一个成熟合格的深度学习训练过程至少具备以下功能:
- 在训练集上训练,并在验证集上进行验证
- 模型可以保存最优的权重,并读取权重
- 记录训练集和验证集的精度,便于调参
本节将构建验证集、模型训练和验证、模型保存与加载和模型调参等几个部分
构造验证集
在机器学习模型(特别是深度学习模型)的训练过程中,模型是非常容易过拟合的。深度学习模型在不断的训练过程中训练误差会逐渐降低,但测试误差的走势则不一定。
在模型的训练过程中,模型只能利用训练数据来进行训练,但不能接触测试集上的数据。因此当模型在训练集上得到非常不错的下效果,但在测试集上效果较差,此现象就是过拟合,模型在未见过的测试集上的泛化能力太弱。
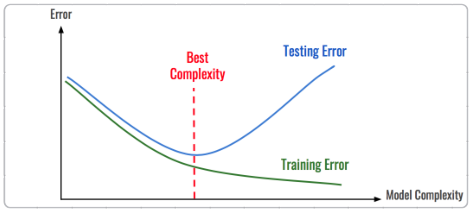
如上图,随着模型复杂度和模型训练轮数的增加,CNN模型在训练集上的误差会降低,但在测试集上的误差会逐渐降低,然后逐渐升高,而我们追求的是在测试集上的精度越高越好。
导致模型过拟合的情况有很多原因,其中最为常见的情况是模型复杂度(Model Complexity)太高,而数据太少,导致模型过度学习,学习到了一些细枝末节的规律。
解决上述问题的解决方法:构建一个与测试集尽可能分布一致的样本集--验证集,在训练过程中不断验证模型在验证集上的密度,并依次控制模型的训练
一般情况下,可在本地划分出一个验证集,进行本地验证。训练集、验证集和测试集作用如下:
- 训练集(Train Set):模型用于训练和调整模型参数
- 验证集(Validation Set):用来验证模型精度和调整超参数
- 测试集(Test Set):验证模型的泛化能力
因为训练集和验证集是分开的,所以模型在验证集上的精度在一定程度上可以反映模型的泛化能力。在划分验证集的时候,需要注意验证集的分布与测试集尽量保持一致,不然模型在验证集上的精度就失去了指导意义。
验证集的划分有如下几种方式:
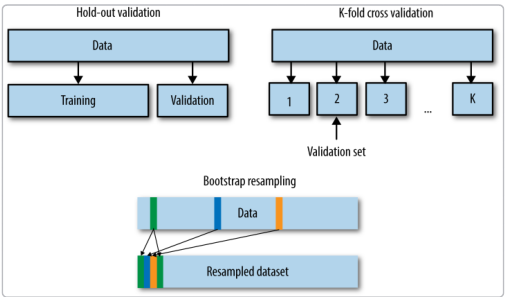
- 留出法(Hold-Out)
直接将训练集划分为两部分,新的训练集和验证集。优点就是最为直接简单;缺点就是只能得到一份验证集,有可能导致模型在验证集上过拟合。使用场景:数据量比较大的情况
2.交叉验证法(Cross Validation,CV)
将训练集划分为K份,将其中的K-1份作为训练集,剩下的1份作为验证集,循环K训练。这种训练方式是所有的验证集都有机会作为验证集,最终模型验证精度是K份平均得到。优点是验证集精度比较可靠,训练K次可以得到K个有多样性差异的模型;缺点:需要训练K次,不适合数据量很大的情况
3.自主采样法(BootStrap)
有放回的采样方式得到新的训练集和验证集,每次的训练集和验证集都有区别。这种方式一般适合用于数据量较小的情况
本赛题中已给出验证集,因此可以直接使用训练集进行训练,并使用验证集进行验证精度
模型的训练与验证
- 加载训练集、验证集数据(DataLoader)
- 每轮进行训练和验证,并根据最优验证集精度保存模型
- 加载训练集数据
train_path = glob.glob(r'./dataset/mchar_train/*.png')
train_path.sort()
train_json = json.load(open('./dataset/mchar_train.json'))
train_lebel = [train_json[x]['label'] for x in train_json]
print(len(train_path),len(train_lebel))
train_loader = torch.utils.data.DataLoader(
SVHNDataset(train_path,train_lebel,
transforms.Compose([
transforms.Resize((64,128)),
transforms.RandomCrop((60,120)),
transforms.ColorJitter(0.3,0.3,0.2),
transforms.RandomRotation(5),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.244,0.225])
])),
batch_size=40,
shuffle=True,
num_workers=0
)
加载验证集数据
val_path = glob.glob(r'./dataset/mchar_val/*.png')
val_path.sort()
val_json = json.load(open('./dataset/mchar_val.json'))
val_label= [val_json[x]['label'] for x in val_json]
print(len(val_path),len(val_json))
val_loader = torch.utils.data.DataLoader(
SVHNDataset(val_path,val_label,
transforms.Compose([
transforms.Resize((64,128)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.244,0.225])
])),
batch_size=40,
shuffle=False,
num_workers=0
)
在验证集中不需要对数据进行扩增,但需要对原图像进行resize以及正则化处理
- 训练函数
def train(train_loader,model,criterion,optimizer):
#训练模式
model.train()
train_loss=[]
for i,(input,target) in enumerate(train_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
target = target.long()
c0,c1,c2,c3,c4 = model(input)
loss = criterion(c0,target[:,0])+
criterion(c1,target[:,1])+
criterion(c2,target[:,2])+
criterion(c3,target[:,3])+
criterion(c4,target[:,4])
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 100 == 0:
print(loss.item())
train_loss.append(loss.item())
return np.mean(train_loss)
- 在验证集上做预测
def validate(val_loader,model,criterion):
#切换预测模式
model.eval()
val_loss = []
#不记录模型梯度
with torch.no_grad():
for i,(input,target) in enumerate(val_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0,c1,c2,c3,c4 = model(input)
target = target.long()
loss = criterion(c0,target[:,0])+
criterion(c1,target[:,1])+
criterion(c2,target[:,2])+
criterion(c3,target[:,3])+
criterion(c4,target[:,4])
val_loss.append(loss.item())
return np.mean(val_loss)
- 在测试集上做预测
def predict(test_loader,model,tta=10):
model.eval()
test_pred_tta = None
#TTA次数
for _ in range(tta):
test_pred =[]
with torch.no_grad():
for i,(input,target) in enumerate(test_loader):
if use_cuda:
input = input.cuda()
target = target.cuda()
c0,c1,c2,c3,c4 = model(input)
target = target.long()
output = np.concatenate([
c0.data.numpy(),
c1.data.numpy(),
c2.data.numpy(),
c3.data.numpy(),
c4.data.numpy()
],axis = 1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
对model.train()、model.eval()的解释
以model.train()为例:

