LinkedList是实现List、Collection接口,是链表方式进行构建的,根据开发要求不同,可以使用LinkedList实现栈(先进先出)和堆(先进后出)这样的数据结构。所以正确答案是B
Java的HashMap 类是一个散列表,它存储的内容是键值对(key-value)映射。HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。因为它属于Map接口的类,所以实现了将唯一键映射到特定的值上。HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
选项A、选项B和选项D的描述都是正确的。选项C是将HashMap和Hashtable作对比。HashMap和Hashtable的比较是Java面试中的常见问题,用来考验程序员是否能够正确使用集合类以及是否可以随机应变使用多种思路解决问题。
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
1)HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null,但Hashtable则不行。
2)HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable。
3)HashMap的迭代器是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
4)由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
5)HashMap不能保证随着时间的推移Map中的元素次序是不变的。
本题应选择C。

DataOutputStream类的写入数据的方法基本以write开头,针对字符串写入,有三个方法 字符数组writeBytes(String arg),多字符 writeChars(String arg),以及unicode字符 writeUTF(String arg)。本题答案中只出现了writeUTF方法,答案为D

通过Java的ArrayList类add()方法向al中添加了4项数据。然后,执行System.out.println(al)方法,调用重写的toString()方法输出al中的全部数据。重写的toString()方法返回此 collection 的字符串表示形式。该字符串表示形式由 collection 元素的列表组成,这些元素按其迭代器返回的顺序排列,并用方括号 ("[]") 括起来。相邻元素由字符 ", "(逗号加空格)分隔。所以,本题应选择C。

进行文件打开操作时,需要进行FileNotFoundException的抛出和处理,此题目中,dos进行实例化时,要进行文件的查找并打开,会出现文件不存才,打开失败等问题,所以需要使用try()catch()进行处理。否则会报出答案D的异常。正确答案D
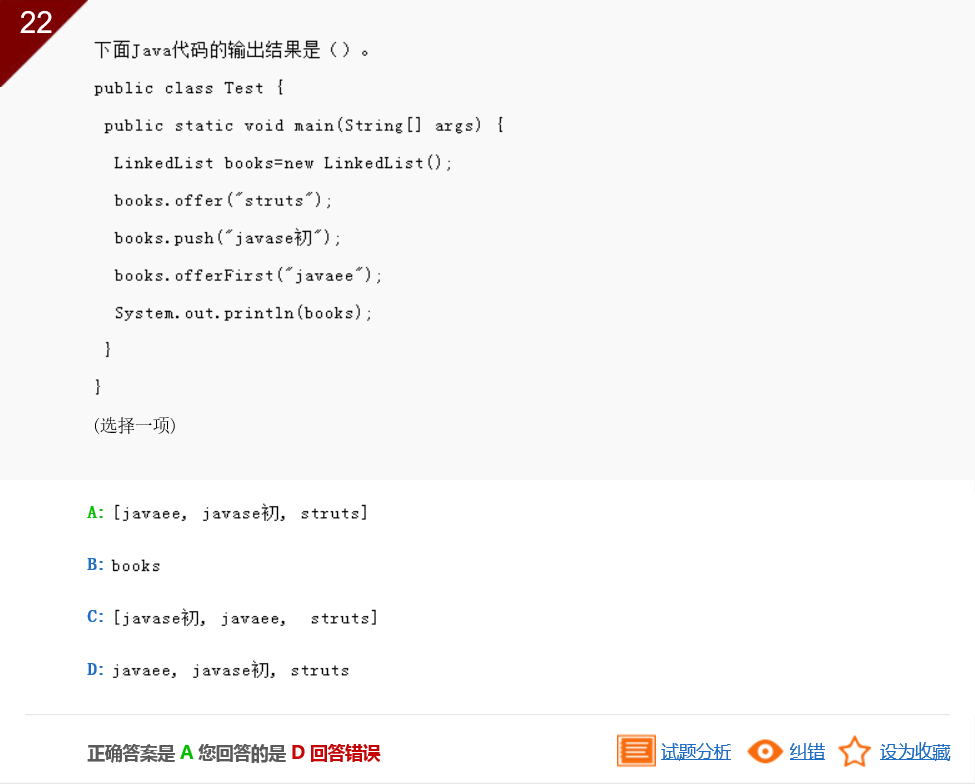
Java集合框架中,LinkedList类实现所有可选的列表操作,并且允许所有元素(包括 null)。本题调用执行了其中的几个常用方法:offer()是将指定元素添加到此列表的末尾(最后一个元素);push()方法是将元素推入此列表所表示的堆栈,即将该元素插入此列表的开头;offerFirst()方法是在此列表的开头插入指定的元素;get()方法是返回此列表中指定位置处的元素。执行System.out.println(books);调用重写的toString()方法输出books中的全部数据。重写的toString()方法返回此 collection 的字符串表示形式。该字符串表示形式由 collection 元素的列表组成,这些元素按其迭代器返回的顺序排列,并用方括号 ("[]") 括起来。相邻元素由字符 ", "(逗号加空格)分隔。本题应选择A。

Java语言中Iterator主要用来获取集合容器里面的数据。通过迭代器Iterator的hasNext()方法判断、遍历并输出Map</p><string,student>类型的对象map中数据。本题应选择A



是使用FileInputStream类中读取数据read方法,read(byte[] arg),具体是讲文本文件中的字符数据读取到byte数组中,与FileOutputStream的write方法不同的是,读取字符得到的ascii码值。同时,skip(int off)方法是在读取数据之前,会将读取位置偏移off,本题偏移一个字符。所以答案为A

File类可以表示路径,所以A答案错误,其次,程序中的getParentFile方法是返回上一级目录(project目录)的Flie对象,所以list方法返回的应该是上一级,也就是project目录下的对象数组,答案B错误,最后,list方法返回值是包括了目录和对象的,所以答案D错误。正确答案C

此方法是写入byte数组中,从off下标开始,len长度的字符到文件中,同时,需要学员熟记字母的ASCII编码对应的数值——65为‘A’。据上面分析,正确答案D

UTF是双字节编码,而writeChars方法写入的是按照字符格式写入的,在文件中的占位要小于以Unicode编码的同样字符串,所以,使用readUTF方法读取时,会出现EOF错误,标准答案B

InputStream为抽象类,不能实例化,只能实例化其子类对象。因此,选择B。

在本程序中,如果没有lst.remove(0)这个语句,do{}while();循环可以正常执行。但是,出现了之后,lst所返回的it这个Iterator对象描述的序列为空,此时先调用next()方法获得第一个成员时,就会出现java.util.NoSuchElementException异常。所以,在使用Iterator对象进行遍历序列时,使用while(){}循环为最佳。正确答案是D

Java的SortedSet是一个接口,其中的元素使用其自然顺序进行排序,或者根据通常在创建有序 set 时提供的 Comparator 进行排序。该 set 的迭代器将按元素升序进行遍历。它提供了一些附加的操作来利用这种排序。first()方法返回此 set 中当前第一个(最低)元素;tailSet()方法返回此 set 中大于等于指定的数值(方法的参数值)的所有元素。对返回的set添加泛型时,应该在赋值运算符的左侧限定泛型类型。因此,本题应选择A。
Char数组长度为1的情况下中文是乱码,当文件读取完成后length值为-1,会导致while是个死循环Char数组长度为1的情况下中文是乱码,当文件读取完成后length值为-1,会导致while是个死循环Char数组长度为1的情况下中文是乱码,当文件读取完成后length值为-1,会导致while是个死循环