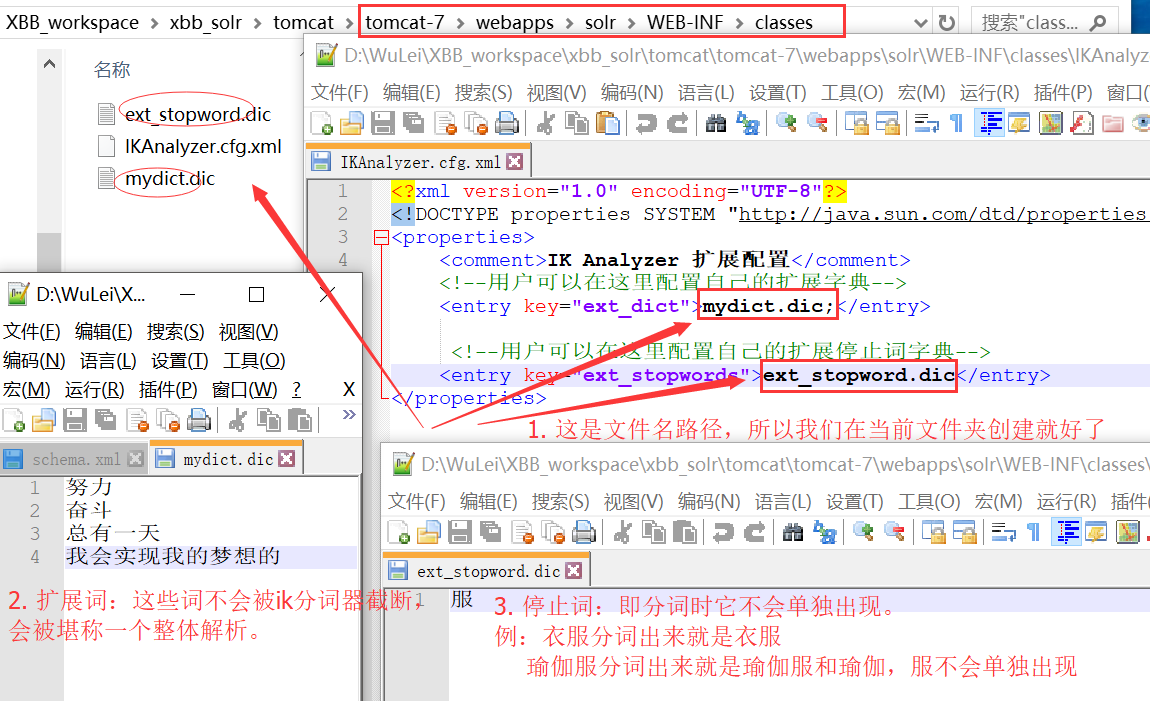
本文记录的是solr在win下安装配置使用的过程,最后将solr部署到Linux上通过远程访问。下一篇文章会介绍 solr集群搭建(SolrCloud) 的安装!
Solr是基于Lucene的全文检索服务器,性能进行了优化。运行在jetty、tomcat这些web容器中。而Lucene只是一个jar包,不能对外提供服务。在安装之前我们要先搞清楚下面两个问题。
一:Solr是如何实现全文检索的
索引流程
