jdk6和7服务器端(-server) 默认的新生代的垃圾回收器为:PS Scavenge,老年代默认的垃圾回收器为:PS MarkSweep
目前项目使用了jdk7,tomcat7,经常出现内存堆使用量200s持续超过堆总内存80%,触发报警。
由于项目最近的更新为jdk和tomcat升级,从6升级到7,而之前使用tomcat6时并未报警,是因为tomcat的一个监听器行为模式变更造成的
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
在tomcat6中,它会每隔一个小时3600s(1小时)调用一次System.gc()方法,手动执行Full GC,使老年代中的无用对象每隔一小时清理一次;
在tomcat7中,事情发生了变化,它会每隔Long.Max_Value -1 毫秒秒执行一次System.gc()
/*
* Several components end up calling
* sun.misc.GC.requestLatency(long) which creates a daemon
* thread without setting the TCCL.
*
* Those libraries / components known to trigger memory leaks
* due to eventual calls to requestLatency(long) are:
* - javax.management.remote.rmi.RMIConnectorServer.start()
*
* Note: Long.MAX_VALUE is a special case that causes the thread
* to terminate
*
*/
if (gcDaemonProtection) {
try {
Class<?> clazz = Class.forName("sun.misc.GC");
Method method = clazz.getDeclaredMethod(
"requestLatency",
new Class[] {long.class});
method.invoke(null, Long.valueOf(Long.MAX_VALUE - 1));
} catch (ClassNotFoundException e) {
if (JreVendor.IS_ORACLE_JVM) {
log.error(sm.getString(
"jreLeakListener.gcDaemonFail"), e);
} else {
log.debug(sm.getString(
"jreLeakListener.gcDaemonFail"), e);
}
} catch (SecurityException e) {
log.error(sm.getString("jreLeakListener.gcDaemonFail"),
e);
} catch (...) {
...
}
}
调用GC类的方法,最终开启一个优先级为2的Deamon线程,在一个无限循环中调用System.gc()
public void run() {
while(true) {
synchronized(GC.lock) {
long var1 = GC.latencyTarget;
if(var1 == 9223372036854775807L) {
GC.daemon = null;
return;
}
long var4 = GC.maxObjectInspectionAge();
if(var4 >= var1) {
System.gc();
var4 = 0L;
}
try {
GC.lock.wait(var1 - var4);
} catch (InterruptedException var8) {
;
}
}
}
}
Long.Max_Value -1 毫秒换算成时间,是62亿年,这个时间太长了,因此我们指望不了这个功能帮你什么忙,并且最好的方式应该是应用自己在适当的时候触发Full GC
回到实际项目中,老年代持续增加,平均每天会触发1~2次Full GC,这个次数倒是不多;由于老年代内存使用量长时间居高不下,而新生代的内存使用量随着业务频率的变化,有时候迅速撑满,触发Young GC;有时候又增长缓慢,如果(Young Memory + Turned Memory / Total Memeory) > 80%,就会报警。
总的来说,老年代内存占用量长期偏高,增长较快,是导致这个问题的主要原因。
先来了解垃圾回收算法的一些术语:
PS Scavenge:新生代垃圾回收器,使用复制算法(指针碰撞,内存分为Eden,S1,S2),并行(不能和App线程同时运行,GC会stw)的多线程收集器,它关注的系统的吞吐量,有效的利用cpu,尽快完成任务,不太关注线程停顿时间。它有一个自适应调整策略(可以通过-XX:-UseAdaptiveSizePolicy关闭,默认开启),导致虚拟机参数配置-XX:SurvivorRatio参数没有实际意义(S1,S2的大小会不定的变化,实际观察来看,S1和S2的大小是每次回收后剩余的对象所占用空间的大小),适用于高吞吐量的场景,而不适合时间敏感的场景
我们的系统是一个后端任务系统,单纯从系统属性来分析,他是很适合使用PS Scavenge、PS MarkSweep的,是什么导致它变得不适合呢?
