初始化脚本(/etc/init.d)来控制启停系统,System V Interface Definition(SVID)是SystemV如何工作的标准定义.
System V IPC指的是AT&T在System V.2发行版中引入的三种进程间通信工具:
(1)信号量,用来管理对共享资源的访问
(2)共享内存,用来高效地实现进程间的数据共享
(3)消息队列,用来实现进程间数据的传递。
我们把这三种工具统称为System V IPC的对象,每个对象都具有一个唯一的IPC标识符(identifier)。要保证不同的进程能够获取同一个IPC对象,必须提供一个IPC关键字(IPC key),内核负责把IPC关键字转换成IPC标识符。
mount Namespace
当调用clone时,设定了CLONE_NEWNS,就会创建一个新的mount Namespace。每个进程都存在于一个mount Namespace里面,mount Namespace为进程提供了一个文件层次视图。如果不设定这个flag,子进程和父进程将共享一个mount Namespace,其后子进程调用mount或umount将会影响到所有该Namespace内的进程。如果子进程在一个独立的mount Namespace里面,就可以调用mount或umount建立一份新的文件层次视图。该flag配合pivot_root系统调用,可以为进程创建一个独立的目录空间。
Network Namespace
当调用clone时,设定了CLONE_NEWNET,就会创建一个新的Network Namespace。一个Network Namespace为进程提供了一个完全独立的网络协议栈的视图。包括网络设备接口,IPv4和IPv6协议栈,IP路由表,防火墙规则,sockets等等。一个Network Namespace提供了一份独立的网络环境,就跟一个独立的系统一样。一个物理设备只能存在于一个Network Namespace中,可以从一个Namespace移动另一个Namespace中。虚拟网络设备(virtual network device)提供了一种类似管道的抽象,可以在不同的Namespace之间建立隧道。利用虚拟化网络设备,可以建立到其他Namespace中的物理设备的桥接。当一个Network Namespace被销毁时,物理设备会被自动移回init Network Namespace,即系统最开始的Namespace。
UTS Namespace
当调用clone时,设定了CLONE_NEWUTS,就会创建一个新的UTS Namespace。一个UTS Namespace就是一组被uname返回的标识符。新的UTS Namespace中的标识符通过复制调用进程所属的Namespace的标识符来初始化。Clone出来的进程可以通过相关系统调用改变这些标识符,比如调用sethostname来改变该Namespace的hostname。这一改变对该Namespace内的所有进程可见。CLONE_NEWUTS和CLONE_NEWNET一起使用,可以虚拟出一个有独立主机名和网络空间的环境,就跟网络上一台独立的主机一样。
以上所有clone flag都可以一起使用,为进程提供了一个独立的运行环境。LXC正是通过clone时设定这些flag,为进程创建一个有独立PID,IPC,FS,Network,UTS空间的container。一个container就是一个虚拟的运行环境,对container里的进程是透明的,它会以为自己是直接在一个系统上运行的。一个container就像传统虚拟化技术里面的一台安装了OS的虚拟机,但是开销更小,部署更为便捷。
Linux Namespaces机制本身就是为了实现 container based virtualizaiton开发的。它提供了一套轻量级、高效率的系统资源隔离方案,远比传统的虚拟化技术开销小,不过它也不是完美的,它为内核的开发带来了更多的复杂性,它在隔离性和容错性上跟传统的虚拟化技术比也还有差距。
下面对Network Namespace在进行实践介绍:
测试拓扑:
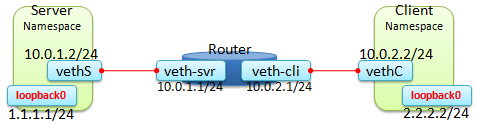
创建基本环境:
(1) 创建虚拟设备:
ip netns server #创建虚拟server设备,其实就是创建一个子network namespace.
ip netns router
ip netns client
# ip netns list #查看创建的Network namespace(虚拟设备)
router
server
client
(2) 创建虚拟接口并用虚拟网线将其连接:
# 注:这些虚拟接口默认被添加到默认network namespace中.
# 默认network namespace就是当前OS的network namespace,
# 它是所有其他network namespace的父命名空间(容器)。
ip link add vethS type veth peer name veth-srv
ip link add vethC type veth peer name veth-cli
ip link show |grep veth #查看创建的虚拟接口
(3) 将虚拟接口绑定到各虚拟设备上:
ip link set vethS netns server #将vethS绑定到Server上.
ip link set veth-srv netns router #将veth-srv绑定到Router上.
ip link set vethC netns client
ip link set veth-cli netns router
# 注:
ip netns exec <NetNamesapce_Name> <Command> #在指定Network Namespace中执行命令.
ip netns exec server ip link # 查看Server上绑定的接口状态.