Solr客户端(浏览器、java程序)可以向solr服务器发送post请求,请求内容是包含Field等信息的一个xml文档, 通过该文档可以对索引进行维护。
搜索流程
Solr客户端(浏览器、java程序)可以向solr服务器发送get请求,solr服务器返回一个xml文档。
二:Solrhome和SoleCore
SolreHome是solr服务运行的主目录,一个solrhome目录里面包含多个SoleCore。一个SolrCore包含一个Solr实例运行时所需的配置文件和数据文件。Solrcore可以单独对外搜索和索引提供服务,彼此间没有半毛钱的关系。Home和core的关系好比,数据库连接和数据库的关系,自己体会。
对solr有个大致的认识后我们就要开始安装了~~
准备工具: 1. solr 2. IK Analyzer中文分词器 3. 一个干净的tomcat
安装步骤: 1. 安装solr 2.配置中文分词
安装步骤:
1.1 解压安装文件
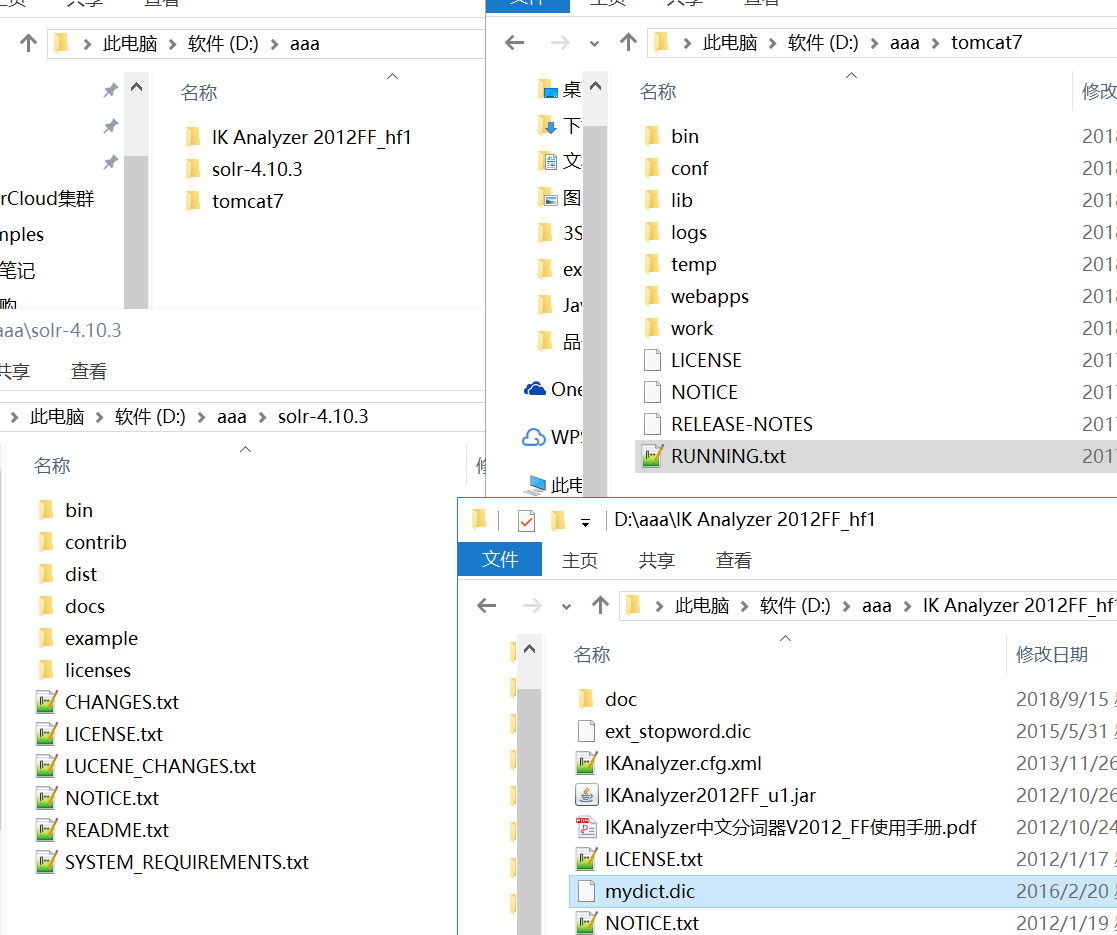
1.2 复制solr.war到tomcat的webapps下; 然后解压为solr文件夹,并删除该solr.war文件。
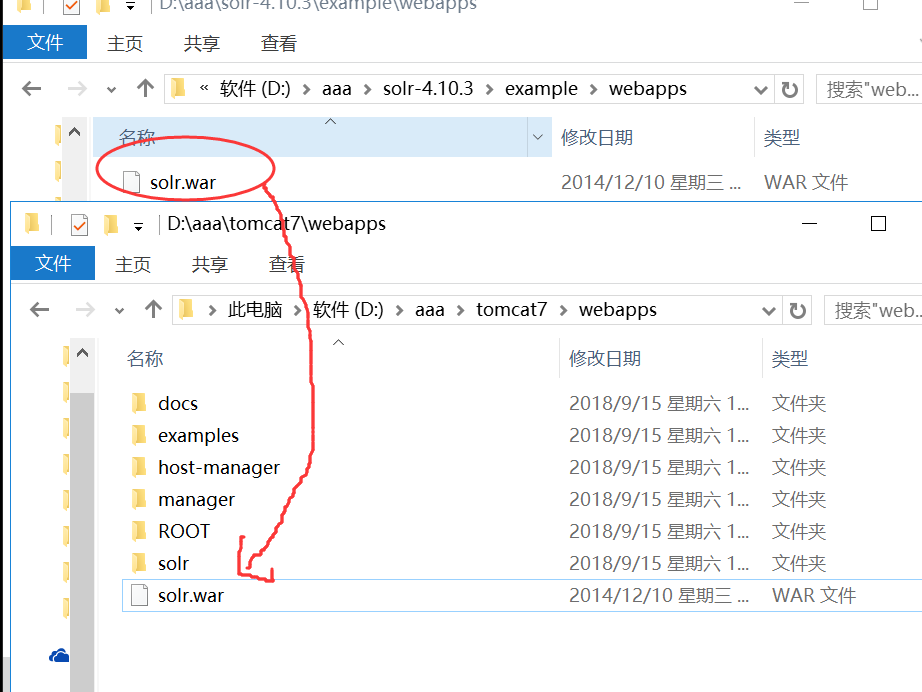
