深度学习编译器介绍
每一种硬件对应一门特定的编程语言,再通过特定的编译器去进行编译产生机器码,那随着硬件和语言的增多,编译器的维护难度会有很大困难。现代编译器已经解决了这个问题。
为了解决这个问题,科学家为编译器抽象出来了编译前端/编译中端/编译后端等概念,并引入IR(Intermediate Representation)。解释如下:
- 编译前端: 接收C/C++/Java等不同语言,进行代码生成,吐出IR
- 编译器中端:接收IR,进行不同编译器后端可以共享的优化,如常量替换,死代码消除,循环优化等,吐出优化后的IR
- 编译器后端:接收优化后的IR,进行不同硬件的平台相关优化与硬件指令生成,吐出目标文件

深度神经网络编译器受到编译器的启发,将各种深度学习模型传入到深度学习编译器之后吐出IR,深度学习的IR其实就是计算图,可以直接叫做Graph IR,然后将Graph IR经过计算图的优化操作再吐出IR分发到各种硬件使用。
类比到深度学习编译器上,如下图
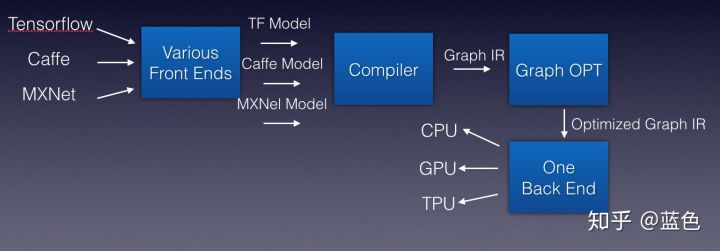
TVM:一个基于编译优化思想的推理框架
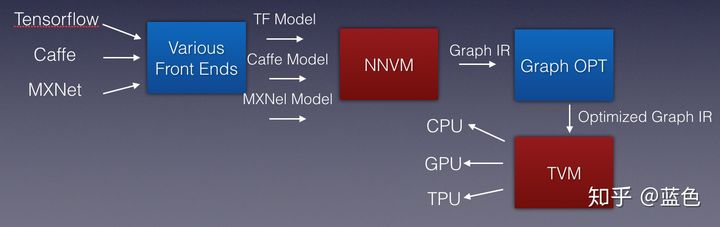
其中NNVM目前已经更新到了Relay, 是NNVM的进阶版本,同时具有编程语言的特点和深度学习图构造的能力,借助 TVM 代码生成工具以及 TOPI 中丰富的算子库,可以完成一系列深度学习编译部署工作。
本例中采用onnx导入深度学习模型,
编译前端 :导入模型
onnx导入resnet18.onnx模型
import onnx
import numpy as np
import tvm
from tvm import te
import tvm.relay as relay
onnx_model = onnx.load('resnet18.onnx')
from PIL import Image
image_path = 'cat.png'
img = Image.open(image_path).resize((224, 224))
# Preprocess the image and convert to tensor
from torchvision import transforms
my_preprocess = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
img = my_preprocess(img)
x = np.expand_dims(img, 0)
接下来便需要将TVM的Relay将ONNX模型变成TVM可以识别的Graph IR,TVM在Realy中提供了一个frontend.from_onnx用来加载ONNX模型并转换为Relay IR。
# 这里设置了target表示我们要在CPU后端运行Realy IR
target = "llvm"
input_name = "input.1"
shape_dict = {input_name: x.shape}
mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)
打印输出mod:
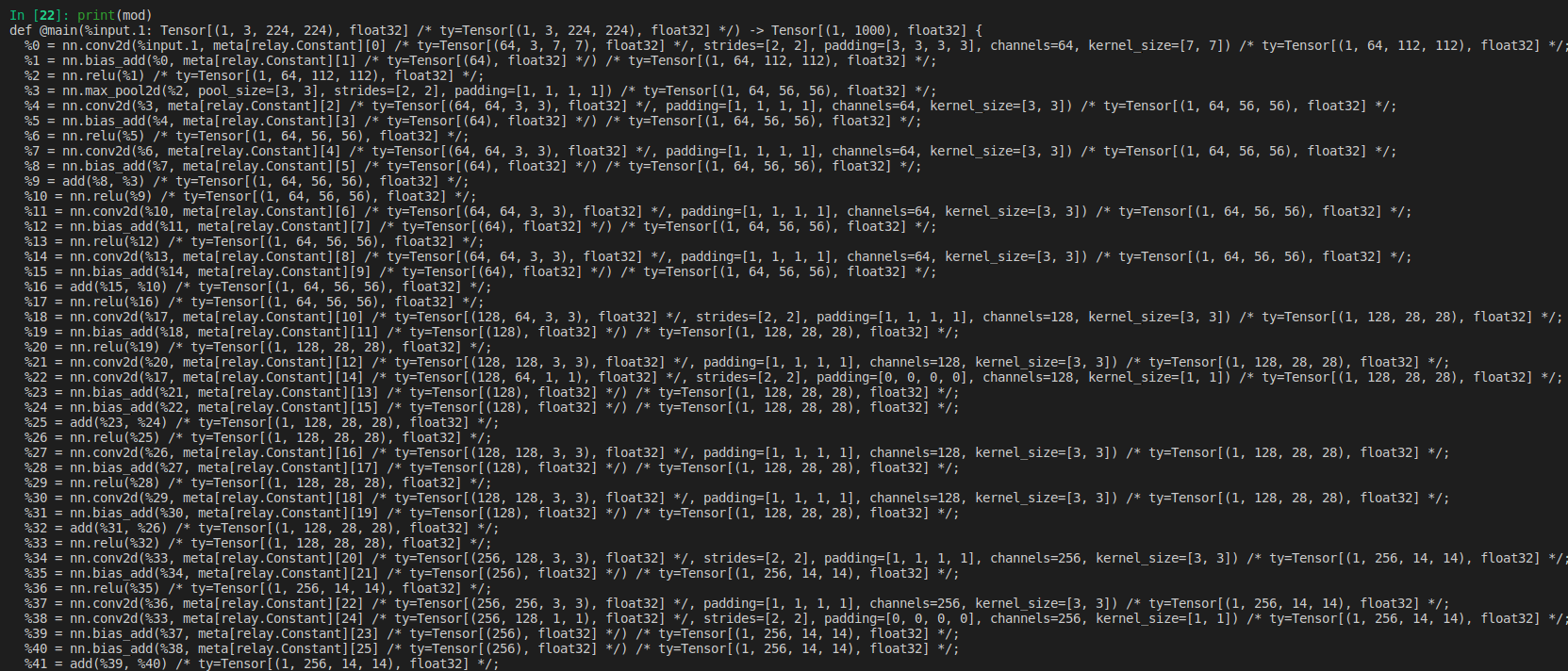
经过 relay.frontend.from_onnx函数接口调用,便可将onnx模型转换成IR,另可通过打印Mod,便可看到mod是一个Relay Function函数,函数输入的是ONNX模型中输入Tensor的shape信息。接下来看下,TVM如何将ONNX转换成Relay IR
补充:
onnx_model = onnx.load('resnet18.onnx')
执行完后,会得到一个ModelProto的对象,在调用from_onnx函数时会先 判断模型格式是否正确:
# 检查模型格式是否完整及正确
onnx.checker.check_model(model)
也可直接调用onnx_model.graph获取模型的图结构
PS:
Protocol buffer结构通常会定义要给proto文件,通过ONNXgithub链接下载onnx.protohttps://github.com/onnx/onnx。
解析模型用到的结构主要如下:
ModelProto:最高级别的结构,定义了整个网络模型结构;
GraphProto: graph定义了模型的计算逻辑以及带有参数的node节点,组成一个有向图结构;
NodeProto: 网络有向图的各个节点OP的结构,通常称为层,例如conv,relu层;
AttributeProto:各OP的参数,通过该结构访问,例如:conv层的stride,dilation等;
TensorProto: 序列化的tensor value,一般weight,bias等常量均保存为该种结构;
TensorShapeProto:网络的输入shape以及constant输入tensor的维度信息均保存为该种结构;
TypeProto:表示ONNX数据类型。
具体解析流程是读取.onnx文件,获得一个model结构,通过model结构访问到graph结构,然后通过graph访问整个网络的所有node以及input,output,通过node结构可以访问到OP的参数。
- ONNX model
The top-level ONNX construct is a ‘Model.’