11: lo: <LOOPBACK> mtu 16436 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
16: vethS: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 3a:0f:10:f6:09:eb brd ff:ff:ff:ff:ff:ff
ip netns exec router ip link # 查看Router上绑定的接口状态。
14: lo: <LOOPBACK> mtu 16436 qdisc noop state DOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
15: veth-srv: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether 2a:81:99:26:1c:15 brd ff:ff:ff:ff:ff:ff
17: veth-cli: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000
link/ether b6:2a:b8:16:d8:b8 brd ff:ff:ff:ff:ff:ff
# 这里vethS显示对端状态为DOWN.
(4) 为虚拟接口配置IP并启动接口
# 为虚拟Server的虚拟接口配置IP并启动
ip netns exec server ip addr add 10.0.1.2/24 dev vethS
ip netns exec server ip addr add 1.1.1.1/24 dev lo #给loopback接口配置IP
ip netns exec server ip link set dev vethS up #开启虚拟Server的vethS接口
ip netns exec server ip link set dev lo up
ip netns exec server ip a
11: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet 1.1.1.1/24 scope global lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
# 注: vethS这里需要注意:<...UP:此表示vethS当前已为活动状态>;
# state DOWN:表示对端当前为不活动,这是因为router还没配IP也没启动.
16: vethS: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000
link/ether 3a:0f:10:f6:09:eb brd ff:ff:ff:ff:ff:ff
inet 10.0.1.2/24 scope global vethS
# 为虚拟Router的虚拟接口配置IP并启动.
ip netns exec router ip addr add 10.0.1.1/24 dev veth-srv
ip netns exec router ip addr add 10.0.2.1/24 dev veth-cli
ip netns exec router ip link set dev veth-srv up
ip netns exec router ip link set dev veth-cli up
ip netns exec router sysctl -w net.ipv4.ip_forward=1 #开启Router的转发功能.以便模拟路由器.
# 为虚拟Client的虚拟接口配置IP并启动:
ip netns exec client ip addr add 10.0.2.2/24 dev vethC
ip netns exec client ip addr add 2.2.2.2/24 dev lo
ip netns exec client ip link set dev vethC up
ip netns exec client ip link set dev lo up
(5) 连通性测试
ip netns exec server ping -c 2 1.1.1.1 # Server 测试 ping环回口.
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=64 time=0.197 ms
ip netns exec server ping -c 2 10.0.1.1 # Server测试ping Router的直连接口
PING 10.0.1.1 (10.0.1.1) 56(84) bytes of data.
64 bytes from 10.0.1.1: icmp_seq=1 ttl=64 time=0.868 ms
ip netns exec client ping 10.0.2.1 # Client测试ping Router的直连接口
PING 10.0.2.1 (10.0.2.1) 56(84) bytes of data.
64 bytes from 10.0.2.1: icmp_seq=1 ttl=64 time=1.14 ms
ip netns exec client ping 10.0.1.1 #Client测试ping Server端,不通
connect: Network is unreachable
(6) 在虚拟Server和Client上添加默认路由:
# 上面测试可知Server和Client是无法到达彼此的,它们只能访问到直连的Router.
ip netns exec client route add default gw 10.0.2.1 #给Client添加默认路由,指向Router.
ip netns exec client ping 10.0.1.2 # 再次测试ping Server_IP,还是不通,这是因为Server不知道如何到达Client.
PING 10.0.1.2 (10.0.1.2) 56(84) bytes of data.
^C
ip netns exec server route add default gw 10.0.1.1 #给Server添加默认路由.
ip netns exec server ping 10.0.2.2 # 再次测试ping Client_IP 已经可以ping通.
PING 10.0.2.2 (10.0.2.2) 56(84) bytes of data.
64 bytes from 10.0.2.2: icmp_seq=1 ttl=63 time=3.11 ms
ip netns exec server ping 2.2.2.2 # 但ping Client的loopback接口还是不通.
PING 2.2.2.2 (2.2.2.2) 56(84) bytes of data.
From 10.0.1.1 icmp_seq=1 Destination Net Unreachable
(7) 为虚拟Router添加静态路由
#注: 指定到达1.1.1.0/24的网络从接口10.0.1.1发出。
ip netns exec router ip route add 1.1.1.0/24 via 10.0.1.1
ip netns exec router ip route add 2.2.2.0/24 via 10.0.2.1
ip netns exec router ip -s -s route list #显示虚拟Router上详细的路由表条目.
