ConcurrentHashMap融合了Hashtable和HashMap二者的优势。
Hashtable是做了线程同步,HashMap未考虑同步。所以HashMap在单线程下效率较高,Hashtable在多线程下同步操作能保证程序的正确性。 但是Hashtable每次执行同步操作都需要锁住整个结构。
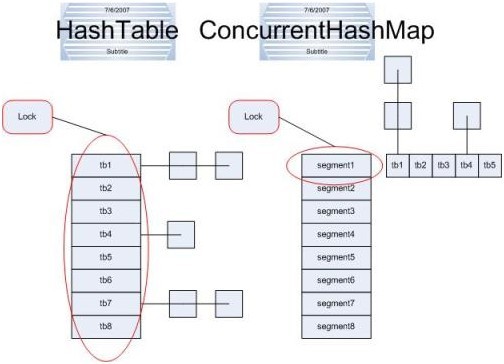
ConcurrentHashMap的出现就是为了解决Hashtable同步lock整个数据结构的问题。ConcurrentHashMap锁的方式是细颗粒度。
ConcurrentHashMap将Hash表分为16个桶(默认值),诸如get/put/remove操作只需要锁着需要的单个桶即可。
ConcurrentHashMap只有在size等操作的时候才会锁住整个Hash表。
下面是自己实现的一个ConcurrentHashMap的本地缓存的例子:ConcurrentHashMap 和Guava cache相比,需要自己显示的删除缓存

import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapTest {
private static ConcurrentHashMap<String, String> cacheMap = new ConcurrentHashMap<>();
/**
* 获取缓存的对象
*
* @param account
* @return
*/
public static String getCache(String account) {
account = getCacheKey(account);
// 如果缓冲中有该账号,则返回value
if (cacheMap.containsKey(account)) {
return cacheMap.get(account);
}
// 如果缓存中没有该账号,把该帐号对象缓存到concurrentHashMap中
initCache(account);
return cacheMap.get(account);
}
/**
* 初始化缓存
*
* @param account
*/
private static void initCache(String account) {
// 一般是进行数据库查询,将查询的结果进行缓存
cacheMap.put(account, "18013093863");
}
/**
* 拼接一个缓存key
*
* @param account
* @return
*/
private static String getCacheKey(String account) {
return Thread.currentThread().getId() + "-" + account;
}
/**
* 移除缓存信息
*
* @param account
*/
public static void removeCache(String account) {
cacheMap.remove(getCacheKey(account));
}
}