本博文详细记录了IBM在网上公布使用spark,elasticsearch搭建一个推荐系统的DEMO。demo中使用的elasticsearch版本号为5.4,数据集是在推荐中经常使用movies data。Demo中提供计算向量相似度es5.4插件在es6.1.1中无法使用,因此我们基于es6.1.1开发一个新的计算特征向量相似度的插件,插件具体详情见github,下面我们一步一步的实现这个推荐系统:
整体框架
整个框架图如下:
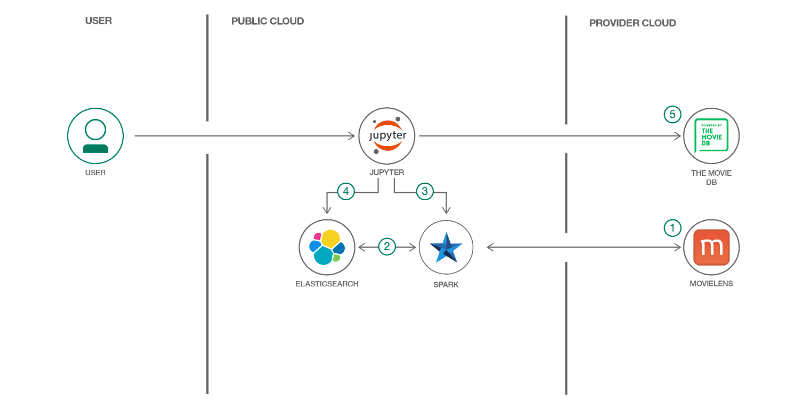
从图中我们可以看出具体的操作流程是:
- 利用spark.read.csv()读取ratings,users,movies数据集。
- 对数据集进行相关的处理
- 通过es-hadoop插件,将整理后的数据集保存到es
- 训练一个推荐模型-协同过滤模型
- 把训练好的模型保存到es中
- 搜索推荐-es查询和一个自定义矢量评分插件,计算用户与movies的最后评分
安装相关的组件
elasticsearch安装
spark安装
下载es-hadoop中间件
安装计算向量相似度的elasticsearch插件
运行
安装完es,spark,下载es-hadoop插件,以及es安装计算矢量评分的插件,然后通过如下命令启动:
PYSPARK_DRIVER_PYTHON="jupyter" PYSPARK_DRIVER_PYTHON_OPTS="notebook" /home/whb/Documents/pc/spark/spark-2.4.0/bin/pyspark --driver-memory 4g --driver-class-path /home/whb/Documents/pc/ELK/elasticsearch-hadoop-6.1.1/dist/elasticsearch-spark-20_2.11-6.1.1.jar
结果展示
from IPython.display import Image, HTML, display
def get_poster_url(id):
"""Fetch movie poster image URL from TMDb API given a tmdbId"""
IMAGE_URL = 'https://image.tmdb.org/t/p/w500'
try:
import tmdbsimple as tmdb
from tmdbsimple import APIKeyError
try:
movie = tmdb.Movies(id).info()
poster_url = IMAGE_URL + movie['poster_path'] if 'poster_path' in movie and movie['poster_path'] is not None else ""
return poster_url
except APIKeyError as ae:
return "KEY_ERR"
except Exception as me:
return "NA"
def fn_query(query_vec, q="*", cosine=False):
"""
Construct an Elasticsearch function score query.
The query takes as parameters:
- the field in the candidate document that contains the factor vector
- the query vector
- a flag indicating whether to use dot product or cosine similarity (normalized dot product) for scores
The query vector passed in will be the user factor vector (if generating recommended movies for a user)
or movie factor vector (if generating similar movies for a given movie)
"""
return {
"query": {
"function_score": {
"query" : {
"query_string": {
"query": q
}
},
"script_score": {
"script": {
"source": "whb_fvd",
"lang": "feature_vector_scoring_script",
"params": {
"field": "@model.factor",
"encoded_vector": query_vec,
"cosine" : True
}
}
},
"boost_mode": "replace"
}
}
}
def get_similar(the_id, q="*", num=10, index="movies", dt="movies"):
"""
Given a movie id, execute the recommendation function score query to find similar movies, ranked by cosine similarity
"""
response = es.get(index=index, doc_type=dt, id=the_id)
src = response['_source']
if '@model' in src and 'factor' in src['@model']:
raw_vec = src['@model']['factor']
# our script actually uses the list form for the query vector and handles conversion internally
q = fn_query(raw_vec, q=q, cosine=True)
results = es.search(index, dt, body=q)
hits = results['hits']['hits']
return src, hits[1:num+1]
def get_user_recs(the_id, q="*", num=10, index="users"):
"""
Given a user id, execute the recommendation function score query to find top movies, ranked by predicted rating
"""
response = es.get(index=index, doc_type="users", id=the_id)
src = response['_source']
if '@model' in src and 'factor' in src['@model']:
raw_vec = src['@model']['factor']
# our script actually uses the list form for the query vector and handles conversion internally
q = fn_query(raw_vec, q=q, cosine=False)
results = es.search(index, "movies", body=q)
hits = results['hits']['hits']
return src, hits[:num]
def get_movies_for_user(the_id, num=10, index="ratings"):
"""
Given a user id, get the movies rated by that user, from highest- to lowest-rated.
