1. VOC的格式
VOC主要有三个重要的文件夹:Annotations、ImageSets和JPEGImages
JPEGImages 文件夹
该文件夹下存放着所有的训练集图片,格式都是.jpg
需要注意的是命名格式,虽然对命名没有特别要求,但是最好按照官方的命名方法,如000001.jpg,000123.jpg,然后在这个文件夹里就没有其他东西了。
Annotations 文件夹
该文件夹下存放的是每一个图片的标注信息,文件都是.xml格式,文件名和图片名是一致的对于该xml的格式,可以参考一下示例:

以上是使用标注工具标注的人脸,(在下面会提到,自己写的一个比较简陋的标注工具 ^^),该图片的名字是000001.jpg
然后会在Annotations文件夹下面生成一个000001.xml文件与之对应:
<annotation>
<folder>VOCType</folder>
<filename>000001.jpg</filename>
<source>
<database>VOC</database>
</source>
<size>
<width>485</width>
<height>324</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>face</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>287</xmin>
<ymin>57</ymin>
<xmax>351</xmax>
<ymax>150</ymax>
</bndbox>
</object>
</annotation>
这是一个基本的格式,其中的object标签保存的就是人脸的位置信息,对于一个图片里面有多个对象的话,在该xml中就有多个object。然后Annotations文件夹里面就是这样的一堆xml文件,其他没什么。
ImageSets 文件夹
在这个文件夹中还有一个Main文件夹,其他的文件夹不太重要(对于我目前的需求来说),这个文件夹中主要有四个.txt文件,分别是train.txt、test.txt、trainval.txt、val.txt

test.txt中保存的是测试所用的所有样本的名字,不过没有后缀(下同),一般测试的样本数量占总数据集的50%
train.txt中保存的是训练所用的样本名,样本数量通常占trainval的50%左右
val.txt中保存的是验证所用的样本名,数量占trainval的50%左右
trainval.txt中保存的是训练验证样本,是上面两个的总和,一般数量占总数据集的50%
2.自动化标注工具
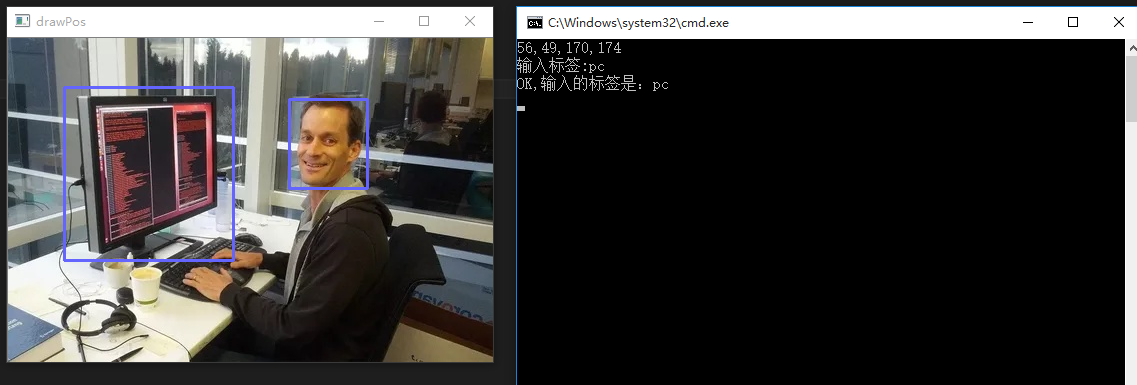
根据VOC的格式可以写一个标注工具。例如我使用Python和C++制作的一个工具:github
首先是rename.py,该脚本用来生成三个基本文件夹并将图片重新命名为VOC格式保存在JPEGImages中
然后打开VS2013工程,运行后可以开始进行图片的标注
标注完成后可以执行txt.py脚本,用来生成test.txt,train.txt,val.txt,trainval.txt四个文件并保存在Main文件夹中。
相关内容请见github。