前言
语音识别和动作识别(Action、Activities) 等一些时序问题,通过微分方式可以视为模式识别方法中的变长模式识别问题。语音识别的基元为音素、音节,字母和句子模式是在时间轴上的变长序列;Action的基元为Pose,action的识别为pose的时间序列模式。
我们跟随时间的脚步,试图解释现在、理解过去、甚至预测未来........ 在概率分析的层面,RNN通过循环结构展开处理变长问题,对不同的长度训练不同的概率模型,并以参数的形式存储在网络中,成为天生适合处理时序分析的复杂模型。
多层网络
一部分最成功的深度学习方法涉及到对人工神经网络的运用。人工神经网络受到了1959年由诺贝尔奖得主大卫·休伯尔(David H. Hubel)和托斯坦·威泽尔(Torsten Wiesel)提出的理论启发。休伯尔和威泽尔发现,在大脑的初级视觉皮层中存在两种细胞:简单细胞和复杂细胞,这两种细胞承担不同层次的视觉感知功能。受此启发,许多神经网络模型也被设计为不同节点之间的分层模型[12]。
福岛邦彦提出的新认知机引入了使用无监督学习训练的卷积神经网络。燕乐存将有监督的反向传播算法应用于这一架构[13]。事实上,从反向传播算法自20世纪70年代提出以来,不少研究者都曾试图将其应用于训练有监督的深度神经网络,但最初的尝试大都失败。赛普·霍克赖特(Sepp Hochreiter)在其博士论文中将失败的原因归结为梯度消失,这一现象同时在深度前馈神经网络和递归神经网络中出现,后者的训练过程类似深度网络。在分层训练的过程中,本应用于修正模型参数的误差随着层数的增加指数递减,这导致了模型训练的效率低下[14][15]。
赛普·霍克赖特和于尔根·施密德胡伯提出的长短期记忆神经网络(long short term memory,LSTM)[16]。2009年,在ICDAR 2009举办的连笔手写识别竞赛中,在没有任何先验知识的情况下,深度多维长短期记忆神经网络取得了其中三场比赛的胜利[17][18]。
斯文·贝克提出了在训练时只依赖梯度符号的神经抽象金字塔模型,用以解决图像重建和人脸定位的问题[19]。
参考文章:DNN结构演进之RNN ,作为预备材料。
摘要
RNN通过引入神经元定向循环用于处理边变长问题,由此被称为递归网络; 再通过其他神经元(如果有自我连接则包括自身)的输入和当前值的输入,进行加权求和(logit)之后重新计算出新的行为,保存之前记忆。 通过时间轴展开成类似于FNN的新构架,因此可以使用BP算法进行网络训练; 而根据时间展开长序列会产生极深FNN,容易产生梯度的消失与爆炸问题,因此引入了LSTM-长短期记忆,保持一个常数误差流,以此保证梯度的不会爆炸消失; 用于恒稳误差,通常使用一个门单元进行误差流控制。...
