作业①:
-
要求:
- 用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
- 每部电影的图片,采用多线程的方法爬取,图片名字为电影名
- 了解正则的使用方法
-
候选网站:豆瓣电影:https://movie.douban.com/top250
-
输出信息:
-
排名 电影名称 导演 主演 上映时间 国家 电影类型 评分 评价人数 引用 文件路径 1 肖申克的救赎 弗兰克·德拉邦特 蒂姆·罗宾斯 1994 美国 犯罪 剧情 9.7 2192734 希望让人自由。 肖申克的救赎.jpg 2......
-
-
代码:
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import threading import os import pymysql class MySpider: def startUp(self): try: self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='523523', db="mydb", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # self.cursor.execute("delete from movie") self.opened = True except Exception as err: print(err) self.opened = False def closeUp(self): if self.opened: self.con.commit() self.con.close() self.opened = False def processSpider(self, start_url): global threads global urls global count try: req = urllib.request.Request(start_url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") lis = soup.find('div', class_='article').find_all('li') for li in lis: title = li.find('div', class_='hd').find_all('span')[0].text # 标题 score = li.find('div', class_='star').find_all('span')[1].text # 评分 head = li.find('div', class_='star').find_all('span')[-1].text # 评价人数 quote = li.find('p', class_='quote').find('span').text # 引用 # 爬取导演、主演、年份、国家、类型 actor_infos_html = li.find(class_='bd') # strip()方法用于移除字符串头尾指定的字符(默认为空格) actor_infos = actor_infos_html.find('p').get_text().strip().split(' ') actor_infos1 = actor_infos[0].split('xa0xa0xa0') director = actor_infos1[0][3:] # 导演 if len(actor_infos1) > 1: role = actor_infos1[1][3:] # 主演 year_area = actor_infos[1].lstrip().split('xa0/xa0') year = year_area[0] # 年份 country = year_area[1] # 国家 type = year_area[2] # 类型 path = title + '.png' # 文件路径 # 将数据写入数据库 if self.opened: self.cursor.execute( "insert into movie(wId, wTitle, wDirector, wRole, wYear, wCountry, wType, wScore, wHead, wQuote, wPath)" "values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)", (str(count), str(title), str(director), str(role), str(year), str(country), str(type), str(score), str(head), str(quote), str(path))) count = count + 1 # 爬取图片 images = soup.select("img") for image in images: try: url = image["src"] # 获取图片下载链接 name = image["alt"] # 获取图片名称 print(url) if url not in urls: urls.append(url) print(url) T = threading.Thread(target=self.download, args=(url, name)) T.setDaemon(False) T.start() threads.append(T) except Exception as err: print(err) except Exception as err: print(err) def download(self, url, name): try: ext = '.png' req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() path = "download\" + name + ext # 保存为png格式 fobj = open(path, "wb") fobj.write(data) fobj.close() print("download" + name + ext) except Exception as err: print(err) def executeSpider(self, start_url): print("Spider starting......") self.startUp() print("Spider processing......") self.processSpider(start_url) print("Spider closing......") self.closeUp() headers = { "User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre" } spider = MySpider() threads = [] # 存放线程 urls = [] # 存放图片的url链接 count = 1 # 用于计数 # 全部10个网页 for i in range(0, 10): start_url = "https://movie.douban.com/top250?start=" + str(i * 25) + "&filter=" spider.executeSpider(start_url) for t in threads: t.join() -