模型结构的主要目的是将元数据(meta data)与图形(graph)相关联,图形包含所有可执行元素。 首先,读取模型文件时使用元数据,为实现提供所需的信息,以确定它是否能够:执行模型,生成日志消息,错误报告等功能。此外元数据对工具很有用,例如IDE和模型库,它需要它来告知用户给定模型的目的和特征。
model具有以组件:

ONNX Operator Sets:
每个模型必须明确命名它依赖于其功能的运算符集。 操作员集定义可用的操作符,其版本和状态。 每个模型按其域定义导入的运算符集。 所有模型都隐式导入默认的ONNX运算符集。
运算符集的属性是:

- ONNX Operator
图(graph)中使用的每个运算符必须由模型(model)导入的一个运算符集明确声明。
运算符定义的属性是:

- ONNX Graph
序列化图由一组元数据字段(metadata),模型参数列表(a list of model parameters,)和计算节点列表组成(a list of computation nodes)。
每个计算数据流图被构造为拓扑排序的节点列表,这些节点形成图形,其必须没有周期。 每个节点代表对运营商的呼叫。 每个节点具有零个或多个输入以及一个或多个输出。
图表具有以下属性:

Each graph MUST define the names and types of its inputs and outputs, which are specified as ‘value info’ structures, having the following properties:
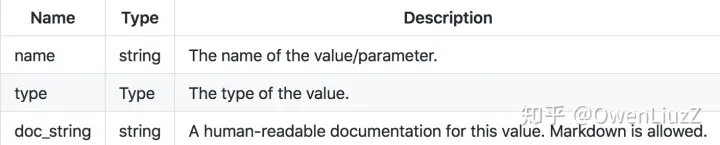
- Names Within a Graph
所有名称必须遵守C标识符语法规则。
节点,输入,输出,初始化器和属性的名称被组织到多个名称空间中。 在命名空间内,每个给定图形的每个名称必须是唯一的。
The namespaces are:

- Node
计算节点由名称,它调用的运算符的名称,命名输入列表,命名输出列表和属性列表组成。输入和输出在位置上与operator输入和输出相关联。 属性按名称与运算符属性相关联。
它们具有以下属性:

计算图中的边缘由后续节点的输入中由名称引用的一个节点的输出建立。
给定节点的输出将新名称引入图中。 节点输出的值由节点的运算符计算。 节点输入可以指定节点输出,图形输入和图形初始化器。 当节点输出的名称与图形输出的名称一致时,图形输出的值是该节点计算的相应输出值。
TVM如何将ONNX转换成Relay IR
from_onnx的执行流程如下:
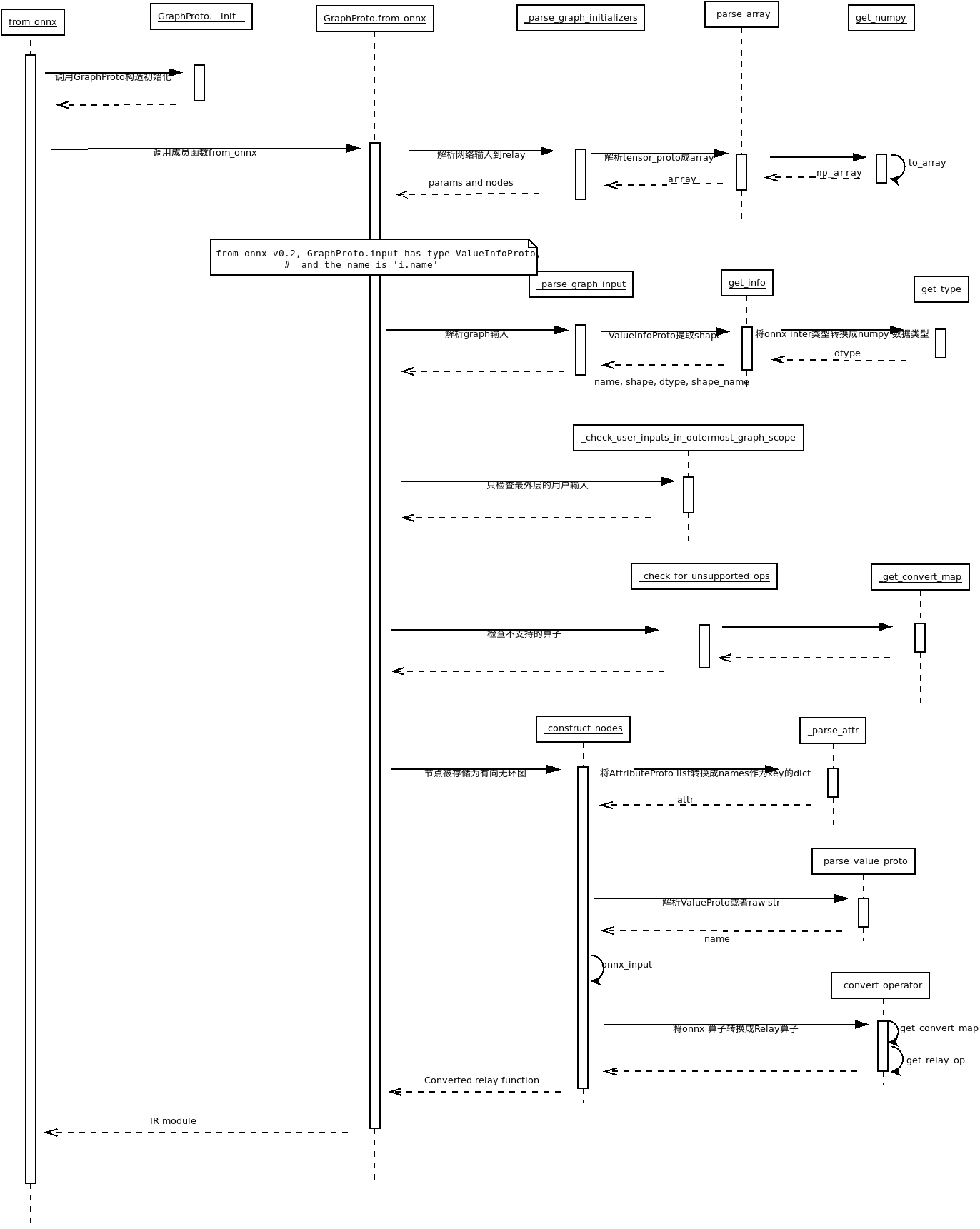
relay.frontend.from_onnx函数是在tvm/python/tvm/relay/frontend/onnx.py中,具体实现如下(参考:https://zhuanlan.zhihu.com/p/365800737):
def from_onnx(model, shape=None, dtype="float32", opset=None, freeze_params=False):
"""将一个ONNX模型转换成一个等价的Relay函数.
ONNX Graph被一个Python的Protobuf对象来表示,伴随着的参数将被自动处理。
然而,ONNX Graph的输入名称是模糊的,混淆了输入和网络权重/偏差,如“1”,“2”。。。
为方便起见,我们将“real”输入名重命名为“input_0”,“input_1”...
并将参数重命名为“param_0”、“param_1”...
默认情况下,ONNX根据动态形状定义模型。 ONNX导入器在导入时会保留这种动态性,并且编译器会在编译
时尝试将模型转换为静态形状。 如果失败,则模型中可能仍存在动态操作。 并非所有的TVM kernels当前
都支持动态形状,如果在使用动态kernels时遇到错误,请在ask.tvm.apache.org上提出问题。
参数
----------
model : protobuf 对象
ONNX ModelProto after ONNX v1.1.0
shape : str为key,tuple为value的字典, 可选
计算图的输入shape
dtype : str or dict of str to str
计算图的输入shapes(可能有多个输入,所以可能是str,也可能是字典)
opset : int, 可选
覆盖自动检测的算子集合。
对于一些测试是有用的。
freeze_params: bool
If this parameter is true, the importer will take any provided
onnx input values (weights, shapes, etc) and embed them into the relay model
as Constants instead of variables. This allows more aggressive optimizations
at compile time and helps in making models static if certain inputs represent
attributes relay would traditionally consider compile-time constants.
这段话简单来说就是一旦打开freeze_params这个参数,通过ONNX产生的Relay IR就会把所有可能提
供的输入,包括权重,shape都以常量的方式嵌入到Relay IR中。这有助于编译时优化和产生静态模型。
返回
-------
mod : tvm.IRModule
用于编译的Realy IR
params : dict of str to tvm.nd.NDArray
Relay使用的参数字典,存储权重
"""
try:
import onnx
if hasattr(onnx.checker, "check_model"):
# try use onnx's own model checker before converting any model
try:
onnx.checker.check_model(model)
except Exception as e: # pylint: disable=c-extension-no-member, broad-except
# the checker is a bit violent about errors, so simply print warnings here
warnings.warn(str(e))
except ImportError:
pass
# 一个从pb2.GraphProto复制的helper class,用于处理Relay IR。
g = GraphProto(shape, dtype, freeze_params)
# ONNX模型的GraphProto
graph = model.graph
if opset is None:
try:
opset = model.opset_import[0].version if model.opset_import else 1
except AttributeError:
opset = 1
# Use the graph proto as a scope so that ops can access other nodes if needed.
with g:
mod, params = g.from_onnx(graph, opset)
return mod, params
其中,freeze_params参数,参数为true,那编译出来的静态模型只能处理用户指定shape的模型。如一个全卷积网络,原本可以输入任意分辨率,但如果用户指定了的(224,224)分辨率进行构建Realy IR并将这个参数设置为True,那么在模型推理时如果接收了非长宽的图片就会抛出异常。
Relay IR在接收到ONNX模型后新建了一个GraphProto对象用来管理ONNX模型的OP转换以及生成Relay IR.其中核心函数就是g.from_onnx(graph, opset).该函数的就具体实现:
def from_onnx(self, graph, opset, get_output_expr=False):
"""Construct Relay expression from ONNX graph.
Onnx graph is a python protobuf object.
The companion parameters will be handled automatically.
However, the input names from onnx graph is vague, mixing inputs and
network weights/bias such as "1", "2"...
For convenience, we rename the `real` input names to "input_0",
"input_1"... And renaming parameters to "param_0", "param_1"...
Parameters
----------
graph : onnx protobuf object
The loaded onnx graph
opset : opset version
get_output_expr: bool
If set to true, this conversion will return each output expression rather
than a packaged module. This can be useful when converting subgraphs to
relay.