最初的RNN并没有从反传函数的角度去考虑梯度消失问题,而是从结构上引入“直连”结构,冀希望于此从概率分析的角度来缓冲深度网络的参数反传的“消失”和“爆炸”问题。
LSTM网络
下文是转自与百度贴吧的文章:http://tieba.baidu.com/p/3405569985


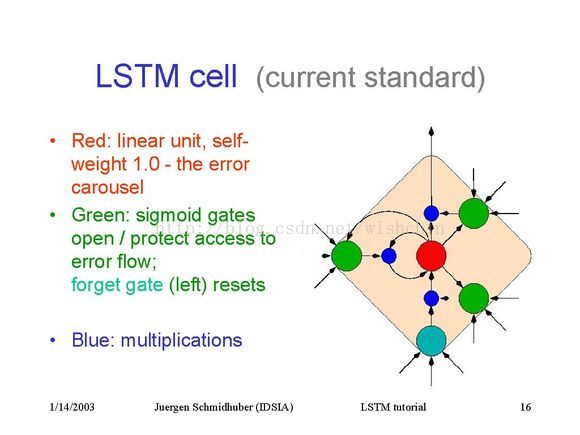
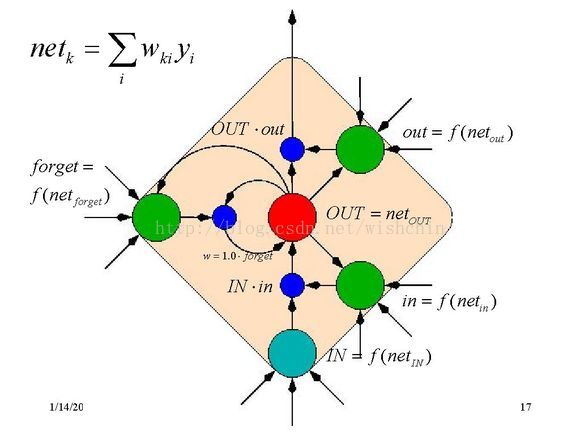
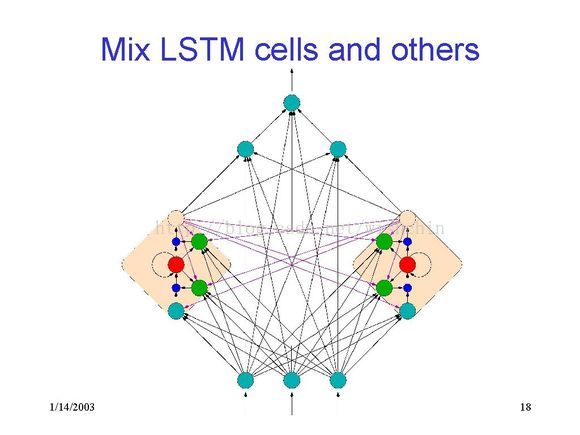
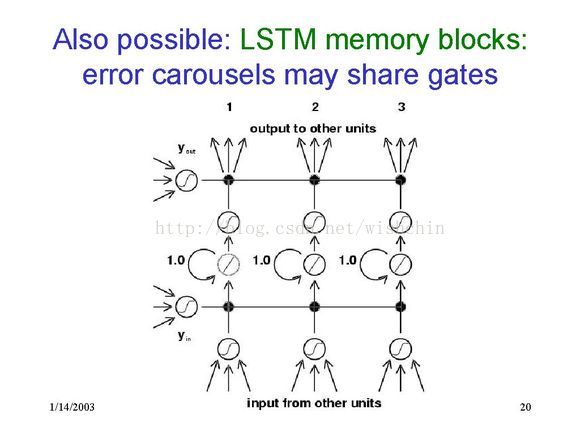
一大堆LSTM可以共用一些 IN/OUT Gate

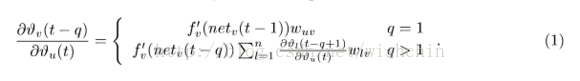
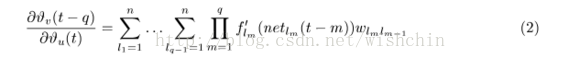
从后面的分析可以看出,
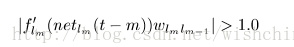 and
and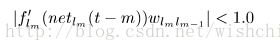 and
and———...................———我是华丽的————.................————分割线————..................————
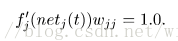 and
and and
and虽然自己对自己的权重被封死了,但这样误差就能穿越时空往回传了,并且增加了IN和OUT两个网络来控制。
完毕..............
仅看LSTM的实施步骤是超级简单的,这些数学推倒只是告诉我们为什么要这样做......................
问题、疑问?
好吧,终于算是认同这个模型了。从BPTT的角度来看,强行设定一些神经元的自连接权重为1 ,并取消和其它神经元的连接权重,使得他们的贡献相当于直接穿过时间作用到输出上,故误差反向传播时是一阶的,不存在衰减或爆炸问题。如果换种理解方式,这本质上是在用神经网络训练一个有限状态机,加入权重为1的积分器使得可以接受类似A*B*C....的正则语言,也就是说在关键字符中间插入若干任意字符不影响输出结果,故具有长时记忆效果。
现在我还存有几点问题:
1.那怎么训练呢?
2.为什么我们不直接采用延时机制实现constant error flow?
我的看法:延时和临时存储本质上是一样的,都是把历史数据直接当作当前数据输入,使得误差反向传播只是一阶。但临时存储是可以控制的,而延时长度暂时不知如何灵活控制。
3.从有限状态机的角度来看,LSTM分辨一定的语言至少需要多少神经元?
4.从动力系统的角度分析是否更简单?