实验结果:



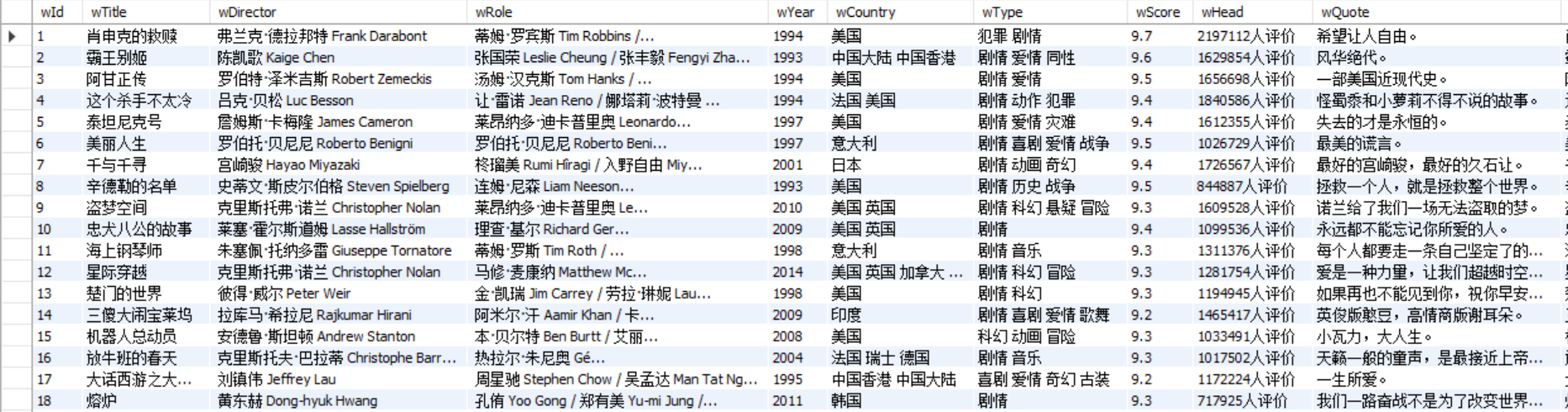

-
实验心得:
实验一复习了这学期刚开始学习的一些知识,有一说一忘得差不多了,花了一段时间才重新回忆起来。由于此次爬取的好多内容都是放在一个text里,因此需要对爬取的文本内容进行分割,花了挺多 时间尝试了不同的分割方式,最后终于成功了orz。。然后就是多线程下载图片,这部分比较简单,直接将书本上例题的代码搬下来就好。
-
作业②:
-
要求:
- 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
- 爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
-
关键词:学生自由选择
-
输出信息:MYSQL的输出信息如下

-
代码:
school.py:
import scrapy import urllib.request from School.items import SchoolItem from bs4 import BeautifulSoup from bs4 import UnicodeDammit class SchoolSpider(scrapy.Spider): name = 'school' start_url = 'https://www.shanghairanking.cn/rankings/bcur/2020/' headers = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 " "Minefield/3.0.2pre"} def start_requests(self): self.count = 1 url = SchoolSpider.start_url yield scrapy.Request(url=url, callback=self.parse) def parse(self, response): try: dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) data = dammit.unicode_markup selector = scrapy.Selector(text=data) trs = selector.xpath("//div[@class='rk-table-box']/table/tbody/tr") for tr in trs: sNo = tr.xpath("./td[position()=1]/text()").extract_first() # 排名 schoolName = tr.xpath("./td[position()=2]/a/text()").extract_first() # 学校名称 city = tr.xpath("./td[position()=3]/text()").extract_first() # 城市 Url = tr.xpath("./td[position()=2]/a/@href").extract_first() sUrl = 'https://www.shanghairanking.cn' + Url.strip() # 详情链接 # 进入详情链接 req = urllib.request.Request(sUrl, headers=SchoolSpider.headers) data1 = urllib.request.urlopen(req) dammit1 = UnicodeDammit(data1, ["utf-8", "gbk"]) data1 = dammit1.unicode_markup mes = scrapy.Selector(text=data1) officalUrl = mes.xpath("//div[@class='univ-website']/a/@href").extract_first() # 官网链接 info = mes.xpath("//div[@class='univ-introduce']/p/text()").extract_first() # 院校信息 imgUrl = mes.xpath("//td[@class='univ-logo']/img/@src").extract_first() # 图片链接 self.download(imgUrl) # 下载图片 mFile = str(self.count) + ".jpg" # 图片保存地址 self.count += 1 item = SchoolItem() item["sNo"] = sNo.strip() if sNo else "" item["schoolName"] = schoolName.strip() if schoolName else "" item["city"] = city.strip() if city else "" item["officalUrl"] = officalUrl.strip() if officalUrl else "" item["info"] = info.strip() if info else "" item["mFile"] = mFile yield item except Exception as err: print(err) def download(self, url): try: ext = '.jpg' # 保存为jpg格式 req = urllib.request.Request(url, headers=SchoolSpider.headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() path = "images\" + str(self.count) + ext fobj = open(path, "wb") fobj.write(data) fobj.close() except Exception as err: print(err)items.py:
