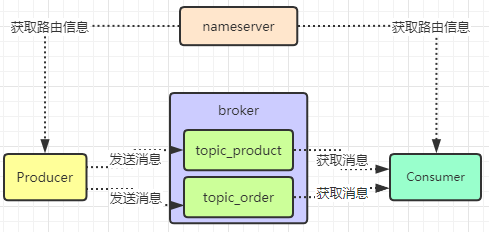
消息发送
Topic
Topic用于将消息按主题做划分,Producer将消息发往broker中指定的Topic,Consumer订阅该Topic就可以收到这条消息。Topic跟发送方和消费方都没有强关联关系,发送方可以同时往多个Topic投放消息,消费方也可以订阅多个Topic的消息。在RocketMQ中,Topic是一个上逻辑概念。消息存储不会按Topic分开。举个例子,现在你的订单系统需要往MQ里发送订单消息,那么此时你就应该建一个Topic,他的名字可以叫做:topic_order_info,也就是一个包含了订单信息的数据集合。要是你有一些商品数据要发送消息到MQ里,你就应该创建一个Topic叫做“topic_product_info”,代表里面都是商品数据,那些想要从MQ里获取商品数据的系统就可以从“topic_product_info”里获取了。
MessageQueue,Topic,Broker的关系
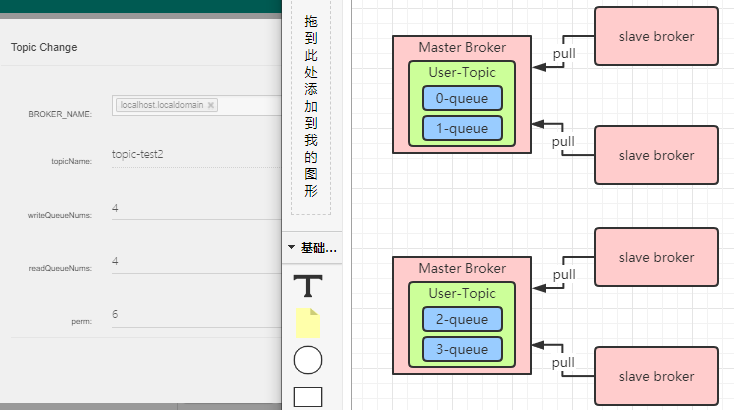
我们要发送消息的时候,会根据业务指定一个topic,然后会指定这个topic对应了多少个队列。其实rocketmq的队列本质上就是一个数据分片的机制,队列将一个topic拆分成很多个数据分片,然后每个broker机器上都存储一些队列。比如现在一个topic我们指定4个queue,我们知道topic数据是分布式存储在多个broker中的。那差不多物理结构是这样子:
消息发送与持久化过程
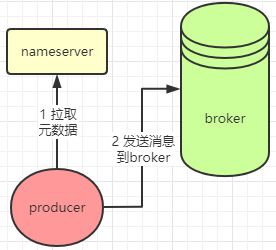
刚才的图就是一个双master的主从架构,那生产者发送消息的时候,怎么知道应该发送到哪个机器呢?其实生产者它首先会跟nameserver通信、获取topic和broker信息,然后就按照一定的规则发送到某个broker里面去。