1.3 把solr的lib文件夹中的5个扩展包复制到tomcat的lib文件夹里面
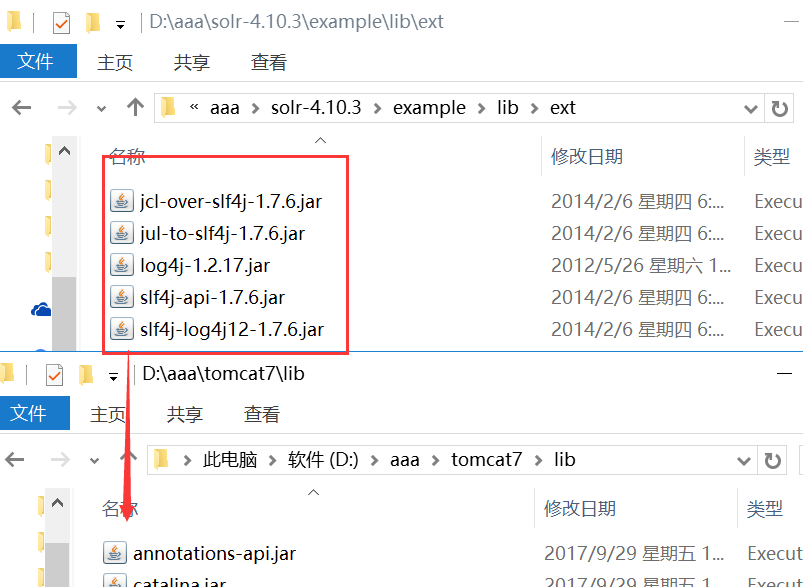
1.4 在tomcat文件夹下面创建mysolrhome文件夹, 并且将solr-4.10-3中的solrhome文件全部复制过来。
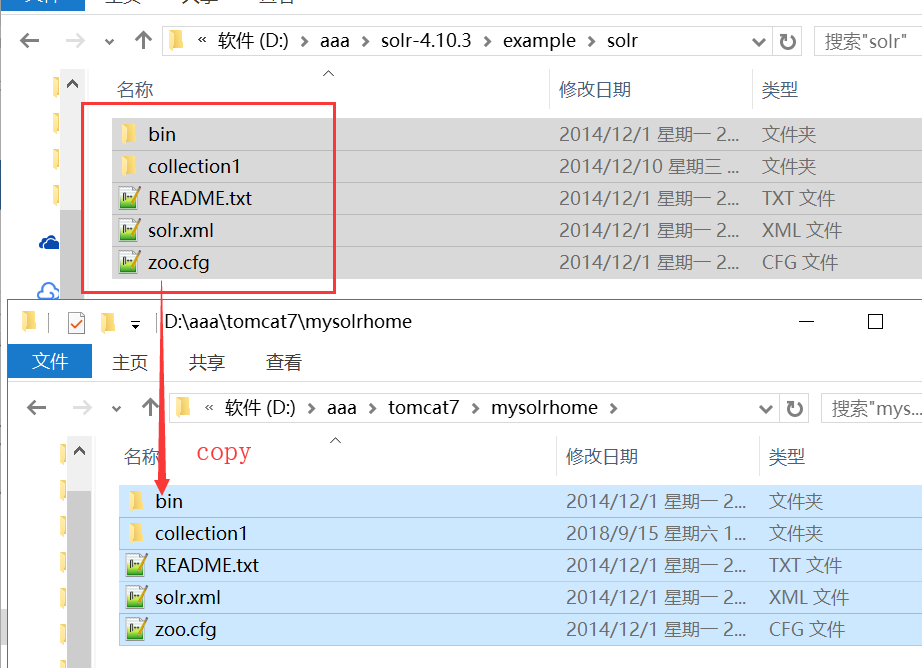
1.5 指定solrhome的路径。
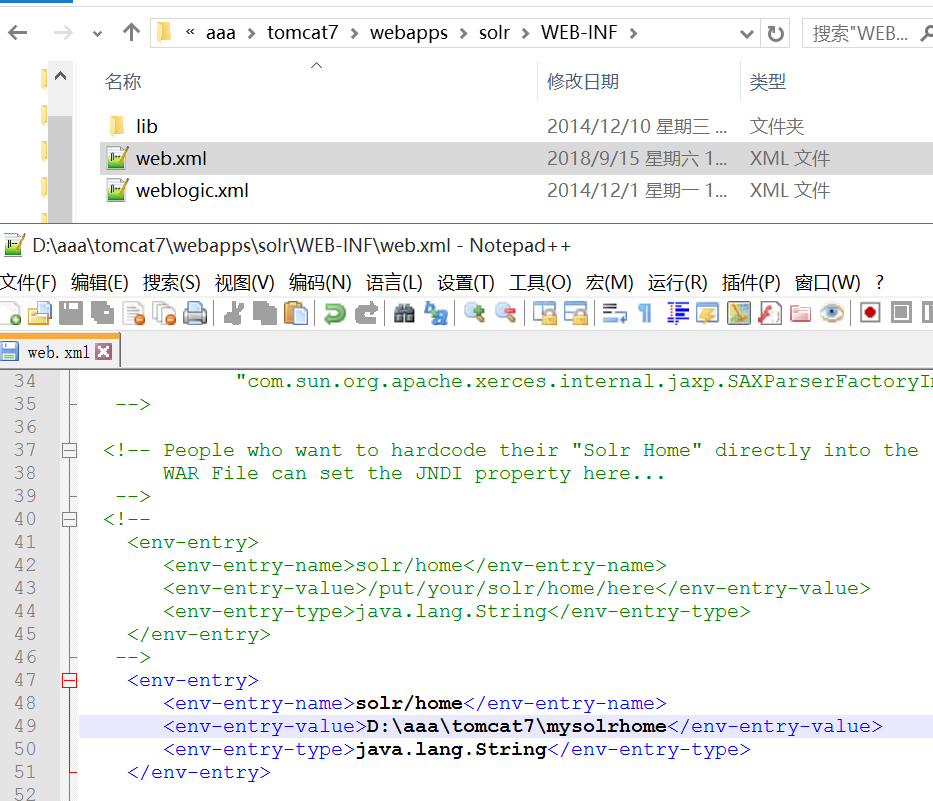