10.0.1.0/24 dev veth-srv proto kernel scope link src 10.0.1.1
2.2.2.0/24 via 10.0.2.1 dev veth-cli
10.0.2.0/24 dev veth-cli proto kernel scope link src 10.0.2.1
1.1.1.0/24 via 10.0.1.1 dev veth-srv
ip netns exec router route -n #或直接使用route命令来查看路由表
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.0.1.0 0.0.0.0 255.255.255.0 U 0 0 0 veth-srv
2.2.2.0 10.0.2.1 255.255.255.0 UG 0 0 0 veth-cli
10.0.2.0 0.0.0.0 255.255.255.0 U 0 0 0 veth-cli
1.1.1.0 10.0.1.1 255.255.255.0 UG 0 0 0 veth-srv
#再次从Server上测试
ip netns exec server ping 2.2.2.2
PING 2.2.2.2 (2.2.2.2) 56(84) bytes of data.
64 bytes from 2.2.2.2: icmp_seq=1 ttl=63 time=5.06 ms
ip netns exec client ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=63 time=1.87 ms
(8) 进一步测试SNAT.
# 注:上面是假设知道怎么去未知网络,因此采用了静态路由。
# 下面假设不知道怎么去未知网络,因此下面采用NAT的方式让Server访问到Client的2.2.2.0/24的网络。
《1》先删除Router添加的静态路由
ip netns exec router ip route del 1.1.1.0/24
ip netns exec router ip route del 2.2.2.0/24
《2》在Router上添加一条全局默认路由:
# 注:这里测试让Server可以ping 通Client的loopback接口.
# 另注: 默认路由一次只能加一个来测试.
ip netns exec router ip route add default scope global via 10.0.2.2
《3》在Router上添加一条iptables的SNAT规则:
ip netns exec router iptables -t nat -A POSTROUTING -s 10.0.1.0/24 -o veth-cli -j SNAT --to-source 10.0.2.1
《4》从Server上测试ping Client_Loopback_IP
ip netns exec server ping 2.2.2.2 -c 2
PING 2.2.2.2 (2.2.2.2) 56(84) bytes of data.
64 bytes from 2.2.2.2: icmp_seq=1 ttl=63 time=0.068 ms
ip netns exec server ip route #Server上的路由表
10.0.1.0/24 dev vethS proto kernel scope link src 10.0.1.2
default via 10.0.1.1 dev vethS
ip netns exec client ip route #Client上的路由表
10.0.2.0/24 dev vethC proto kernel scope link src 10.0.2.2
default via 10.0.2.1 dev vethC
ip netns exec router ip route #Router上的路由表
10.0.1.0/24 dev veth-srv proto kernel scope link src 10.0.1.1
10.0.2.0/24 dev veth-cli proto kernel scope link src 10.0.2.1
default via 10.0.2.2 dev veth-cli #这是在Router上添加的默认路由,出口是veth-cli.
ip netns exec router iptables -nL -v -t nat #Router上的SNAT规则查看.
Chain PREROUTING (policy ACCEPT 4 packets, 336 bytes)
pkts bytes target prot opt in out source destination
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
# 此为添加的SNAT规则
1 84 SNAT all -- * veth-cli 10.0.1.0/24 0.0.0.0/0 to:10.0.2.1
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
~]# ip netns exec router iptables -nL -vv -t nat
Chain PREROUTING (policy ACCEPT 4 packets, 336 bytes)
pkts bytes target prot opt in out source destination
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
1 84 SNAT all -- * veth-cli 10.0.1.0/24 0.0.0.0/0 to:10.0.2.1
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
libiptc vlibxtables.so.4. 800 bytes.
Table `nat'
Hooks: pre/in/fwd/out/post = 0/ffffffff/ffffffff/1d8/98
Underflows: pre/in/fwd/out/post = 0/ffffffff/ffffffff/1d8/140
Entry 0 (0):
SRC IP: 0.0.0.0/0.0.0.0
DST IP: 0.0.0.0/0.0.0.0
Interface: `'/................to `'/................
Protocol: 0
Flags: 00
Invflags: 00
Counters: 4 packets, 336 bytes
Cache: 00000000
Target name: `' [40]
verdict=NF_ACCEPT
Entry 1 (152):
SRC IP: 10.0.1.0/255.255.255.0
DST IP: 0.0.0.0/0.0.0.0
Interface: `'/................to `veth-cli'/XXXXXXXXX.......
Protocol: 0
Flags: 00
Invflags: 00
Counters: 1 packets, 86 bytes
Cache: 00000000
Target name: `SNAT' [56]
....... 下面内容省略。
(9) 清理测试环境
ip netns del server
ip netns del router
ip netns del client