模型前向传播、后向传播以及对参数的更新
如train()函数中model(input)便是对输入的数据进行前向传播,并通过预先定义好的交叉熵损失函数计算损失值
然后对参数进行初始化optimizer.zero_grad(),随后对数据进行后向传播并更新参数,(loss.backward()与optimizer.step())

对模型进行训练与保存模型
model = SVHN_Model2()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),0.001)
best_loss = 1000.0
use_cuda = False
if use_cuda:
model = model.cuda()
for epoch in range(2):
train_loss = train(train_loader,model,criterion,optimizer)
val_loss = validate(val_loader,model,criterion)
val_label = [''.join(map(str,x) for x in val_loader.dataset.img_label)]
val_predict_label = np.vstack([
val_predict_label[:,:11].argmax(1),
val_predict_label[:,11:22].argmax(1),
val_predict_label[:,22:33].argmax(1),
val_predict_label[:,33:44].argmax(1),
val_predict_label[:,44:55].argmax(1),
]).T
val_label_pred = []
for x in val_predict_label:
val_label_pred.append(''.join(map(str,x[x!=10])))
val_char_acc = np.mean(np.array(val_label_pred) == np.array(val_label))
print('Epoch:{0} ,Train loss :{1} Val loss:{2}'.format(epoch,train_loss,val_loss))
print(val_char_acc)
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict(),'./model.pt')
由于设备的算力问题,目前计算机仍在辛苦计算,现在它只是需要时间
部分数据结果


模型的保存与加载
比较常见的做法是保存和加载模型参数:
torch.save(model_object.state_dict(),'model.pt')
加载模型参数
model.load_state_dict(torch.load('model.pt'))
模型调参
这里对深度学习的训练技巧推荐的阅读链接:
- http://lamda.nju.edu.cn/weixs/project/CNNTricks/CNNTricks.html
- http://karpathy.github.io/2019/04/25/recipe/
对测试样本进行训练,并生成提交文件
加载模型
model = SVHN_Model2()
model.load_state_dict(torch.load('model.pt'))
读取数据
test_path = glob.glob(r'./dataset/mchar_test_a/*.png')
test_path.sort()
test_label=[[1]] * len(test_path)
print(len(test_path),len(test_label))
test_loader = torch.utils.data.DataLoader(
SVHNDataset(test_path,test_label,
transforms.Compose([
transforms.Resize((64,128)),
transforms.RandomCrop((60,120)),
# transforms.ColorJitter(0.3,0.3,0.2),
# transforms.RandomRotation(5),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.244,0.225])
])),
batch_size=40,
shuffle=False,
num_workers=0
)
test_predict_label = predict(test_loader,model,1)
test_label = [''.join(map(str,x)) for x in test_loader.dataset.img_label]
test_predict_label = np.vstack([
test_predict_label[:,:11].argmax(1),
test_predict_label[:,11:22].argmax(1),
test_predict_label[:,22:33].argmax(1),
test_predict_label[:,33:44].argmax(1),
test_predict_label[:,44:55].argmax(1),
]).T
test_label_pred = []
for x in test_predict_label:
test_label_pred.append(''.join(map(str,x[x!=10])))
生成提交文件
import pandas as pd
df_submit =pd.read_csv('./dataset/mchar_sample_submit_A.csv')
df_submit['file_code'] = test_label_pred
df_submit.to_csv('resnet_18.csv',index = None)

由于训练批次很好,仅2epoch,因此精度很低