Returns
-------
mod : tvm.IRModule
The returned relay module
params : dict
A dict of name: tvm.nd.array pairs, used as pretrained weights
"""
self.opset = opset
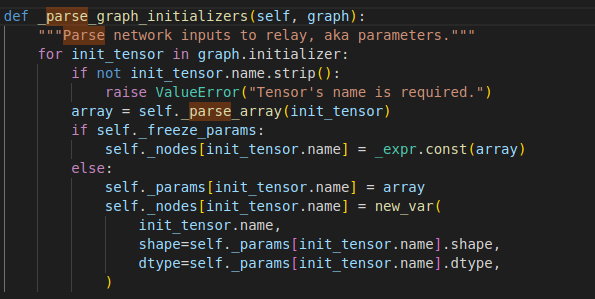
self._parse_graph_initializers(graph)
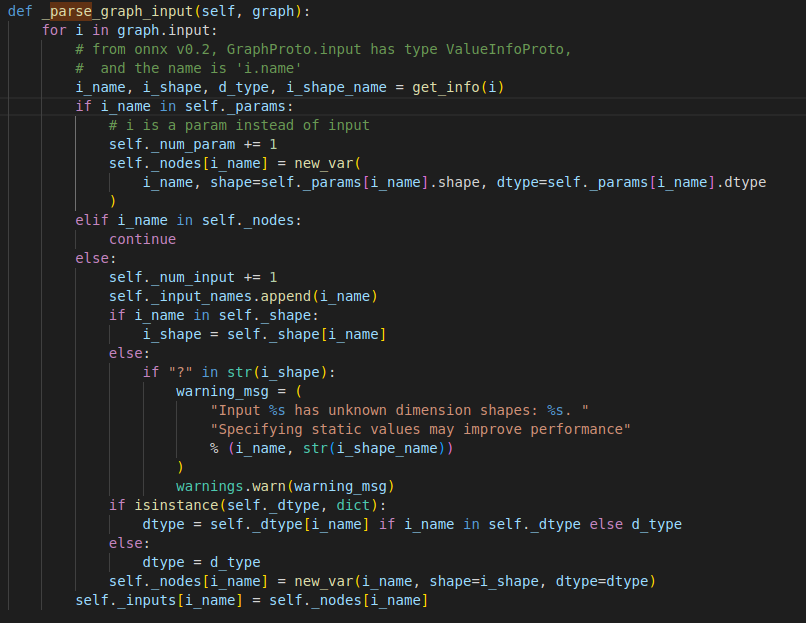
self._parse_graph_input(graph)
self._check_user_inputs_in_outermost_graph_scope()
self._check_for_unsupported_ops(graph)
self._construct_nodes(graph)
# now return the outputs
outputs = [self._nodes[self._parse_value_proto(i)] for i in graph.output]
outputs = outputs[0] if len(outputs) == 1 else _expr.Tuple(outputs)
# If requested, directly return the converted expressions.
if get_output_expr:
return outputs
## Maintain the order of inputs and parameters from the ONNX graph, but only include
## those parameters that are needed to execute the relay graph
free_vars = analysis.free_vars(outputs)
nodes = {v: k for k, v in self._nodes.items()}
free_vars = [nodes[var] for var in free_vars]
for i_name in self._params:
if i_name in free_vars and i_name not in self._inputs:
self._inputs[i_name] = self._nodes[i_name]
# Create a function from our output expression and all input variables.
func = _function.Function([v for k, v in self._inputs.items()], outputs)
return IRModule.from_expr(func), self._params
该函数中实现了ONNX graph转换为Relay表达。
首先_parse_graph_initializers(graph)解析网络的输入到relay中, 又叫参数,onnx的initializer就是用来保存模型参数的
_parse_graph_input解析模型的输入
然后就是校验用户最外层输入的尺寸_check_user_inputs_in_outermost_graph_scope,检查不支持的op算子_check_for_unsupported_ops,如果有不支持的算子,将会抛出异常
如果没有抛出异常,则说明onnx模型中的算子都被Relay支持,接下来就可以正常转换了,即最主要的函数_construct_nodes
def _construct_nodes(self, graph):
"""Nodes are stored as directed acyclic graph."""
for node in graph.node:
op_name = node.op_type
attr = self._parse_attr(node.attribute)
# Create and populate input list.创建并填充onnx输入对象
inputs = onnx_input()
for i in node.input:
if i != "":
#self._renames.get(i, i)用来获取ONNX Graph每个节点的输入
inputs.append(self._nodes[self._renames.get(i, i)])
else:
inputs.append(None)
i_name = self._parse_value_proto(node)
node_output = self._fix_outputs(op_name, node.output)
attr["tvm_custom"] = {}
attr["tvm_custom"]["name"] = i_name
attr["tvm_custom"]["num_outputs"] = len(node_output)
op = self._convert_operator(op_name, inputs, attr, self.opset)
if not isinstance(op, _expr.TupleWrapper):
outputs_num = 1
else:
outputs_num = len(op)
if outputs_num == 1:
op = fold_constant(op)
else:
op = _expr.TupleWrapper(fold_constant(op.astuple()), len(op))
if outputs_num > 1:
# ONNX supports optional outputs for some nodes.
# This block searches for missing outputs in the ONNX graph
# and removes any unneeded ops
valid_outputs = [False] * outputs_num
for i, output in enumerate(node_output):
if output != "":
valid_outputs[i] = True
# If we have outputs ONNX isn't expecting, we need to drop them
if not all(valid_outputs):
tup = op.astuple()
# TupleWrapper can also wrap ops with TupleType outputs
if isinstance(tup, _expr.Tuple):
# For tuples, we extract the fields instead of using GetTupleItem
outputs = [tup.fields[i] for i, valid in enumerate(valid_outputs) if valid]
else:
# For call nodes, we need to GetTupleItem
outputs = [op[i] for i, valid in enumerate(valid_outputs) if valid]
# Create the new op with valid outputs
if len(outputs) == 1:
op = outputs[0]
elif len(outputs) != outputs_num:
op = _expr.TupleWrapper(_expr.Tuple(outputs), len(outputs))
# Drop invalid outputs for the onnx node
outputs_num = len(outputs)
node_output = [output for output in node_output if output != ""]
assert (
len(node_output) == outputs_num
), "Number of output mismatch {} vs {} in {}.".format(
len(node_output), outputs_num, op_name
)
if outputs_num == 1:
self._nodes[node_output[0]] = op
else:
for k, i in zip(list(node_output), range(len(node_output))):
self._nodes[k] = op[i]
其中,执行转换操作的是_convert_operator
def _convert_operator(self, op_name, inputs, attrs, opset):
"""Convert ONNX operator into a Relay operator.
The converter must specify conversions explicitly for incompatible name, and
apply handlers to operator attributes.
Parameters
----------
op_name : str
Operator name, such as Convolution, FullyConnected
inputs : list of tvm.relay.function.Function
List of inputs.
attrs : dict
Dict of operator attributes
opset : int
Opset version
Returns
-------
sym : tvm.relay.function.Function
Converted relay function
"""
convert_map = _get_convert_map(opset)
if op_name in _identity_list:
sym = get_relay_op(op_name)(*inputs, **attrs)
elif op_name in convert_map:
sym = convert_map[op_name](inputs, attrs, self._params)
else:
raise NotImplementedError("Operator {} not implemented.".format(op_name))
return sym
通过_get_convert_map函数获取ONNX特定的Opset Version中被TVM支持的OP字典,字典的Key是ONNX OP的类型名字,而字典的Value就是转换之后的Relay IR。
# _convert_map defines maps of name to converter functor(callable)
# for 1 to 1 mapping, use Renamer if nothing but name is different
# use AttrCvt if attributes need to be converted
# for 1 to N mapping(composed), use custom callable functions
# for N to 1 mapping, currently not supported(?)
def _get_convert_map(opset):
