讲授Lenet、Alexnet、VGGNet、GoogLeNet等经典的卷积神经网络、Inception模块、小尺度卷积核、1x1卷积核、使用反卷积实现卷积层可视化等。
大纲:
LeNet网络
AlexNet网络
VGG网络
GoogLeNnet网络
反卷积可视化
数学特性
根据卷积结果重构图像
本集总结
LeNet网络:
卷积神经网络是1989年Y.LeCun提出的,真正有意义的卷积神经网络是LeNet-5网络,它是Y.LeCun1998年提出来的,现在尊称Y.LeCun为卷积神经网络之父,后来他去了Facebook的AI实验室。
这是第一个广为传播的卷积网络,规模很小,但五脏俱全(卷积、池化、全连接层都有),用于手写文字的识别,采用了标准的卷积层,池化层,全连接层结构,此后各种卷积网络的设计都借鉴了它的思想。
这篇文章提出的方法并没有大规模的被使用和广泛地引起关注,当时是SVM、AdaBoost占据优势,从1998年LeNet出现以后到2012年AlexNet出现,之间的十几年里边,卷积神经网络并没有得到很好的发展。
LeNet网络的结构:

MINIST数据集,两个卷积层、两个池化层、一些全连接层,输入图像32×32的灰度图像,第一个卷积层的卷积核的尺寸是5×5的六组卷积核,第一层卷积之后,得到6张(6通道)28×28的图像,再经过2×2的池化层变为6张14×14的图像。一个卷积核对应一个特征的提取,每个卷积核通道数等于输入数据通道数,而卷积层输出数据通道数等于提取的特征个数(即卷积核个数)。
第二个卷积层为16组卷积核,卷积核尺寸也是5×5的,前面讲的多通道卷积的时候按照常规的做法是,上层池化层输出是6通道的,这16组卷积核,每组应该是6通道的分别和输入的6通道卷积加起来,但是这里没有这样做,第0个卷积核只用了前三个通道卷积,后边的卷积核分别不同,如下图
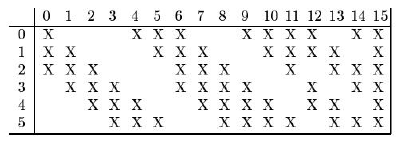
卷积完之后得到16个10×10的图像(16通道),然后第二个池化层进行下采样,得到16个5×5的图像。
然后是全连接层,把16中5×5的图像一字摆开,所有图形的像素拼接成一个向量,当成全连接网络的输入层,后边跟着一个120个神经元的全连接层,再跟着一个84个神经元的全连接层,最后一个是输出层10个神经元,即10个类的数字。
每个卷积层、全连接层都带有一个激活函数的作用,激活函数统一采用tanh函数,损失函数采用欧氏距离(之前多用欧氏距离损失函数,后边采用交叉熵和其他损失函数)。训练的时候采用梯度下降法进行训练,样本的标签值(十个类)采用one-hot编码形式的。
AlexNet网络:
由于计算能力(GPU没有用来做大规模机器学习使用)和训练样本数(没有数码相机和手机)的限制,网络层数增加带来的梯度消失等问题的困扰,在1989年LeNet提出后到2012年之间卷积神经网络并没有得到广泛的关注与大规模的应用。
直到2012年,Hinton等人设计出一个称为AlexNet(也是用人的名字命名的×××Net,Alex是人名,是一个深层的神经网络,本质上和LeNet没有多大差别)的深层卷积神经网络,在图像分类(ImageNet数据集,有大量图像和标签,而LeNet是MINIST数据集)任务上取得了成功。
Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks.2012
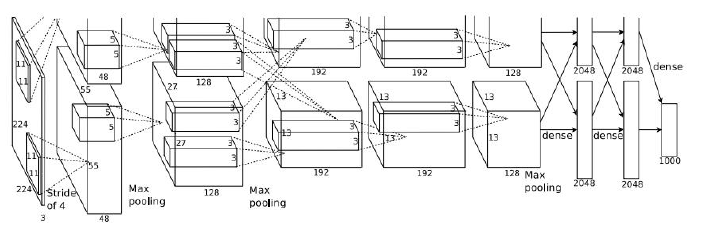
卷积核是11×11,图像输入是224×224的图像三通道RGB彩色图像(LeNet输入是32×32单通道,卷积核是5×5),卷积完分成两个组进行卷积,输出使用softmax变换,卷积核逐渐变小。结构上和LeNet相比,层次加深了,神经元的个数增多了,参数多了很多。