"""
response = es.search(index="ratings", doc_type="ratings", q="userId:%s" % the_id, size=num, sort=["rating:desc"])
hits = response['hits']['hits']
ids = [h['_source']['movieId'] for h in hits]
movies = es.mget(body={"ids": ids}, index="movies", doc_type="movies", _source_include=['tmdbId', 'title'])
movies_hits = movies['docs']
tmdbids = [h['_source'] for h in movies_hits]
return tmdbids
def display_user_recs(the_id, q="*", num=10, num_last=10, index="users"):
user, recs = get_user_recs(the_id, q, num, index)
user_movies = get_movies_for_user(the_id, num_last, index)
# check that posters can be displayed
first_movie = user_movies[0]
first_im_url = get_poster_url(first_movie['tmdbId'])
if first_im_url == "NA":
display(HTML("<i>Cannot import tmdbsimple. No movie posters will be displayed!</i>"))
if first_im_url == "KEY_ERR":
display(HTML("<i>Key error accessing TMDb API. Check your API key. No movie posters will be displayed!</i>"))
# display the movies that this user has rated highly
display(HTML("<h2>Get recommended movies for user id %s</h2>" % the_id))
display(HTML("<h4>The user has rated the following movies highly:</h4>"))
user_html = "<table border=0>"
i = 0
for movie in user_movies:
movie_im_url = get_poster_url(movie['tmdbId'])
movie_title = movie['title']
user_html += "<td><h5>%s</h5><img src=%s width=150></img></td>" % (movie_title, movie_im_url)
i += 1
if i % 5 == 0:
user_html += "</tr><tr>"
user_html += "</tr></table>"
display(HTML(user_html))
# now display the recommended movies for the user
display(HTML("<br>"))
display(HTML("<h2>Recommended movies:</h2>"))
rec_html = "<table border=0>"
i = 0
for rec in recs:
r_im_url = get_poster_url(rec['_source']['tmdbId'])
r_score = rec['_score']
r_title = rec['_source']['title']
rec_html += "<td><h5>%s</h5><img src=%s width=150></img></td><td><h5>%2.3f</h5></td>" % (r_title, r_im_url, r_score)
i += 1
if i % 5 == 0:
rec_html += "</tr><tr>"
rec_html += "</tr></table>"
display(HTML(rec_html))
def display_similar(the_id, q="*", num=10, index="movies", dt="movies"):
"""
Display query movie, together with similar movies and similarity scores, in a table
"""
movie, recs = get_similar(the_id, q, num, index, dt)
q_im_url = get_poster_url(movie['tmdbId'])
if q_im_url == "NA":
display(HTML("<i>Cannot import tmdbsimple. No movie posters will be displayed!</i>"))
if q_im_url == "KEY_ERR":
display(HTML("<i>Key error accessing TMDb API. Check your API key. No movie posters will be displayed!</i>"))
display(HTML("<h2>Get similar movies for:</h2>"))
display(HTML("<h4>%s</h4>" % movie['title']))
if q_im_url != "NA":
display(Image(q_im_url, width=200))
display(HTML("<br>"))
display(HTML("<h2>People who liked this movie also liked these:</h2>"))
sim_html = "<table border=0>"
i = 0
for rec in recs:
r_im_url = get_poster_url(rec['_source']['tmdbId'])
r_score = rec['_score']
r_title = rec['_source']['title']
sim_html += "<td><h5>%s</h5><img src=%s width=150></img></td><td><h5>%2.3f</h5></td>" % (r_title, r_im_url, r_score)
i += 1
if i % 5 == 0:
sim_html += "</tr><tr>"
sim_html += "</tr></table>"
display(HTML(sim_html))