2. 延时就是指net_j(t)=求和W_ijτ * x_i(t-τ) ;
3. 不一定,比如要设计一个只需分辨是否1*0的状态机,*为任意字串,那么只许3个单元就可以了,而这样只需3个单元的状态机却可以识别任意有限长度的字串,所以并不是词向量维度越高需要越多的神经元。直观感觉是取决于需要分辨的字串总数(分类类别数),但又和字串之间的关联也有关,所以不知道怎么分析。
4.看到一篇从动力系统分析TDNN的(就是2说的延时)paper,貌似不能用来分析LSTM= =。
"延时的意思就是把时间当作空间处理?"--反正我也是这么理解的,按理说直接把时间当做空间处理不会有问题,但经过LSTM这个理论洗脑后我开始明白时间比空间更具有长程关联(跨度大的统计/重要特征-好吧,这词好像是我造的?),而且分布密度低,所以虽然TDNN也可以处理时间序列,但是为了密度极低的长程关联要花费的代价实在太高,而且随着跨度的增加要不停增加神经元(LSTM不一定,因为长程特征相比来讲极少,增加的神经元数不必正比于跨度的增加)。要弥补TDNN这一点也不是没有办法,粗略的想了想还是挺麻烦的。
注:
说统计/重要特征,是因为LSTM貌似没有统计学习过程,而只有最小化误差的过程,我希望它能学到统计特征但事实上它只能学到用来减小误差的特征。但我觉得只需要在前面加DL即可,弥补它的统计能力,主要针对短程统计特征(好比图片中的小线条,边边角角)
..................................................
2015 年,百度公开发布的采用神经网络的 LSTM+CTC 模型大幅度降低了语音识别的错误率。采用这种技术在安静环境下的标准普通话的识别率接近 97%。
CTC 是 Connectionist Temporal Classification 的缩写,详细的论文介绍见论文 “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks”
CTC 的计算实际上是计算损失值的过程,就像其他损失函数一样,它的计算结果也是评估网络的输出值和真实差多少。
声音波形示意图
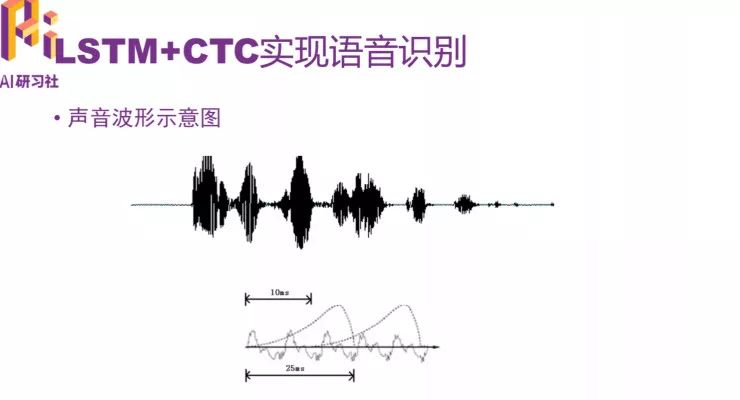
在开始之前,需要对原始声波进行数据处理,输入数据是提取过声学特征的数据,以帧长 25ms、帧移 10ms 的分帧为例,一秒钟的语音数据大概会有 100 帧左右的数据。
采用 MFCC 提取特征,默认情况下一帧语音数据会提取 13 个特征值,那么一秒钟大概会提取 100*13 个特征值。用矩阵表示是一个 100 行 13 列的矩阵。
把语音数据特征提取完之后,其实就和图像数据差不多了。只不过图像数据把整个矩阵作为一个整体输入到神经网络里面处理,序列化数据是一帧一帧的数据放到网络处理。
如果是训练英文的一句话,假设输入给 LSTM 的是一个 100*13 的数据,发音因素的种类数是 26(26 个字母),则经过 LSTM 处理之后,输入给 CTC 的数据要求是 100*28 的形状的矩阵(28=26+2)。其中 100 是原始序列的长度,即多少帧的数据,28 表示这一帧数据在 28 个分类上的各自概率。在这 28 个分类中,其中 26 个是发音因素,剩下的两个分别代表空白和没有标签。
设计的基本网络机构

原始的 wav 文件经过声学特征提取变成 N*13,N 代表这段数据有多长,13 是每一帧数据有多少特征值。N 不是固定的。然后把 N*13 矩阵输入给 LSTM 网络,这里涉及到两层双向 LSTM 网络,隐藏节点是 40 个,经过 LSTM 网络之后,如果是单向的,输出会变成 40 个维度,双向的就会变成 80 个维度。再经过全连接,对这些特征值分类,再经过 softmax 计算各个分类的概率。后面再接 CDC,再接正确的音素序列。
真实的语音识别环境要复杂很多。实验中要求的是标准普通话和安静无噪声的环境。
如果对代码讲解(详细代码讲解请点击视频)感兴趣的话,可以复制链接中的代码:https://github.com/thewintersun/tensorflowbook/tree/master/Chapter6
运行结果如下:

参考:基于RNN的语音识别技术