AlexNex网络的主要改进:
层数更深,参数更多,规模更大,训练样本更多(ImageNet数据集,而LeNet是MINIST数据集),采用了GPU加速。
真正的创新:
①新的激活函数ReLU函数(LeNet是tanh函数,更早的是sigmoid函数),tanh函数容易饱和产生梯度消失问题。
ReLU(x) = max(0,x)一定程度上缓解梯度消失问题(只是缓解没有根除,导数算起来简单,很多时候导数为1多次连乘梯度幅度不变,梯度消失是多个小于1的导数相乘值为0),在x=0不可导,并不影响全局。
②dropout机制
是一种正则化的技术,在训练的时候,挑出一部分神经元,如128个神经元随机挑出64个神经元不参加训练,即数据透明通过输入和输出一样,反向传播的时候也是那些神经元不更新,只是神经网络训练的时候用,训练完就不用这种机制了。
在训练时随机的选择一部分神经元进行正向传播和反向传播,另外一些神经元的参数值保持不变,以减轻过拟合。
dropout机制使得每个神经元在训练时只用了样本集中的部分样本,这相当于对样本集进行采样,即bagging的做法。最终得到的是多个神经网络的组合,但这不是一种严格的解释。
同机器学习的bagging机制类似,从整个大样本集中随机抽样抽出N个样本集出来,来训练每一个弱学习器,训练出来的每一个若学习器之间是相互独立的用各自的样本集训练的,但这里的神经网络是一个整体的,并不能看成是多个弱学习器的集成。
这个小的技巧可以取得很好的效果,可以减轻过拟合并不能消除过拟合。2012年在ImageNet一千个类的分类问题取得第一名遥遥领先于第二名,相比于2011年冠军的结果提高了很多个百分点,从此卷积神经网络得到了大规模的关注。ReLU函数很早就出来了,是第一次用到是卷积神经网络,缓解梯度消失非根除梯度消失。
VGG网络:
2012年AlexNet的出现可以被看做深度学习deeplearning真正的一个开端,从此之后各种深度的卷积神经网络,如DCNN不断出来,后面不管深度学习、机器学习、机器视觉等顶级会议上边,很多问题都开始用卷积神经网络来做了,确实也取到了当前最好的效果。
在AlexNet的基础上继续改进出来的东西,由牛津大学视觉组2015年提出,被广泛应用于视觉领域的各类任务,如目标检测、图像分割,都用了它作为基础网络。
K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.international conference on learning representations. 2015
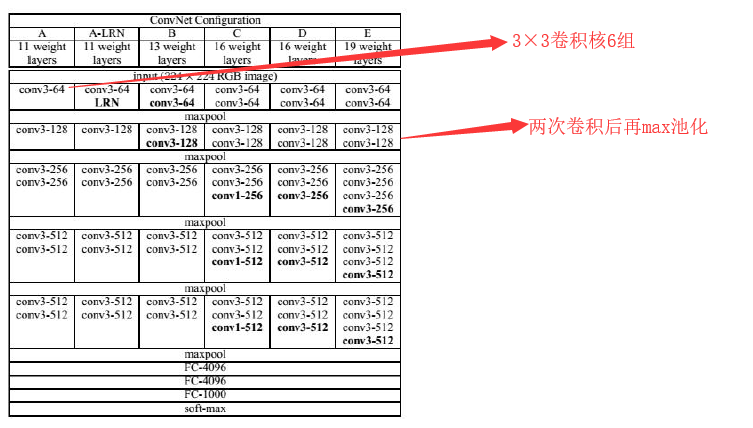
主要创新是采用了小尺寸卷积核,AlexNet是11×11、5×5...的卷积核,卷积核规模大了,参数增加了,占用的存储空间增加了,参数多了也容易造成过拟合不太好训练。
VGG所有卷积层都使用3×3的卷积核,且卷积步长为1。
为了保证卷积后的图像大小不变,对图像进行了填充,四周各填充1个像素0,卷积层输出和输出的图像尺寸是相等的,只有池化层来做图像的缩小工作,3×3的卷积核,四周只需添加一个像素的边界就够了。
所有池化层都采用2×2的核,步长为2。
除了最后一个全连接层之外,所有层都采用了ReLU激活函数。自AlexNet出现以后,至少在卷积神经网络里边,ReLU和它的改进形态会经常被使用,而传统的函数如tanh、sigmoid就不怎么被用了。
VGG网络都采用3×3的卷积核来代替大的卷积核,这样做可以吗?
