1.3 编译程序的发展
1.编译程序历史
编译程序是系统软件中资格最老的成员之一。译理论和技术近30年来发展十分迅速、成熟现已形成一套较为系统化的编译理论和技术
2.编译理论与其他课程关系
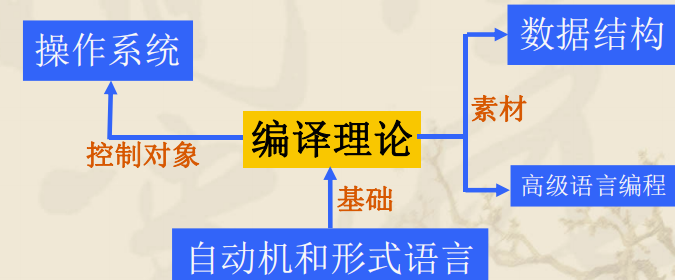
3.编译理论的应用
编译理论的许多想法和技术可用于一般软件的设计。
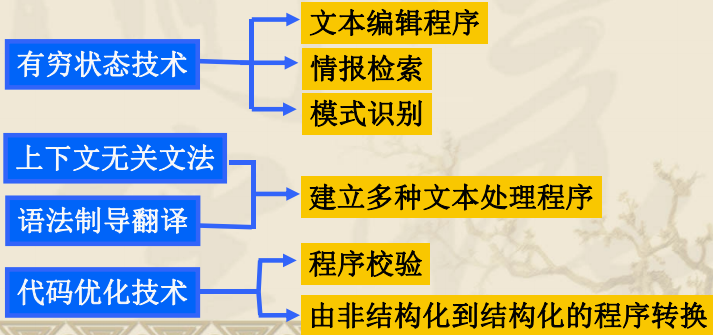
4.翻译程序
翻译程序(Translator) 是一种程序,其输入是某种语言的一系列语句,而其输出则是另一语言的语句序列。

5.编译程序
编译程序(Compiler) 是一种程序。它把用高级语言写的源程序作为数据输入,经过翻译转换,产生面向机器的代码作为输出。
这当中代码还可能要由汇编程序或装配程序作进一步加工,得出目标程序,交给计算机执行。

6.翻译与编译
这种变换程序称为翻译程序
编译程序有一些限制(针对输入、输出)