在rocketmq中每个messageQueue都会对应一个consumeQueue,因为消息最终是要写入到磁盘文件(CommitLog)的,consumeQueue主要记录了消息在文件中的offset偏移量(也可以理解成在文件中的下标位置)。为了达到近乎内存写性能,Broker是基于OS操作系统的 PageCache 和 顺序写 两个机制,来提升写入效率。consumeQueue记录下标位置后,首先写入pageCache中,然后通过OS线程异步刷盘到CommitLog文件中;当然,与此相对应还有同步刷盘,就是consumeQueue直接写入到CommitLog中。
* 异步刷盘时会有消息丢失风险,因为消息写入PageCache后就返回ACK了;同步刷盘是写到磁盘后才返回ACK。

DLedger主从同步原理
Broker实现高可用,至少要有一个Broker组,master接收消息后,slave去同步消息。也就是说同一条数据其实会有三份。DLedger来实现broker高可用,实际上就是由DLedger来代为管理broker的commitlog,然后根据Raft协议选举出主从节点,一条消息发送过来,首先是标记为uncommitted状态,过半节点同步消息后,则更新为commited状态。

细嗅蔷薇
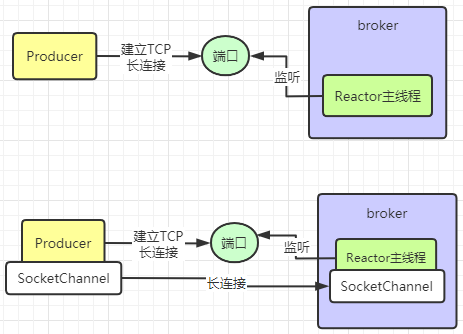
Producer和Broker的长连接
Producer向Broker发送消息前,需要先建立长链接,Broker中会有个Reactor主线程专门监听Producer建立连接的请求。然后Producer和Broker中会有一个SocketChannel,用来代表长连接它们建立好的长连接。
Reactor与Worker线程池
Producer会用SocketChannel向Broker发送消息,然后Broker中会有一个Reactor线程池,里面默认有3个线程,会去监听SocketChannel中到达的消息。然后会将请求转交给Worker线程池、默认8个线程,Worker来进行一系列的预处理,比如SSL加密验证、编码解码、连接空闲检查、网络连接等。