return {
# defs/experimental
"Identity": Renamer("copy"),
"Affine": Affine.get_converter(opset),
"BitShift": BitShift.get_converter(opset),
"ThresholdedRelu": ThresholdedRelu.get_converter(opset),
"ScaledTanh": ScaledTanh.get_converter(opset),
"ParametricSoftplus": ParametricSoftPlus.get_converter(opset),
"Constant": Constant.get_converter(opset),
"ConstantOfShape": ConstantOfShape.get_converter(opset),
# 'GivenTensorFill'
"FC": AttrCvt("dense", ignores=["axis", "axis_w"]),
"Scale": Scale.get_converter(opset),
# 'GRUUnit'
# 'ATen'
# 'ImageScaler'
"MeanVarianceNormalization": MeanVarianceNormalization.get_converter(opset),
# 'Crop'
# 'Embedding'
"Upsample": Upsample.get_converter(opset),
"SpatialBN": BatchNorm.get_converter(opset),
# defs/generator
# 'Constant' # Implemented
# 'RandomUniform'
# 'RandomNormal'
# 'RandomUniformLike'
# 'RandomNormalLike'
# defs/logical
# defs/math
"Add": Add.get_converter(opset),
"Sub": Sub.get_converter(opset),
"Mul": Mul.get_converter(opset),
"Div": Div.get_converter(opset),
"Neg": Renamer("negative"),
"Abs": Absolute.get_converter(opset),
"Reciprocal": Reciprocal.get_converter(opset),
"Floor": Renamer("floor"),
"Ceil": Renamer("ceil"),
"Round": Round.get_converter(opset),
"IsInf": IsInf.get_converter(opset),
"IsNaN": Renamer("isnan"),
"Sqrt": Renamer("sqrt"),
"Relu": Renamer("relu"),
"Celu": Celu.get_converter(opset),
"LeakyRelu": Renamer("leaky_relu"),
"Selu": Selu.get_converter(opset),
"Elu": Elu.get_converter(opset),
"Gelu": Gelu.get_converter(opset),
"BiasGelu": BiasGelu.get_converter(opset),
# TODO: We need a better way to handle different domains, in case
# of name collisions. EmbedLayerNormalization, SkipLayerNormalization, and Attention
# are in the `com.microsoft` domain.
"EmbedLayerNormalization": EmbedLayerNormalization.get_converter(opset),
"SkipLayerNormalization": SkipLayerNormalization.get_converter(opset),
"Attention": Attention.get_converter(opset),
"Exp": Renamer("exp"),
"Greater": Renamer("greater"),
"GreaterOrEqual": Renamer("greater_equal"),
"Less": Renamer("less"),
"LessOrEqual": Renamer("less_equal"),
"Log": Renamer("log"),
"Acos": Renamer("acos"),
"Acosh": Renamer("acosh"),
"Asin": Renamer("asin"),
"Asinh": Renamer("asinh"),
"Atan": Renamer("atan"),
"Atanh": Renamer("atanh"),
"Cos": Renamer("cos"),
"Cosh": Renamer("cosh"),
"Sin": Renamer("sin"),
"Sinh": Renamer("sinh"),
"Tan": Renamer("tan"),
"Tanh": Renamer("tanh"),
"Pow": Pow.get_converter(opset),
"PRelu": Prelu.get_converter(opset),
"Sigmoid": Renamer("sigmoid"),
"HardSigmoid": HardSigmoid.get_converter(opset),
"HardSwish": HardSwish.get_converter(opset),
"Max": Maximum.get_converter(opset),
"Min": Minimum.get_converter(opset),
"Sum": Sum.get_converter(opset),
"Mean": Mean.get_converter(opset),
"Clip": Clip.get_converter(opset),
"Softplus": Softplus.get_converter(opset),
# softmax default axis is different in onnx
"Softmax": Softmax.get_converter(opset),
"LogSoftmax": LogSoftmax.get_converter(opset),
"OneHot": OneHot.get_converter(opset),
"Hardmax": Hardmax.get_converter(opset),
"Shrink": Shrink.get_converter(opset),
"Softsign": Softsign.get_converter(opset),
"Gemm": Gemm.get_converter(opset),
"MatMul": MatMul.get_converter(opset),
"MatMulInteger": MatMulInteger.get_converter(opset),
"MatMulInteger16": MatMulInteger16.get_converter(opset),
"Mod": Mod.get_converter(opset),
"Xor": Renamer("logical_xor"),
# defs/nn
"AveragePool": AveragePool.get_converter(opset),
"LpPool": LpPool.get_converter(opset),
"GlobalLpPool": GlobalLpPool.get_converter(opset),
"MaxPool": MaxPool.get_converter(opset),
"MaxUnpool": MaxUnpool.get_converter(opset),
"Conv": Conv.get_converter(opset),
"ConvTranspose": ConvTranspose.get_converter(opset),
"GlobalAveragePool": GlobalAveragePool.get_converter(opset),
"GlobalMaxPool": GlobalMaxPool.get_converter(opset),
"BatchNormalization": BatchNorm.get_converter(opset),
"InstanceNormalization": InstanceNorm.get_converter(opset),
# 'LpNormalization'
"Dropout": AttrCvt("dropout", {"ratio": "rate"}, ignores=["is_test"]),
"Flatten": Flatten.get_converter(opset),
"LRN": LRN.get_converter(opset),
# Recurrent Layers
"LSTM": LSTM.get_converter(opset),
"GRU": GRU.get_converter(opset),
# defs/vision
"MaxRoiPool": MaxRoiPool.get_converter(opset),
"RoiAlign": RoiAlign.get_converter(opset),
"NonMaxSuppression": NonMaxSuppression.get_converter(opset),
# defs/reduction
"ReduceMax": ReduceMax.get_converter(opset),
"ReduceMin": ReduceMin.get_converter(opset),
"ReduceSum": ReduceSum.get_converter(opset),
"ReduceMean": ReduceMean.get_converter(opset),
"ReduceProd": ReduceProd.get_converter(opset),
"ReduceLogSumExp": ReduceLogSumExp.get_converter(opset),
"ReduceLogSum": ReduceLogSum.get_converter(opset),
"ReduceSumSquare": ReduceSumSquare.get_converter(opset),
"ReduceL1": ReduceL1.get_converter(opset),
"ReduceL2": ReduceL2.get_converter(opset),
# defs/sorting
"ArgMax": ArgMax.get_converter(opset),
"ArgMin": ArgMin.get_converter(opset),
"TopK": TopK.get_converter(opset),
# defs/tensor
"Cast": Cast.get_converter(opset),
"Reshape": Reshape.get_converter(opset),
"Expand": Expand.get_converter(opset),
"Concat": Concat.get_converter(opset),
"Split": Split.get_converter(opset),
"Slice": Slice.get_converter(opset),
"Transpose": AttrCvt("transpose", {"perm": "axes"}),
"DepthToSpace": DepthToSpace.get_converter(opset),
"SpaceToDepth": SpaceToDepth.get_converter(opset),
"Gather": Gather.get_converter(opset),
"GatherElements": GatherElements.get_converter(opset),
"GatherND": GatherND.get_converter(opset),
"Compress": Compress.get_converter(opset),
"Size": AttrCvt("ndarray_size", extras={"dtype": "int64"}),
"Scatter": Scatter.get_converter(opset),
"ScatterElements": Scatter.get_converter(opset),
"ScatterND": ScatterND.get_converter(opset),
"EyeLike": EyeLike.get_converter(opset),
"Squeeze": Squeeze.get_converter(opset),
"Unsqueeze": Unsqueeze.get_converter(opset),
"Pad": Pad.get_converter(opset),
"Shape": Shape.get_converter(opset),
"Sign": Sign.get_converter(opset),
"Equal": Equal.get_converter(opset),
"Not": Not.get_converter(opset),
"And": And.get_converter(opset),
"Tile": Tile.get_converter(opset),
"Erf": Erf.get_converter(opset),
"Where": Where.get_converter(opset),
"Or": Or.get_converter(opset),
"Resize": Resize.get_converter(opset),
"NonZero": NonZero.get_converter(opset),
"Range": Range.get_converter(opset),
"CumSum": CumSum.get_converter(opset),
"Unique": Unique.get_converter(opset),
"Einsum": Einsum.get_converter(opset),
# defs/control_flow
"Loop": Loop.get_converter(opset),
"If": If.get_converter(opset),
# Torch ATen Dispatcher.
"ATen": ATen.get_converter(opset),
# Quantization
"QuantizeLinear": QuantizeLinear.get_converter(opset),
"DequantizeLinear": DequantizeLinear.get_converter(opset),
"DynamicQuantizeLinear": DynamicQuantizeLinear.get_converter(opset),
"ReverseSequence": ReverseSequence.get_converter(opset),
"QLinearConv": QLinearConv.get_converter(opset),
"QLinearConcat": QLinearConcat.get_converter(opset),
"QLinearAdd": QLinearAdd.get_converter(opset),
"QLinearMatMul": QLinearMatMul.get_converter(opset),
"QLinearMul": QLinearMul.get_converter(opset),
"QLinearSigmoid": QLinearSigmoid.get_converter(opset),
"ConvInteger": ConvInteger.get_converter(opset),
"QLinearAveragePool": QLinearAveragePool.get_converter(opset),
"QLinearGlobalAveragePool": QLinearGlobalAveragePool.get_converter(opset),
"QLinearLeakyRelu": QLinearLeakyRelu.get_converter(opset),
# Random number generation.
"RandomNormal": RandomNormal.get_converter(opset),
"RandomNormalLike": RandomNormalLike.get_converter(opset),
"RandomUniform": RandomUniform.get_converter(opset),
"RandomUniformLike": RandomUniformLike.get_converter(opset),
# Loss functions / training
"NegativeLogLikelihoodLoss": NegativeLogLikelihoodLoss.get_converter(opset),
"SoftmaxCrossEntropyLoss": SoftmaxCrossEntropyLoss.get_converter(opset),
"Adagrad": Adagrad.get_converter(opset),
"Adam": Adam.get_converter(opset),
"Momentum": Momentum.get_converter(opset),
"Scan": Scan.get_converter(opset),
# ML
"LinearRegressor": LinearRegressor.get_converter(opset),
# Sequence operators
"SequenceConstruct": SequenceConstruct.get_converter(opset),
"SequenceInsert": SequenceInsert.get_converter(opset),
"ConcatFromSequence": ConcatFromSequence.get_converter(opset),
}
以卷积层为例来看看ONNX的OP是如何被转换成Relay表达式的。卷积OP一般有输入,权重,偏置这三个项,对应了下面函数中的inputs[0],inputs[1],inputs[2]。
而auto_pad这个属性是ONNX特有的属性,TVM的Relay 卷积OP不支持这种属性,所以需要将ONNX 卷积OP需要Pad的数值计算出来并分情况进行处理(这里有手动对输入进行Pad以及给Relay的卷积OP增加一个padding参数两种做法,具体问题具体分析)。然后需要注意的是在这个转换函数中inputs[0]是Relay IR,而不是真实的数据,我们可以通过打印下面代码中的inputs[0]看到。
class Conv(OnnxOpConverter):
"""Operator converter for Conv."""