分析原因:
1.系统大量引入了MQ、ServiceFramework,调用三方系统,使用的是nio封装的长连接,在每次调用后,连接依然还在; 2.由于1产生了很多长连接,在某次minor GC回收后s1空间大小为n,下次minor GC回收时,剩余存活对象占用空间 > n,此时如果系统没有重新设置S空间大小,对象更易进入老年代 3.在2的基础上,一些长连接进入老年代后,由于网络异常、连接断开或其他因素,已不可用,伴生对象仍然在老年代中,但它需要等到下次full GC时才会回收
此时我们已经想到一个解决办法,那就是如何让O区在空间用完前就执行Full GC,并且对象不过快过早进入O区,这个问题就可完美解决,而这是PS MarkSweep收集器不具备的功能。
下面来了解一下标记清理算法:
标记-清除MarkSweep:把内存分成很多块,对象没有引用了就标记出来,标记完后统一回收对象,清除后空间不再连续,分配大对象时可能无法找到足够空间将触发一次垃圾回收,如果在老年代,将触发Full GC
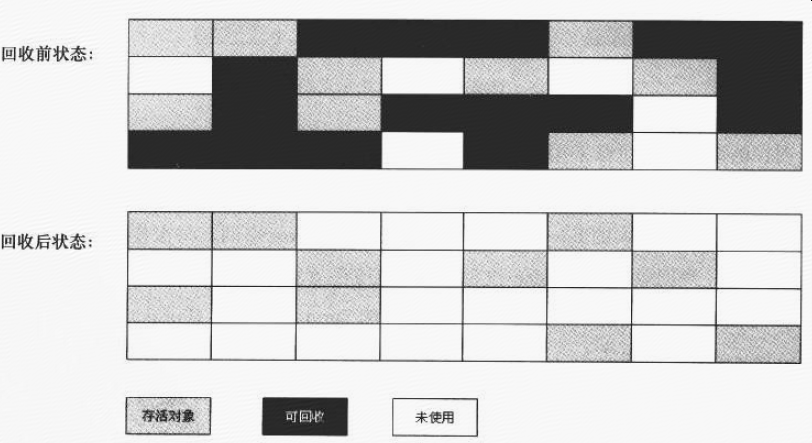 (《深入理解Java虚拟机第二版》图)
(《深入理解Java虚拟机第二版》图)
PS MarkSweep:老年代收集器,是一个可以并行标记和清理垃圾的回收器,无整理,使用的是空闲列表的方式,就像一个多线程版本的Serial Old收集器
能做到老年代提前GC的垃圾回收器有CMS收集器,但它的搭配伙伴是ParNew,由ParNew来执行新生代垃圾回收。
ParNew:多个线程并行(app线程需等待,stop the world)收集,新生代收集器,最大的优点是可以配合CMS回收器,默认gc线程数和cpu数量相同,当cpu太多,如32个时,可以使用-XX:ParallelGCThreads来限制gc线程个数
CMS:(-XX:+UseConcMarkSweepGC)分为初始标记(并行,app线程挂起 stop the world,仅标记GC Roots关联的对象,速度很快)、并发标记(GC Roots对象向下追踪)、重新标记(并行,app线程挂起 stop the world,矫正并发标记时的修改,时间稍长)、并发清除,垃圾收集过程中最耗时的并发标记、并发清除都可以和用户线程一起工作,所以,整体来说,它的内存回收过程与app线程是一起并发执行的,stop the world的时间较短;
但并发执行也意味着此时会与app线程竞争cpu资源,app会变慢,系统吞吐量降低,gc线程数为(cpu+3)/4个;无法处理浮动垃圾:即stop the world后的并发阶段,生成的对象。jdk1.6会在老年代占比92%时触发full gc,以预留空间给浮动对象,参数为(-XX:CMSInitiatingOccupancyFraction=80 手动设定),设置太高时可能会出现Concurrent Mode Failure(老年代剩余空间大于 新生代 Eden + S1的和),不建议设置太高
CMSInitiatingOccupancyFraction = (100 - MinHeapFreeRatio) + (CMSTriggerRatio * MinHeapFreeRatio / 100)
MinHeapFreeRatio默认40、 指定 jvm heap 在使用率小于 n 的情况下 ,heap 进行收缩 ,Xmx==Xms 的情况下无效
CMSTriggerRatio默认80, 设置由-XX:MinHeapFreeRatio指定值的百分比的值。默认是80%
计算结果
CMSInitiatingOccupancyFraction=92
查看方式:jinfo -flag CMSInitiatingOccupancyFraction pid
CMS基于标记-清除算法,收集结束后会有大量碎片空间,不利于大对象(当前连续的碎片空间已不能满足某个对象分配所需内存时,这里的大对象相对而言的)分配,大对象分配失败时,会触发一次FullGC,CMS为此提供了-XX:+UseCMSCompactAtFullCollection开关(默认开启),在没有足够的连续空间时,启动碎片整理合并,但此时stop the world时间相应增加。默认情况下,每次Full GC都会对老年代进行碎片整理
使用ParNew + CMS后
1.Eden、S1、S2空间大小固定,相对于PS Scavenge收集器,S1、S2空间更大,能容纳更大的对象,这样对象在S1、S2呆的时间更容易长久,在对象被回收前进入老年代的概率大大降低 2.老年代对象增加的速度明显变慢,并且在jdk6、jdk7环境默认参数下,在 占用空间 / 总空间 > 92%时,及时回收掉无用对象,老年代内存使用量大幅降低 备注:须知老年代在执行Full GC后对象应该是大大降低的,如果GC后对象并未下降太多,可能有两种情况:老年代内存分配较少程序有内存泄露的风险
如果使用CMS后还会有堆内存长时间使用率 > 80%的异常情况,我们可根据New空间和Turned空间的空间总占用量极限值来推导参数CMSInitiatingOccupancyFraction的合适值
如新生代 1000M、老年代1000M -Xmx-Xmn
则Eden(800m) S1(100M) S2(100M) Tenured(1000M)
Eden + S1 = 900M
Tenured* 92% = 920M
则最大推内存使用率为 900M + 920M = 1820M