import scrapy class SchoolItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() sNo = scrapy.Field() schoolName = scrapy.Field() city = scrapy.Field() officalUrl = scrapy.Field() info = scrapy.Field() mFile = scrapy.Field()pipelines.py:
import pymysql from itemadapter import ItemAdapter class SchoolPipeline: def open_spider(self, spider): print("opened") try: self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="523523", db="mydb", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from school") self.opened = True self.count = 0 except Exception as err: print(err) self.opened = False def close_spider(self, spider): if self.opened: self.con.commit() self.con.close() self.opened = False print("closed") def process_item(self, item, spider): try: if self.opened: self.cursor.execute( "insert into school (sNo,schoolName,city,officalUrl,info,mfile) values( % s, % s, % s, % s, % s, % s)", (item["sNo"], item["schoolName"], item["city"], item["officalurl"], item["info"], item["mFile"])) except Exception as err: print(err) return itemsettings.py:
ROBOTSTXT_OBEY = False ITEM_PIPELINES = { 'School.pipelines.SchoolPipeline': 300, } -
实验结果:

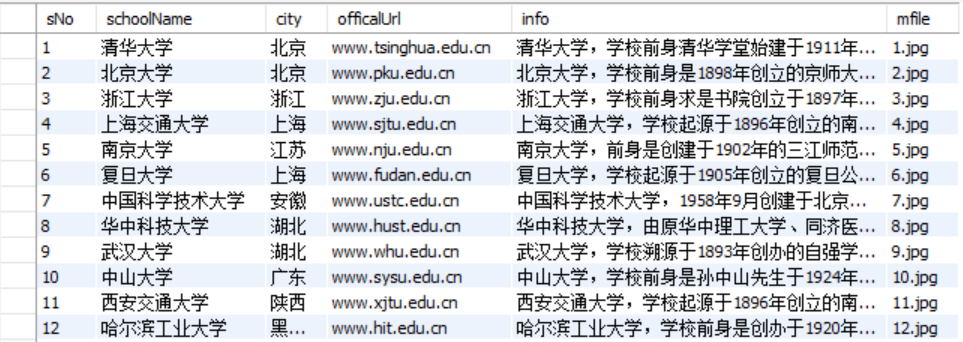
-
实验心得:
scrapy框架忘得也差不多了。。花了点时间复习了一下各个模块的作用。代码编写比较简单,没什么好说的。
-
-
作业③:
-
要求:
- 熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
- 使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
- 其中模拟登录账号环节需要录制gif图。
-
候选网站: 中国mooc网:https://www.icourse163.org
-
输出信息:MYSQL数据库存储和输出格式如下
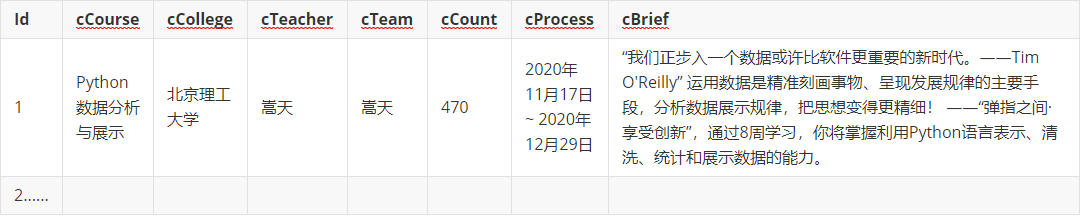
-
代码:
import pymysql from selenium import webdriver from selenium.webdriver.chrome.options import Options import time class MoocSpider: headers = { "User-Agent": "SMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/86.0.4240.183 Safari/537.361 " } def startUp(self, url): chrome_options = Options() self.driver = webdriver.Chrome(options=chrome_options) # 与数据库建立连接 try: self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='523523', db="mydb", charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) self.cursor.execute("delete from mooc") self.opened = True except Exception as err: print(err) self.opened = False # 获取url链接 self.driver.get(url) # 计数 self.count = 1 def closeUp(self): if self.opened: self.con.commit() self.con.close() self.opened = False self.driver.close() print("closed") # 登录慕课 def enter(self): self.driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']").click() # 点击登录|注册 time.sleep(3) self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']").click() # 选择其他登录方式 time.sleep(3) self.driver.find_elements_by_xpath("//ul[@class='ux-tabs-underline_hd']//li")[1].click() # 选择手机号登录 time.sleep(3) iframe_id = self.driver.find_elements_by_tag_name("iframe")[1].get_attribute('id') self.driver.switch_to.frame(iframe_id) self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys('13107693360') # 输入手机号 time.sleep(1) self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys('********') # 输入密码 time.sleep(1) self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click() # 点击登录 time.sleep(3) self.driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']").click() # 进入个人中心 time.sleep(2) self.driver.get(self.driver.current_url) # 爬取数据 def processSpider(self): time.sleep(1) lis = self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']" "//div[@class='course-card-wrapper']") # 找到所有参加的课程 for li in lis: li.find_element_by_xpath(".//div[@class='img']").click() # 进入课程窗口 last_window = self.driver.window_handles[-1] self.driver.switch_to.window(last_window) time.sleep(2) # 进入课程介绍 self.driver.find_element_by_xpath(".//a[@class='f-fl']").click() last_window = self.driver.window_handles[-1] self.driver.switch_to.window(last_window) try: cCourse = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text # 课程名 cCollege = self.driver.find_element_by_xpath("//img[@class='u-img']").get_attribute("alt") # 大学名 cTeacher = self.driver.find_element_by_xpath("//div[@class='um-list-slider_con']/div[position(" ")=1]//h3[@class='f-fc3']").text # 教师 k = 0 ls = [] while (True): try: teacher = self.driver.find_elements_by_xpath( "//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")[k].text ls.append(teacher) k += 1 except: break cTeam = ",".join(ls) # 转换成字符串 教师团队 cCount = self.driver.find_element_by_xpath( "//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text # 人数 cProcess = self.driver.find_element_by_xpath( "//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text # 时间 cBrief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text # 简介 except Exception as err: print(err) self.driver.close() # 关闭窗口 # 回到课程窗口 old_window1 = self.driver.window_handles[-1] self.driver.switch_to.window(old_window1) self.driver.close() # 关闭窗口 # 回到个人中心 old_window2 = self.driver.window_handles[0] self.driver.switch_to.window(old_window2) # 打印爬取结果 print(self.count, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief) # 将结果写入数据库r if self.opened: self.cursor.execute( "insert into mooc(wId, wCourse, wCollege, wTeacher, wTeam, wCount, wProcess, wBrief)" "values(%s, %s, %s, %s, %s, %s, %s, %s)", (str(self.count), cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)) self.count += 1 def executeSpider(self, url): print("Spider starting......") self.startUp(url) print("Spider entering......") self.enter() print("Spider processing......") self.processSpider() print("Spider closing......") self.closeUp() url = 'https://www.icourse163.org/' spider = MoocSpider() spider.executeSpider(url) -
实验结果:


-
实验心得:
实验三就像是上次实验的进阶版,实践用selenium框架进行点击、用户登录、返回窗口等操作,果然自动化爬取乐趣无穷!!以后还要继续探索selenium框架的妙用。
-