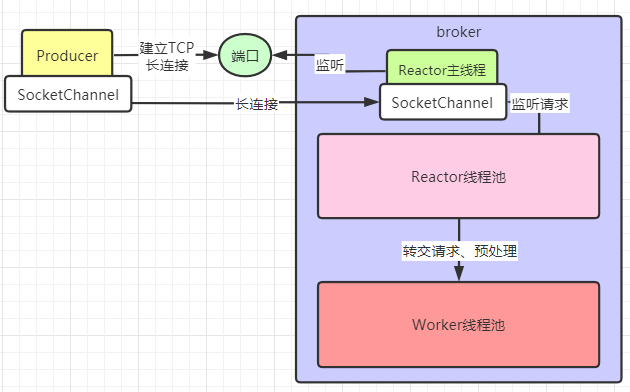
最后再交给SendMessage线程池进行刷盘处理。
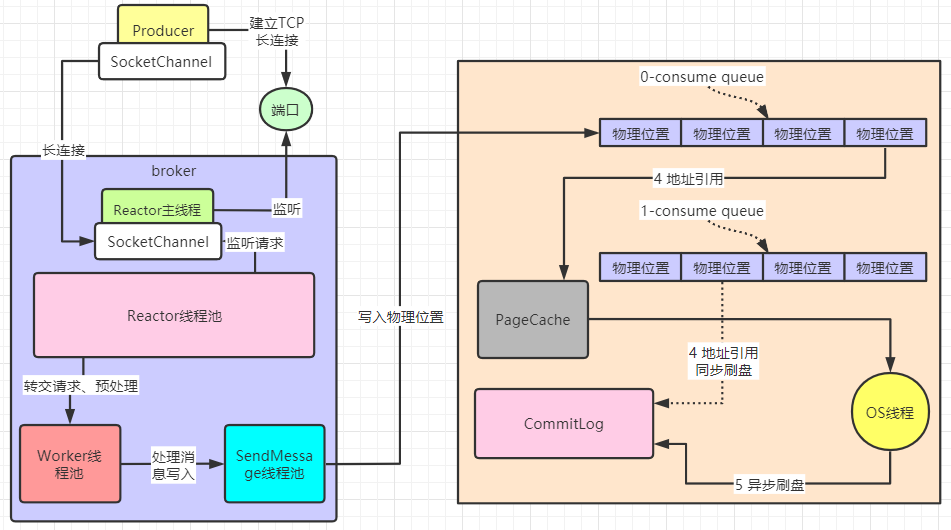
mmap+PageCache
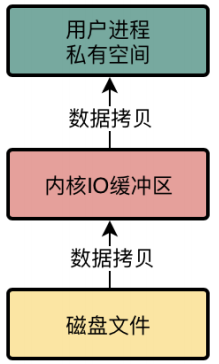
我们普通的文件IO操作去进行磁盘文件的读写,那会存在多次数据拷贝性能问题。首先从磁盘上把数据读取到内核IO缓冲区里去,然后再从内核IO缓存区里读取到用户进程私有空间里去,然后我们才能拿到这个文件里的数据。性能是很差的。
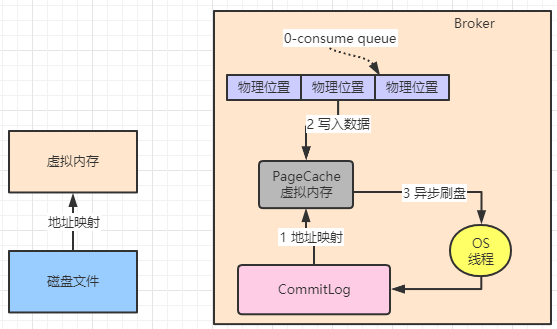
而RocketMQ就基于mmap技术+PageCache技术进行了优化。mmap是一种内存映射技术,就是把物理磁盘文件的地址和用户进程私有空间的一些虚拟内存地址进行了一个映射。在上面我们说到过CommitLog磁盘文件写入数据,文件大小默认1G那是因为mmap在文件映射时,一般有大小限制,在1.5GB~2GB之间。所以RocketMQ才让CommitLog单个文件在1GB,ConsumeQueue文件在5.72MB,不会太大。
消息接收
消费组和topic的关系
我们初始化消费者的时候都会指定一个分组名,比如积分系统、仓储系统什么的就可以起个名字:stock_consumer_group、wms_consumer_group,他们可以订阅topic去读取broker的消息。比如现在订单系统下单后发送了一个消息,而这两个系统都订阅了这个消息的topic,那么他们则可以都拿到这个消息。但是比如积分系统里面部署了n台机器做集群,只有一台机器能拿到消息,同一个消费组的其他机器是无法获取的。
集群模式和广播模式