1.6 启动tomcat 输入 localhost:8080/solr 能看到solr首页就说明已经配置成功了。 如果启动tomcat闪退,是因为tomcat找不到jdk路径,需要修改下startup.bat文件(自行百度)
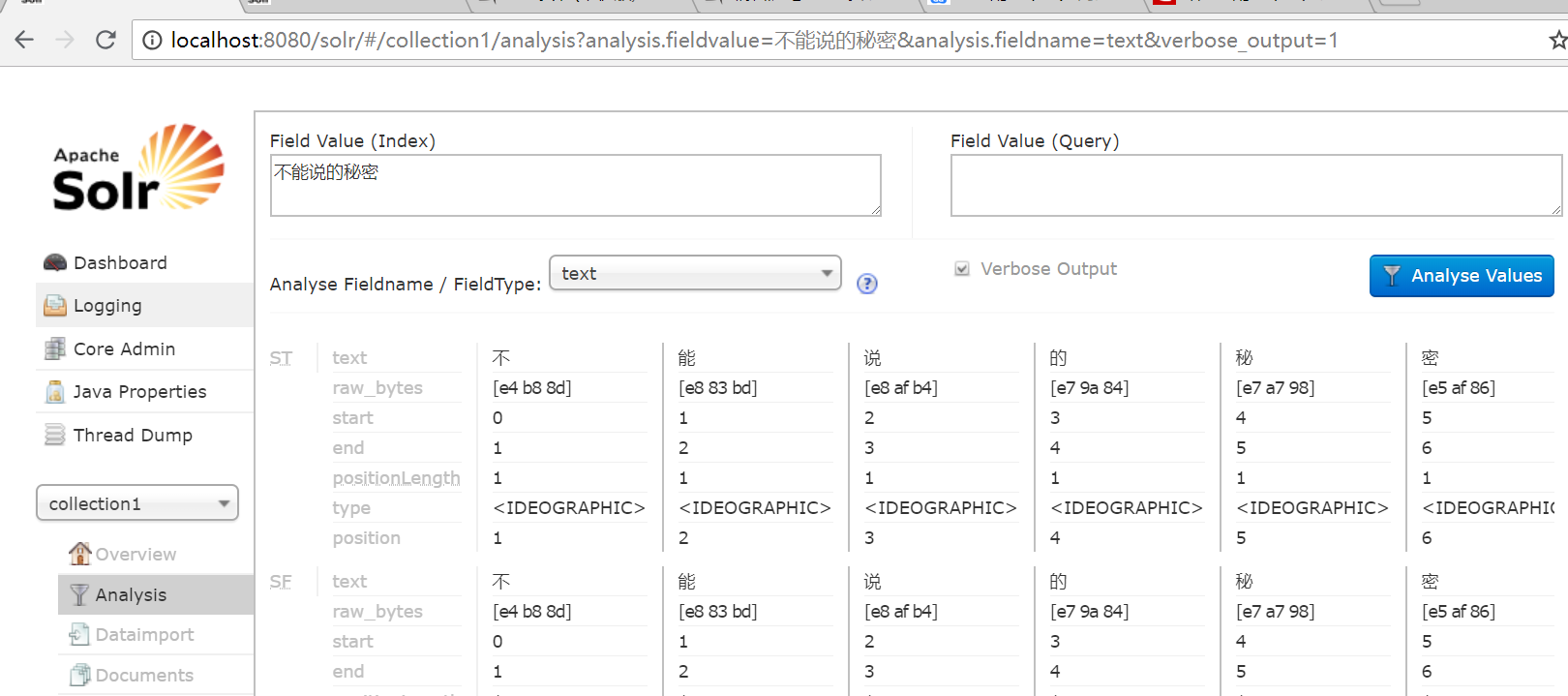
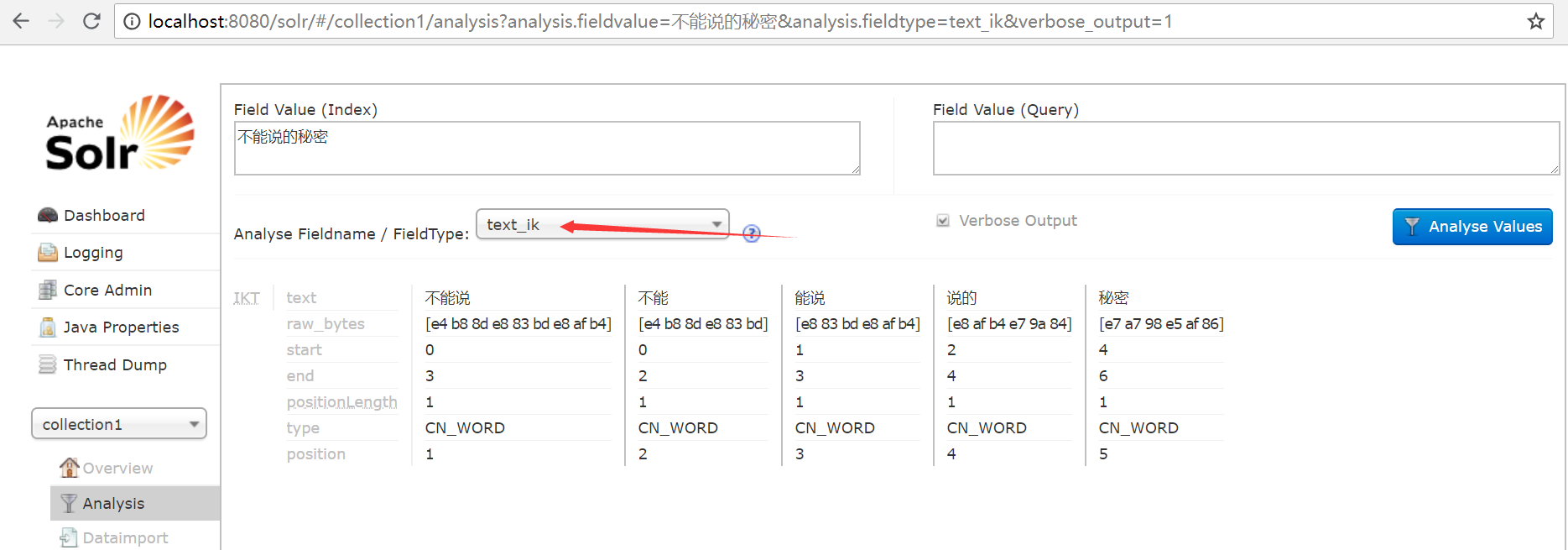
solr启动成功后,我们如图搜一句话,会发现它默认的分词规则是一个汉字就是一个词,比如秘密是个词语就不应该分开,下面我们来配置一些扩展信息吧!