编译过程概述
1.编译过程的组成
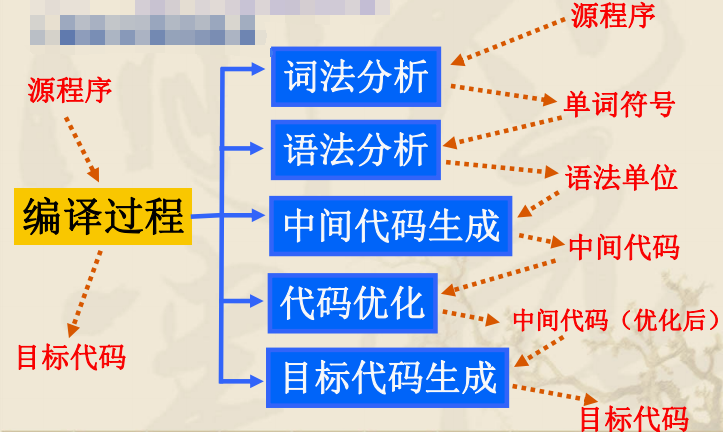
编译过程概述
2.词法分析


3.语法分析



此时可以看出,上述结果符合F 0 R循环语句的语法定义,故语法分析成功完成
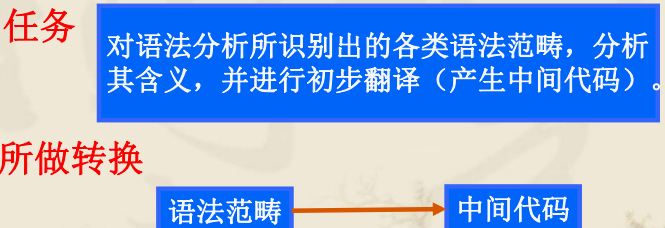
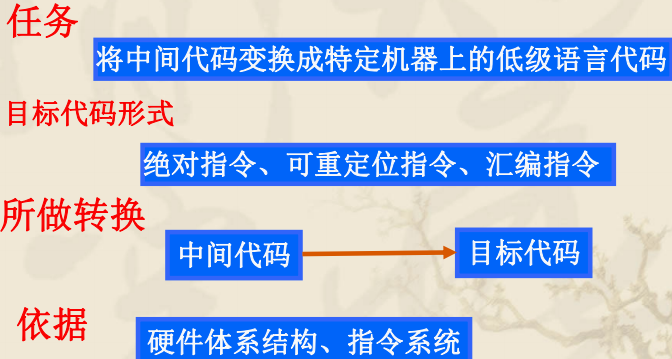
4.中间代码生成

5.代码优化


6.目标代码生成
三.编译程序的结构
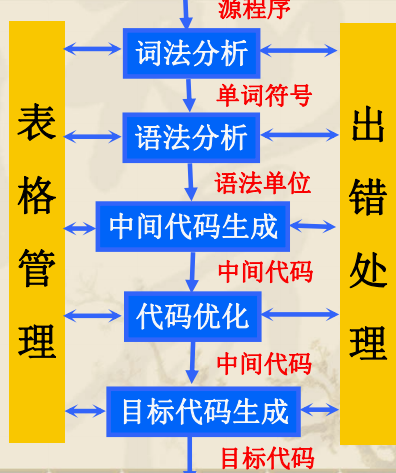
1.编译程序总框
2.表格与表格管理
编译各阶段均须维持表格并进行表格管理建表的技术支持是数据结构
表格的分类、结构、处理方法决定于语言及机器,还有优化措施
编译程序涉及的表格有:
符号名表
循环表
常数表
等价名表
标号表
公用链表
入口名表
格式表
过程引用表
中间代码表
3.出错处理
一个好的编译程序应该:
- 全 大限度发现错误
- 准 确指出错误的性质和发生地点
- 局部化 错误的影响限制在尽可能小的范围内
若能自动校正错误则更好,但其代价非常高
源程序中的错误通常分为:
- 语法错误
不符合语法( 或词法)规则的错误【单词拼写错误、括号不匹配】
- 语义错误
不符合语义规则的错误【说明错误、作用域错误、类型不匹配】
遍
是对源程序或源程序的中间结果从头到尾扫描一次,并作有关的加工处理,生成新的中间结果或目标程序。
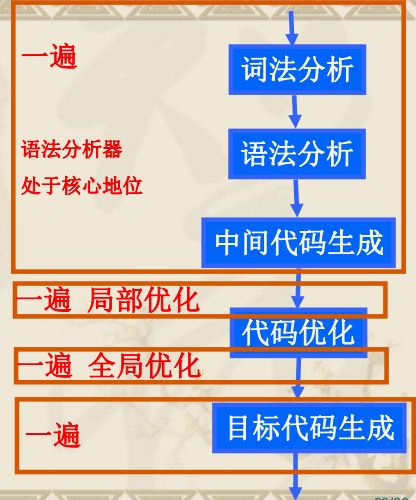
5.编译前端与后端
编译前端 要由与源语言有关但与目标机无关的那些部分组成
编译后端 括编译程序中与目标机有关的那些部分
四、编译程序生成
1.编译程序的构造工具
以往编译程序的构造大多采用机器语言或汇编语言
现在编译程序的构造越来越多采用高级语言
有时为了充分发挥效率或满足不同需求,仍然采用机器语言或汇编语言构造编译程序(或其核心部分)
2.构造工具
构造编译程序的工具称为编译程序产生器或翻译程序书写系统
自动产生扫描器 LEX FLEX
自动产生语法分析器 YACC BISON