最大堆内存使用率 1820 / 2000 = 91%
当然这是极端情况,如果你的内存占用率要求不能长时间高于80%,则可以通过配置新生代、老年代的比例,以及-XX:CMSInitiatingOccupancyFraction=n参数来保证
内存分配了,如果一直不使用也是一种浪费,我们的目标不是完全杜绝堆利用 > 80%,而是长时间大于80%
目前来看,默认的老年代92%时进行Full GC已经满足了我们的需求
HotSpot为什么perm和heap要一起回收:因为两块区域可能有相互引用的关系,分开回收比较困难
由于新生代采用复制算法进行垃圾收集,所以可能会由于分配担保导致一次full gc,空间分配担保机制可使对象提前进入老年代
也就是Eden + S1 > Turned的剩余连续空间 或者 turned剩余连续空间 > 历次晋升到老年代对象空间大小的平均值, 并且 -XX:HandlePromotionFailure(JDK6 Update 24之后这个参数就没有意义了,也就是强制使用空间分配担保策略了)为是否开启担保,如果担保,就进行Minor GC,如果无担保则会Full GC,也就是
JDK6 Update24之后的空间分配担保:如果老年代剩余的连续空间大小大于新生代所有对象总和或大于历次晋升到老年代的平均大小,执行Minor GC,否则Full GC
担保失败是指执行minor gc后,剩余的空间survior空间装不下,不得不触发一次Full GC,这个路径相对于直接执行Full GC,中间多了一步Minor GC,而Full GC本身会回收新生代、老年代、方法区(Major GC仅回收老年代,我们不拘泥于MajorGCFullGC这样的区别,都当成一次比较深度的GC来理解)
大对象直接进入老年代,避免在Eden和Survivor之间进行大量内存复制
G1:充分利用多核环境缩短stop-the-world,通过并发执行减少app线程停顿时间;拥有分代收集,将整个堆划分为多个相等的独立区域,这样,老年代和新生代不再是物理隔离的了,它们有可能是挨着的,且不只是两块区域,但可以独立管理整个堆,整体上是标记-整理算法;可预测的停顿时间,可以知道在长度多少毫秒时间片段内,垃圾收集时间不超过n毫秒
GC日志:
jvm参数:-XX:MaxPermSize=400M -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=80 -XX:+PrintGCDetails -Xloggc:D:gc.log
3324K->152K(11904K)表示GC前堆已使用量 -> GC后堆已使用容量(堆总容量)
有书上(《深入理解java虚拟机》)说GC、FULL GC说明的是停顿类型,若是Full GC则在GC时产生了stop-the-world,也就是用它来区分是否发生了stop-the-world,而不是用来说明是对哪个代进行回收的(Young代还是turned代、Perm),这个说法应该是有误的
根据GC算法原理,每个代的回收都会有GC Roots分析可达性,Young代也是如此,因此他们都会有stop-the-world(虚拟机的某些机制可加速,如在安全点的基础上,OopMap快速找出栈上有普通对象引用的区域,避免挨个遍历栈的内存区域)。
84.884: [GC 84.884: [ParNew: 18175K->1358K(19136K), 0.0099206 secs] 74132K->57459K(109692K), 0.0100078 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] 85.104: [GC 85.184: [ParNew: 18382K->1160K(19136K), 0.0042949 secs] 74483K->58053K(109692K), 0.0043920 secs] [Times: user=0.00 sys=0.00, real=0.08 secs] 两次普通GC 新生代回收空间 堆总的回收空间 (新生代回收-堆总空间回收) 第一条GC日志: 16817 16673 144 第二条GC日志: 17222 16430 792 可以看到每次MinorGC后,新生代回收的空间都是大于了堆总的回收空间,这说明有新生代的对象进入了老年代,而这两个GC日志间并没有老年代GC日志,ParNew是新生代回收器
Full GC会回收老年代内的对象,Hotspot中还会回收Perm空间,同时,触发Full GC一般是因为需要往老年代放入对象,而这个操作一般都伴随了先前一次的Young GC
-Xmx150M -Xms150M -XX:+PrintGCDetails 不断插入1M的大对象,且不释放引用时的GC日志
[GC [PSYoungGen: 43187K->5680K(44800K)] 103604K->101937K(147200K), 0.0601768 secs] [Times: user=0.03 sys=0.06, real=0.06 secs]
[Full GC [PSYoungGen: 5680K->0K(44800K)] [PSOldGen: 96257K->101848K(102400K)] 101937K->101848K(147200K) [PSPermGen: 3718K->3718K(21248K)], 0.1401878 secs] [Times: user=0.01 sys=0.00, real=0.14 secs]