2.1 复制IKAnalyzer2012FF_u1.jar到solr的lib文件夹; 复制3个配置文件到solr的classes文件夹
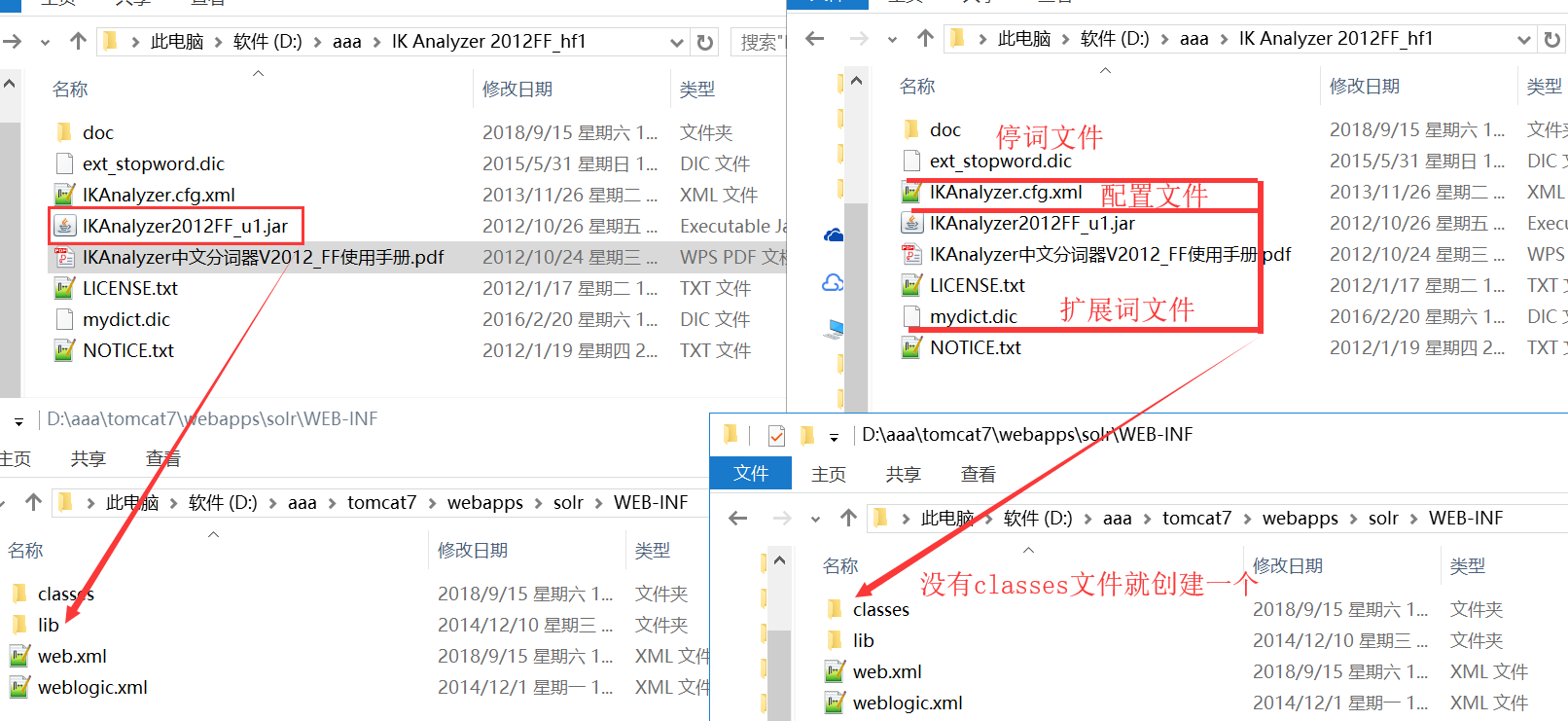
2.2 自定义分词规则
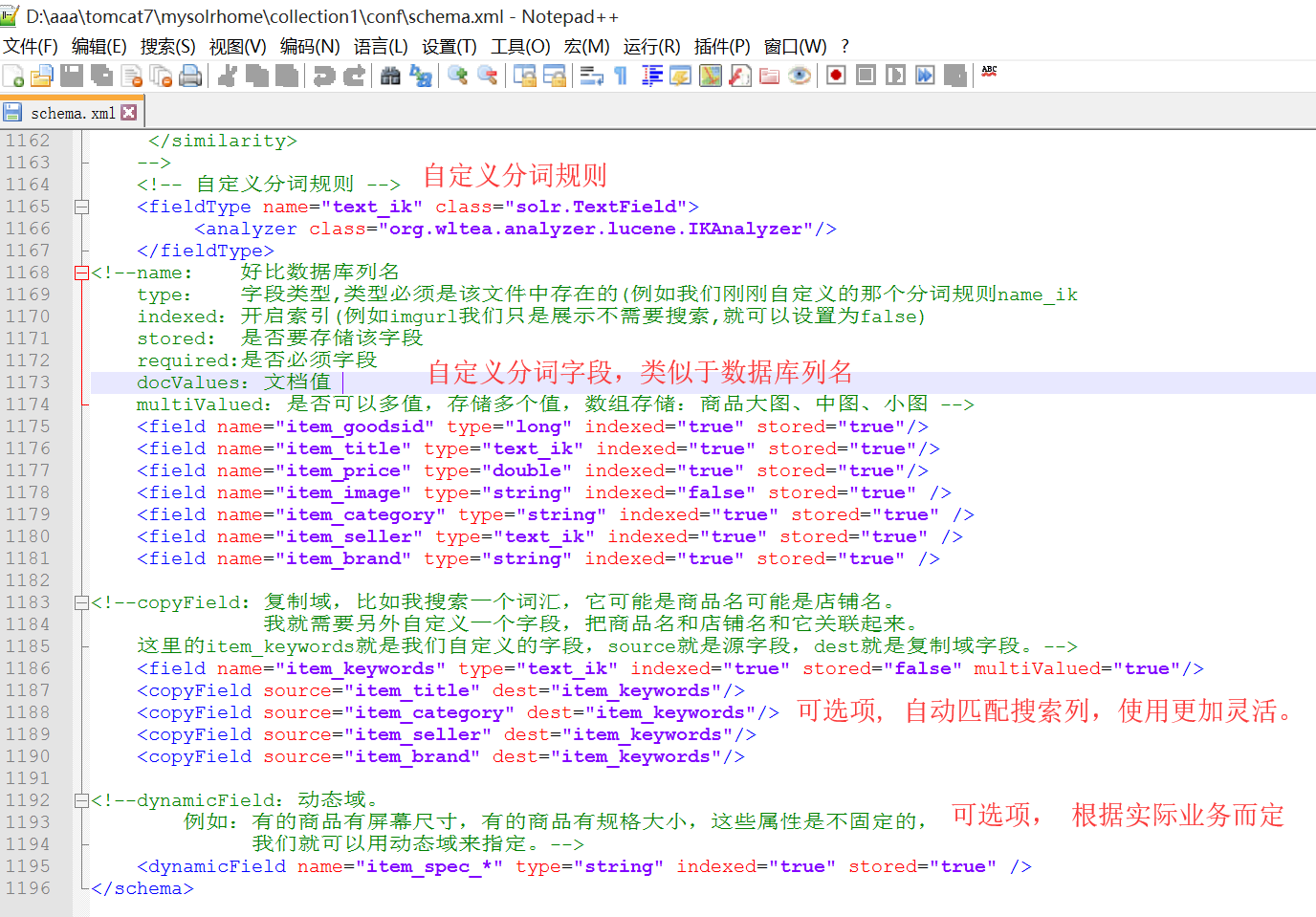
<!-- 自定义分词规则 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> <!--name: 好比数据库列名 type: 字段类型,类型必须是该文件中存在的(例如我们刚刚自定义的那个分词规则name_ik indexed:开启索引(例如imgurl我们只是展示不需要搜索,就可以设置为false) stored: 是否要存储该字段 required:是否必须字段 docValues:文档值 multiValued:是否可以多值,存储多个值,数组存储:商品大图、中图、小图 --> <field name="item_goodsid" type="long" indexed="true" stored="true"/> <field name="item_title" type="text_ik" indexed="true" stored="true"/> <field name="item_price" type="double" indexed="true" stored="true"/> <field name="item_image" type="string" indexed="false" stored="true" /> <field