@classmethod
def _impl_v1(cls, inputs, attr, params):
# Use shape of input to determine convolution type.
data = inputs[0]
kernel = inputs[1]
input_shape = infer_shape(data)
ndim = len(input_shape)
kernel_type = infer_type(inputs[1])
kernel_shapes = [get_const_tuple(kernel_type.checked_type.shape)]
if "kernel_shape" not in attr:
attr["kernel_shape"] = kernel_shapes[0][2:]
if "auto_pad" in attr:
attr["auto_pad"] = attr["auto_pad"].decode("utf-8")
if attr["auto_pad"] in ("SAME_UPPER", "SAME_LOWER"):
# Warning: Convolution does not yet support dynamic shapes,
# one will need to run dynamic_to_static on this model after import
data = autopad(
data,
attr.get("strides", [1] * (ndim - 2)),
attr["kernel_shape"],
attr.get("dilations", [1] * (ndim - 2)),
mode=attr["auto_pad"],
)
elif attr["auto_pad"] == "VALID":
attr["pads"] = [0 for i in range(ndim - 2)]
elif attr["auto_pad"] == "NOTSET":
pass
else:
msg = 'Value {} in attribute "auto_pad" of operator Conv is invalid.'
raise tvm.error.OpAttributeInvalid(msg.format(attr["auto_pad"]))
attr.pop("auto_pad")
attr["channels"] = kernel_shapes[0][0]
out = AttrCvt(
op_name=dimension_picker("conv"),
transforms={
"kernel_shape": "kernel_size",
"dilations": ("dilation", 1),
"pads": ("padding", 0),
"group": ("groups", 1),
},
custom_check=dimension_constraint(),
)([data, kernel], attr, params)
use_bias = len(inputs) == 3
if use_bias:
out = _op.nn.bias_add(out, inputs[2])
return out
然后这个函数里面还有一个AttrCvt类,是用来做属性转换的,即上面提到的将ONNX Graph中OP的属性对应转换到TVM Relay的OP属性。最后如果卷积层有Bias,则使用_op.nn.bias_add将Bias加上去,注意这个OP返回的仍然是一个Relay表达式。
其它的OP处理类似卷积OP,做完所有ONNX的OP 一对一转换之后我们就可以获得第二节中的Relay IR和权重参数了,即这行代码:mod, params = relay.frontend.from_onnx(onnx_model, shape_dict)
TVM中如何添加OP
现在我们已经知道TVM是如何将ONNX转换成Realy IR的了,那么如果我们在适配自定义模型的时候某些OP TVM还不支持怎么办?这个时候就需要我们自定义OP了,自定义OP的方式可以是基于已有的OP进行拼接,也可以在TVM中独立实现这个OP,然后再在前端新增转换接口。这里以SeLU为例简单介绍新增OP需要做什么?
首先我们需要实现一个SeLU Class,这个类继承了OnnxOpConverter,然后实现_impl_v1方法,代码如下:
class Selu(OnnxOpConverter):
"""Operator converter for Selu."""
@classmethod
def _impl_v1(cls, inputs, attr, params):
alpha = float(attr.get("alpha", 1.6732))
gamma = float(attr.get("gamma", 1.0507))
return _expr.const(gamma) * (
_expr.const(-alpha) * _op.nn.relu(_expr.const(1.0) - _op.exp(inputs[0]))
+ _op.nn.relu(inputs[0])
)
可以看到这里是基于一些常用的算子按照SeLU的公式来拼出这个OP,在实现了这个转换逻辑之后,我们需要将这个OP注册到_convert_map中,即在_get_convert_map新增一行:"Selu": Selu.get_converter(opset),,然后保存源码重新编译TVM即可。这里新增SeLU类继承的OnnxOpConverter类实现如下:
class OnnxOpConverter(object):
"""A helper class for holding onnx op converters."""
@classmethod
def get_converter(cls, opset):
"""获取匹配给定的算子集合的转换器
Parameters
----------
opset: int
opset from model.
Returns
-------
converter, which should be `_impl_vx`. Number x is the biggest
number smaller than or equal to opset belongs to all support versions.
"""
# 这里的_impl_v_xxx方法是每个OP的具体实现方法,xxx代表版本,对应ONNX的Opset Version
versions = [int(d.replace("_impl_v", "")) for d in dir(cls) if "_impl_v" in d]
versions = sorted(versions + [opset])
version = versions[max([i for i, v in enumerate(versions) if v == opset]) - 1]
if hasattr(cls, "_impl_v{}".format(version)):
return getattr(cls, "_impl_v{}".format(version))
raise NotImplementedError(
"opset version {} of {} not implemented".format(version, cls.__name__)
)
重新编译完即可以对我们自定义的模型进行部署。
编译中端:IR编译与优化
有了Relay IR中的模型和参数,接下来便可进行编译
target = tvm.target.Target("llvm", host="llvm")
dev = tvm.cpu(0)
with tvm.transform.PassContext(opt_level=3):
lib = relay.build(mod, target=target, params=params)
这几行代码展示了TVM的编译流程,在这个 编译流程中不仅包含了基于Relay IR进行的优化策略来去除冗余的算子(也叫Pass)还包含了将Relay程序编译成特定后端(这里是llvm)可以执行的代码(codegen)。
relay.build(mod, target=target, params=params)便会进入TVM的编译流程。
这里的mod和prams分别代表模型的图结构和权重参数,relay.build函数定义在tvm/python/tvm/relay/build_module.py这个函数中,入口代码如下:
@register_func("tvm.relay.build")
def _build_module_no_factory_impl(mod, target, target_host, params, mod_name):
return build(
mod, target=target, target_host=target_host, params=params, mod_name=mod_name
).module
target为llvm代表这个模型会被TVM编译成CPU的可执行程序。
PS:
- 函数
register_func()为注册全局函数,便可访问到tvm.relay.build函数,具体实现如下:
def register_func(func_name, f=None, override=False):
"""Register global function
Parameters
----------
func_name : str or function
The function name
f : function, optional
The function to be registered.
override: boolean optional
Whether override existing entry.
Returns
-------
fregister : function
Register function if f is not specified.
Examples
--------
The following code registers my_packed_func as global function.
Note that we simply get it back from global function table to invoke
it from python side. However, we can also invoke the same function
from C++ backend, or in the compiled TVM code.
.. code-block:: python
targs = (10, 10.0, "hello")
@tvm.register_func
def my_packed_func(*args):
assert(tuple(args) == targs)
return 10
# Get it out from global function table
f = tvm.get_global_func("my_packed_func")
assert isinstance(f, tvm.PackedFunc)
y = f(*targs)
assert y == 10
"""
if callable(func_name):
f = func_name
func_name = f.__name__
if not isinstance(func_name, str):
raise ValueError("expect string function name")
ioverride = ctypes.c_int(override)
def register(myf):
"""internal register function"""
if not isinstance(myf, PackedFuncBase):
myf = convert_to_tvm_func(myf)
check_call(_LIB.TVMFuncRegisterGlobal(c_str(func_name), myf.handle, ioverride))
return myf
if f:
return register(f)
return register
- Target这个类的实现在tvm/python/tvm/target/target.py这里,是用来管理TVM支持的设备后端的。
接着看build函数,代码如下:
def build(
ir_mod,
target=None,
target_host=None,
executor=Executor("graph"),
runtime=Runtime("cpp"),
workspace_memory_pools=None,
constant_memory_pools=None,
params=None,
mod_name="default",
):
# fmt: off
# pylint: disable=line-too-long
"""Helper function that builds a Relay function to run on TVM graph executor.
Parameters
----------
ir_mod : :py:class:`~tvm.IRModule`
The IR module to build. Using relay.Function is deprecated.
target : None, or any multi-target like object, see Target.canon_multi_target
For homogeneous compilation, the unique build target.
For heterogeneous compilation, a dictionary or list of possible build targets.
Defaults to the current target in the environment if None.
target_host : None, or any target like object, see Target.canon_target
Host compilation target, if target is device.
executor : Optional[Executor]
The executor configuration with which to build the model.
Defaults to "graph" if no executor specified.
runtime : Optional[Runtime]
Runtime configuration to use when building the model.
Defaults to "cpp" if no runtime specified.
workspace_memory_pools : Optional[WorkspaceMemoryPools]
The object that contains an Array of WorkspacePoolInfo objects
that hold properties of read-write workspace pools that could be
used by the inference.
constant_memory_pools : Optional[ConstantMemoryPools]
The object that contains an Array of ConstantPoolInfo objects
that hold properties of read-only pools that could be
used by the inference.
params : dict of str to NDArray
Input parameters to the graph that do not change
during inference time. Used for constant folding.
mod_name: Optional[str]
The module name we will build
Returns
-------
factory_module : tvm.relay.backend.executor_factory.ExecutorFactoryModule
The runtime factory for the TVM graph executor.