可以看到这种极端情况下Full GC会同时触发Minor GC、Turned GC、PermGen GC,同时Minor GC依然用的青年代的收集器,所以这次Full GC,其实是有多个阶段的,因为他们不是同时进行的;
虚拟机性能监控指令:
jps
jps -m 显示main函数的参数
jps -v 显示虚拟机启动参数
jstat -gcutil pid 查看垃圾回收各个代的内存情况,百分比,gc时间
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
8.90 0.00 40.80 60.12 - - 238 1.165 16 0.080 1.245
SOS1EO分别是两个Survior空间的使用率,Eden空间、老年代使用率,在java8中引入了MetaSpace
jinfo 查看虚拟机配置参数
jmap -dump 生成java堆转储快照到文件
jmap -heap 显示堆详细信息,如回收器、参数、分代情况
jmap -histo 堆中对象统计
jhat xxx.bin 解析jmap -dump出来的文件,会生成一个http server,展示页面中包括了各种信息
jstack pid查看线程的堆栈信息
jstack -l pid额外查询锁的附加信息
G1:-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:+PrintTenuringDistribution -XX:+UseG1GC -XX:+DisableExplicitGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:ParallelGCThreads=4 -Xloggc:/export/Logs/gclogs
再谈引用:强引用、软引用、弱引用、虚引用
强引用:比如new,只要强引用还存在,垃圾收集永远不会回收掉对象
软引用:对于被软引用关联的对象,在系统发布内存溢出之前,会把这些对象列入可回收返回,进行二次垃圾回收
弱引用:只被弱引用关联的对象,只能生存到下次垃圾回收
虚引用:一个对象是否有虚引用,对其生命周期毫不影响
CMS笔记
cms,担保失败,会使用Serial Old搜集器重新对老年代进行垃圾回收,这个和G1相同
cms垃圾回收器只回收老年代,可以通过启动参数配置,在重新标记前执行一次young gc,降低remark的工作量,提高老年代的GC速度
有两种情况会触发fullgc:
1.担保失败, 指minor gc时,survivor空间放不下,对象只能放到老年代,而此时老年代也放不下
2.并发失败comcurrent mode failure 指cms gc过程中,同时有对象放入老年代,而此时老年代空间不足
2018-08-06T20:39:36.689+0800: 3600.552: [Full GC (System) 3600.552: [CMS: 130965K->149171K(1835008K), 0.7744930 secs] 925033K->149171K(3063808K), [CMS Perm : 121859K->120837K(262144K)], 0.7748330 secs] [Times: user=0.77 sys=0.00, real=0.77 secs]
System.gc()不会直接回收新生代
CMS日志
4.595: [GC 4.595: [ParNew: 19136K->1808K(19136K), 0.0042364 secs] 31584K->15824K(49088K), 0.0043025 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.793: [GC 4.793: [ParNew: 18832K->1901K(19136K), 0.0021414 secs] 32848K->15917K(49088K), 0.0021969 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.902: [GC 4.902: [ParNew: 18925K->1748K(19136K), 0.0024316 secs] 32941K->16459K(49088K), 0.0026722 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.977: [GC 4.977: [ParNew: 18772K->1912K(19136K), 0.0016380 secs] 33483K->17185K(49088K), 0.0016828 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
老年代阈值导致的cms?,怎么这么低,根据preclean后的young gc,可能是由于担保失败造成的,young gc后,suviror装不下,但上次yg后,应该不足以触发担保失败
则极有可能是老年代的连续空间不足以分配某个对象,然后这看起来也不太可能,解释权只能给JVM自动触发动态策略了(这个动态策略极有可能是50%左右第一次触发),如果使用了-XX:+UseCMSInitiatingOccupancyOnly,这个参数是会生效的