name="item_category" type="string" indexed="true" stored="true" /> <field name="item_seller" type="text_ik" indexed="true" stored="true" /> <field name="item_brand" type="string" indexed="true" stored="true" /> <!--copyField: 复制域,比如我搜索一个词汇,它可能是商品名可能是店铺名。 我就需要另外自定义一个字段,把商品名和店铺名和它关联起来。 这里的item_keywords就是我们自定义的字段,source就是源字段,dest就是复制域字段。--> <field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/> <copyField source="item_title" dest="item_keywords"/> <copyField source="item_category" dest="item_keywords"/> <copyField source="item_seller" dest="item_keywords"/> <copyField source="item_brand" dest="item_keywords"/> <!--dynamicField:动态域。 例如:有的商品有屏幕尺寸,有的商品有规格大小,这些属性是不固定的, 我们就可以用动态域来指定。--> <dynamicField name="item_spec_*" type="string" indexed="true" stored="true" />
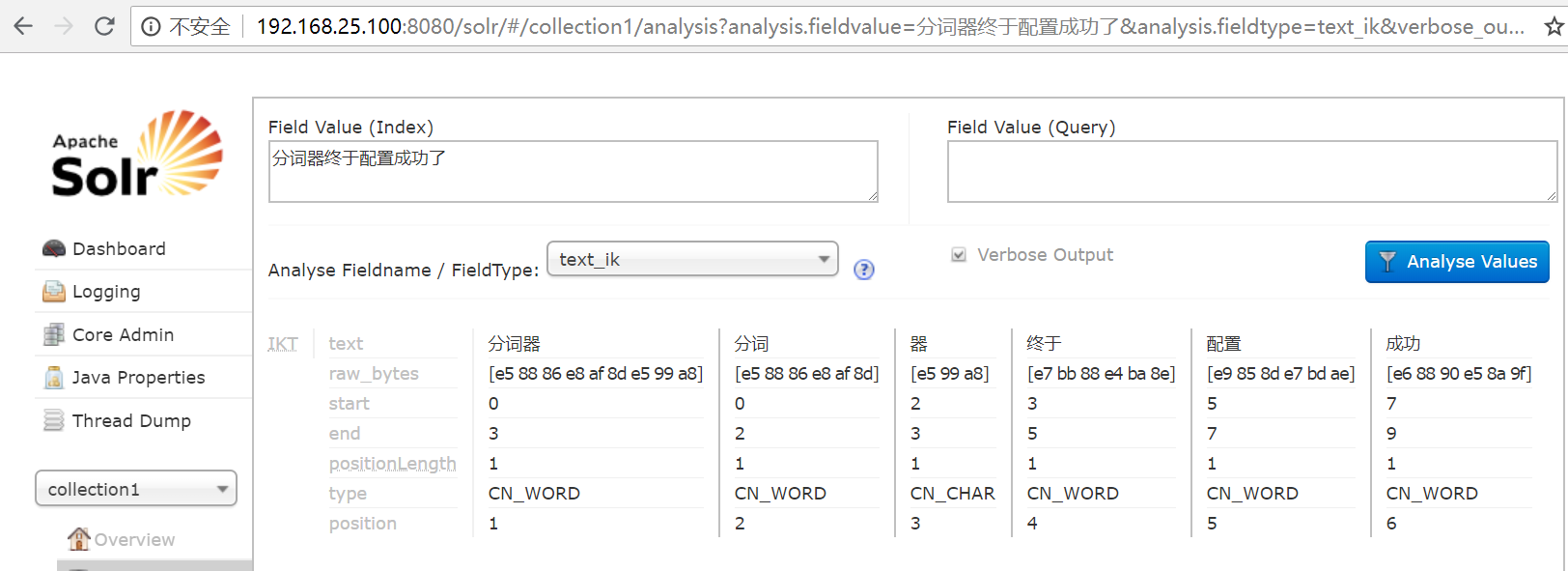
此时重启tomcat 选择我们刚才自定义的分词规则,发现中文分词就配置成功了!
将solr部署到linux中:
1. 创建文件夹 mkdir /usr/local/wulei/solr
2. 把刚配置好的solr压缩为zip文件,上传到该文件夹 。
3. 解压 unzip tomcat7.zip
4. 编辑配置文件 vim tomcat7/webapps/solr/WEB-INF/web.xml
修改solrhome地址 /usr/local/wulei/solr/tomcat7/mysolrhome
5. 修改成功略过这一步 (楼主这里没有权限,所以在wulei/目录下设置下权限 chmod -R 777 solr 然后重新编辑。)
6. cd tomcat7/bin/ ./startup.sh 浏览器输入 ip:8080/solr 测试。
7. 【测试】 若启动成功而浏览器不能访问, 可能要关闭防火墙。 service firewalld stop
===============================================
扩展知识: 在IKAnalyzer.cfg.xml中配置扩展词和停止词 (不配也行,没任何影响,了解下就就够了)