"""
# pylint: enable=line-too-long
# fmt: on
if not isinstance(ir_mod, (IRModule, _function.Function)):
raise ValueError("Type of input parameter mod must be tvm.IRModule")
if isinstance(ir_mod, _function.Function):
if params:
ir_mod = bind_params_by_name(ir_mod, params) # 将relay.Function与params组合
ir_mod = IRModule.from_expr(ir_mod)
warnings.warn(
"Please use input parameter mod (tvm.IRModule) "
"instead of deprecated parameter mod (tvm.relay.function.Function)",
DeprecationWarning,
)
raw_targets = Target.canon_multi_target_and_host(Target.target_or_current(target), target_host) #检查和更新目标设备类型target和target对应的host端类型
assert len(raw_targets) > 0
target_host = raw_targets[0].host
# All of this logic is to raise deprecation warnings for various parameters
# TODO(Mousius) Remove these after some time
deprecated_params_target = target_host or list(raw_targets)[0]
deprecated_executor, deprecated_runtime = _reconstruct_from_deprecated_options(
deprecated_params_target
)
if deprecated_executor:
executor = deprecated_executor
if deprecated_runtime:
runtime = deprecated_runtime
# If current dispatch context is fallback context (the default root context),
# then load pre-tuned parameters from TopHub
if isinstance(autotvm.DispatchContext.current, autotvm.FallbackContext):
tophub_context = autotvm.tophub.context(list(raw_targets)) #寻找是否有AutoTVM预先fintune的记录,如果没有就使用autotvm.FallbackContext
else:
tophub_context = autotvm.utils.EmptyContext()
with tophub_context:
bld_mod = BuildModule() # 构建BuildModule对象
# BuildModule对象调用build函数,生成硬件可以执行的更底层IR
graph_json, runtime_mod, params = bld_mod.build(
mod=ir_mod,
target=raw_targets,
params=params,
executor=executor,
runtime=runtime,
workspace_memory_pools=workspace_memory_pools,
constant_memory_pools=constant_memory_pools,
mod_name=mod_name,
)
func_metadata = bld_mod.get_function_metadata()
devices = bld_mod.get_devices()
lowered_ir_mods = bld_mod.get_irmodule()
executor_codegen_metadata = bld_mod.get_executor_codegen_metadata()
if executor.name == "aot":
executor_factory = _executor_factory.AOTExecutorFactoryModule(
ir_mod,
lowered_ir_mods,
raw_targets,
executor,
runtime,
runtime_mod,
mod_name,
params,
func_metadata,
executor_codegen_metadata,
devices,
)
elif executor.name == "graph":
executor_factory = _executor_factory.GraphExecutorFactoryModule(
ir_mod,
raw_targets,
executor,
graph_json,
runtime_mod,
mod_name,
params,
func_metadata,
)
else:
assert False, "Executor " + executor + " not supported"
return executor_factory
在上面的函数中,首先将relay.Function和params组织成一个IRModule待用,并且再次检查和更新目标设备类型target和target对应的host端类型。接下来,Relay会寻找是否有AutoTVM预先Fintune的记录,如果没有那么就使用autotvm.FallbackContext这个环境上下文信息,如果有那么接下来的所有操作都在tophub_context 的 scope 之下(with tophub_context:)。值得一提的是 Relay考虑了异构情景下的代码生成,用户可以指定多个生成代码的目标(target)。
在with tophub_context:中,创建了一个BuildModule对象bld_mod,然后调用了bld_mod对象的build函数生成一个硬件可以执行的更底层的IR,以及包含各种必需运行时库的tvm.Module和优化后的计算图的参数。这里还有一个_executor_factory.GraphExecutorFactoryModule函数,它的功能就是将上面的IR,运行时库以及参数打包成一个tvm.Module,这样用户只需要把这个tvm.Module存下来,下次就可以省去编译过程直接在硬件上执行了。
TVM编译Relay IR的核心实现应该就是BuildModule类中的build函数,接着看源码:
class BuildModule(object):
"""Build an IR module to run on TVM graph executor. This class is used
to expose the `RelayBuildModule` APIs implemented in C++.
"""
def __init__(self):
self.mod = _build_module._BuildModule()
self._get_graph_json = self.mod["get_graph_json"]
self._get_module = self.mod["get_module"]
self._build = self.mod["build"]
self._optimize = self.mod["optimize"]
self._set_params_func = self.mod["set_params"]
self._get_params_func = self.mod["get_params"]
self._get_function_metadata = self.mod["get_function_metadata"]
self._get_executor_codegen_metadata = self.mod["get_executor_codegen_metadata"]
self._get_devices = self.mod["get_devices"]
self._get_irmodule = self.mod["get_irmodule"]
在构建BuildModule对象时,会调用BuildModule中的__init__函数,通过self.mod = _build_module._BuildModule()获取对应的C++函数,其中对_build_module对应/tvm/python/tvm/relay/_build_module.py, 具体实现如下:
"""The interface for building Relay functions exposed from C++."""
import tvm._ffi
tvm._ffi._init_api("relay.build_module", __name__)
可看到,其实它就是一个接口,将函数名_BuildModule()传给_init_api(), _init_api()函数在/tvm/python/tvm/_ffi/**registry.py **中,具体实现如下
def _init_api(namespace, target_module_name=None):
"""Initialize api for a given module name
namespace : str
The namespace of the source registry
target_module_name : str
The target module name if different from namespace
"""
target_module_name = target_module_name if target_module_name else namespace
if namespace.startswith("tvm."):
_init_api_prefix(target_module_name, namespace[4:])
else:
_init_api_prefix(target_module_name, namespace)
最终都会调到_init_api_prefix() 函数中,继续往下分析:
def _init_api_prefix(module_name, prefix):
module = sys.modules[module_name]
for name in list_global_func_names():
if not name.startswith(prefix):
continue
fname = name[len(prefix) + 1 :]
target_module = module
if fname.find(".") != -1:
continue
f = get_global_func(name)
ff = _get_api(f)
ff.__name__ = fname
ff.__doc__ = "TVM PackedFunc %s. " % fname
setattr(target_module, ff.__name__, ff)
可看到最终它调用了get_global_func(name)函数,这个函数为通过函数名从全局函数表中获取函数的实现。
TVM的注册机制:这个函数是通过register注册的全局函数,通过对函数名_BuildModule全局搜索,可找到函数注册的地方
TVM_REGISTER_GLOBAL("relay.build_module._BuildModule").set_body([](TVMArgs args, TVMRetValue* rv) {
*rv = RelayBuildCreate();
});
该注册位于/tvm/src/relay/backend/build_module.cc中,
首先,看下TVM_REGISTER_GLOBAL这个宏,定义如下:
#define TVM_REGISTER_GLOBAL(OpName) \
TVM_STR_CONCAT(TVM_FUNC_REG_VAR_DEF, __COUNTER__) = ::tvm::runtime::Registry::Register(OpName)
该Register函数的实现位于/tvm/src/runtime/registry.cc
Registry& Registry::Register(const std::string& name, bool can_override) { // NOLINT(*)
Manager* m = Manager::Global();
std::lock_guard<std::mutex> lock(m->mutex);
if (m->fmap.count(name)) {
ICHECK(can_override) << "Global PackedFunc " << name << " is already registered";
}
Registry* r = new Registry();
r->name_ = name;
m->fmap[name] = r;
return *r;
}
构造Register()对象,并将函数名与对应的Registry类型(set_body)进行绑定
然后 set_body函数中,就是调用了*rv = RelayBuildCreate();,RelayBuildCreate实现如下:
runtime::Module RelayBuildCreate() {
auto exec = make_object<RelayBuildModule>();
return runtime::Module(exec);
}
其中构造了RelayBuildModule对象,类RelayBuildModule继承自runtime::ModuleNode,具体实现如下:
class RelayBuildModule : public runtime::ModuleNode {
public:
RelayBuildModule() = default;
/*!
* \brief Get member function to front-end
* \param name The name of the function.
* \param sptr_to_self The pointer to the module node.
* \return The corresponding member function.
*/
PackedFunc GetFunction(const std::string& name, const ObjectPtr<Object>& sptr_to_self) final {
if (name == "get_graph_json") {
return PackedFunc(
[sptr_to_self, this](TVMArgs args, TVMRetValue* rv) { *rv = this->GetGraphJSON(); });
} else if (name == "get_module") {
return PackedFunc(
[sptr_to_self, this](TVMArgs args, TVMRetValue* rv) { *rv = this->GetModule(); });
} else if (name == "build") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
ICHECK_EQ(args.num_args, 8);
this->Build(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7]);
});
} else if (name == "list_params") {
return PackedFunc(
[sptr_to_self, this](TVMArgs args, TVMRetValue* rv) { *rv = this->ListParamNames(); });
} else if (name == "get_params") {
return PackedFunc(
[sptr_to_self, this](TVMArgs args, TVMRetValue* rv) { *rv = this->GetParams(); });
} else if (name == "set_params") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
Map<String, Constant> params = args[0];
for (const auto& kv : params) {
this->SetParam(kv.first, kv.second->data);
}
});
} else if (name == "get_devices") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->executor_codegen_->ListDevices();
});
} else if (name == "get_irmodule") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->executor_codegen_->GetIRModule();
});
} else if (name == "get_external_modules") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->executor_codegen_->GetExternalModules();
});
} else if (name == "get_function_metadata") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->executor_codegen_->GetFunctionMetadata();
});
} else if (name == "get_executor_codegen_metadata") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->executor_codegen_->GetExecutorCodegenMetadata();
});
} else if (name == "optimize") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
ICHECK_EQ(args.num_args, 2);
*rv = this->Optimize(args[0], args[1]);
});
} else {
LOG(FATAL) << "Unknown packed function: " << name;
return PackedFunc([sptr_to_self, name](TVMArgs args, TVMRetValue* rv) {});
}
}
这个类中有一个GetFunction函数,这个函数会通过名字查询要使用的函数,打包成PackedFunc返回,这个函数和上面__init__中的self.mod[“build”]等建立了映射关系。
则self.mod[“build”]会调用到如下代码:
if (name == "build") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
ICHECK_EQ(args.num_args, 8);
this->Build(args[0], args[1], args[2], args[3], args[4], args[5], args[6], args[7]);
});
其中Build代码实现如下:
/*!