4.979: [GC [1 CMS-initial-mark: 15272K(29952K)] 17521K(49088K), 0.0008371 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
4.980: [CMS-concurrent-mark-start]
5.015: [CMS-concurrent-mark: 0.035/0.035 secs] [Times: user=0.06 sys=0.00, real=0.04 secs]
5.015: [CMS-concurrent-preclean-start]
5.016: [CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.016: [CMS-concurrent-abortable-preclean-start]
5.071: [GC 5.071: [ParNew: 18933K->1539K(19136K), 0.0018825 secs] 34205K->17552K(49088K), 0.0019298 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]
5.157: [GC 5.157: [ParNew: 18563K->1886K(19136K), 0.0012275 secs] 34576K->17899K(49088K), 0.0012685 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.246: [GC 5.246: [ParNew: 18910K->1413K(19136K), 0.0029214 secs] 34923K->18444K(49088K), 0.0029696 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.350: [GC 5.350: [ParNew: 18437K->1859K(19136K), 0.0019435 secs] 35468K->19389K(49088K), 0.0020356 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.432: [GC 5.432: [ParNew: 18883K->2112K(19136K), 0.0021222 secs] 36413K->20335K(49088K), 0.0021679 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]
5.507: [GC 5.507: [ParNew: 19136K->1689K(19136K), 0.0020429 secs] 37359K->21727K(49088K), 0.0020890 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.581: [GC 5.581: [ParNew: 18713K->1472K(19136K), 0.0011870 secs] 38751K->21511K(49088K), 0.0012326 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.681: [GC 5.681: [ParNew: 18496K->2112K(19136K), 0.0013845 secs] 38535K->22240K(49088K), 0.0014276 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]
5.755: [GC 5.755: [ParNew: 19136K->2103K(19136K), 0.0022780 secs] 39264K->23213K(49088K), 0.0023245 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.850: [GC 5.850: [ParNew: 19127K->1370K(19136K), 0.0018551 secs] 40237K->23337K(49088K), 0.0018978 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
5.915: [GC 5.915: [ParNew: 18394K->1720K(19136K), 0.0015151 secs] 40361K->23688K(49088K), 0.0015586 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]
5.985: [GC 5.985: [ParNew: 18744K->1816K(19136K), 0.0022302 secs] 40712K->24297K(49088K), 0.0022801 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.067: [GC 6.067: [ParNew: 18840K->2049K(19136K), 0.0024256 secs] 41321K->25281K(49088K), 0.0024695 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.149: [GC 6.149: [ParNew: 19073K->1358K(19136K), 0.0018667 secs] 42305K->25242K(49088K), 0.0019145 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