作者回答:
用2个相连的3×3的卷积核可以实现5×5的卷积核,两个3×3的卷积核组合起来的视野就相当于一个5×5的卷积核的视野。
用3个相连的3×3的卷积核可以实现7×7的卷积核。
小卷积核有更少的参数,能够加速网络的训练和计算,同时可以减轻过拟合问题(小的卷积核使网络参数和规模更小了)。
两个3×3的卷积核有18个参数(不考虑偏置项),而一个5×5卷积核有25个参数。
除了参数减少,用多层小卷积核实现一个大卷积核的另外一个好处是多了几次激活函数,增加了非线性。
VGG具体结构(作者设计了六种):
GoogLeNnet网络:
自从AlexNet出来以后,对于图像类的任务出现了大量的改进的卷积神经网络结构,其中一个关键的主线是增大网络的规模,增加网络的深度(增加网络的层数)和宽度(增加每一层卷积核的个数)。网络的规模大了,只要训练样本够,训练效果还是比简单的网络好很多,这是被试验和实际经验反复证明过的。直接增加网络的规模将面临两个问题,首先,网络参数增加之后更容易出现过拟合,在训练样本有限的情况下这一问题更为明显;另一个问题是计算量的增加、存储开销。
需要既要增加网络的深度和宽度,又要限制网络的规模,这就是GoogLeNet要做的事情。
GoogLeNet由Google2014-2015年提出,主要创新是
①Inception机制,它对图像进行多尺度处理(用多个简单的卷积核逼近一个大的卷积核)。
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions, Arxiv Link: http://arxiv.org/abs/1409.4842.2014-2015.
这种机制带来的一个好处是大幅度减少了模型的参数数量,其做法是将多个不同尺度的卷积核、池化进行整合,形成一个Inception模块。
②去掉了全连接层,节省空间,减少计算量。AlexNet、VGG中很多参数都是在全连接层,因为全连接层是密集连接,卷积层占的参数少一些。
一个简单的Inception模块:
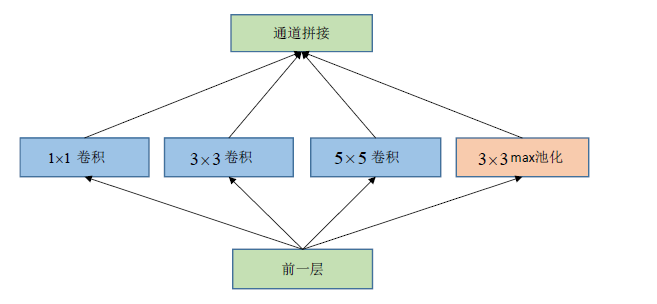
在通道拼接时图像大小不一致,只需做图像填充使各个通道尺寸一样。怎么让池化层图像输出不变小?只需步长变为1然后周围填充。
通道拼接而非通道相加,如4个16通道拼接起来为一个64通道的深度更大的图像,然后做后边的操作。
从理论上看,Inception模块的目标是用尺寸更小的矩阵来替代大尺寸的稀疏矩阵。即用一系列小的卷积核来替代大的卷积核,而保证二者有近似的性能。