* \brief Build relay IRModule for graph executor
*
* \param mod Relay IRModule
* \param raw_targets List of available targets for kernels.
* \param executor Executor to target
* \param runtime Runtime to codegen for
* \param mod_name Name of the module
*/
void Build(IRModule mod, const Array<Target>& raw_targets, const tvm::Target& target_host,
const Executor& executor, const Runtime& runtime,
const WorkspaceMemoryPools& workspace_memory_pools,
const ConstantMemoryPools& constant_memory_pools, const String mod_name) {
VLOG_CONTEXT << "Build";
executor_ = executor;
runtime_ = runtime;
workspace_memory_pools_ = workspace_memory_pools;
constant_memory_pools_ = constant_memory_pools;
config_ = CompilationConfig(PassContext::Current(), raw_targets);
VLOG(1) << "Using compilation config:" << std::endl << config_;
BuildRelay(std::move(mod), mod_name);
}
BuildRelay代码实现:
/*!
* \brief Compile a Relay IR module to runtime module.
*
* \param relay_module The Relay IR module.
* \param params The parameters.
*/
void BuildRelay(IRModule relay_module, const String& mod_name) {
// Relay IRModule -> IRModule optimizations.
IRModule module = WithAttrs(
relay_module, {{tvm::attr::kExecutor, executor_}, {tvm::attr::kRuntime, runtime_}});
relay_module = OptimizeImpl(std::move(module));
// Get the updated function and new IRModule to build.
// Instead of recreating the IRModule, we should look at the differences between this and the
// incoming IRModule to see if we can just pass (IRModule, Function) to the code generator.
Function func = Downcast<Function>(relay_module->Lookup("main"));
IRModule func_module = WithAttrs(IRModule::FromExpr(func),
{{tvm::attr::kExecutor, executor_},
{tvm::attr::kRuntime, runtime_},
{tvm::attr::kWorkspaceMemoryPools, workspace_memory_pools_},
{tvm::attr::kConstantMemoryPools, constant_memory_pools_}});
// Generate code for the updated function.
executor_codegen_ = MakeExecutorCodegen(executor_->name);
executor_codegen_->Init(nullptr, config_->primitive_targets);
executor_codegen_->Codegen(func_module, func, mod_name);
executor_codegen_->UpdateOutput(&ret_);
ret_.params = executor_codegen_->GetParams();
auto lowered_funcs = executor_codegen_->GetIRModule();
// No need to build for external functions.
Target ext_dev("ext_dev");
if (lowered_funcs.find(ext_dev) != lowered_funcs.end()) {
lowered_funcs.Set(ext_dev, IRModule());
}
const Target& host_target = config_->host_virtual_device->target;
const runtime::PackedFunc* pf = runtime::Registry::Get("codegen.LLVMModuleCreate");
// When there is no lowered_funcs due to reasons such as optimization.
if (lowered_funcs.size() == 0) {
if (host_target->kind->name == "llvm") {
CHECK(pf != nullptr) << "Unable to create empty module for llvm without llvm codegen.";
// If we can decide the target is LLVM, we then create an empty LLVM module.
ret_.mod = (*pf)(host_target->str(), "empty_module");
} else {
// If we cannot decide the target is LLVM, we create an empty CSourceModule.
// The code content is initialized with ";" to prevent complaining
// from CSourceModuleNode::SaveToFile.
ret_.mod = tvm::codegen::CSourceModuleCreate(";", "", Array<String>{});
}
} else {
ret_.mod = tvm::TIRToRuntime(lowered_funcs, host_target);
}
auto ext_mods = executor_codegen_->GetExternalModules();
ret_.mod = tvm::codegen::CreateMetadataModule(ret_.params, ret_.mod, ext_mods, host_target,
runtime_, executor_,
executor_codegen_->GetExecutorCodegenMetadata());
// Remove external params which were stored in metadata module.
for (tvm::runtime::Module mod : ext_mods) {
auto pf_var = mod.GetFunction("get_const_vars");
if (pf_var != nullptr) {
Array<String> variables = pf_var();
for (size_t i = 0; i < variables.size(); i++) {
auto it = ret_.params.find(variables[i].operator std::string());
if (it != ret_.params.end()) {
VLOG(1) << "constant '" << variables[i] << "' has been captured in external module";
ret_.params.erase(it);
}
}
}
}
}
在这个函数是编译流程的主要代码,可以看到它包含了Optimize,Codegen两个过程。
至此,类BuildModule中的__init__函数初始化完成,
接下来便执行调用该类中的build函数,这个函数为BuildModule类中的成员函数,具体实现如下:
def build(
self,
mod,
target=None,
target_host=None,
executor=Executor("graph"),
runtime=Runtime("cpp"),
workspace_memory_pools=None,
constant_memory_pools=None,
params=None,
mod_name=None,
):
"""
Parameters
----------
mod : :py:class:`~tvm.IRModule`
The IRModule to build.
target : any multi-target like object, see Target.canon_multi_target
For homogeneous compilation, the unique build target.
For heterogeneous compilation, a dictionary or list of possible build targets.
target_host : None, or any target-like object, see Target.canon_target
Host compilation target, if target is device.
When TVM compiles device specific program such as CUDA,
we also need host(CPU) side code to interact with the driver
to setup the dimensions and parameters correctly.
target_host is used to specify the host side codegen target.
By default, llvm is used if it is enabled,
otherwise a stackvm interpreter is used.
executor : Optional[Executor]
The executor configuration with which to build the model.
Defaults to "graph" if no executor specified.
runtime : Optional[Runtime]
Runtime configuration to use when building the model.
Defaults to "cpp" if no runtime specified.
workspace_memory_pools : Optional[WorkspaceMemoryPools]
The object that contains an Array of WorkspacePoolInfo objects
that hold properties of read-write workspace pools that could be
used by the inference.
constant_memory_pools : Optional[ConstantMemoryPools]
The object that contains an Array of ConstantPoolInfo objects
that hold properties of read-only memory pools that could be
used by the inference.
params : dict of str to NDArray
Input parameters to the graph that do not change
during inference time. Used for constant folding.
mod_name: Optional[str]
The module name we will build
Returns
-------
graph_json : str
The json string that can be accepted by graph executor.
mod : tvm.Module
The module containing necessary libraries.
params : dict
The parameters of the final graph.
"""
# pylint: disable=import-outside-toplevel
from tvm.auto_scheduler import is_auto_scheduler_enabled
from tvm.meta_schedule import is_meta_schedule_enabled
# pylint: enable=import-outside-toplevel
# Setup the params.
if params:
self._set_params(params)
# Build the IR module. If auto_scheduler is not enabled,
# then use the TOPI-defined schedule.
# Turn off AutoTVM config not found warnings if auto_scheduler is enabled.
old_autotvm_silent = autotvm.GLOBAL_SCOPE.silent
autotvm.GLOBAL_SCOPE.silent = (
is_auto_scheduler_enabled() or is_meta_schedule_enabled() or old_autotvm_silent
)
mod_name = mangle_module_name(mod_name)
self._build(
mod,
target,
target_host,
executor,
runtime,
workspace_memory_pools,
constant_memory_pools,
mod_name,
)
autotvm.GLOBAL_SCOPE.silent = old_autotvm_silent
# Get artifacts
mod = self.get_module()
params = self.get_params()
executor_config = self.get_graph_json() if executor.name == "graph" else None
return executor_config, mod, params
该成员函数返回,graph_json(The json string that can be accepted by graph executor.)/mod(tvm.Module类型,包含必要的库)/params(dict类型,最后graph的参数)
最后 _executor_factory.GraphExecutorFactoryModule()函数将结果返回
补充下:Codegen的调用过程:
在BuildRelay()函数中,
// Generate code for the updated function.
executor_codegen_ = MakeExecutorCodegen(executor_->name);
executor_codegen_->Init(nullptr, config_->primitive_targets);
executor_codegen_->Codegen(func_module, func, mod_name);
executor_codegen_->UpdateOutput(&ret_);
ret_.params = executor_codegen_->GetParams();
auto lowered_funcs = executor_codegen_->GetIRModule();
其中,MakeExecutorCodegen根据算子名称创建 ExecutorCodegen对象,MakeExecutorCodegen()函数实现如下:
/*!