6.227: [GC 6.227: [ParNew: 18382K->2112K(19136K), 0.0015543 secs] 42266K->25996K(49088K), 0.0015970 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
6.299: [GC 6.299: [ParNew: 19136K->1845K(19136K), 0.0028023 secs] 43020K->26721K(49088K), 0.0028659 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.388: [GC 6.388: [ParNew: 18869K->2112K(19136K), 0.0020894 secs] 43745K->27566K(49088K), 0.0021431 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.472: [GC 6.472: [ParNew: 19136K->1358K(19136K), 0.0019375 secs] 44590K->27416K(49088K), 0.0019836 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.542: [GC 6.542: [ParNew: 18382K->1717K(19136K), 0.0012241 secs] 44440K->27776K(49088K), 0.0012702 secs] [Times: user=0.00 sys=0.02, real=0.00 secs]
6.606: [GC 6.606: [ParNew: 18741K->1533K(19136K), 0.0020919 secs] 44800K->28156K(49088K), 0.0021414 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.700: [GC 6.700: [ParNew: 18557K->1448K(19136K), 0.0018522 secs] 45180K->28531K(49088K), 0.0018970 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.771: [GC 6.771: [ParNew: 18472K->1901K(19136K), 0.0017114 secs] 45555K->29263K(49088K), 0.0017553 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.814: [GC 6.814: [ParNew: 18925K->2112K(19136K), 0.0020745 secs] 46287K->29806K(49088K), 0.0021210 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.871: [GC 6.871: [ParNew (promotion failed): 19136K->19136K(19136K), 0.0058138 secs]6.877: [CMS6.877: [CMS-concurrent-abortable-preclean: 0.232/1.862 secs] [Times: user=2.13 sys=0.23, real=1.86 secs]
(concurrent mode failure): 28066K->28158K(29952K), 0.0945723 secs] 46830K->28158K(49088K), [CMS Perm : 17828K->17805K(21248K)], 0.1005691 secs] [Times: user=0.09 sys=0.00, real=0.10 secs] 执行了serial old gc,用了0.1sec
7.584: [Full GC 7.584: [CMS: 29951K->29943K(29952K), 0.0865138 secs] 49086K->30785K(49088K), [CMS Perm : 17811K->17811K(29868K)], 0.0865800 secs] [Times: user=0.09 sys=0.00, real=0.09 secs]
FULL GC会回收老年代和永久代,普通的cms gc只会回收老年代
G1
-把一块内存分成很多块固定大小的内存:每个region可以为:EDENSURVIORHOLDUN USED
OLD GC:
初始标记:young gc时稍带会执行初始标记,如gc log里面的GC pause (young)(inital-mark)