用1×1卷积进行降维:不会改变图像的高度和宽度,只会改变通道数,可用于减少通道数。1×1卷积就相当于对每个输入图像的对应通道数据乘以一个系数,然后再对该组1×1卷积核对应的卷积结果图像对应位置相加得到一个等尺寸的图像。如果是24通道降到8通道只需8组1×1卷积核即可。
改进的Inception模块,先通道的降维再卷积,池化是先池化再通道降维:
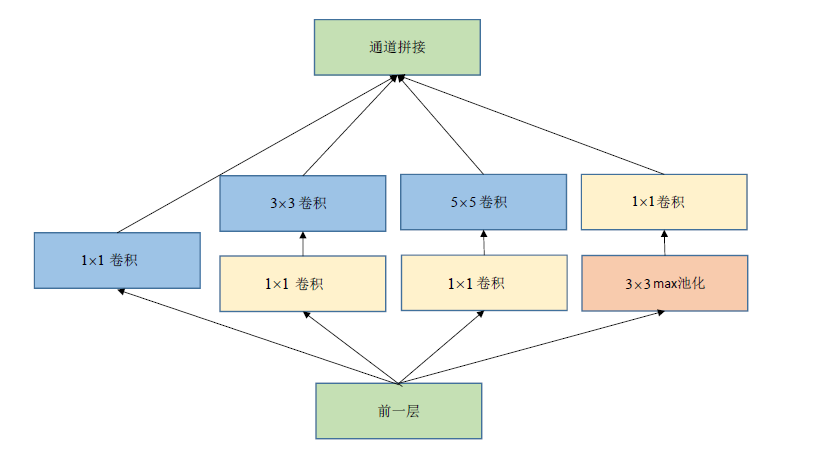
这样做的依据是利用多个小的卷积核代替大的卷积核,GoogLeNnet能够保证在网络深度比较大的时候,有效的降低参数的规模,可以观察caffee和tensorflow训出来的AlexNet、VGG、GoogLeNnet的模型有多大,网络的规模有多大也代表运算量有多大,把除输出层外的全连接去掉了有效了减少了参数的数量。
反卷积:
反卷积不是卷积函数的逆运算。
卷积运算可以用矩阵乘法来实现:

可以看到卷积核展开矩阵中kij重复出现,即卷积神经网络有称为权重共享的神经网络。
卷积运算等价于如下的矩阵乘法:y=Cx。
反向传播时的计算公式为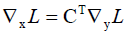 (由BP算法问题2的结论可知)
(由BP算法问题2的结论可知)
正向传播时,卷积层是用卷积矩阵C与图像向量x相乘;反向传播时,是用卷积矩阵的转置与传入的误差向量相乘,将误差项传播到前一层。
反卷积也称为转置卷积,它的操作刚好和这个过程相反。反卷积不是卷积的逆运算,因为卷积运算不可逆,卷积运算是把几个元素映射为1个元素无法逆向将1个元素映射为多个元素,不存在反函数。
正向传播时左乘矩阵CT,反向传播时左乘矩阵C。通过反卷积将卷积之前的图像重构出来,得到和卷积之前一样尺寸的图像,如C为4×16的矩阵,x是1×16的矩阵,相乘之后y是4×1的矩阵,此时反卷积一下,左乘CT,CT是16×4的矩阵,和y相乘,得到16×1的矩阵,即核输入图像尺寸一样,可以近似的替代卷积前的图像。
可以根据卷积以后的y,近似将卷积以前的x重建出来。
反卷积的应用:
卷积网络可视化
全卷积网络中的上采样(如将变小的图像再变大,如图像分割后的分类,就用到上采样。)
卷积层的可视化:
用反卷积进行卷积层可视化,将卷积网络学习到的特征图像左乘得到这些特征图像的卷积核的转置矩阵,将图像从特征图像空间转换到原始的像素空间,和原图像等尺寸,以发现是哪些像素激活了特定的特征图像,观察卷积核究竟起到了什么作用,如提取边缘信息、颜色信息、轮廓信息等。
Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks. European Conference on Computer Vision, 2013.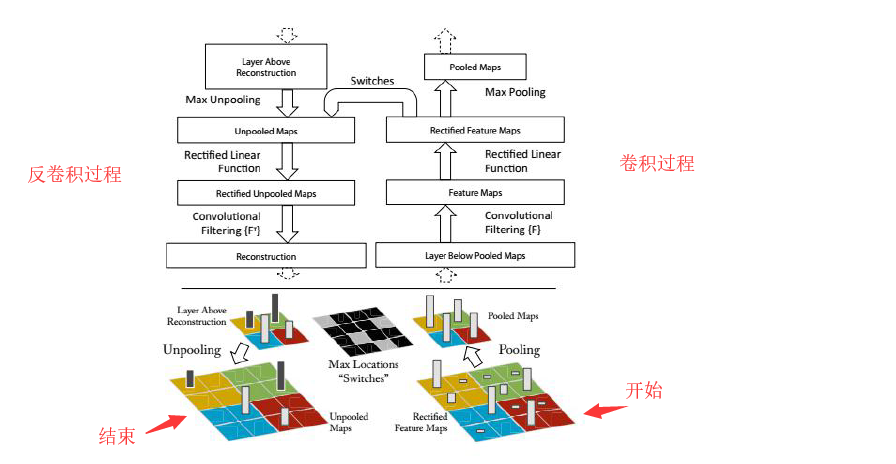