* \brief Executor codegen factory function
*/
std::unique_ptr<ExecutorCodegen> MakeExecutorCodegen(String executor_str) {
std::unique_ptr<ExecutorCodegen> ret;
if (executor_str == runtime::kTvmExecutorGraph) {
ret = std::make_unique<GraphCodegen>();
} else if (executor_str == runtime::kTvmExecutorAot) {
ret = std::make_unique<AOTCodegen>();
} else {
CHECK(false) << "Executor " << executor_str << " not supported";
}
return ret;
}
接下来使用的executor_codegen_对象,其中ExecutorCodegen这个结构体定义在:src/relay/backend/build_module.cc中的struct ExecutorCodegen ,它封装了src/runtime/graph_executor/graph_executor.cc中的CodegenModule中的几个和 Codegen有关的函数,如init,get_graph_json,get_irmodule等。
struct ExecutorCodegen 实现如下:
class GraphExecutorCodegenModule : public runtime::ModuleNode {
public:
GraphExecutorCodegenModule() {}
virtual PackedFunc GetFunction(const std::string& name, const ObjectPtr<Object>& sptr_to_self) {
if (name == "init") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
ICHECK_EQ(args.num_args, 2) << "The expected of arguments are: "
<< "runtime::Module mod and Array<Target> targets";
void* mod = args[0];
Array<Target> targets = args[1];
codegen_ = std::make_shared<GraphExecutorCodegen>(reinterpret_cast<runtime::Module*>(mod),
std::move(targets));
});
} else if (name == "codegen") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
IRModule mod = args[0];
Function func = args[1];
String mod_name = args[2];
this->output_ = this->codegen_->Codegen(mod, func, mod_name);
});
} else if (name == "get_graph_json") {
return PackedFunc(
[sptr_to_self, this](TVMArgs args, TVMRetValue* rv) { *rv = this->output_.graph_json; });
} else if (name == "list_params_name") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
Array<runtime::String> ret;
for (const auto& kv : this->output_.params) {
ret.push_back(kv.first);
}
*rv = ret;
});
} else if (name == "get_param_by_name") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
String key = args[0];
auto it = this->output_.params.find(key);
CHECK(it != this->output_.params.end()) << "no such parameter " << key;
*rv = (*it).second;
});
} else if (name == "get_irmodule") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->output_.lowered_funcs;
});
} else if (name == "get_external_modules") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->output_.external_mods;
});
} else if (name == "get_devicesn_metadata;
});
} else {
return PackedFunc([](TVMArgs args, TVMRetValue* rv) {});
}
}
const char* type_key() const final { return "RelayGraphExecutorCodegenModule"; }
private:
std::shared_ptr<GraphExecutorCodegen> codegen_;
LoweredOutput output_;
};
通过CallFunc函数根据函数名调用过去的,如GetIRModule代码生成函数的调用实现:
void Codegen(IRModule mod, const Function& func, String mod_name) {
CallFunc("codegen", mod, func, mod_name);
}
CallFunc的实现如下:
template <typename R, typename... Args>
R CallFunc(const std::string& name, Args... args) {
auto pf = mod.GetFunction(name, false);
return pf(std::forward<Args>(args)...);
}
mod.getFunction()通过“codegen"函数名,进行函数调用:
if (name == "get_irmodule") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
*rv = this->executor_codegen_->GetIRModule();
});
如上所描述的,codegen代码实现在src/runtime/graph_executor/graph_executor.cc中
codegen实现函数如下:
if (name == "codegen") {
return PackedFunc([sptr_to_self, this](TVMArgs args, TVMRetValue* rv) {
IRModule mod = args[0];
Function func = args[1];
String mod_name = args[2];
this->output_ = this->codegen_->Codegen(mod, func, mod_name);
});
这里的Func是经过了一系列Pass优化之后的Relay Func,this->output_ = this->codegen_->Codegen(func);这里就调用了Graph Codegen的核心实现函数
这个函数LoweredOutput Codegen(IRModule mod, relay::Function func, String mod_name) 实现了内存的分配,Relay IR节点到TIR节点的转换,TIR图节点的调度优化
LoweredOutput Codegen(IRModule mod, relay::Function func, String mod_name) {
mod_name_ = mod_name;
VLOG_CONTEXT << "GraphExecutorCodegen";
VLOG(1) << "compiling:" << std::endl << PrettyPrint(func);
// TODO(mbs): Why plan memory and update workspace sizes before lowering?
memory_plan_ = GraphPlanMemory(func);
backend::FunctionInfo func_info;
if (memory_plan_.defined()) {
// TODO(@electriclilies, @jroesch): remove UpdateMainWorkspaceSize
func_info =
relay::tec::UpdateMainWorkspaceSize(mod, config_, memory_plan_->expr_to_storage_info);
mod = WithAttr(mod, "main_func_info", func_info);
}
IRModule lowered_mod = tec::LowerTE(mod_name_, config_, [this](BaseFunc func) {
// We need to maintain the constant map for external
// functions so we pass this processing function which
// allows us to process each function as we lower it.
if (func->GetAttr<String>(attr::kCompiler).defined()) {
UpdateConstants(func, ¶ms_);
}
// TODO(@areusch, @jroesch): We should refactor this to
// execute as a further pass, instead writing data to the
// lowering process directly.
tec::UpdateFunctionMetadata(func, this->function_metadata_);
})(mod);
Optional<backend::FunctionInfo> main_func_info =
lowered_mod->GetAttr<backend::FunctionInfo>("main_func_info");
function_metadata_.Set(runtime::symbol::tvm_module_main, main_func_info.value());
Function lowered_main_func = Downcast<Function>(lowered_mod->Lookup("main"));
// Now that we have lowered all operators to TIR code, we can proceed with compilation.
//
// We need to unfortunately re-plan as the previous results have been invalidated by lowering
// we will fix this in future refactors.
memory_plan_ = GraphPlanMemory(lowered_main_func);
// The graph planner also can not handle planning calls to global variables to we must remap
// First we convert all the parameters into input nodes.
for (auto param : lowered_main_func->params) {
auto node_ptr = GraphInputNode::make_node_ptr(param->name_hint(), GraphAttrs());
var_map_[param.get()] = AddNode(node_ptr, param);
}
heads_ = VisitExpr(lowered_main_func->body);
std::ostringstream os;
dmlc::JSONWriter writer(&os);
GetJSON(&writer);
LoweredOutput ret;
ret.graph_json = os.str();
// Collect any runtime modules generated by external codegen.
ret.external_mods =
lowered_mod->GetAttr<Array<runtime::Module>>(tvm::attr::kExternalMods).value_or({});
// Collect any constants extracted by external codegen.
ret.params = std::unordered_map<std::string, tvm::runtime::NDArray>();
Map<String, runtime::NDArray> const_name_to_constant =
lowered_mod->GetAttr<Map<String, runtime::NDArray>>(tvm::attr::kConstNameToConstant)
.value_or({});
for (const auto& kv : const_name_to_constant) {
VLOG(1) << "constant '" << kv.first << "' contributed by external codegen";
ICHECK(ret.params.emplace(kv.first, kv.second).second);
}
// Collect any constants extracted during lowering.
for (const auto& kv : params_) {
VLOG(1) << "constant '" << kv.first << "' contributed by TECompiler";
ICHECK(ret.params.emplace(kv.first, kv.second).second);
}
ret.function_metadata = std::move(function_metadata_);
// This is the point where we separate the functions in the module by target
ret.lowered_funcs = tec::GetPerTargetModules(lowered_mod);
ret.metadata =
ExecutorCodegenMetadata({} /* inputs */, {} /* input_tensor_types */, {} /* outputs */,
{} /* output_tensor_types */, {} /* pools */, {} /* devices */,
runtime::kTvmExecutorGraph /* executor */, mod_name_ /* mod_name */,
"packed" /* interface_api */, Bool(false) /* unpacked_api */);
return ret;
}
Graph Codegen的第一步是内存申请,即下面代码做的事:
TVM_REGISTER_GLOBAL("relay.backend.GraphPlanMemory").set_body_typed(GraphPlanMemory);
继续跟进GraphPlanMemory的实现:src/relay/backend/graph_plan_memory.cc
StaticMemoryPlan GraphPlanMemory(const Function& func) { return StorageAllocator().Plan(func); }
这里主要和StorageAllocator和StorageAllocaInit两个类的实现相关,StorageAllocaInit是用来创建封装内存申请信息的TokenMap,收集不同算子的设备信息。StorageAllocaInit的GetInitTokenMap构造函数是用来遍历func的节点,获得每个节点的设备属性。GetInitTokenMap构造函数的实现如下:
*! \brief Associate storage with every expression without any concern for sharing. */
class StorageAllocaInit : protected StorageAllocaBaseVisitor {
public:
explicit StorageAllocaInit(support::Arena* arena) : arena_(arena) {}
/*! \return The internal token map */
std::unordered_map<const ExprNode*, std::vector<StorageToken*>> GetInitTokenMap(
const Function& func) {
this->Run(func);
return std::move(token_map_);
}
StorageAllocaInit构造函数赋初值,GetInitTokenMap函数调用Run()函数,并将结果以map的形式返回
内存分配的暂时先这样了。。。
另通过lowerTE将IR转换为TIR,代码如下:
IRModule lowered_mod = tec::LowerTE(mod_name_, config_, [this](BaseFunc func) {
// We need to maintain the constant map for external
// functions so we pass this processing function which
// allows us to process each function as we lower it.
if (func->GetAttr<String>(attr::kCompiler).defined()) {
UpdateConstants(func, ¶ms_);
}
// TODO(@areusch, @jroesch): We should refactor this to
// execute as a further pass, instead writing data to the
// lowering process directly.
tec::UpdateFunctionMetadata(func, this->function_metadata_);
})(mod);
参考:https://zhuanlan.zhihu.com/p/386942253
编译后端:目标版本生成
Now we can try deploying the compiled model on target.
from tvm.contrib import graph_executor
dtype = "float32"
m = graph_executor.GraphModule(lib["default"](dev))
# Set inputs
m.set_input(input_name, tvm.nd.array(img.astype(dtype)))
# Execute
m.run()
# Get outputs
tvm_output = m.get_output(0)
参考:https://zhuanlan.zhihu.com/p/50529704
https://zhuanlan.zhihu.com/p/376863322