默认是集群模式,也就是说一个消费组获取到一条消息,只会交给组内的一台机器去处理,但是我们可以通过如下设置来改变为广播模式:consumer.setMessageModel(MessageModel.BROADCASTING);如果修改为广播模式,那么消费组内每台机器都可以获取到这条消息。不过这个播模式其实用的很少。消费者会比较均匀的消费每个MessageQueue的消息。如果过程中有机器新增和宕机,它们会立即重新分配MessageQueue。
Rocketmq消费模型
RocketMQ默认是采用pushConsumer方式消费的,从概念上来说是推送给消费者,它的本质是pull+长轮询。这样既通过长轮询达到了push的实时性,又有了pull的可控性。系统收到消息后会自动处理消息和offset(消息偏移量),如果期间有新的consumer加入会自动做负载均衡(集群模式下offset存在broker中; 广播模式下offset存在consumer里)。当然我们也可以设置为pullConsumer模式,这样灵活性会提高,但是代码却会很复杂,需要手动维护offset,消息存储和状态。
Rocketmq消费策略
消费者从那个位置消费,分别为:
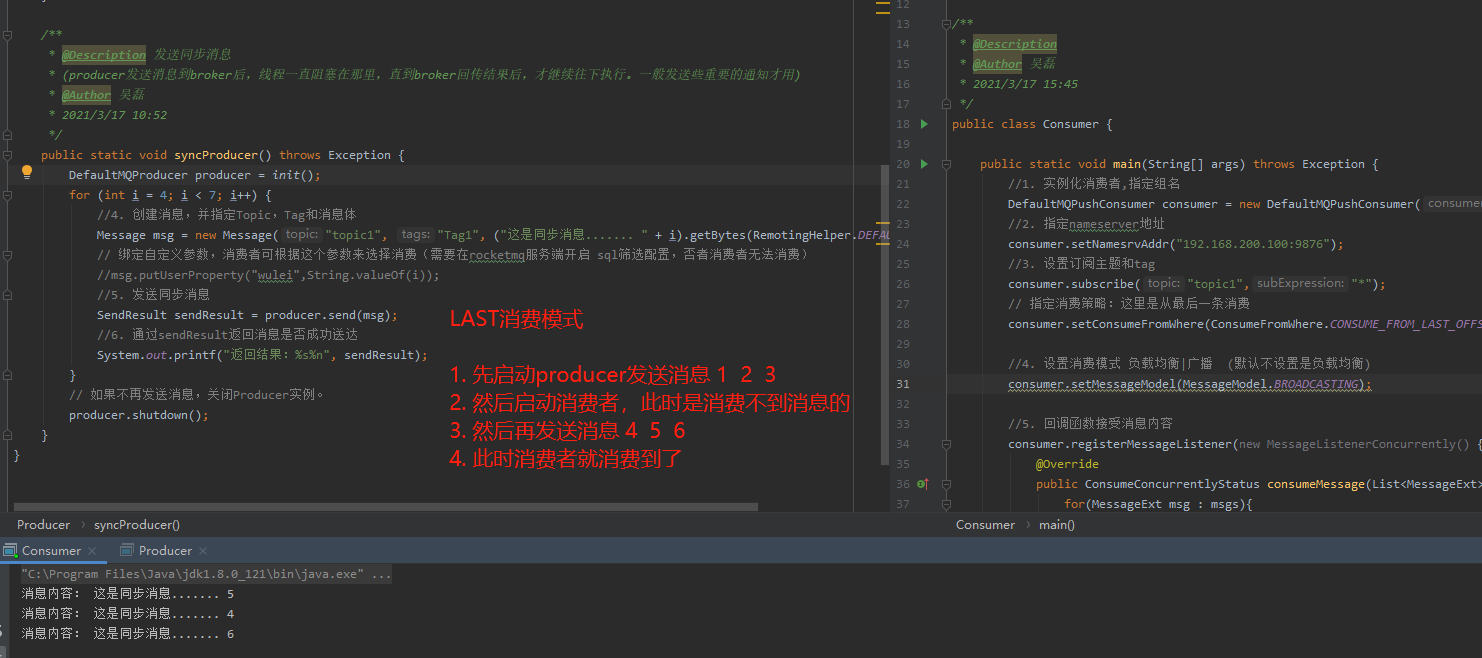
CONSUME_FROM_LAST_OFFSET: 第一次启动从队列最后位置消费,后续再启动接着上次消费的进度开始消费
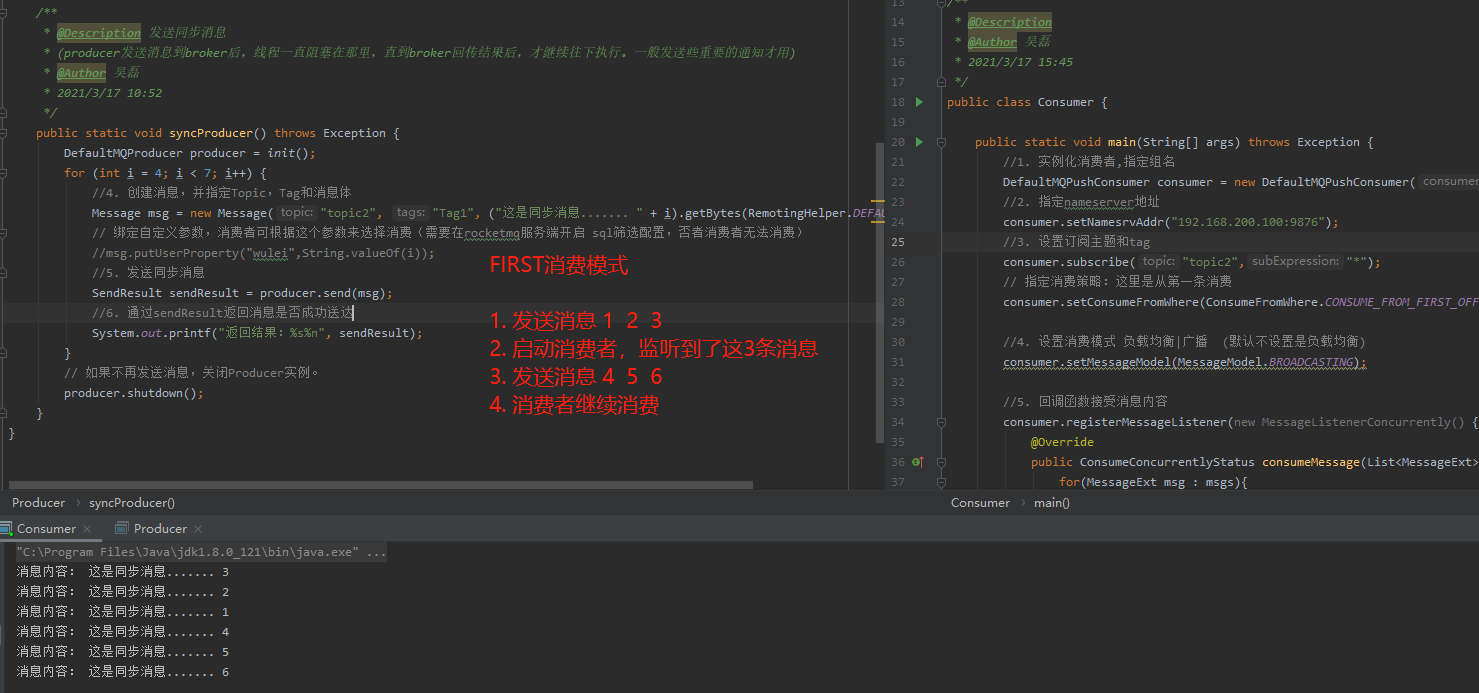
CONSUME_FROM_FIRST_OFFSET:第一次启动从队列初始位置消费,后续再启动接着上次消费的进度开始消费
CONSUME_FROM_TIMESTAMP: 第一次启动从指定时间点位置消费,后续再启动接着上次消费的进度开始消费
* 以上所说的第一次启动是指从来没有消费过的消费者,如果该消费者消费过,那么会在broker端记录该消费者的消费位置,如果该消费者挂了再启动,那么自动从上次消费的进度开始。一般来说,我们都会选择CONSUME_FROM_FIRST_OFFSET,这样你刚开始就从Topic的第一条消息开始消费。
。