1、问题描述:在页面上一些下载附件功能,点击触发执行下载操作时候,有些电脑的浏览器可以,有些电脑的浏览器下载不了,电脑打开弹出的下载框下载的不是一个文件,而是一个如jspx后缀名的页面,jspx后缀是访问的xhtml页面,显示的是一个代码返回的下载页面名称:
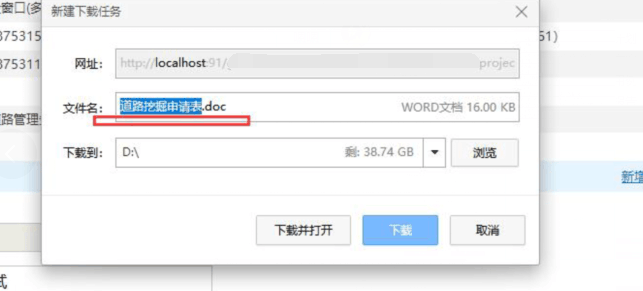
下图是返回的doc格式的,可以正常下载,下面是返回代码返回的下载页面名称:

jspx后缀是访问的xhtml页面,这种是不能正常下载的。
2、问题排查解决:大部分的电脑大部分的浏览器是可以正常下载的,可能涉及到到浏览器版本和其兼容性的问题,不同的内核或者不同的版本所支持的接口或者方法有所不同,内核及版本太多不去一一深究,排查优化代码,原来是在页面的js脚本对应方法中跳转到下载附件的这个页面地址,然后再调用后台实现的:
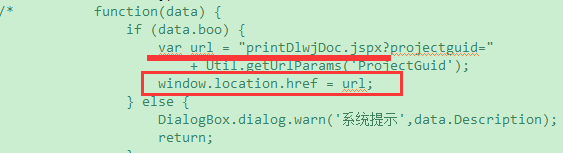
有时下载会是一个如jspx后缀名的页面,想着不通过这个中间页面直接实现下载,方法是页面js脚本方法中直接访问restful接口形式实现,如下:

这边的地址为一个后台的类注解加上方法注解的方式访问的一个restful接口:
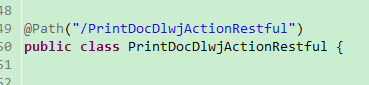

这个接口返回的是二进制字节流文件,用OutputStream对象输出,附上下载附件的后台方法:
@Path("/downloadDlwjBpb")
@GET
@Produces(MediaType.APPLICATION_OCTET_STREAM)
public StreamingOutput downloadDlwjBpb(@Context HttpServletResponse response, @Context HttpServletRequest request) {
String projectguid = request.getParameter("projectguid");
String licenseName = JsfHelper.getDeployWarPath() + "WEB-INF/classes/license.xml";
License license = new License();
try {
license.setLicense(licenseName);
BaseService service = new BaseService();
// 取数据的语句
String sql = "select * from audit_project where rowguid = '" + projectguid + "'";
String sql2 = "select * from audit_dlwj where projectguid='" + projectguid + "'";
//String sql3 = "select * from audit_dyfy_project_yyss where projectguid='" + projectguid + "'";
// 执行封装查询方法,返回实体类
AuditProject AuditProject = service.getSingleResultNative(sql, AuditProject.class);
AuditDlwj dlwj = service.getSingleResultNative(sql2, AuditDlwj.class);
if (dlwj == null) {
dlwj = new AuditDlwj();
}
// document对象结合word邮件合并域,代码给word域赋值
Document doc = new Document();
String filepathname = JsfHelper.getDeployWarPath() + "wsbsdt/PrintDocFlolder/dlwjsqb.doc";
doc = new Document(filepathname);
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
Map<Object, Object> map = new HashMap<Object, Object>();
// 取值赋值给word域
map.put("applyername", AuditProject.getApplyername());
map.put("contactperson", AuditProject.getContactperson());
map.put("contactphone", AuditProject.getContactphone());
map.put("address", AuditProject.getAddress());
map.put("kwdate", "开始时间:"+EpointDateUtil.convertDate2String(dlwj.getKwdateks(), EpointDateUtil.DATE_FORMAT)+"至结束时间:"+EpointDateUtil.convertDate2String(dlwj.getKwdatejs(), EpointDateUtil.DATE_FORMAT));
map.put("kwaddress", dlwj.getKwaddress());
map.put("applyreason", dlwj.getApplyreason());
if("1".equals(dlwj.getIsbystreetcar())){
map.put("isbystreetcar1", "☑");
map.put("isbystreetcar0", "□");
}else{
map.put("isbystreetcar1", "□");
map.put("isbystreetcar0", "☑");
}
if("1".equals(dlwj.getIsaboutgreen())){
map.put("isaboutgreen1", "☑");
map.put("isaboutgreen0", "□");
}else{
map.put("isaboutgreen1", "□");
map.put("isaboutgreen0", "☑");
}
String tableid = String.valueOf("");
// 在通过mis平台处理通用的字段值
List<Object[]> objlist = getWordFieldAndValue(tableid, "", map);
String[] fieldNames = (String[]) objlist.get(0);// word域
Object[] values = objlist.get(1);// 域对应的值
// 2 替换域和表格并且生成word入库
doc.getMailMerge().execute(fieldNames, values);// 替换基本信息表word中的域
doc.getFirstSection().getPageSetup().setSectionStart(SectionStart.NEW_PAGE);
doc.save(outputStream, SaveFormat.DOC);
// 定义二进制流对象,用来接收数据返回outputstream对象
final byte[] in2b = outputStream.toByteArray();
//JsfHelper.sendRespose(in2b, URLEncoder.encode("道路挖掘申请表.doc"), ".doc");
String fileName = URLEncoder.encode("道路挖掘申请表.doc", "utf-8");
response.setContentLength(in2b.length);
//Content-Disposition不是标准版的http响应头,它是扩展header
response.setHeader("Content-Disposition", "attachment; filename=" + fileName + "");
return new StreamingOutput() {
public void write(OutputStream output) throws IOException, WebApplicationException {
output.write(in2b);
output.flush();
}
};
}
catch (Exception e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
return null;
}