灰色表示卷积层提取的特征(由反卷积可视化得到),可以发现,前面的层提取的特征比较简单,越往后的卷积层提取的特征越复杂,这也是符合卷积神经网络设计的初衷的,从前往后对图像层层抽象, 可以观察每一层具体提取到了什么特征。
数学特征:
卷积神经网络和全连接神经网络本质上一样,只不过卷积神经网络是一个权重共享的全连接神经网络,还是满足万能逼近定理的。
万能逼近定理保证卷积神经网络可以拟合闭区间上任意一个连续函数。卷积层和池化层带尤其自身的特性。
Stephane Mallat. Understanding deep convolutional networks. Philosophical Transactions of the Royal Society A,2016.
根据卷积结果重构图像:
除了反卷积运算达到卷积层可视化的效果,还有其他更复杂的方法。
Aravindh Mahendran, Andrea Vedaldi. Understanding Deep Image Representations by Inverting Them. CVPR 2015
卷积网络实现从图像到向量的映射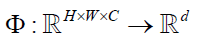 ,其中C是输入图像的通道个数,H是图像的高,W是图像的宽度,映射为d维向量。
,其中C是输入图像的通道个数,H是图像的高,W是图像的宽度,映射为d维向量。
给定一张图像的输出向量,我们要对它进行反向表示寻找输入图像,它是如下最优化问题的解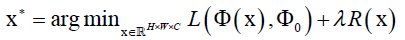 ,欧式距离损失函数
,欧式距离损失函数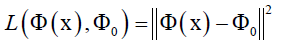 ,已知该张图像映射之后的向量为
,已知该张图像映射之后的向量为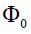 ,推它映射前的样子,这里损失函数可以取欧氏距离函数,正则化项R(x)对输入数据x水平方向和垂直方向边缘梯度尽可能小的约束,自然图像一般比较平滑不会特别尖锐。x是输入图像,x*是重构出来的图像,计算x*时,先初始化x为噪声图像,然后计算L对x的导数值利用反向传播和梯度下降法求解。
,推它映射前的样子,这里损失函数可以取欧氏距离函数,正则化项R(x)对输入数据x水平方向和垂直方向边缘梯度尽可能小的约束,自然图像一般比较平滑不会特别尖锐。x是输入图像,x*是重构出来的图像,计算x*时,先初始化x为噪声图像,然后计算L对x的导数值利用反向传播和梯度下降法求解。

可以发现重建出来的图像还是保留了源图像的主要信息。
本集总结