今天看到一个很有趣的程序,如下:
int main()
{
const int a = 1;
int *b = (int*)&a;
*b = 21;
printf("%d, %d", a, *b);
return 0;
}
当我第一眼看到这个程序的时候,我想当然的认为输出结果是21, 21,但是我错了

一时很难理解,于是我又输出了它们的地址:
int main()
{
const int a = 1;
int *b = (int*)&a;
*b = 21;
printf("%d, %d", a, *b);
printf("
%p, %p", &a, &*b);
return 0;
}
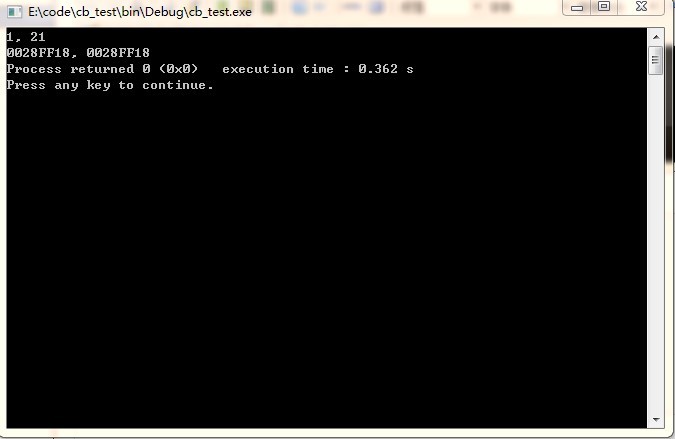
它们的地址是一样的,看到这里我更加的不解,于是我试着查看一下汇编代码。
int main()
{
const int a = 1;
int *b = (int*)&a;
*b = 21;
printf("%d", a);
return 0;
}
对应汇编代码如下:
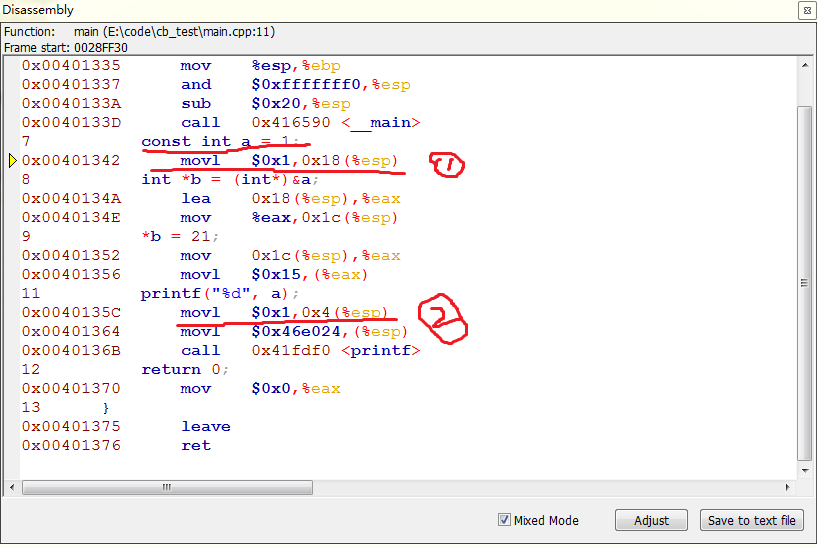
这里得到的是at&t的汇编代码,与intel不同之处在于:
1,指令格式为:指令名称 元操作数 目的操作数
2,寄存器前加%
3,操作数前加$
4,0x4(%esp)为内存寻址,实际表示的是esp寄存器中的内容 + 4(如果不是很明白,望自行查找资料,本人知识有限)
我们首先看标号为1的行,对应c语句为const int a =1,这是把1放进地址为0x18(%esp)的地方,再来看标号2的地方,对应的printf语句,发现并没有引用地址为0x18(%esp)的地方的值,而是把1直接放到了0x4(%esp),然后输出。
所以个人认为,之所以会出现最开始的结果,是因为编译器给我们做了一些优化导致的。为了证明我的观点,我修改了程序:
int main()
{
int c = 1;
const int a = c;
int *b = (int*)&a;
*b = 21;
printf("%d, %d", a, *b);
return 0;
}
输出结果为:
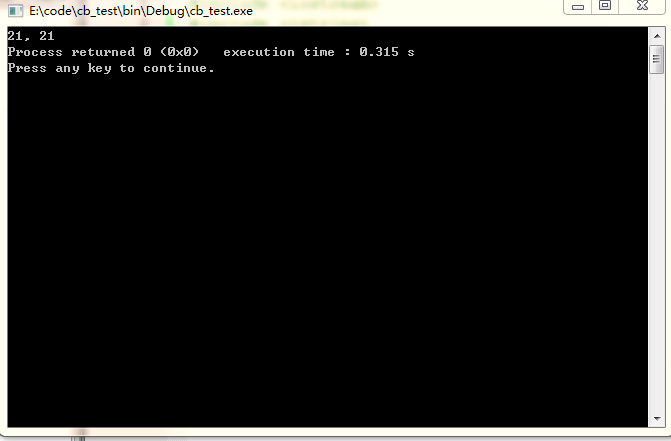
对应的汇编代码为:
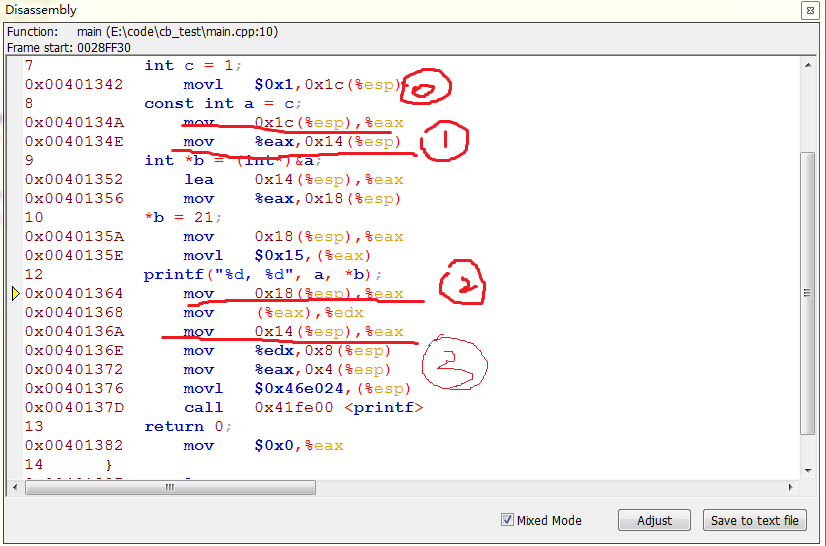
在标号1处,我们可以确定a存放在0x14(%esp)的地方,在标号2处,对应的printf语句,此语句从右向左处理参数,2处理的是*b,3处理的是a,这时看到用的是地址,而不是直接用数值,同时看标号0处,我们是将c赋值1,再给a赋值时编译器用的是数值,并没有引用地址。
所以,个人猜测,编译器在这方面有一个优化功能:如果一个变量在定义时赋值常量,那么在引用它的时候,编译器会直接用该常量数值代替地址的引用来节省时间,但是也给我们带来了以外的麻烦。
这些都是个人的观点,希望各位指教!!!