MapReduce简介
- MapReduce是一种分布式计算模型,是Google提出的,主要用于搜索领域,解决海量数据的计算问题。
- MR有两个阶段组成:Map和Reduce,用户只需实现map()和reduce()两个函数,即可实现分布式计算。
MapReduce执行流程
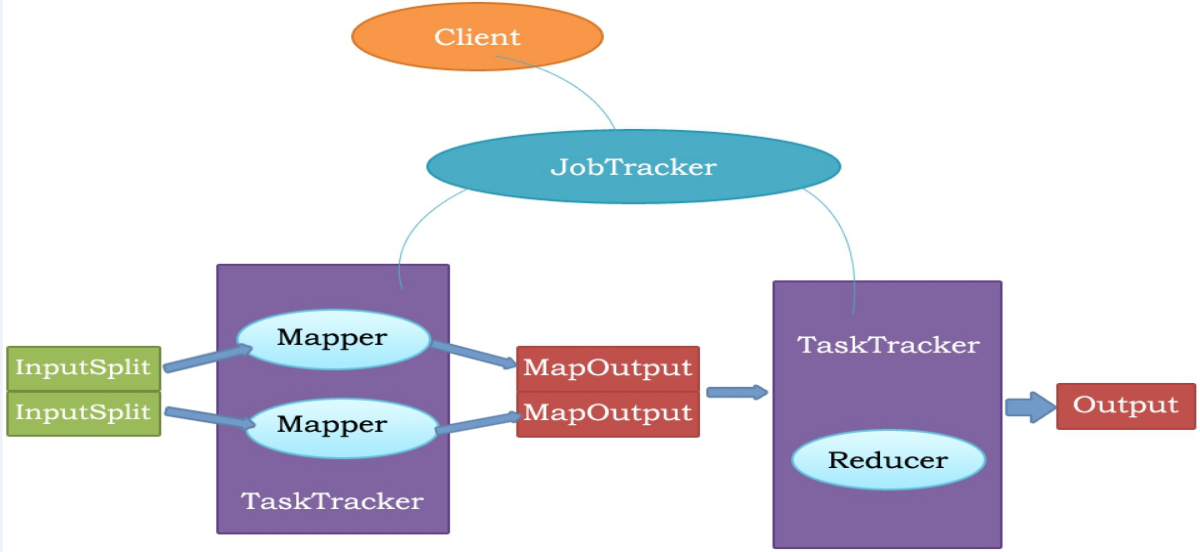
MapReduce原理
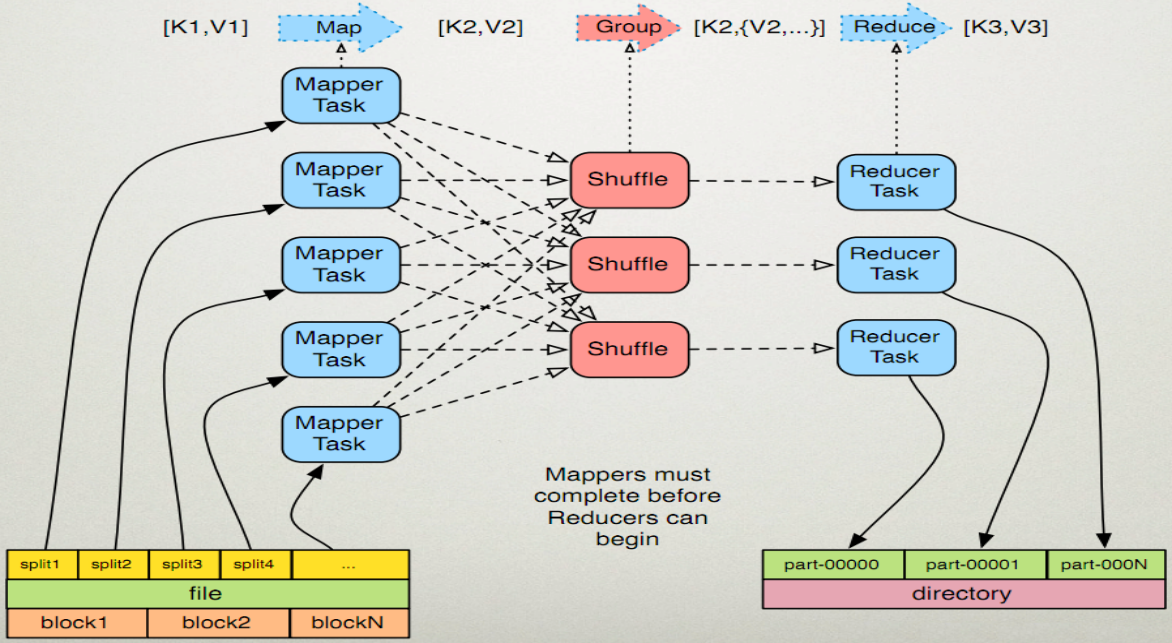
MapReduce的执行步骤:
1、Map任务处理
1.1 读取HDFS中的文件。每一行解析成一个<k,v>。每一个键值对调用一次map函数。 <0,hello you> <10,hello me>
1.2 覆盖map(),接收1.1产生的<k,v>,进行处理,转换为新的<k,v>输出。 <hello,1> <you,1> <hello,1> <me,1>
1.3 对1.2输出的<k,v>进行分区。默认分为一个区。
1.4 对不同分区中的数据进行排序(按照k)、分组。分组指的是相同key的value放到一个集合中。 排序后:<hello,{1,1}><me,{1}><you,{1}>
1.5 (可选)对分组后的数据进行归约。
2、Reduce任务处理
2.1 多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点上。
2.2 对多个map的输出进行合并、排序。覆盖reduce函数,接收的是分组后的数据,实现自己的业务逻辑, <hello,2> <me,1> <you,1>
处理后,产生新的<k,v>输出。
2.3 对reduce输出的<k,v>写到HDFS中。